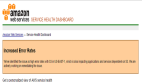
AWS美國東部地區服務遭遇嚴重故障
CloudWatch、SES、SNS、SQS、SWS、AutoScale、Cloud Formation、Directory Service、密鑰管理和Lambda這些服務出現了非常高的錯誤率。
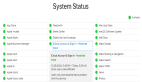
***消息:截至美國東部時間9月20日中午11:50,大多數服務似乎已恢復如初,AWS服務儀表板顯示上面全是綠色。
Dynamo DB在限制API的訪問,似乎在管理元數據方面遇到了問題。
主要問題似乎出在DynamoDB上
來自狀態頁面的一份內容如下:
3:00 AM PDT 我們調查美國東部1區API請求錯誤率增加的現象。
3:26 AM PDT 我們繼續看到在美國東部1區,DynamoDB中所有API調用的錯誤率增加。我們在積極主動地竭力解決問題。
4:0***M PDT 我們發現了問題的根源。我們在竭力恢復正常。
4:41 AM PDT 我們繼續竭力解決引起美國東部1區DynamoDB API錯誤率增加的問題,希望恢復正常。
4:52 AM PDT 我們想為你們提供出現的問題方面的更多信息。根源出在我們在DynamoDB里面的一部分元數據服務。這是一種內部子服務,負責管理表和分區信息。我們的恢復工作現在致力于恢復元數據操作。我們在竭力恢復正常的過程中,會限制API。
5:22 AM PDT 我們可以證實,我們在繼續致力于恢復正常的過程中,現在限制了API。
5:42 AM PDT 我們看到元數據服務日益穩定,我們繼續努力爭取盡早可以開始消除限制。
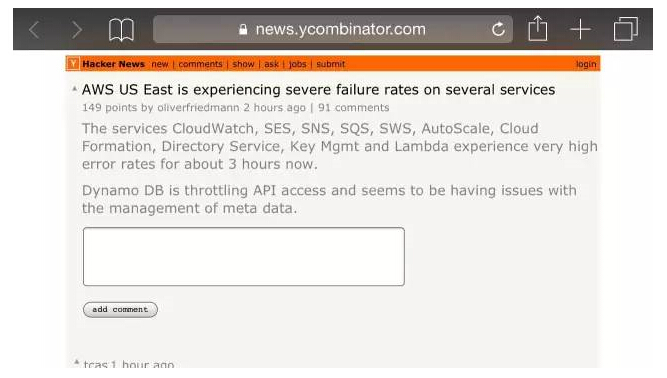
亞馬遜AWS DynamoDB出現停運,殃及Netflix、Reddit、Medium及更多服務
早上好!不知各位有沒有注意到手機上的應用程序沒法正常使用?可能沒法使用Netflix?
那是由于在過去的幾個小時,亞馬遜網絡服務(AWS)遇到了一次大范圍的服務停運事件。
這起事件已影響了Netflix、Product Hunt、Nest、Reddit、Medium、IMDB、Social Flow以及亞馬遜自家的Alexa和Instant Video服務,覆蓋北美東部地區的用戶。
罪魁禍首似乎是亞馬遜位于弗吉尼亞州北部的DynamoDB系統。
屏幕截圖如下:
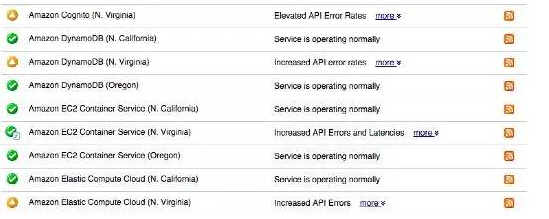
我們VentureBeat網站使用SocialFlow自動發布社交媒體帖子。你可能已注意到,我們社交媒體流中的鏈接點擊后打開的卻是503出錯頁面。但愿亞馬遜盡早解決這個問題。
這對亞馬遜來說可能會是一次代價慘重的失誤。早在2013年,一起類似的停運事件就讓亞馬遜損失慘重:每秒估計損失1100美元。
攤上了網絡服務故障這檔事,不妨走到外面,躺在草地上,想想脆弱的計算機系統對我們的整個現代生活帶來的連鎖效應。