LinkedIn三人小組離職創(chuàng)立Confluent:基于Kafka實(shí)時(shí)信息列隊(duì)系統(tǒng)
LinkedIn有個(gè)三人小組出來(lái)創(chuàng)業(yè)了—正是當(dāng)時(shí)開(kāi)發(fā)出Apache Kafka實(shí)時(shí)信息列隊(duì)技術(shù)的團(tuán)隊(duì)成員,基于這項(xiàng)技術(shù)Jay Kreps帶頭創(chuàng)立了新公司Confluent,致力于為各行各業(yè)的公司提供實(shí)時(shí)數(shù)處理服務(wù)解決方案,其他兩位成員是Neha Narkhede和Jun Rao。該公司已獲Benchmark、LinkedIn、Data Collective 690萬(wàn)美金融資。
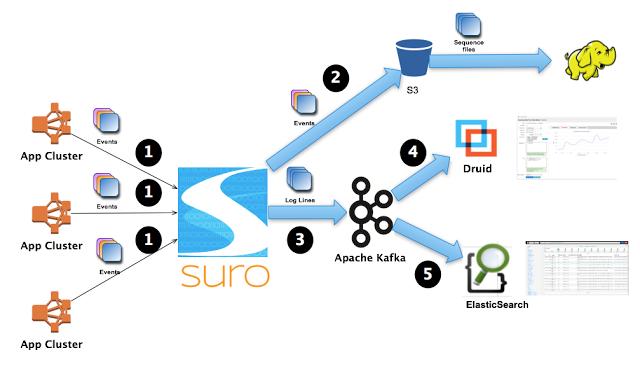
Kreps將Kafka描述為L(zhǎng)inkedIn的“中樞神經(jīng)系統(tǒng)”,管理從各個(gè)應(yīng)用程序匯聚到此的信息流,這些數(shù)據(jù)經(jīng)過(guò)處理后再被分發(fā)到各處。
不同于傳統(tǒng)的企業(yè)信息列隊(duì)系統(tǒng),Kafka是以近乎實(shí)時(shí)的方式處理流經(jīng)一個(gè)公司的所有數(shù)據(jù),目前已經(jīng)為L(zhǎng)inkedIn, Netflix, Uber和Verizon建立了實(shí)時(shí)信息處理平臺(tái)。Confluent的愿景便是讓其他公司也能用上這種平臺(tái)。Confluent已經(jīng)向Kafka用戶(hù)了解了他們的使用模型。現(xiàn)在還沒(méi)有產(chǎn)品出來(lái),但這些實(shí)踐足以啟示Confluent應(yīng)當(dāng)打造何種產(chǎn)品。
Kreps承認(rèn),他最初也懷疑那些非網(wǎng)絡(luò)公司是否會(huì)對(duì)Kafka這樣的技術(shù)感興趣,但當(dāng)他看到金融服務(wù)和電信行業(yè)對(duì)這項(xiàng)技術(shù)的廣泛采用后,Kreps改變了自己的看法。今年三月,去拜訪了一家叫做Synapse Wireless的公司,這家公司使用Kafka來(lái)支持一套傳感器網(wǎng)絡(luò)系統(tǒng),用于追蹤醫(yī)院工作人員的衛(wèi)生習(xí)慣。
因此他認(rèn)為需求是絕對(duì)存在的,Confluent的優(yōu)勢(shì)就在于近乎實(shí)時(shí)性。Kreps認(rèn)為,基于Kafka信息處理技術(shù)建立一家公司,總比基于像Apache Storm這樣的開(kāi)源流處理技術(shù)建立一家公司要靠譜,因?yàn)樾畔⒘嘘?duì)是先進(jìn)數(shù)據(jù)處理架構(gòu)的更基本的組成部分。
他還記得剛加入LinkedIn那會(huì)兒,網(wǎng)站只有批處理系統(tǒng),后來(lái)有了流處理系統(tǒng)后每個(gè)人都別提多開(kāi)心了。再后來(lái),他們意識(shí)到LinkedIn并沒(méi)有支持這一系統(tǒng)的架構(gòu)。
“當(dāng)今大多數(shù)公司之所以與佼佼者存在差距,是因?yàn)樗麄儙缀醪荒軐?shí)時(shí)任何獲取數(shù)據(jù)。”一旦公司找到最對(duì)路的技術(shù)堆棧,它們就有望建立物聯(lián)網(wǎng)或者其它基于傳感器的應(yīng)用程序,再或者是從許多渠道抓取大量數(shù)據(jù)進(jìn)入后端系統(tǒng)的其他業(yè)務(wù)。
“這實(shí)際上是開(kāi)辟了全新的應(yīng)用場(chǎng)景,”Kreps說(shuō)道,“而且是不這么辦就沒(méi)法真正打開(kāi)的場(chǎng)景。”