從回歸分析到數(shù)據(jù)挖掘
回歸分析是研究兩種或兩種以上變量之間相互依賴的定量關(guān)系的統(tǒng)計分析方法,在很多行業(yè)都有廣泛的應(yīng)用。無論是銀行、保險、電信等服務(wù)行業(yè)的業(yè)務(wù)分析人員在進行數(shù)據(jù)庫營銷、欺詐風(fēng)險偵測,還是半導(dǎo)體、電子、化工、醫(yī)藥、鋼鐵等制造行業(yè)的研發(fā)技術(shù)人員在進行新產(chǎn)品實驗設(shè)計與分析、流程優(yōu)化與過程監(jiān)控,或者更廣義地說,不同類型的企業(yè)在開展質(zhì)量管理和六西格瑪項目時,都常常會用到回歸分析。
回歸分析可以幫助我們判斷哪些因素的影響是顯著的,哪些因素的影響是不顯著的,還可以利用求得的回歸方程進行預(yù)測和控制。但是,稍微對回歸模型的有效程度和預(yù)測精度有一定要求時,我們就會發(fā)現(xiàn)回歸分析有一些先天性的不足和隱患:
1. 缺少用實際數(shù)據(jù)驗證模型有效性的環(huán)節(jié),經(jīng)常聽到的抱怨是:模型看上去很美,但是一到應(yīng)用環(huán)節(jié)就發(fā)現(xiàn)預(yù)測不準(zhǔn)確;
2. 建模手段單一,不能多角度地考慮問題,從而更好地擬合數(shù)據(jù);
3. 無法系統(tǒng)地比較通過不同方法得到的不同模型,更談不上在眾多候選模型中甄選出一個相對***的模型。
這時,想要消除上述隱患,突破工具瓶頸的理想辦法就是從“回歸分析”的層次上升到“數(shù)據(jù)挖掘”的層次。
數(shù)據(jù)挖掘是一個更大的數(shù)據(jù)分析概念,主要指從大量的企業(yè)數(shù)據(jù)中揭示出隱含的、先前未知的并有潛在價值的信息的整個過程。從統(tǒng)計技術(shù)層面上講,數(shù)據(jù)挖掘至少具有三大特征:
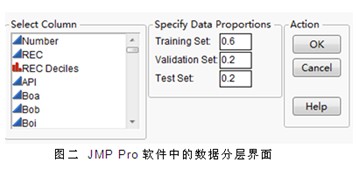
1. 強調(diào)分析建模之前的數(shù)據(jù)源劃分,一般需要將所有原始數(shù)據(jù)分為模型訓(xùn)練數(shù)據(jù)training data、模型驗證數(shù)據(jù)validation data、模型測試數(shù)據(jù)test data三類。從而從源頭上確保了由此求得的模型是經(jīng)得起現(xiàn)實復(fù)雜情況的嚴(yán)峻考驗。
2. 提供了豐富的建模手段,除了基于最小二乘法、逐步法和Logistic法等傳統(tǒng)的回歸分析之外,還包括很多新穎又實用的建模技術(shù),如:決策樹(Decision Tree)、神經(jīng)網(wǎng)絡(luò)(Neural Network)、關(guān)聯(lián)規(guī)則(Association Rule)、支持向量機(Support Vector Machine)、文本挖掘(Text Mining)等。這使我們在遇到回歸分析失效的情況下,依然具備解決問題的能力。
3.“模型比較(Model Comparison)”是數(shù)據(jù)挖掘后期的過程中必不可少的一個環(huán)節(jié),這樣一來,我們就可以科學(xué)、客觀地從不同的候選模型中找到最理想的模型來做最精準(zhǔn)的預(yù)測分析,將預(yù)測誤差降低到***。
顯然,數(shù)據(jù)挖掘的這三個特征有效地彌補了回歸分析的不足,為我們的建模預(yù)測工作奠定了扎實的基礎(chǔ)。下面用一個真實案例來說明從回歸分析到數(shù)據(jù)挖掘的實際應(yīng)用,出于數(shù)據(jù)安全性的考慮,核心數(shù)據(jù)(包括變量名稱)已做了相應(yīng)的編碼處理。
某知名鋼鐵公司的研發(fā)部門在一個構(gòu)建結(jié)構(gòu)鋼端淬曲線預(yù)測模型的項目中,先用用SAS公司面向普通工程師和科學(xué)家開發(fā)的交互式可視化統(tǒng)計發(fā)現(xiàn)軟件JMP中的逐步回歸做了一個預(yù)測模型(見下圖)。
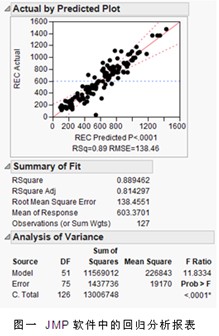
從分析報告上來看,這個預(yù)測模型還是不錯的。但在模型的推廣過程中,多次發(fā)現(xiàn)預(yù)測誤差很大,甚至嚴(yán)重動搖了技術(shù)人員應(yīng)用統(tǒng)計建模的信心。所幸在權(quán)威咨詢機構(gòu)的指導(dǎo)下,發(fā)現(xiàn)造成模型預(yù)測失誤的主要原因是模型過度擬合,包含了很多不必要擬合的噪聲信息。項目成員重新思考了技術(shù)攻關(guān)中需要用到的方法論,最終決定升級到高級版JMP Pro,沒有多做一次現(xiàn)場實驗,沒有申請任何額外預(yù)算,卻顯著改善了模型的預(yù)測效果,達到了預(yù)期效果。
從技術(shù)細(xì)節(jié)上來看,項目后期與前期的不同之處也恰巧體現(xiàn)了前面所介紹的數(shù)據(jù)挖掘的三大特征,即:
***,沒有囫圇吞棗地把所有數(shù)據(jù)全都用來構(gòu)建模型,而是有計劃地按照一定比例將所有數(shù)據(jù)分為訓(xùn)練數(shù)據(jù)、驗證數(shù)據(jù)、測試數(shù)據(jù)三類,各類數(shù)據(jù)各司其職,確保由此產(chǎn)生的模型在生產(chǎn)階段的有效性。
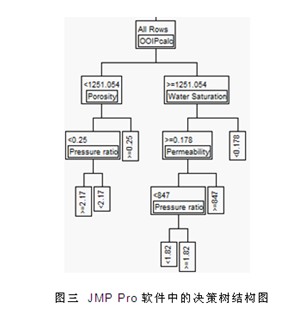
第二,開拓思路,有機地運用除了回歸分析之外的多種數(shù)據(jù)挖掘建模工具,如決策樹、神經(jīng)網(wǎng)絡(luò),以及其衍生工具(如隨機森林Bootstrap Forest、提升樹Boosted Tree等),避免了由于單一方法的生搬硬套而導(dǎo)致的建模錯誤。
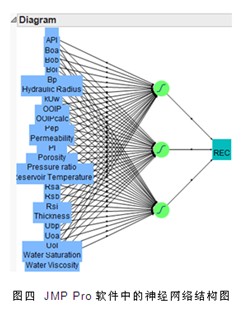
第三,先松后緊,整合之前求得的各個候選模型,將科學(xué)嚴(yán)謹(jǐn)?shù)慕y(tǒng)計量化指標(biāo)與實際業(yè)務(wù)經(jīng)驗相結(jié)合,挑選出整體上最合適的預(yù)測模型,體現(xiàn)了“博采眾長,取長補短”的建模理念。

總之,“從回歸分析到數(shù)據(jù)挖掘”是企業(yè)在精細(xì)化管理發(fā)展到一定階段后必定會遇到的一個問題。當(dāng)然,相對于傳統(tǒng)的回歸分析,數(shù)據(jù)挖掘會顯得相對復(fù)雜一些。但是,融合先進算法而關(guān)注界面友好的現(xiàn)代化統(tǒng)計分析軟件(如案例中用到的JMP Pro軟件),已經(jīng)大大降低了數(shù)據(jù)挖掘的技術(shù)門檻,使得無論是科班出身的統(tǒng)計學(xué)家,還是沒有統(tǒng)計學(xué)功底的普通技術(shù)人員,都能快速上手,真正地數(shù)據(jù)中挖掘出對企業(yè)運營有益的信息。