0到1再到100 蘑菇街搜索與推薦架構的探索之路
原創【51CTO.com原創稿件】丁小明,花名小寶,蘑菇街搜索技術團隊負責人。2011年底加入蘑菇街,2013年開始負責搜索團隊,見證了蘑菇街一路蓬勃發展的歷程,也和團隊一起從零起步摸爬滾打,打造了蘑菇街的搜索推薦體系,包括自主研發的C++主搜引擎和廣告引擎、實時個性化推薦系統、基于開源Solr/ES深度定制的實時搜索平臺等。

小寶·蘑菇街搜索技術團隊負責人
以下內容根據小寶老師在WOTA2017 “電商大促背后的技術挑戰”專場的演講內容整理。
我將和大家分享蘑菇街在搜索推薦上踩過的坑及在探索路上的經驗總結。我們的經驗雖算不上業界最佳實踐,但也是一步步從0到1再到100,希望大家可以從中得到一些收獲。
搜索架構的探索之當前現狀

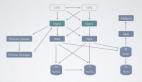
蘑菇街搜索當前架構
如上圖,是蘑菇街當前搜索架構,分為在線和離線兩部分。在線部分主要職責是處理在線的搜索請求。離線部分的主要職責是處理數據流。

在線請求鏈路
如上圖,是整個在線請求鏈路,主要分為topn->qr->引擎->精排->透出五個環節。
第一步,請求首先進入topn系統,做ab配置/業務請求鏈路配置。
第二步,請求進入QR改寫系統做切詞,同義詞擴展,類目相關性,插件化等。
第三步,進入UPS用戶個性化數據存儲系統。
第四步,投放層得到UPS和QR兩部分的數據后,放入搜索引擎做召回。搜索主要會經過一輪海選,海選的依據是文本相關性和商品質量,這樣做是為確保召回的商品質量大致可靠。之后會經過多輪初選,過程中會應用到更復雜的算法模型,對海選的結果進行排序。搜索引擎得到粗排的結果約千級別。
第五步,粗排結果進入到精排系統,精排系統主要通過算法,做個性化排序、實時預測,精排和引擎類似,也支持多輪排序。經過精排系統之后,最終把結果透出給業務層。
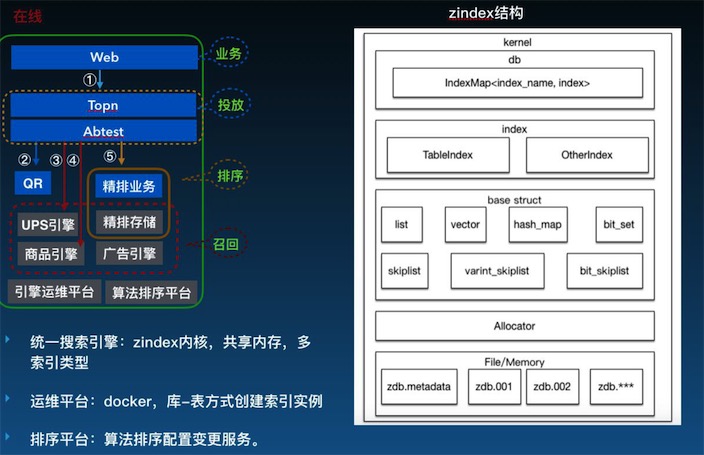
蘑菇街統一引擎系統
如上圖,左側紅色框內是蘑菇街統一引擎系統,包含用戶個性化存儲系統、精排存儲、商品引擎、廣告引擎等。由于這樣的形式維護成本特別高,故做了右圖這個統一的Zindex內核架構。這個架構的最底層是共享內存分配器,再上層是可支持不同數據結構的各種引擎,再上層是索引管理。基于這個架構,不同的引擎可根據各自需求去創建自己的索引。
跟這個架構相關的,就是我們的運維平臺,是基于公司Docker虛擬化技術做的一個運維平臺,能夠非常快的支持索引創建,包括創建之后整個索引數據的管理。還有就是排序平臺,用來提供算法配置變更服務。

搜索架構離線部分的數據流程
如上圖,是離線的數據流程的情況,主要職責是數據流的處理,完整的索引數據分為算法數據和業務數據。
算法數據參與排序,整個鏈路從最前端ACM打點、再落到整個數據倉庫、經過清洗之后,在數據平臺上跑訓練腳本,得出的特征導到特征平臺,再同步到線上。
業務數據的主要來源就是DB,DB中主要存儲商品、店鋪之間的數據,業務變更主要基于mysql bin-log事件監聽,變更之后做全量和增量。全量每天定時索引操作、增量會流到MQ,再通過業務拼裝推到線上。
搜索架構的探索之演變歷程
蘑菇街搜索架構主要經歷導購時期(~2013.11)、電商初期(2013.11~2014.11)、Solr主搜(2015.4~2016.3)、C++主搜(2015.8~2016.11)、平臺化(2017.1~now)五大階段。

蘑菇街搜索架構現狀簡化版
為了更清晰直觀進行對比,我把當前搜索架構簡化成如上圖所示的業務、投放、排序、召回、數據流五大層。接下來我們來看看,我們從最早期,都經歷哪些演變,一步步走到現在。

蘑菇街搜索架構導購時期架構
如上圖,是~2013.11導購時期的架構,有用到放在PHP代碼里的業務+投放、用Java搜索引擎Solr做的召回+排序和數據流三層。這個時期,排序需求不是很迫切,更多側重的是商品整體的豐富度和新穎度。簡單理解,熱銷排序等于喜歡乘10加上收藏乘50,基于Solr的改造來實現。
在電商轉型初期(2013.11~2014.11),由于賣自己的商品,流量變得更值錢了,工程師會想法設法去提升流量的效率。同時用戶行為也在增加,產生更多的數據。還有增量管理復雜,數據量大、Optimaize風險大、導購、廣告和搭配等多類型商品透出等等。其中最明顯挑戰就是排序特征變多、數據變大、次數頻繁。

蘑菇街搜索架構轉型初期架構
面對這些挑戰,當時的思路是把算法獨立成單獨Java工程做算分,但百萬商品百種排序,算法排序達G級別,這些排序數據需要作用于搜索引擎,快速生效,問題是用增量的方式會引來索引碎片的增加,會給線上引擎穩定性帶來波動。故另辟蹊徑,用在Solr進程中設置堆外內存來管理這部分排序數據。
總結來說,轉型初期整體的解決方案就是把算法獨立出來單獨去做,把部分分數盡快同步到引擎,進行生效。這樣的方法,當時線上效果很顯著,但隨時間推移又有新問題出來:
- 規則排毒->LTR,算法排序需求多;
- 排序靈活性制約:計算好的分數離線推送到Solr;
- Solr內存壓力:GC/段合并;
- 靜態分,相關性差;
- 大促相關性問題:搜索“雨傘”,雨傘圖案的連衣裙會排在前面;

Solr主搜整體架構
針對這些新問題,(2015.4)Solr主搜改造,支持Rank插件(Ranker->Scorer),配置化+動態化,整體架構如上圖。應對相關性問題,新增QR系統、應對內存壓力,做Solr升級(Docvalues),算法分走動態字段增量,同時投放方式也漸漸形成Topn系統,對外對接不同的搜索場景。
Solr架構解決相關性、算法變更線上排序等問題,但新問題在于雖用機器學習的排序做法,但那個時期主要是爆款模型,有很多個性化需求模型同時對不同人要有不同的排序結果,還有一些重排序或打散等更加復雜的需求。因Solr實現機制的限制,只能做一輪排序,想要改動比較難。另外,Solr整個索引結構非常復雜,二次開發成本高,內存、性能上也慢慢地暴露出很多問題,同時還有Java的GC也是不可逾越的鴻溝。
當時多輪排序的需求,除了做一些文本相關性,還相對商品做品牌加權,如想扶持某些品牌、做類目打散等,這些在單輪排序內做不到,原來的方式只能把多輪融合在一個排序中搞定,但效果會很差。

C++主搜架構
如上圖,是C++主搜架構(2015.8~2016.11)上線,在整個性能和排序方面做了定制,可支持多輪排序、整個內存采用內存方式,由排序體系支撐。這個階段整體來看,相對是完善的,每層,整個系統都成型,可數據流環節又出現了三個問題:
- 全量無調度,都要依靠流程制約
- 增量帶來算法分數不可比,會帶來一些線上排序的抖動
- 業務數據增量對服務接口壓力過大(促銷故障)

全量的整個鏈路
如上圖,是全量的整個鏈路,算法序列的整個鏈路靠時間約定,數據容災機制弱。所以大促時,前置任務延遲全量做不了,線上內存幾乎撐爆,經常性全量延時,必須手動去處理。還有算法誤導排序分,導致線上錯亂,增量恢復時間長。
要解決這個問題,我們首要引入一個基于Zookeeper的調度系統,把整個數據流驅動起來同時支持錯誤報警。容災部分的思路就是增加排序SOS字段、基于HBase定期生成全量快照,快速回檔、單算法字段修復等。
兩次算法增量分數不可比,增量生效特別慢。如時刻1算出商品是90分,時刻2是60分,就會引起線上排序抖動,主要因算法兩次序列導致整個數據分布不同,特別到大促時期,不同時段成交數據變化特別快,商品排序的波動非常明顯,增量數據同一批正常,但兩次見就會出錯。當0點大家在瘋狂購物的時候,變更非常頻繁,會導致排序錯亂。算法數據出錯后,生效時間也會比較慢。

如上圖,我們的解決方案是通過小全量的方式把算法、分數單獨拖到線上引擎本地,在引擎本地依次一次加載,直接切換的方式,讓每一次算法增量數據的數據加速生效,容災也會加快。

如上圖,由于變更都是Doc級更新,每一個字段更新都會調用所有的接口去拼裝成一條完整的數據去更新,這導致業務增量壓力特別大。大促期間,增量QPS可以達到幾千~上萬,對下游40多個接口的壓力非常大。

如上圖,這個問題解決的思路是讓引擎,包括數據流支持字段更新。只拼裝變更字段、不需要拼裝完整的數據,這需要引擎本身支持才能做到。當時上線,收益非常明顯,關鍵接口QPS減少80%以上。
平臺化(2017.1~now)是現在正在做的事情。面對UPS、廣告、商品多套引擎系統與廣告、搜索多套投放系統分別從不同團隊合并過來, 維護成本問題。排序計算需求變得更加復雜,嘗試用非線性模型等方面挑戰,就有了現在整理的架構,思路就是平臺化、統一化,把重復的系統整合、數據流做統一。
搜索架構的探索之經驗總結
這一路走來,整個搜索架構的探索經驗就是在發展前期要簡單快速支持線上業務,之后在逐步演變,來滿足算法的需求,最后在考慮整個利用平臺化、統一化的思路去提升效率,降低成本。
不同階段要有不同的選擇,我們最早基于Solr改寫,待團隊、人員,包括技術儲備上也有實力后,直接重寫搜索引擎,覆蓋算法的離線、在線鏈路,做體系化建設。
我們的后續規劃是新架構整體平臺化繼續深入,算法方面加強學習,如深度學習、在線學習等。如深度學習框架的研究和使用,以及圖搜工程體系的建設。
推薦架構的探索之發展概述
蘑菇街的推薦架構已經覆蓋大部分的用戶行為路徑,從使用進入APP,到下單成交完成都會有推薦場景出現。推薦架構的整個發展分為發展早期(2103.11~2015.6)、1.0時期:從0到1(2015.6~2016.3)、2.0:投放+個性化(2016.3~2016.12)、3.0:平臺化(2016.2~now)四大階段。
發展早期(2103.11~2015.6)推薦的場景并不多,需求也比較簡單,數據離線更新到Redis就好,當時明顯的問題是沒有專門的推薦系統來承載推薦場景、效果跟蹤差、場景對接、數據導入等效率低等。

1.0時期的推薦架構
1.0時期:從0到1(2015.6~2016.3)把推薦系統搭建起來,包含Service層對接場景、推薦實時預測、自寫的K-V的系統用來存儲推薦結果。這里踩的一個坑是,把實時預測做到離線部分,但其實實時預測更多的是在線流程。
隨著時間推移,場景類型(猜你喜歡、搜相似、店鋪內)、相似場景(首頁、購物車、詳情頁…)不斷增加,算法方面需要實時排序,應對實時的點擊、加購等,還有一些個性化排序需求,如店鋪、類目、離線偏好等。1.0階段主要面臨三大問題:
- 多類型多場景:上線系統不一,缺少統一對接層,成本高;
- 場景配置化:場景算法一對一,重復代碼拷貝,維護難;
- 個性化+實時:缺系統支持;

2.0時期的推薦架構
如上圖,2.0時期的推薦架構(2016.3~2016.12)主要解決1.0的三大問題,增加投放層Prism,統一對外對接不同的業務場景,對Prism做動態配置和規則模板。個性化實時方面增加UPS與精排系統。

2.0時期推薦架構投放層配置化
如上圖,2.0時期推薦架構投放層配置化思路是把不變的部分模板化,可變的部分配置化。系統提供召回組建、數據補全、格式化等模板。當時效果很明顯,321大促運營位置個性化效果提升20%+,雙11大促,會場樓層個性化提升100%+。
大促帶來的巨大收益,給整個系統帶來很正面的影響,后續推薦架構又面臨更多的需求與挑戰:
- 日益增長的資源位、直播、圖像等場景和類型;
- 跟美的融合,跨團隊跨地域的挑戰;
- 工程算法用一套代碼,整個策略的開發調試都非常復雜,包括工程部分的職責不清問題;
- 由于原來模板化的配置,導致一些簡單場景復雜化。
針對這些問題,我們需要做的事情就是通用化、平臺化。針對整套系統進行統一推薦方案,自動化整體算法對接核心業務流程、以及和算法人員的職責劃分清晰,提升雙方的工作效率。

3.0時期推薦架構
3.0時期推薦架構 (2016.2~now)與搜索架構類似,系統間職能更加明晰,統一和平臺化,主要還是投放層做了改造。

3.0時期推薦架構投放層細節
如上圖, 3.0時期推薦架構投放層重要的概念就是場景化,場景應對推薦業務,不同場景會對應不同的策略實現。
推薦架構的探索之總結
推薦架構前期,也和搜索架構一樣,需要快速支持推薦業務,不需要花費大量精力去搭建非常復雜的系統。滿足業務、算法等需求后,才是平臺化提升算法、工程雙方的效率。后續平臺化繼續深入,如針對算法策略的評測和壓測工具方面,全場景智能監控報警&容災。算法支持方面,就是OnlineLearning&強化學習,根據算法效果來設計新產品。
更多細節,請觀看演講視頻:http://edu.51cto.com/course/course_id-9255.html
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】