













谷歌SDN部署經驗:如何漸進部署到現有數據中心
Google 已經將其數據中心廣域網 (WAN) 的設計和部署經驗完整地公之于眾,為什么 Google 要用SDN?如何把 SDN 漸進地部署到現有的數據中心?透過本文,我們能窺見 Google 全球數據中心網絡的冰山一角。
流量的巨大浪費
眾所周知,網絡流量總有高峰和低谷,高峰流量可達平均流量的 2~3 倍。為了保證高峰期的帶寬需求,只好預先購買大量的帶寬和價格高昂的高端路由設備,而平均用量只有 30%~40%。這大大提高了數據中心的成本。
這種浪費是必然的嗎?Google 觀察到,數據中心中的流量是有不同優先級的:
用戶數據拷貝 到遠程數據中心,以保證數據可用性和持久性。這個數據量最小,對延遲最敏感,優先級最高。
遠程存儲訪問 進行 MapReduce 之類的分布式計算。
大規模數據同步 以同步多個數據中心之間的狀態。這個流量最大,對延遲不敏感,優先級最低。
Google 發現高優先級流量僅占總流量的 10%~15%。只要能區分出高優先級和低優先級流量,保證高優先級流量以低延遲到達,讓低優先級流量把空余流量擠滿,數據中心的廣域網連接(WAN link)就能達到接近 100% 的利用率。要做到這個,需要幾方面的配合:
應用(Application)需要提前預估所需要的帶寬。由于數據中心是 Google 自家的,各種服務所需的帶寬都可以預估出來。
低優先級應用需要容忍高延遲和丟包,并根據可用帶寬自適應發送速度。
需要一個中心控制系統來分配帶寬。這是本文討論的重點。
Why SDN?
計算機網絡剛興起時,都是插一根線連到交換機上,手工配置路由規則。在學校機房之類網絡不復雜的情況下,時至如今也是這么做的。但是,只要增加一個新設備,就得鉆進機房折騰半天;如果一個舊設備壞了,就會出現大面積的網絡癱瘓。廣域網絡的維護者們很快就不能忍受了,于是就誕生了分布式、自組織的路由協議,如BGP、ISIS、OSPF 等。
為什么設計成這樣呢?有兩方面原因。首先,七八十年代廣域網絡剛剛興起時,網絡交換設備很不穩定,三天兩頭掛掉,如果是個中心服務器分配資源,那么整個網絡就會三天兩頭癱瘓。其次,Internet 是多家參與的,是 Stanford 愿意聽 MIT 指揮,還是 MIT 愿意聽 Stanford 指揮?
今天,在數據中心里,這兩個問題都不復存在。首先,現在的網絡交換設備和服務器足夠穩定,而且有 Paxos 等成熟的分布式一致性協議可以保證“中心服務器”幾乎不會掛掉。其次,數據中心的規模足夠大,一個大型數據中心可以有 5000 臺交換機(switch),20 萬臺服務器,與七八十年代整個 Internet 的規模已經相當了。數據中心是公司自家的,想怎么搞就怎么搞。
因此,Software Defined Networking (SDN) 應運而生。以 OpenFlow 為代表,SDN 把分散自主的路由控制集中起來,路由器按照 controller 指定的規則對 packet 進行匹配,并執行相應動作。這樣,controller 就可以利用整個網絡的拓撲信息和來自 application 的需求信息計算出一組接近全局最優的路由規則。這種 Centralized Traffic Engineering (TE) 有幾個好處:
使用非最短路的包轉發機制,將應用的優先級納入資源分配的考慮中;
當連接或交換機出現故障,或者應用的需求發生變化時,動態地重新分配帶寬,快速收斂;
在較高的層次上指定規則,例如Gmail 的流量不經過天朝。
#p#
Design
Overview
交換機硬件是 Google 定制的,負責轉發流量,不運行復雜的控制軟件。
OpenFlow Controller (OFC) 根據網絡控制應用的指令和交換機事件,維護網絡狀態。
Central TE Server 是整個網絡邏輯上的中心控制器。
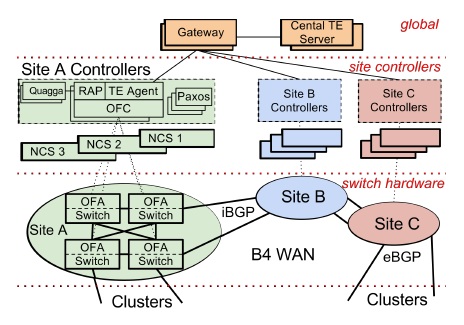
第一條虛線上面是 Central TE (Traffic Engineering) Server。
一二兩條虛線之間是每個數據中心(Site)的控制器,被稱為 Network Control Server (NCS),其上運行著 OpenFlow Controller (OFC) 集群,使用 Paxos 協議選出一個 master,其他都是熱備(hot standby)。
二三兩條虛線之間是交換機(switch),運行著 OpenFlow Agent (OFA),接受 OFC 的指令并將 TE 規則寫到硬件 flow-table 里。
Switch Design
Google 定制的 128 口交換機由 24 個 16 口 10Gbps 通用交換機芯片制成。(在本文中,“交換機”和“路由器”是通用的。需要說明工作在 MAC 層還是 IP 層時,會加定語 layer-2 或 layer-3)拓撲結構見下圖。
藍色的芯片是對外插線的,綠色的芯片充當背板(backplane)。如果發往藍色芯片的 packet 目標 MAC 地址在同一塊藍色芯片上,就“內部解決”;如果不是,則發往背板,綠色芯片發到目標地址所對應的藍色芯片。
交換機上運行著用戶態進程 OFA (OpenFlow Agent),連接到遠程的 OFC (OpenFlow Controller),接受 OpenFlow 命令,轉發合適的 packet 和連接狀態到 OFC。例如,BGP 協議的 packet 會被轉發到 OFC 上,在 OFC 上運行 BGP 協議棧。
Routing
RIB: Routing Information Base,路由所需要的網絡拓撲、路由規則等
Quagga: Google 采用的開源 BGP/ISIS 協議實現
RAP: Routing Application Proxy,負責 OFA 與 OFC 之間的互聯
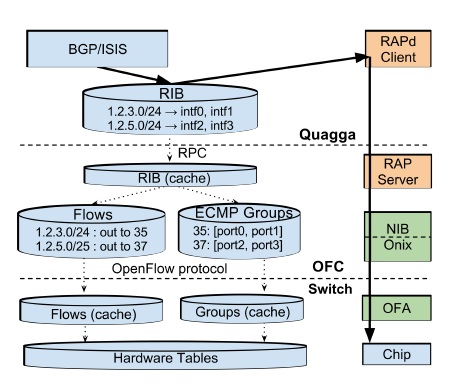
如上圖所示,Quagga 路由協議棧中的 RIB 保存著路由規則,如發往某個子網的包要從某兩個端口選一個出去。數據中心網絡中一個 packet 一般會有多條路線可走,一方面提高冗余度,一方面充分利用帶寬,常用的協議是 Equal Cost Multiple Path (ECMP),即如果有多條最短路,就從其中隨機選一條走。
在 OFC 中,RIB 被分解為 Flows 和 Groups。要理解這個拆分的必要性,先要理解網絡交換設備是怎樣工作的。現代網絡交換設備的核心是 match-action table。Match 部分就是 Content Addressable Memory (CAM),所有條目可以并行地匹配,匹配結果經過 Mux 選出優先級最高的一條;Action 則是對數據包進行的動作,比如修改包頭、減少 TTL、送到哪個端口、丟棄數據包。
對路由規則來說,僅支持精確匹配的 CAM 是不夠的,需要更高級的 TCAM,匹配規則支持 bit-mask,也就是被 mask 的位不論是0還是1都算匹配。例如需要匹配 192.168.0.0/24,前24位精確匹配,最后8位設為掩碼即可。
在 OFC 中,Flows 對應著 Match 部分,匹配得出 Action 規則編號;Groups 對應著 Action 部分,采用交換機中現有的 ECMP Hash 支持,隨機選擇一個出口。
#p#
TE 算法
優化目標
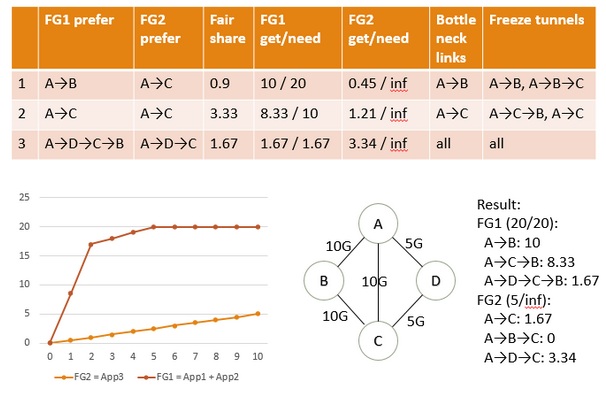
系統管理員首先決定每個應用在每對數據中心之間所需的帶寬和優先級,這就形成了一系列 {Source site, Dest site, Priority, Required bandwidth} 四元組(此處為了便于理解,對原論文進行了修改)。將這些四元組按照 {Source site, Dest site, Priority}分組,把所需帶寬加起來,就形成了一系列 Flow Group (FG)。每個 FG 由四元組 {Source site, Dest site, Priority, Bandwidth} 表征。
TE Optimization 的目標是 max-min fairness,就是在公平的前提下滿足盡可能多的需求。由于未必可以滿足所有需求,就要給“盡可能多”和“公平”下個定義。我們認為,客戶的滿意度是跟提供的帶寬成正比的,也是跟優先級成反比的(優先級越高,就越不容易被滿足);如果已經提供了所有要求的帶寬,則滿意度不再提高。在此假設基礎上,引入 fair share 的概念,兩個 Flow Group 如果 fair share 相同,就認為這兩個客戶的滿意度相同,是公平的。
例子:App1 需要 15G 帶寬,優先級為10;App2 需要 5G 帶寬,優先級為1;App3 帶寬多多益善(無上限),優先級為0.5。
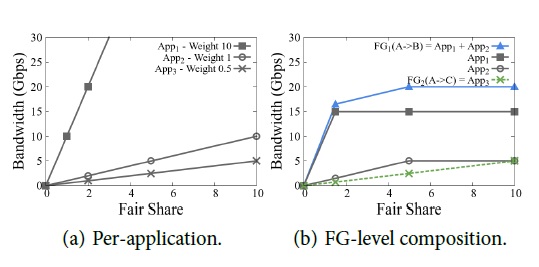
TE Optimization 算法分下面三步:
Tunnel Selection: 選擇每個 FG 可能走的幾條路線(tunnel)
Tunnel Group Generation: 給 FG 分配帶寬
Tunnel Group Quantization: 將帶寬離散化到硬件可以實現的粒度
選路
Tunnel Selection:利用 Yen 算法 [2],選出 k 條最短路,k 是一個常量。
例如下面的網絡拓撲,取 k = 3:
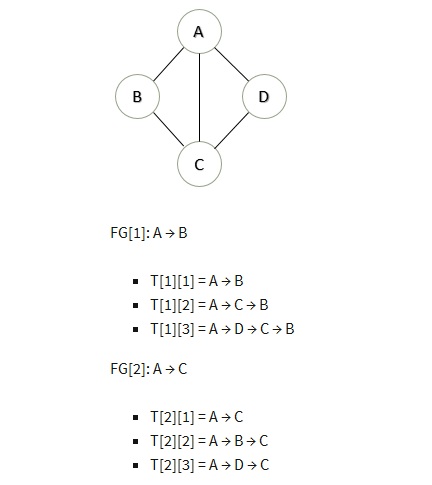
算法描述:

分配流量
Tunnel Group Generation: 根據流量需求和優先級分配流量。(論文中沒有算法描述,我自己整理了一下。由于有些名詞用中文寫出來很別扭,就用英文了)
Initialize each FG with their most preferred tunnels.
Allocate bandwidth by giving equal fair share to each preferred tunnel.
Freeze tunnels containing any bottlenecked link.
If every tunnel is frozen, or every FG is fully satisfied, finish.
Select the most preferred non-frozen tunnel for each non-satisfied FG, goto 2.
繼續上面的例子:
流量離散化
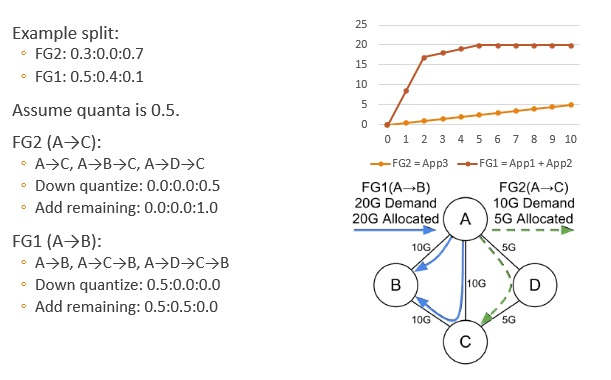
Tunnel Group Quantization: 由于硬件支持的流量控制不能無限精細,需要對上一步計算出的流量進行離散化。求最優解是個整數規劃問題,很難快速求解。因此論文使用了貪心算法。
Down quantize (round) each split.
Add a remaining quanta to a non-frozen tunnel that makes the solution max-min fair (with minimum fair share).
If there are still remaining quantas, goto 2.
繼續上面的例子:
離散化會降低性能嗎

上圖展示了離散化對性能的影響,這里的 Throughput Delta 是相對優化之前而言的,越大越好。可以看到,當流量分配粒度達到 1/16 后,再提高精細程度,就沒有太多作用了。
在 Google 最終的實現中,tunnel 個數(前面的 k)設置為4,分配粒度為 1/4。至于為什么這么設置,you ask me, I ask who。
#p#
TE 實現
Tunneling
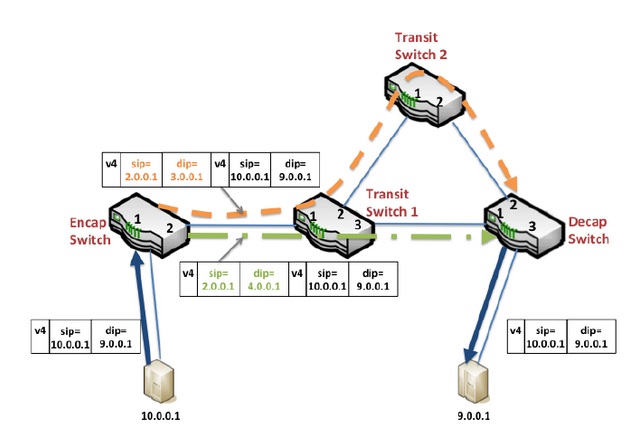
Encap Switch 是連接終端機器的邊界路由器,它們將 IP packet 封裝起來,包上路由專用的 source ip 和 destination ip。
Transit Switch 是中間傳輸路由器,它們只接受經過 Encap Switch 封裝的 IP packet,并在數據中心之間進行路由。
Decap Switch 是連接終端機器的邊界路由器,其實跟 Encap Switch 是同一批機器。它們將被封裝的 IP packet 剝掉一層皮,送給終端機器。
TE as Overlay
SDN “一步到位”的做法是設計一種統一的、集中式的服務,囊括路由和 Traffic Engineering。但這樣的協議研發過程會很長。另外,萬一出問題了,大家就都上不了 Google 了。
在這個問題上,Google 又發揚了“小步快走”的敏捷開發思想,把 TE 和傳統路由兩個系統并行運行,TE 的優先級高于傳統路由,這樣 SDN 就可以逐步部署到各個數據中心,讓越來越多的流量從傳統路由轉移到 TE 系統。同時,如果 TE 系統出現問題,隨時可以關閉 TE,回到傳統路由。
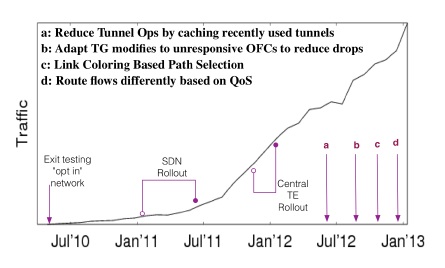
Google SDN 所承載的流量變化曲線
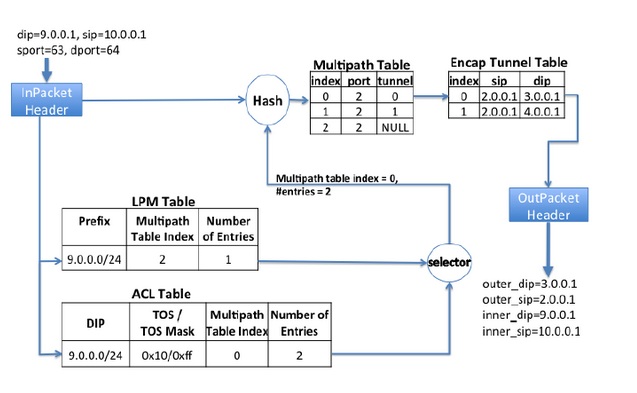
每個交換機都有兩張路由表,LPM (Longest Prefix Match) Table 由基于最短路徑的傳統路由協議(BGP/ISIS)維護。ACL Table 是 TE 使用的路由表,優先級高于 LPM,也就是 LPM 和 ACL 都匹配出條目時,ACL 說的算。
上圖的例子是 Encap Switch。匹配結果是一個 Multipath Table Index 和可選條數,也就是從 Index 開始的這么多條規則中根據 Hash 值選出一條規則。這條規則寫明了出口(port)和路徑(tunnel),再從路徑表(Encap Tunnel Table)里查到要被封裝到 IP packet 頭部的 source IP 和 dest IP。對于 Transit Switch,就不需要路徑表了。
操作依賴
一次 TE 變更可能涉及多個交換機的插入/刪除規則操作,而這些操作不能以任意的順序進行,否則就有可能出現丟包。因此有了兩條規則:
在修改 Tunnel Group 和 Flow Group 之前,先在所有受影響的數據中心建立好 tunnel
在所有引用某 tunnel 的條目被刪除之前,不能刪除這個 tunnel
為了在有網絡延遲和數據包亂序 (reordering) 的情況下保證依賴關系,中心 TE 服務器為每個事務(session)中的有序操作分配遞增的序列號。OpenFlow Controller 維護當前最大的 session 序列號,拒絕任何比它小的 session 序列號。TE 服務器如果被 OFC 拒絕,將在超時后重試這個操作。
#p#
部署效果
統計
每分鐘 13 次拓撲變化
去除維護造成的更新,每分鐘 0.2 次拓撲變化
拓撲中的邊添加/刪除事件,一天 7 次(TE 算法運行在拓撲聚合后的視圖上。兩個數據中心之間可能有上百條 link,把它們聚合成一條容量巨大的 link。)
這方面的經驗是:
拓撲聚合明顯降低了路徑顛簸和系統負載
即使有拓撲聚合,每天也會發生好幾次邊的刪除
WAN link 對端口顛簸(反復變化)很敏感,用中心化的動態管理收效較好
錯誤恢復
在數據中心,設備、線路損壞是常有的事,因此錯誤的影響范圍和恢復速度很重要。

由上表可見,單條線路損壞只會中斷連接 4 毫秒,因為受影響的兩臺交換機會立即更新 ECMP 表;一個 Encap Switch 損壞會使周邊的交換機都更新 ECMP 表,比單條線路損壞多耗時一些。
但臨近 Encap Switch 的 Transit Switch 掛掉就不好玩了,因為 Encap Switch 里有個封裝路徑表(Encap Tunnel Table),這個表是中心維護的,出現故障后鄰近的 Encap Switch 要匯報給 OFC,OFC 匯報給全球中心的 TE Server(高延遲啊),TE Server 再按照操作依賴的順序,逐個通知受影響的 Encap Switch 修改路徑。由于這種操作很慢,需要 100ms,整個恢復事務需要 3300ms 才能完成。
OFC、TE Server 的故障都沒有影響,首先因為它們使用了 Paxos 分布式一致性協議,其次即使全都掛掉了,也只是不能修改網絡拓撲結構,不會影響已有的網絡通信。由于前面提到的 TE as Overlay,關閉 TE 時,整個網絡會回到基于最短路徑的傳統路由協議,因此也不會造成網絡中斷。
優化效果
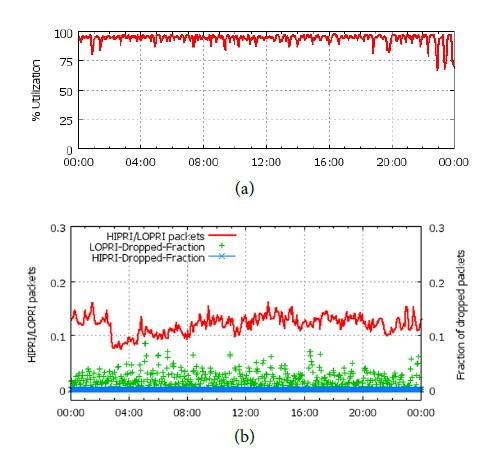
(a) 是平均帶寬使用率,可以看到帶寬使用率平均可達 95%。
(b) 是丟包率,其中占 10%~15% 比例(紅線)的高優先級 packet 幾乎沒有丟包(藍色),而低優先級 packet 有較多的丟包(綠色)。如果低優先級應用使用通常的 TCP 協議,在這么高的丟包率下很難高效工作。因此傳輸層協議也是要特殊設計的,不過論文并未透露。
一次事故
Google 的 SDN 系統曾經出現一次重大事故。過程是這樣的:
一個新加入的交換機被不小心配置成了跟原有交換機一樣的 ID。
兩個 ID 相同的交換機分別發送 ISIS Link State Packet,收到的其他交換機感覺很奇怪,怎么這兩份拓撲完全不一樣呢?這兩個 ID 相同的交換機都堅持自己的觀察是正確的,導致網絡中出現洪泛。
TE 控制信令要從 OFC 發給 OFA,被網絡阻塞了,造成了長達 400MB 的等待隊列。
ISIS Hello message(心跳包)也因為長隊列而阻塞了,交換機們都認為周圍的交換機掛掉了。不過 TE 流量仍然正常運行,因為它的優先級高于傳統路由。
此時,由于網絡擁塞,TE Server 無法建立新的 tunnel。雪上加霜的是,TE 依賴機制要求序列號較小的操作成功后才能進行下一個操作(見上文),建立新 tunnel 更是不可能了。因此,任何網絡拓撲變化或設備故障都會導致受影響的網絡仍在使用已經不能用的 tunnel。前面有統計數字,每分鐘都會發生拓撲變化,因此這個問題是很嚴重的。
系統運維人員當時并不知道問題的根源,于是就重啟了 OFC。不幸的是,這一重啟,觸發了 OFC 中未發現的一個 bug,在低優先級流量很大時不能自啟動。
文中說,這次故障有幾個經驗/教訓:
OFC 與 OFA 之間通信的可擴展性和可靠性很重要。
OFA 的硬件編程操作應該是異步并行的。
應該加入更多系統監控措施,以發現故障前期的警告。
當 TE 連接中斷時,不會修改現有的路由表。這是一種 fail-safe 的措施,保證這次故障中已經建立的 tunnel 沒有被破壞。
TE Server 需要處理 OFC 無響應的情況。如果有的 OFC 掛掉了,與其禁止所有新建 tunnel 的操作,不如先讓其中一部分運轉起來。
一些未來研究方向:
硬件編程的開銷。OpenFlow 的規則順序是很重要的,插入一條規則可能導致后面的規則都要移動,因此操作起來很慢。這是可靠性的主要瓶頸。
OFC 與 OFA 間的通信瓶頸。OFC 和 OFA 間通信的可擴展性和可靠性不足。OpenFlow 最好能提供兩個通信端口,分別支持高優先級操作和需要大帶寬的數據傳輸。
原文鏈接:http://boj.blog.ustc.edu.cn/index.php/2013/08/google-dcn/














