單KEY業務,數據庫水平切分架構實踐
本文將以“用戶中心”為例,介紹“單KEY”類業務,隨著數據量的逐步增大,數據庫性能顯著降低,數據庫水平切分相關的架構實踐:
- 如何來實施水平切分
- 水平切分后常見的問題
- 典型問題的優化思路及實踐
一、用戶中心
用戶中心是一個非常常見的業務,主要提供用戶注冊、登錄、信息查詢與修改的服務,其核心元數據為:
- User(uid, login_name, passwd, sex, age, nickname, …)
其中:
- uid為用戶ID,主鍵
- login_name, passwd, sex, age, nickname, …等用戶屬性
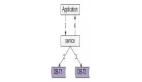
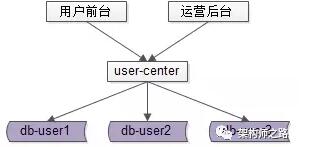
數據庫設計上,一般來說在業務初期,單庫單表就能夠搞定這個需求,典型的架構設計為:

- user-center:用戶中心服務,對調用者提供友好的RPC接口
- user-db:對用戶進行數據存儲
二、用戶中心水平切分方法
當數據量越來越大時,需要對數據庫進行水平切分,常見的水平切分算法有“范圍法”和“哈希法”。
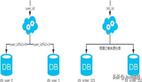
范圍法,以用戶中心的業務主鍵uid為劃分依據,將數據水平切分到兩個數據庫實例上去:

- user-db1:存儲0到1千萬的uid數據
- user-db2:存儲1到2千萬的uid數據
范圍法的優點是:
- 切分策略簡單,根據uid,按照范圍,user- center很快能夠定位到數據在哪個庫上
- 擴容簡單,如果容量不夠,只要增加user-db3即可
范圍法的不足是:
- uid必須要滿足遞增的特性
- 數據量不均,新增的user-db3,在初期的數據會比較少
- 請求量不均,一般來說,新注冊的用戶活躍度會比較高,故user-db2往往會比user-db1負載要高,導致服務器利用率不平衡
哈希法,也是以用戶中心的業務主鍵uid為劃分依據,將數據水平切分到兩個數據庫實例上去:

- user-db1:存儲uid取模得1的uid數據
- user-db2:存儲uid取模得0的uid數據
哈希法的優點是:
- 切分策略簡單,根據uid,按照hash,user-center很快能夠定位到數據在哪個庫上
- 數據量均衡,只要uid是均勻的,數據在各個庫上的分布一定是均衡的
- 請求量均衡,只要uid是均勻的,負載在各個庫上的分布一定是均衡的
哈希法的不足是:
- 擴容麻煩,如果容量不夠,要增加一個庫,重新hash可能會導致數據遷移,如何平滑的進行數據遷移,是一個需要解決的問題
三、用戶中心水平切分后帶來的問題
使用uid來進行水平切分之后,整個用戶中心的業務訪問會遇到什么問題呢?
對于uid屬性上的查詢可以直接路由到庫,假設訪問uid=124的數據,取模后能夠直接定位db-user1:

對于非uid屬性上的查詢,例如login_name屬性上的查詢,就悲劇了:

假設訪問login_name=shenjian的數據,由于不知道數據落在哪個庫上,往往需要遍歷所有庫,當分庫數量多起來,性能會顯著降低。
如何解決分庫后,非uid屬性上的查詢問題,是后文要重點討論的內容。
四、用戶中心非uid屬性查詢需求分析
任何脫離業務的架構設計都是耍流氓,在進行架構討論之前,先來對業務進行簡要分析,看非uid屬性上有哪些查詢需求。
根據樓主這些年的架構經驗,用戶中心非uid屬性上經常有兩類業務需求:
(1)用戶側,前臺訪問,最典型的有兩類需求
- 用戶登錄:通過login_name/phone/email查詢用戶的實體,1%請求屬于這種類型
- 用戶信息查詢:登錄之后,通過uid來查詢用戶的實例,99%請求屬這種類型
用戶側的查詢基本上是單條記錄的查詢,訪問量較大,服務需要高可用,并且對一致性的要求較高。
(2)運營側,后臺訪問,根據產品、運營需求,訪問模式各異,按照年齡、性別、頭像、登陸時間、注冊時間來進行查詢。
運營側的查詢基本上是批量分頁的查詢,由于是內部系統,訪問量很低,對可用性的要求不高,對一致性的要求也沒這么嚴格。
這兩類不同的業務需求,應該使用什么樣的架構方案來解決呢?
五、用戶中心水平切分架構思路
用戶中心在數據量較大的情況下,使用uid進行水平切分,對于非uid屬性上的查詢需求,架構設計的核心思路為:
- 針對用戶側,應該采用“建立非uid屬性到uid的映射關系”的架構方案
- 針對運營側,應該采用“前臺與后臺分離”的架構方案
六、用戶中心-用戶側最佳實踐
【索引表法】
思路:uid能直接定位到庫,login_name不能直接定位到庫,如果通過login_name能查詢到uid,問題解決
解決方案:
- 建立一個索引表記錄login_name->uid的映射關系
- 用login_name來訪問時,先通過索引表查詢到uid,再定位相應的庫
- 索引表屬性較少,可以容納非常多數據,一般不需要分庫
- 如果數據量過大,可以通過login_name來分庫
潛在不足:多一次數據庫查詢,性能下降一倍
【緩存映射法】
思路:訪問索引表性能較低,把映射關系放在緩存里性能更佳
解決方案:
- login_name查詢先到cache中查詢uid,再根據uid定位數據庫
- 假設cache miss,采用掃全庫法獲取login_name對應的uid,放入cache
- login_name到uid的映射關系不會變化,映射關系一旦放入緩存,不會更改,無需淘汰,緩存命中率超高
- 如果數據量過大,可以通過login_name進行cache水平切分
潛在不足:多一次cache查詢
【login_name生成uid】
思路:不進行遠程查詢,由login_name直接得到uid
解決方案:
- 在用戶注冊時,設計函數login_name生成uid,uid=f(login_name),按uid分庫插入數據
- 用login_name來訪問時,先通過函數計算出uid,即uid=f(login_name)再來一遍,由uid路由到對應庫
潛在不足:該函數設計需要非常講究技巧,有uid生成沖突風險
【login_name基因融入uid】
思路:不能用login_name生成uid,可以從login_name抽取“基因”,融入uid中

假設分8庫,采用uid%8路由,潛臺詞是,uid的最后3個bit決定這條數據落在哪個庫上,這3個bit就是所謂的“基因”。
解決方案:
- 在用戶注冊時,設計函數login_name生成3bit基因,login_name_gene=f(login_name),如上圖粉色部分
- 同時,生成61bit的全局唯一id,作為用戶的標識,如上圖綠色部分
- 接著把3bit的login_name_gene也作為uid的一部分,如上圖屎黃色部分
- 生成64bit的uid,由id和login_name_gene拼裝而成,并按照uid分庫插入數據
- 用login_name來訪問時,先通過函數由login_name再次復原3bit基因,login_name_gene=f(login_name),通過login_name_gene%8直接定位到庫
七、用戶中心-運營側最佳實踐
前臺用戶側,業務需求基本都是單行記錄的訪問,只要建立非uid屬性 login_name / phone / email 到uid的映射關系,就能解決問題。
后臺運營側,業務需求各異,基本是批量分頁的訪問,這類訪問計算量較大,返回數據量較大,比較消耗數據庫性能。
如果此時前臺業務和后臺業務公用一批服務和一個數據庫,有可能導致,由于后臺的“少數幾個請求”的“批量查詢”的“低效”訪問,導致數據庫的cpu偶爾瞬時100%,影響前臺正常用戶的訪問(例如,登錄超時)。
而且,為了滿足后臺業務各類“奇形怪狀”的需求,往往會在數據庫上建立各種索引,這些索引占用大量內存,會使得用戶側前臺業務uid/login_name上的查詢性能與寫入性能大幅度降低,處理時間增長。
對于這一類業務,應該采用“前臺與后臺分離”的架構方案:
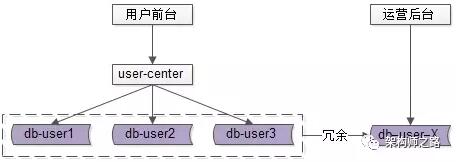
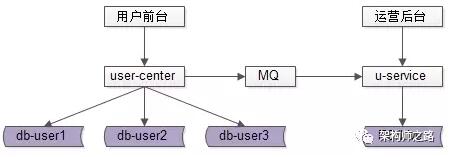
用戶側前臺業務需求架構依然不變,產品運營側后臺業務需求則抽取獨立的web / service / db 來支持,解除系統之間的耦合,對于“業務復雜”“并發量低”“無需高可用”“能接受一定延時”的后臺業務:
- 可以去掉service層,在運營后臺web層通過dao直接訪問db
- 不需要反向代理,不需要集群冗余
- 不需要訪問實時庫,可以通過MQ或者線下異步同步數據
- 在數據庫非常大的情況下,可以使用更契合大量數據允許接受更高延時的“索引外置”或者“HIVE”的設計方案
八、總結
將以“用戶中心”為典型的“單KEY”類業務,水平切分的架構點,本文做了這樣一些介紹。
水平切分方式:
- 范圍法
- 哈希法
水平切分后碰到的問題:
- 通過uid屬性查詢能直接定位到庫,通過非uid屬性查詢不能定位到庫
非uid屬性查詢的典型業務:
- 用戶側,前臺訪問,單條記錄的查詢,訪問量較大,服務需要高可用,并且對一致性的要求較高
- 運營側,后臺訪問,根據產品、運營需求,訪問模式各異,基本上是批量分頁的查詢,由于是內部系統,訪問量很低,對可用性的要求不高,對一致性的要求也沒這么嚴格
這兩類業務的架構設計思路:
- 針對用戶側,應該采用“建立非uid屬性到uid的映射關系”的架構方案
- 針對運營側,應該采用“前臺與后臺分離”的架構方案
用戶前臺側,“建立非uid屬性到uid的映射關系”最佳實踐:
- 索引表法:數據庫中記錄login_name->uid的映射關系
- 緩存映射法:緩存中記錄login_name->uid的映射關系
- login_name生成uid
- login_name基因融入uid
運營后臺側,“前臺與后臺分離”最佳實踐:
- 前臺、后臺系統web/service/db分離解耦,避免后臺低效查詢引發前臺查詢抖動
- 可以采用數據冗余的設計方式
- 可以采用“外置索引”(例如ES搜索系統)或者“大數據處理”(例如HIVE)來滿足后臺變態的查詢需求
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】