Firefox OS性能探秘:Dalvik vs ASM.JS vs本地代碼
眾所周知,Mozilla涉足手機操作系統領域,推出Firefox OS,這都不是什么新鮮事了。Firefox OS是純粹用Web技術打造的,其核心內容就是HTML,CSS,當然還有***的Javascript。Firefox OS上所有的應用程序都是基于上述技術的,甚至包括那些核心應用也不例外。
鑒于FireFox OS完全由Javascript打造,Mozilla的Javascript引擎(SpiderMonkey)不能回避的一個話題,就是與其他手機設備平 臺的開發語言相互比較。為了詳細地研究這個問題,我花了大約兩周的時間做了一個小小的性能測試實驗。
實驗:
我們的實驗以SunSpider benchmark測試為基礎,我把部分程序從Javascript代碼同時轉換成了Java和C++代碼,并盡力忠實于Javascript代碼本身的 邏輯。接著,我將Java版本的程序編譯成Android Dalvik應用,然后用emscripte工具把C++版本的程序生成為asm.js代碼。
然后,我在Nexus 4設備上做了如下測試:
1、Dalvik應用程序,直接在Android運行
2、Asm.js代碼(從C++編譯而來),運行在Mobile Firefox Nightly上
3、本地代碼(從C++編譯而來),直接在Android上運行(編譯指令為:ndk-build V=1 TARGET_ARCH_ABI=armeabi-v7a)
我使用運行時間的倒數作為評判指標(分數越高的話就越好),并且把結果進行了等比例縮放,以保證Dalvik至少能得到1分(哈哈,好惡毒的評論——譯者注)
我還讓每個程序循環運行了10到1000次(根據程序的實際情況來定),以便讓引擎優化器能夠有機會編譯熱代碼。一般情況下,SunSpider程 序運行只需要很少的時間。讓程序運行很多次能夠有效地使得SunSpider模仿真正應用程序運行的情況,因為真正的應用程序都是長時間運行的。
我選擇的測試程序包括:binary-trees, 3D-morph, partial-sums, fasta, spectral-norm, nsieve和nbody。源代碼可以從下列地址獲取:
http://github.com/kannanvijayan/benchdalvik
免責聲明:
我必須事先說明一點:我不敢說SunSpider就是一個***的測試基準軟件,能夠精確地反應真實的性能分析結果。實際上它更像是一系列小的基準測試程序的合集,能夠在某種程度上反應出一些性能測試等級而已。
我選擇SunSpider作實驗的原始,是因為它里面的測試程序很容易能被拿出來,并且能夠很清楚地從Javascript源代碼轉換成對應的 C++或者Java代碼。總的來說,對不同語言平臺的比較很難做到科學意義上的嚴格和準確。因此,即使是對這些小的基準測試,也必須要對結果做適當的分析 和估算,才能保持客觀。
結果:
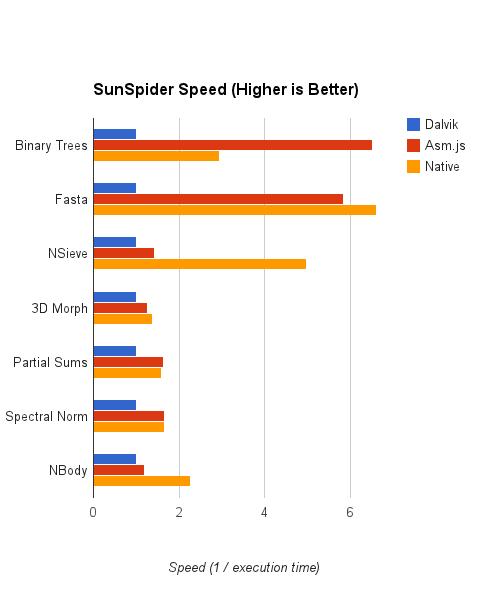
上圖顯示,asm.js的表現非常好,與原生代碼的性能相當,甚至在某些測試上(binary-trees)比原生代碼的性能還要好。這些數字本身,當然不能夠解釋為什么會如此,并且真正的原因也不會像數字這么有趣。那么,就讓我們把趣味性放低一些,看看到底是什么造成了這樣的結果。
#p#
分析:
二叉樹測試
二叉樹測試的得分是非常讓人意外的。在這個測試里,asm.js版本的程序甚至比原生代碼的表現還要好很多。這個結果似乎與常識相悖,但是其中也是有可以解釋的原因的。
我們知道,二叉樹的數據結構需要給很多對象分配內存。在C++里(實際上是在C語言里,因為malloc是CRT的函數——譯者注),分配內存的操 作會大量調用malloc函數。當程序被編譯成本地代碼時,malloc方法會被大量調用,這個個方法本身就是非常消耗時間的。
在asm.js里,被編譯后的C++代碼在執行的時候會使用一個Javascript類型的序列,叫做“機器內存“。“機器內存”在整個程序的運行 期內只會分配一次。從asm.js產生的malloc方法不會執行系統級別的調用。這可能就是為什么asm.js編譯出來的C++代碼比編譯成本地的 C++代碼執行效率更高的原因,當然這個說法還有待于進一步的證實。
另一個問題是,為什么Dalvik表現那么糟糕。這就是Java需要優化的地方了:過于簡單,采用固定大小的類結構,過多的瑣碎的內存分配策略,等 等。我對Dalvik的性能問題并沒有很好的答案——并且這個測試的結果也讓我十分驚訝,我本以為Dalvik的表現應該比這好很多才對。
下面的說法純屬是我的猜測,不過我認為Dalvik的糟糕表現估計和tracing JIT有關。根據我與那些有tracing JIT研究經驗的交流結果,我得知tracing JIT對遞歸的編譯顯得非常困難。鑒于二叉樹的基本功能就是基于幾個遞歸函數實現的,這也很可能就解釋了為什么Dalvik的表現很糟糕的問題。如果讀者 對此有更好的解釋,請不吝賜教。
Fasta
注意到fasta程序已經修改,把makeCumulative操作移除主循環,放到了setup代碼里。
Asm.js和本地C++代碼都遠比Dalvik的運行分數高,本地代碼好像比asm.js的性能稍微好那么一點點。那么,讓我們分析一下其中的原因。
從代碼很容易看出來,程序花了很多時間在關聯矩陣之間進行迭代,反復取值。在C++/asm.js版本的實現里,這些迭代操作是通過使用標注有 inlie關鍵字的hash_map結構來進行操作的,鍵采用char類型,值采用double類型,效率很高。在Java代碼里,所有的迭代是通過 java.util.HashMap數據結構來操作的,并且采用了Character和Double的裝箱類作為基本數據結構。
Java的HashTable迭代是非常耗費資源,并且很不直接的。迭代器會首先將指針轉換為Map.Entry對象,而不是直接只用固定大小的實 例數組(C++就是這么做的),并且它還潛質獎char和double類型自動裝箱成Character和Double的裝箱類實例對象。Java集合類 雖然功能非常強大,但是它們在規模較大,結構較復雜的情況下才能有效地展現出威力,如果把本來可以用原生類型處理的結構再搞成集合,那反而會起到反作用。 這個fasta中的小小的查找表就完全違背了Java數據結構的本意。
C++和asm.js版本的程序就采取了更有效的存儲模式來存儲數據,并且采用了更有效的迭代器來處理數據。C++/asm.js還是用了單字節的 char, 而不是Java和Javascript的雙字節char, 這也就意味著C++/asm.js的實現版本能夠節約更多的存儲空間。
總的來說,fasta測試的主要目的,是測試語言能夠在多快的速度下找到與之相關的小序列。我相信Dalvik的表現不好的主要原因也在于Java語言本身:集合不支持原生數據類型,集合迭代器的資源消耗太大等等。
NSIEVE
在這個測試里,asm.js比本地程序慢了三倍,并且僅僅領先Dalvik一點點。
這是一個完全令人意想不到的結果——我本來以為asm.js的速度會和本地代碼的速度差不多。Alon Zakai(Mozilla研究員,emscripte的作者)跟我說,在臺式機電腦上(x86構架),asm.js的表現大約是本地代碼的84%。這樣 一來,問題就很可能出在SpikderMonkey的ARM代碼生成上,而且應當是可以進行優化的。
3D Morph, Partial Sums, and Spectral Norm
我把這么多程序寫在一起,主要是因為我覺得這些程序的得分基本上都可以用同樣的道理來解釋。
本地代碼,asm.js和Dalvik的得分都很相似,本地代碼比asm.js快一點點,asm.js又比Dalvik快更多一點點。(請忽略asm.js綜合起來仿佛比本地代碼還快一點的現象,我基本可以肯定這是實驗中的誤差造成的,實際上這兩者可以算是齊頭并進的)
這些程序都是基于雙精度浮點數的。對于這種數據類型的運算,在ARM CPU上的代價是很高的,而且部分代碼的運行速度差異很可能掩蓋了整體性能的表現。
最令人驚訝的并不是asm.js和本地代碼運行效率之間的比較,而是Dalvik仿佛比asm.js的得分大約落后了20%-30%。
NBody
我猜測asm.js的速度只有本地代碼速度的一半。Nbody代碼的主要邏輯是產生大量的二次間接尋址操作:從一個數組中挑出一個指針,然后從這個 指針的地址開始再讀取一個偏移量的內存。每次讀取操作都可以用ARM的單條指令來完成,采用帶有多地址模式的ARM LDR指令即可:
例如,從一個指針數組中讀取一個對象的指針,然后再從這個對象中讀取一個屬性,用下面兩個指令就可以完成:
LDR TargetReg, [ArrayReg + (IndexReg leftshift 2)] LDR TargetReg, [TargetReg + OffsetOfField]
(如上,ArrayReg是一個寄存器,保存了一個指向數組的指針,IndexReg也是一個寄存器,保存了數組中的序列號,OffSetOfField是一個常量)
然而,在asm.js里面,“內存”讀取操作實際上是在一個類型化了數組中完成的,“指針”實際上是指對應數組內部的整數偏移量。Asm.js里的指針與本地代碼有所不同,因為它還包含了邊界檢查。與上面邏輯相同的邏輯代碼實際上是由下面五條語句構成的:
LDR TargetReg, [ArrayReg + (IndexReg leftshift 2)] CMP TargetReg, MemoryLength BGE bounds-check-failure-address LDR TargetReg, MemoryReg + TargetReg LDR TargetReg, [TargetReg + OffsetOfField]
(如上,ArrayReg, IndexReg, 和 OffsetOfField都與之前相同,MemoryReg是用來保存TypeArray數組基址指針的寄存器,TypeArray數組在asm.js里面被用來表示內存。)
基本上看來,asm.js加入了額外的操作,從而讓對內存的間接讀取變得開銷更大。因此這個測試完全依賴于其內部循環的情況,我認為大大地影響了降低了程序的性能。
請記住,上面所說的一切理由都是基于理論推測,沒有進一步的實驗和驗證,下任何結論都是不符合事實的。
一點看法:
這個實驗是相當有趣的。因此我產生了幾點看法,我個人覺得都還挺有道理的:
1. 在ARM上,asm.js完全是一個可以和C++本地代碼抗衡的語言。就算是去掉一個***分(就是asm.js比C++快的那個測試),asm.js依然 可以表現出本地C++代碼70%的速度。這些測試結果說明,那些對性能需求很高的應用程序,完全可以采用asm.js來達到接近于本地代碼的性能表現。
2. Asm.js跟Dalvik相比,擁有巨大的優勢。即使是去掉一個***分(在二叉樹測試和fasta中的那個結果),asm.js依然比Dalvik代碼快10%-50%,并且這一優勢十分穩定。
尾聲:
敏感的讀者一定會問:如果是直接用Javascript代碼會怎么樣?普通的Javascript代碼性能太差,以至于我完全忽略它了?還是有什么貓膩我故意不提?
坦誠地說,我并沒有把對普通Javascript代碼的測試放到這次試驗當中。因為普通的Javascript大碼到目前為止表現得有些太好了,所以我覺得我還是不要把他們放到測試里面來,以免這些測試結果反而起到誤導的作用。
因為一些原因,SunSpider的標準測試的得分會“相當不合理”,這多少還是有點讓人遺憾的。所有的Javascript引擎,包括 SpiderMonkey,都多少使用了優化技術,例如先驗式數學緩存(就是把正弦,余弦,正切等三角函數的值緩存起來,在使用的時候直接查內存表,而不 是真的去計算,以此來節省時間),來提高他們的SunSpider測試得分。這些專門針對SunSpider進行的優化,很諷刺地讓SunSpider完 全失去了對純粹Javascript代碼運行效率測評的客觀性。