













主搜索與店鋪內搜索聯合優化的初步探索與嘗試
原創背景與簡介
在淘寶平臺上有非常多的子場景,例如搜索、推薦、廣告。每個子場景又有非常多細分,例如搜索包括默認排序、店鋪內搜索、店鋪搜索等;推薦內有猜你喜歡、今日推薦、每日好店等。基于數據驅動的機器學習和優化技術目前大量的應用于這些場景中,并已經取得了不錯的效果——在單場景內的A/B測試上,點擊率、轉化率、成交額、單價都能看到顯著提升。 然而,目前各個場景之間是完全獨立優化的,這樣會帶來幾點比較嚴重的問題:
a. 用戶在淘寶上購物會經常在多個場景之間切換,例如:從主搜索到猜你喜歡,從猜你喜歡到店鋪內。不同場景的商品排序僅考慮自身,會導致用戶的購物體驗是不連貫或者雷同的。例如:從冰箱的詳情頁進入店鋪,卻展示手機;各個場景都展現趨同,都包含太多的U2I(點擊或成交過的商品)。
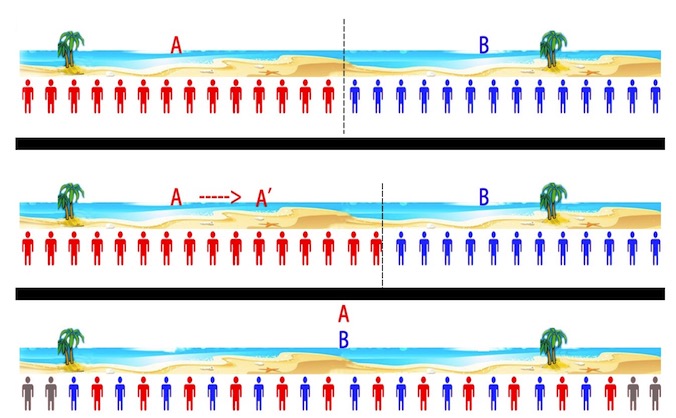
b. 多場景之間是博弈(競爭)關系,期望每個場景的提升帶來整體提升這一點是無法保證的。很有可能一個場景的提升會導致其他場景的下降,更可怕的是某個場景帶來的提升甚至小于其他場景更大的下降。這并非是不可能的,那么這種情況下,單場景的A/B測試就顯得沒那么有意義,單場景的優化也會存在明顯的問題。因為這一點尤為重要,因此我們舉一個更簡單易懂的例子,如下圖。
一個1000米長的沙灘上有2個飲料攤A和B,沙灘上均分分布者很多游客,他們一般會找更近的飲料攤去買飲料。最開始A和B分別在沙灘250米和750米的位置,此時沙灘左邊的人會去A買,右邊的人去B買。然后A發現,自己往右邊移動的時候,會有更多的用戶(A/B測試的結論),因此A會右移,同樣B會左移。A和B各自‘優化’下去,***會都在沙灘中間的位置,從博弈論的角度,到了一個均衡點。然而,***‘優化’得到的位置是不如初始位置的,因為會有很多游客會因為太遠而放棄買飲料。這種情況下,2個飲料攤各自優化的結果反而是不如不優化的。
多場景問題實際并不止存在于淘寶上,目前比較大型的平臺或者無線APP都不止一個場景。即使不談Yahoo,Sina等綜合性網站,像Baidu、Google等功能比較單一、集中的應用,也會有若干場景(如網頁、咨詢、地圖等)。那么這些平臺或應用都會面臨類似的問題。 綜上,研究大型在線平臺上的多子場景聯合優化,無論從淘寶平臺的應用上,還是從科研的角度,都具有重要意義。
為了解決上述的問題,本文提出一個多場景聯合排序算法,旨在提升整體指標。我們將多場景的排序問題看成一個完全合作的、部分可觀測的多智能體序列決策問題,利用Multi-Agent Reinforcement Learning的方法來嘗試著對問題進行建模。
該模型以各個場景為Agent,讓各個場景不同的排序策略共享同一個目標,同時在一個場景的排序結果會考慮該用戶在其他場景的行為和反饋。這樣使得各個場景的排序策略由獨立轉變為合作與共贏。由于我們想要使用用戶在所有場景的行為,而DRQN中的RNN網絡可以記住歷史信息,同時利用DPG對連續狀態與連續動作空間進行探索,因此我們算法取名MA-RDPG(Multi-Agent Recurrent Deterministic Policy Gradient)。
系統總覽
傳統的單場景優化
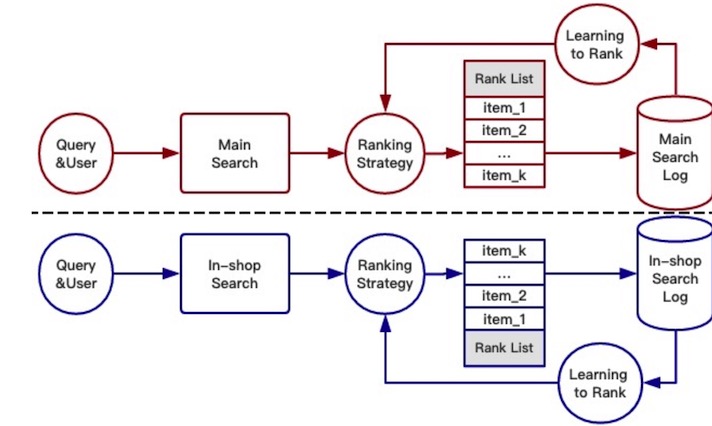
目前,單場景排序策略的大體結構如下,每個商品用一組特征來表示<人氣分,ctr分……>,排序策略通過給出一組特征權重來決定排序的結果,商品的分數即為各個特征的加權相加。主搜索和店鋪內搜索都有自己的排序策略,獨立優化,互不影響。
多場景聯合優化

目前,單場景排序策略的大體結構如下,每個商品用一組特征來表示<人氣分,ctr分……>,排序策略通過給出一組特征權重來決定排序的結果,商品的分數即為各個特征的加權相加。主搜索和店鋪內搜索都有自己的排序策略,獨立優化,互不影響。























