大數(shù)據(jù)工具比較:R語(yǔ)言和Spark 誰(shuí)更勝一籌?

背景介紹
由于R語(yǔ)言本身是單線程的,所以可能從性能方面對(duì)比Spark和R并不是很明智的做法。即使這種比較不是很理想,但是對(duì)于那些曾經(jīng)遇到過這些問題的人,下文中的一些數(shù)字一定會(huì)讓你很感興趣。
你是否曾把一個(gè)機(jī)器學(xué)習(xí)的問題丟到R里運(yùn)行,然后等上好幾個(gè)小時(shí)?而僅僅是因?yàn)闆]有可行的替代方式,你只能耐心地等。所以是時(shí)候去看看Spark的機(jī)器學(xué)習(xí)了,它包含R語(yǔ)言大部分的功能,并且在數(shù)據(jù)轉(zhuǎn)換和性能上優(yōu)于R語(yǔ)言。
曾經(jīng)我嘗試過利用不同的機(jī)器學(xué)習(xí)技術(shù)——R語(yǔ)言和Spark的機(jī)器學(xué)習(xí),去解決同一個(gè)特定的問題。為了增加可比性,我甚至讓它們運(yùn)行在同樣的硬件環(huán)境和操作系統(tǒng)上。并且,在Spark中運(yùn)行單機(jī)模式,不帶任何集群的配置。
在我們討論具體細(xì)節(jié)之前,關(guān)于Revolution R 有個(gè)簡(jiǎn)單的說(shuō)明。作為R語(yǔ)言的企業(yè)版,Revolution R試圖彌補(bǔ)R語(yǔ)言單線程的缺 陷。但它只能運(yùn)行在像Revolution Analytics這樣的專有軟件上,所以可能不是理想的長(zhǎng)期方案。如果想獲得微軟 Revolution Analytics軟件的擴(kuò)展,又可能會(huì)讓事情變得更為復(fù)雜,比方說(shuō)牽扯到許可證的問題。
因此,社區(qū)支持的開源工具,像是Spark,可能成為比R語(yǔ)言企業(yè)版更好的選擇。
數(shù)據(jù)集和問題
分析采用的是Kaggle網(wǎng)站 [譯者注:Kaggle是一個(gè)數(shù)據(jù)分析的競(jìng)賽平臺(tái),網(wǎng)址:https://www.kaggle.com/]上的數(shù)字識(shí)別器的數(shù)據(jù)集,其中包含灰度的手寫數(shù)字的圖片,從0到9。
每張圖片高28px,寬28px,大小為784px。每個(gè)像素都包含關(guān)于像素點(diǎn)明暗的值,值越高代表像素點(diǎn)越暗。像素值是0到255之間的整數(shù),包括0和255。整張圖片包含***列在內(nèi)共有785列數(shù)據(jù),稱為“標(biāo)記”,即用戶手寫的數(shù)字。
分析的目標(biāo)是得到一個(gè)可以從像素?cái)?shù)值中識(shí)別數(shù)字是幾的模型。
選擇這個(gè)數(shù)據(jù)集的論據(jù)是,從數(shù)據(jù)量上來(lái)看,實(shí)質(zhì)上這算不上是一個(gè)大數(shù)據(jù)的問題。
對(duì)比情況
針對(duì)這個(gè)問題,機(jī)器學(xué)習(xí)的步驟如下,以得出預(yù)測(cè)模型結(jié)束:
-
在數(shù)據(jù)集上進(jìn)行主成分分析和線性判別式分析,得到主要的特征。(特征工程的步驟)[譯者注:百度百科傳送門,主成分分析、線性判別式分析]。
-
對(duì)所有雙位數(shù)字進(jìn)行二元邏輯回歸,并且根據(jù)它們的像素信息和主成分分析以及線性判別式分析得到的特征變量進(jìn)行分類。
-
在全量數(shù)據(jù)上運(yùn)行多元邏輯回歸模型來(lái)進(jìn)行多類分類。根據(jù)它們的像素信息和主成分分析以及線性判別式分析的特征變量,利用樸素貝葉斯分類模型進(jìn)行分類。利用決策樹分類模型來(lái)分類數(shù)字。
在上述步驟之前,我已經(jīng)將標(biāo)記的數(shù)據(jù)分成了訓(xùn)練組和測(cè)試組,用于訓(xùn)練模型和在精度上驗(yàn)證模型的性能。
大部分的步驟都在R語(yǔ)言和Spark上都運(yùn)行了。詳細(xì)的對(duì)比情況如下,主要是對(duì)比了主成分分析、二元邏輯模型和樸素貝葉斯分類模型的部分。
主成分分析
主成分分析的主要計(jì)算復(fù)雜度在對(duì)成分的打分上,邏輯步驟如下:
-
通過遍歷數(shù)據(jù)以及計(jì)算各列的協(xié)方差表,得到KxM的權(quán)重值。(K代表主成分的個(gè)數(shù),M代表數(shù)據(jù)集的特征變量個(gè)數(shù))。
-
當(dāng)我們對(duì)N條數(shù)據(jù)進(jìn)行打分,就是矩陣乘法運(yùn)算。
-
通過NxM個(gè)維度數(shù)據(jù)和MxK個(gè)權(quán)重?cái)?shù)據(jù),***得到的是NxK個(gè)主成分。N條數(shù)據(jù)中的每一條都有K個(gè)主成分。
在我們這個(gè)例子中,打分的結(jié)果是42000 x 784的維度矩陣與784 x 9的矩陣相乘。坦白說(shuō),這個(gè)計(jì)算過程在R中運(yùn)行了超過4個(gè)小時(shí),而同樣的運(yùn)算Spark只用了10秒多
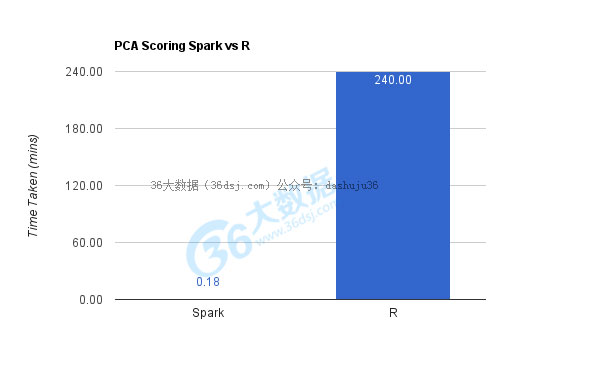
矩陣相乘差不多是3億次運(yùn)算或者指令,還有相當(dāng)多的檢索和查找操作,所以Spark的并行計(jì)算引擎可以在10秒鐘完成還是非常令人驚訝的。
我通過查看前9個(gè)主成分的方差,來(lái)驗(yàn)證了所產(chǎn)生的主成分的精度。方差和通過R產(chǎn)生的前9個(gè)主成分的方差吻合。這一點(diǎn)確保了Spark并沒有犧牲精度來(lái)?yè)Q取性能和數(shù)據(jù)轉(zhuǎn)換上的優(yōu)勢(shì)。
邏輯回歸模型
與主成分分析不同的是,在邏輯回歸模型中,訓(xùn)練和打分的操作都是需要計(jì)算的,而且都是極其密集的運(yùn)算。在這種模型的通用的數(shù)據(jù)訓(xùn)練方案中包含一些對(duì)于整個(gè)數(shù)據(jù)集矩陣的轉(zhuǎn)置和逆運(yùn)算。
由于計(jì)算的復(fù)雜性,R在訓(xùn)練和打分都需要過好一會(huì)兒才能完成,準(zhǔn)確的說(shuō)是7個(gè)小時(shí),而Spark只用了大概5分鐘。
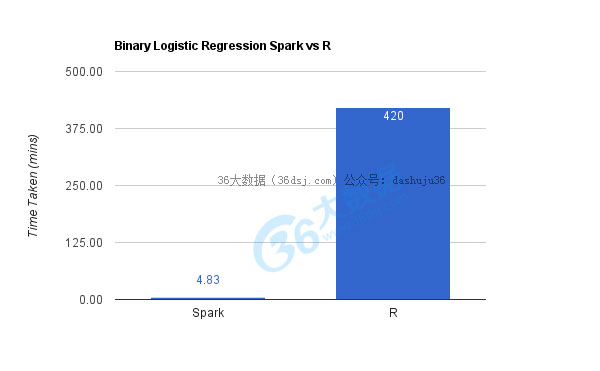
這里我在45個(gè)從0到9的雙位數(shù)字上運(yùn)行了二元邏輯回歸模型,打分/驗(yàn)證也是在這45個(gè)測(cè)試數(shù)據(jù)上進(jìn)行的。
我也并行執(zhí)行了多元邏輯回歸模型,作為多類分類器,大概3分鐘就完成了。而這在R上運(yùn)行不起來(lái),所以我也沒辦法在數(shù)據(jù)上進(jìn)行對(duì)比。
對(duì)于主成分分析,我采用AUC值 [譯者注: AUC的值就是計(jì)算出ROC曲線下面的面積,是度量分類模型好壞的一個(gè)標(biāo)準(zhǔn)。] 來(lái)衡量預(yù)測(cè)模型在45對(duì)數(shù)據(jù)上的表現(xiàn),而Spark和R兩者運(yùn)行的模型結(jié)果的AUC值差不多。
樸素貝葉斯分類器
與主成分分析和邏輯回歸不一樣的是,樸素貝葉斯分類器不是密集計(jì)算型的。其中需要計(jì)算類的先驗(yàn)概率,然后基于可用的附加數(shù)據(jù)得到后驗(yàn)概率。[譯者注:先驗(yàn)概率是指根據(jù)以往經(jīng)驗(yàn)和分析得到的概率,它往往作為”由因求果”問題中的”因”出現(xiàn)的概率;后驗(yàn)概率是指在得到“結(jié)果”的信息后重新修正的概率,是“執(zhí)果尋因”問題中的”果”。]
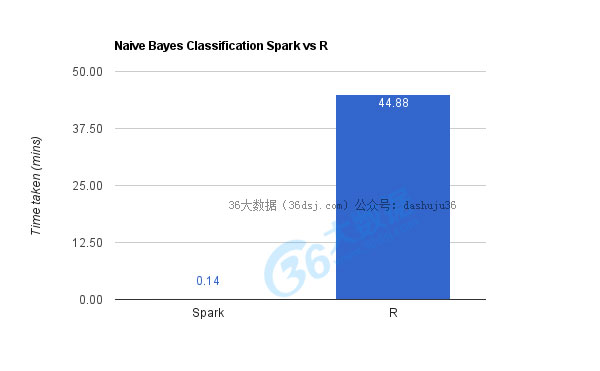
如上圖所示,R大概花了45余秒完成,而Spark只用了9秒鐘。像之前一樣,兩者的精確度旗鼓相當(dāng)。
同時(shí)我也試著用Spark機(jī)器學(xué)習(xí)運(yùn)行了決策樹模型,大概花了20秒,而這個(gè)在R上完全運(yùn)行不起來(lái)。
Spark機(jī)器學(xué)習(xí)入門指南
對(duì)比已經(jīng)足夠,而這也成就了Spark的機(jī)器學(xué)習(xí)。 ***是從編程指南開始學(xué)習(xí)它。不過,如果你想早點(diǎn)嘗試并從實(shí)踐中學(xué)習(xí)的話,你可能要痛苦一陣子才能將它運(yùn)行起來(lái)吧。
為搞清楚示例代碼并且在數(shù)據(jù)集上進(jìn)行試驗(yàn),你需要先去弄懂Spark的RDD [譯者注:RDD,Resilient Distributed Datasets,彈性分布式數(shù)據(jù)集] 支持的基本框架和運(yùn)算。然后也要弄明白Spark中不同的機(jī)器學(xué)習(xí)程序,并且在上面進(jìn)行編程。當(dāng)你的***個(gè)Spark機(jī)器學(xué)習(xí)的程序跑起來(lái)的時(shí)候,你可能就會(huì)意興闌珊了。
以下兩份資料可以幫你避免這些問題,同時(shí)理順學(xué)習(xí)的思路:
-
Spark機(jī)器學(xué)習(xí)所有的源代碼,可提供任何人拿來(lái)與R語(yǔ)言作對(duì)比:
https://github.com/vivekmurugesan/experiments/tree/master/spark-ml
-
Docker容器的源代碼,Spark和上述項(xiàng)目的包已預(yù)置在內(nèi),以供快速實(shí)施:
https://hub.docker.com/r/vivekmurugesan/spark-hadoop/ Docker容器中已事先安裝Apache Hadoop,并且在偽分布式環(huán)境下運(yùn)行。這可以將大容量文件放進(jìn)分布式文件系統(tǒng)來(lái)測(cè)試Spark。通過從分布式文件系統(tǒng)加載記錄,可以很輕松地來(lái)創(chuàng)建RDD實(shí)例。
產(chǎn)能和精度
人們會(huì)使用不同的指標(biāo)來(lái)衡量這些工具的好壞。對(duì)我來(lái)說(shuō),精準(zhǔn)度和產(chǎn)能是決定性的因素。
大家總是喜歡R多過于Spark機(jī)器學(xué)習(xí),是因?yàn)榻?jīng)驗(yàn)學(xué)習(xí)曲線。他們最終只能選擇在R上采用少量的樣本數(shù)據(jù),是因?yàn)镽在大數(shù)據(jù)量的樣本上花了太多時(shí)間,而這也影響了整個(gè)系統(tǒng)的性能。
對(duì)我來(lái)說(shuō),用少量的樣本數(shù)據(jù)是解決不了問題的,因?yàn)樯倭繕颖靖敬聿涣苏w(至少在大部分情況下是這樣)。所以說(shuō),如果你使用了少量樣本,就是在精度上選擇了妥協(xié)。
一旦你拋棄了少量樣本,就歸結(jié)到了生產(chǎn)性能的問題。機(jī)器學(xué)習(xí)的問題本質(zhì)上就是迭代的問題。如果每次迭代都花費(fèi)很久的話,那么完工時(shí)間就會(huì)延長(zhǎng)。可是,如果每次迭代只用一點(diǎn)時(shí)間的話,那么留給你敲代碼的時(shí)間就會(huì)多一些了。
結(jié)論
R語(yǔ)言包含了統(tǒng)計(jì)計(jì)算的庫(kù)和像ggplot2這樣可視化分析的庫(kù),所以它不可能被完全廢棄,而且它所帶來(lái)的挖掘數(shù)據(jù)和統(tǒng)計(jì)匯總的能力是毋庸置疑的。
但是,當(dāng)遇到在大數(shù)據(jù)集上構(gòu)建模型的問題時(shí),我們應(yīng)該去挖掘一些像Spark ML的工具。Spark也提供R的包,SparkR可以在分布式數(shù)據(jù)集上應(yīng)用R。
***在你的“數(shù)據(jù)軍營(yíng)”中多放點(diǎn)工具,因?yàn)槟悴恢涝?ldquo;打仗”的時(shí)候會(huì)遇到什么。因此,是時(shí)候從過去的R時(shí)代邁入Spark ML的新時(shí)代了。
原文:Tools in the data armoury: R vs Spark