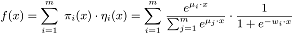數(shù)據(jù)挖掘核心算法之一--回歸
回歸,是一個(gè)廣義的概念,包含的基本概念是用一群變量預(yù)測(cè)另一個(gè)變量的方法,白話就是根據(jù)幾件事情的相關(guān)程度,用其中幾件來預(yù)測(cè)另一件事情發(fā)生的概率,最簡(jiǎn)單的即線性二變量問題(即簡(jiǎn)單線性),例如下午我老婆要買個(gè)包,我沒買,那結(jié)果就是我肯定沒有晚飯吃;復(fù)雜一點(diǎn)就是多變量(即多元線性,這里有一點(diǎn)要注意的,因?yàn)槲易钤缫郧胺高^這個(gè)錯(cuò)誤,就是認(rèn)為預(yù)測(cè)變量越多越好,做模型的時(shí)候總希望選取幾十個(gè)指標(biāo)來預(yù)測(cè),但是要知道,一方面,每增加一個(gè)變量,就相當(dāng)于在這個(gè)變量上增加了誤差,變相的擴(kuò)大了整體誤差,尤其當(dāng)自變量選擇不當(dāng)?shù)臅r(shí)候,影響更大,另一個(gè)方面,當(dāng)選擇的倆個(gè)自變量本身就是高度相關(guān)而不獨(dú)立的時(shí)候,倆個(gè)指標(biāo)相當(dāng)于對(duì)結(jié)果造成了雙倍的影響 ),還是上面那個(gè)例子,如果我丈母娘來了,那我老婆就有很大概率做飯;如果在加一個(gè)事件,如果我老丈人也來了,那我老婆肯定會(huì)做飯;為什么會(huì)有這些判斷,因?yàn)檫@些都是以前多次發(fā)生的,所以我可以根據(jù)這幾件事情來預(yù)測(cè)我老婆會(huì)不會(huì)做晚飯。
大數(shù)據(jù)時(shí)代的問題當(dāng)然不能讓你用肉眼看出來,不然要海量計(jì)算有啥用,所以除了上面那倆種回歸,我們經(jīng)常用的還有多項(xiàng)式回歸,即模型的關(guān)系是n階多項(xiàng)式;邏輯回歸(類似方法包括決策樹),即結(jié)果是分類變量的預(yù)測(cè);泊松回歸,即結(jié)果變量代表了頻數(shù);非線性回歸、時(shí)間序列回歸、自回歸等等,太多了,這里主要講幾種常用的,好解釋的(所有的模型我們都要注意一個(gè)問題,就是要好解釋,不管是參數(shù)選擇還是變量選擇還是結(jié)果,因?yàn)槟P徒ê昧俗罱K用的是業(yè)務(wù)人員,看結(jié)果的是老板,你要給他們解釋,如果你說結(jié)果就是這樣,我也不知道問什么,那升職加薪基本無望了),例如你發(fā)現(xiàn)日照時(shí)間和某地葡萄銷量有正比關(guān)系,那你可能還要解釋為什么有正比關(guān)系,進(jìn)一步統(tǒng)計(jì)發(fā)現(xiàn)日照時(shí)間和葡萄的含糖量是相關(guān)的,即日照時(shí)間長(zhǎng)葡萄好吃,另外日照時(shí)間和產(chǎn)量有關(guān),日照時(shí)間長(zhǎng),產(chǎn)量大,價(jià)格自然低,結(jié)果是又便宜又好吃的葡萄銷量肯定大。再舉一個(gè)例子,某石油產(chǎn)地的咖啡銷量增大,國際油價(jià)的就會(huì)下跌,這倆者有關(guān)系,你除了要告訴領(lǐng)導(dǎo)這倆者有關(guān)系,你還要去尋找為什么有關(guān)系,咖啡是提升工人精力的主要飲料,咖啡銷量變大,跟蹤發(fā)現(xiàn)工人的工作強(qiáng)度變大,石油運(yùn)輸出口增多,油價(jià)下跌和咖啡銷量的關(guān)系就出來了(單純的例子,不要多想,參考了一個(gè)根據(jù)遙感信息獲取船舶信息來預(yù)測(cè)糧食價(jià)格的真實(shí)案例,感覺不夠典型,就換一個(gè),實(shí)際油價(jià)是人為操控地)。
回歸利器--最小二乘法,牛逼數(shù)學(xué)家高斯用的(另一個(gè)法國數(shù)學(xué)家說自己先創(chuàng)立的,不過沒辦法,誰讓高斯出名呢),這個(gè)方法主要就是根據(jù)樣本數(shù)據(jù),找到樣本和預(yù)測(cè)的關(guān)系,使得預(yù)測(cè)和真實(shí)值之間的誤差和最小;和我上面舉的老婆做晚飯的例子類似,不過我那個(gè)例子在不確定的方面只說了大概率,但是到底多大概率,就是用最小二乘法把這個(gè)關(guān)系式寫出來的,這里不講最小二乘法和公式了,使用工具就可以了,基本所有的數(shù)據(jù)分析工具都提供了這個(gè)方法的函數(shù),主要給大家講一下之前的一個(gè)誤區(qū),最小二乘法在任何情況下都可以算出來一個(gè)等式,因?yàn)檫@個(gè)方法只是使誤差和最小,所以哪怕是天大的誤差,他只要是誤差和里面最小的,就是該方法的結(jié)果,寫到這里大家應(yīng)該知道我要說什么了,就算自變量和因變量完全沒有關(guān)系,該方法都會(huì)算出來一個(gè)結(jié)果,所以主要給大家講一下最小二乘法對(duì)數(shù)據(jù)集的要求:
1、正態(tài)性:對(duì)于固定的自變量,因變量呈正態(tài)性,意思是對(duì)于同一個(gè)答案,大部分原因是集中的;做回歸模型,用的就是大量的Y~X映射樣本來回歸,如果引起Y的樣本很凌亂,那就無法回歸
2、獨(dú)立性:每個(gè)樣本的Y都是相互獨(dú)立的,這個(gè)很好理解,答案和答案之間不能有聯(lián)系,就像擲硬幣一樣,如果***次是反面,讓你預(yù)測(cè)拋兩次有反面的概率,那結(jié)果就沒必要預(yù)測(cè)了
3、線性:就是X和Y是相關(guān)的,其實(shí)世間萬物都是相關(guān)的,蝴蝶和龍卷風(fēng)(還是海嘯來著)都是有關(guān)的嘛,只是直接相關(guān)還是間接相關(guān)的關(guān)系,這里的相關(guān)是指自變量和因變量直接相關(guān)
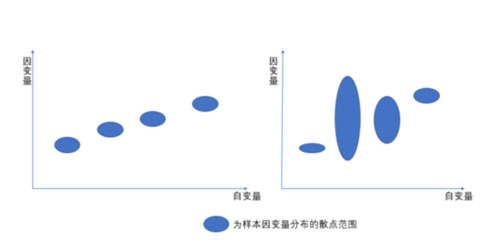
4、同方差性:因變量的方差不隨自變量的水平不同而變化。方差我在描述性統(tǒng)計(jì)量分析里面寫過,表示的數(shù)據(jù)集的變異性,所以這里的要求就是結(jié)果的變異性是不變的,舉例,腦袋軸了,想不出例子,畫個(gè)圖來說明。(我們希望每一個(gè)自變量對(duì)應(yīng)的結(jié)果都是在一個(gè)盡量小的范圍)
我們用回歸方法建模,要盡量消除上述幾點(diǎn)的影響,下面具體講一下簡(jiǎn)單回歸的流程(其他的其實(shí)都類似,能把這個(gè)講清楚了,其他的也差不多):
first,找指標(biāo),找你要預(yù)測(cè)變量的相關(guān)指標(biāo)(***步應(yīng)該是找你要預(yù)測(cè)什么變量,這個(gè)話題有點(diǎn)大,涉及你的業(yè)務(wù)目標(biāo),老板的目的,達(dá)到該目的最關(guān)鍵的業(yè)務(wù)指標(biāo)等等,我們后續(xù)的話題在聊,這里先把方法講清楚),找相關(guān)指標(biāo),標(biāo)準(zhǔn)做法是業(yè)務(wù)專家出一些指標(biāo),我們?cè)跍y(cè)試這些指標(biāo)哪些相關(guān)性高,但是我經(jīng)歷的大部分公司業(yè)務(wù)人員在建模初期是不靠譜的(真的不靠譜,沒思路,沒想法,沒意見),所以我的做法是將該業(yè)務(wù)目的所有相關(guān)的指標(biāo)都拿到(有時(shí)候上百個(gè)),然后跑一個(gè)相關(guān)性分析,在來個(gè)主成分分析,就過濾的差不多了,然后給業(yè)務(wù)專家看,這時(shí)候他們就有思路了(先要有東西激活他們),會(huì)給一些你想不到的指標(biāo)。預(yù)測(cè)變量是最重要的,直接關(guān)系到你的結(jié)果和產(chǎn)出,所以這是一個(gè)多輪優(yōu)化的過程。
第二,找數(shù)據(jù),這個(gè)就不多說了,要么按照時(shí)間軸找(我認(rèn)為比較好的方式,大部分是有規(guī)律的),要么按照橫切面的方式,這個(gè)就意味橫切面的不同點(diǎn)可能波動(dòng)較大,要小心一點(diǎn);同時(shí)對(duì)數(shù)據(jù)的基本處理要有,包括對(duì)極值的處理以及空值的處理。
第三, 建立回歸模型,這步是最簡(jiǎn)單的,所有的挖掘工具都提供了各種回歸方法,你的任務(wù)就是把前面準(zhǔn)備的東西告訴計(jì)算機(jī)就可以了。
第四,檢驗(yàn)和修改,我們用工具計(jì)算好的模型,都有各種假設(shè)檢驗(yàn)的系數(shù),你可以馬上看到你這個(gè)模型的好壞,同時(shí)去修改和優(yōu)化,這里主要就是涉及到一個(gè)查準(zhǔn)率,表示預(yù)測(cè)的部分里面,真正正確的所占比例;另一個(gè)是查全率,表示了全部真正正確的例子,被預(yù)測(cè)到的概率;查準(zhǔn)率和查全率一般情況下成反比,所以我們要找一個(gè)平衡點(diǎn)。
第五,解釋,使用,這個(gè)就是見證奇跡的時(shí)刻了,見證前一般有很久時(shí)間,這個(gè)時(shí)間就是你給老板或者客戶解釋的時(shí)間了,解釋為啥有這些變量,解釋為啥我們選擇這個(gè)平衡點(diǎn)(是因?yàn)闃I(yè)務(wù)力量不足還是其他的),為啥做了這么久出的東西這么差(這個(gè)就尷尬了)等等。
回歸就先和大家聊這么多,下一輪給大家聊聊主成分分析和相關(guān)性分析的研究,然后在聊聊數(shù)據(jù)挖掘另一個(gè)利器--聚類。