全面解析Linux網絡I/O:數據是如何“跑”起來的?
數字化時代,網絡已深度融入生活與工作,從日常上網、觀影到企業數據傳輸,都離不開網絡支持。而 Linux 內核作為操作系統核心,在網絡數據處理中扮演關鍵角色,其核心功能之一便是管理網絡數據的輸入輸出。Linux 內核因開源、高效、穩定,被廣泛應用于服務器、嵌入式設備、超級計算機等場景。
全球超 90% 的超級計算機運行 Linux 系統,谷歌、亞馬遜等互聯網巨頭的服務器集群,也依賴其強大網絡處理能力,支撐海量數據傳輸與高并發請求。那么,Linux 內核如何實現網絡數據的輸入輸出?本文將深入其源碼,解析網絡數據處理的技術原理,探究從接收、協議解析到發送的全過程,展現 Linux 內核在網絡領域的精妙設計。
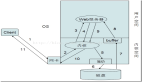
Part1.Linux網絡棧架構總覽
Linux 網絡棧采用分層架構,這種架構設計就如同建造高樓,每一層都有其獨特的功能和職責,層層協作,共同構建起強大的網絡通信體系。從下往上,Linux 網絡棧主要分為鏈路層、網絡層、傳輸層和應用層 ,各層緊密配合,實現網絡數據的高效傳輸。
 圖片
圖片
1.1應用層:用戶的交互界面
應用層是用戶與網絡應用程序進行交互的界面,就像是各種商店,為用戶提供各種具體的網絡服務。它負責處理特定的應用程序細節,如 HTTP(Hypertext Transfer Protocol)協議用于網頁瀏覽、SMTP(Simple Mail Transfer Protocol)協議用于郵件發送、FTP 協議用于文件傳輸等。應用層通過調用傳輸層提供的接口,實現數據的傳輸和交互。
例如,當我們在瀏覽器中輸入網址并按下回車鍵后,瀏覽器會使用 HTTP 協議向服務器發送請求,服務器接收到請求后,會根據請求內容返回相應的網頁數據,瀏覽器再將這些數據解析并顯示出來,供用戶瀏覽。
(1) Socket
應用層的各種網絡應用程序基本上都是通過 Linux Socket 編程接口來和內核空間的網絡協議棧通信的。Linux Socket 是從 BSD Socket 發展而來的,它是 Linux 操作系統的重要組成部分之一,它是網絡應用程序的基礎。從層次上來說,它位于應用層,是操作系統為應用程序員提供的 API,通過它,應用程序可以訪問傳輸層協議。
- socket 位于傳輸層協議之上,屏蔽了不同網絡協議之間的差異
- socket 是網絡編程的入口,它提供了大量的系統調用,構成了網絡程序的主體
- 在Linux系統中,socket 屬于文件系統的一部分,網絡通信可以被看作是對文件的讀取,使得我們對網絡的控制和對文件的控制一樣方便。
 圖片
圖片
(2)應用層處理流程
- 網絡應用調用Socket API socket (int family, int type, int protocol) 創建一個 socket,該調用最終會調用 Linux system call socket() ,并最終調用 Linux Kernel 的 sock_create() 方法。該方法返回被創建好了的那個 socket 的 file descriptor。對于每一個 userspace 網絡應用創建的 socket,在內核中都有一個對應的 struct socket和 struct sock。其中,struct sock 有三個隊列(queue),分別是 rx , tx 和 err,在 sock 結構被初始化的時候,這些緩沖隊列也被初始化完成;在收據收發過程中,每個 queue 中保存要發送或者接受的每個 packet 對應的 Linux 網絡棧 sk_buffer 數據結構的實例 skb。
- 對于 TCP socket 來說,應用調用 connect()API ,使得客戶端和服務器端通過該 socket 建立一個虛擬連接。在此過程中,TCP 協議棧通過三次握手會建立 TCP 連接。默認地,該 API 會等到 TCP 握手完成連接建立后才返回。在建立連接的過程中的一個重要步驟是,確定雙方使用的 Maxium Segemet Size (MSS)。因為 UDP 是面向無連接的協議,因此它是不需要該步驟的。
- 應用調用 Linux Socket 的 send 或者 write API 來發出一個 message 給接收端
- sock_sendmsg 被調用,它使用 socket descriptor 獲取 sock struct,創建 message header 和 socket control message
- _sock_sendmsg 被調用,根據 socket 的協議類型,調用相應協議的發送函數。對于 TCP ,調用 tcp_sendmsg 函數。對于 UDP 來說,userspace 應用可以調用 send()/sendto()/sendmsg() 三個 system call 中的任意一個來發送 UDP message,它們最終都會調用內核中的 udp_sendmsg() 函數。
 圖片
圖片
1.2傳輸層:數據的可靠保障
傳輸層是網絡通信的可靠保障,如同快遞服務中的包裹跟蹤系統,確保數據能夠準確無誤地從發送方傳輸到接收方。它主要提供端到端的通信服務,常見的傳輸層協議有 TCP(Transmission Control Protocol)和 UDP(User Datagram Protocol)。
TCP 協議是一種面向連接的、可靠的傳輸協議,它通過三次握手建立連接,在數據傳輸過程中進行流量控制和擁塞控制,確保數據的完整性和有序性;TCP棧的簡要過程包括連接建立、數據傳輸和連接關閉三個主要階段:
①連接建立(三次握手)
- 客戶端選擇一個初始序列號 x,發送一個帶有 SYN 標志的數據包到服務器,此時客戶端進入 SYN_SENT 狀態。
- 服務器收到 SYN 包后,如果同意連接,會分配 TCP 資源,選擇自己的初始序列號 y,并發送一個 SYN-ACK 包,確認客戶端的序列號為 x+1。此時服務器進入 SYN_RCVD 狀態。
- 客戶端收到 SYN-ACK 包后,發送一個 ACK 包給服務器,確認服務器的序列號為 y+1,客戶端進入 ESTABLISHED 狀態。服務器收到 ACK 包后,也進入 ESTABLISHED 狀態,至此 TCP 連接建立成功。
②數據傳輸
- 應用程序創建要發送的數據,通過系統調用(如 write)將數據從用戶空間拷貝到內核空間的發送 socket 緩沖區。
- TCP 協議從發送緩沖區中取出數據,構造 TCP 段,包括添加 TCP 頭部,設置序列號、確認號等字段,并計算 TCP 校驗和。TCP 段的 payload(有效載荷)大小受接收窗口、擁塞窗口和最大段大小(MSS)限制。
- TCP 段被傳輸到 IP 層,IP 層在 TCP 段頭部加上 IP 頭信息,用于路由。然后 IP 包被傳輸到鏈路層,鏈路層添加以太網頭部信息,并通過 ARP 協議獲取下一跳的 MAC 地址,最終將數據包發送到網絡中。
- 接收方收到數據包后,從鏈路層依次向上解封裝,到達 TCP 層。TCP 層根據序列號和確認號對數據進行排序和確認,將正確的數據放入接收 socket 緩沖區,供應用程序讀取。如果發現數據丟失或錯誤,接收方會請求發送方重發相應數據,發送方會緩存未收到 ACK 的數據,在超時未收到確認時進行重發。同時,接收方會根據自己的接收能力,通過窗口字段告知發送方自己能接收的最大字節數,進行流控制。發送方還會根據網絡狀況進行擁塞控制,避免網絡擁塞。
③連接關閉(四次揮手)
- 當客戶端完成數據傳輸并希望斷開連接時,它發送一個 FIN 包,進入 FIN-WAIT-1 狀態。
- 服務器收到 FIN 包后,發送一個 ACK 包確認,進入 CLOSE-WAIT 狀態。客戶端收到 ACK 包后,進入 FIN-WAIT-2 狀態。
- 服務器完成數據傳輸后,發送一個 FIN 包給客戶端,請求關閉其端的連接,此時服務器進入 LAST-ACK 狀態。
- 客戶端收到服務器的 FIN 包后,發送一個 ACK 包進行確認,然后進入 TIME-WAIT 狀態。經過 2MSL(最大報文段生存時間的兩倍)后,客戶端確保服務器接收到最終的 ACK 包,然后關閉連接。服務器收到 ACK 后,也關閉連接。
UDP 協議則是一種無連接的、不可靠的傳輸協議,它不保證數據的可靠傳輸,但具有傳輸速度快、開銷小的特點,適用于對實時性要求較高但對數據準確性要求相對較低的應用場景,如視頻直播、音頻通話等。例如,當我們使用 FTP(File Transfer Protocol)進行文件傳輸時,通常會使用 TCP 協議,以確保文件的完整傳輸;而在觀看在線視頻時,由于對實時性要求較高,即使少量數據丟失也不會對觀看體驗造成太大影響,因此可能會使用 UDP 協議。
UDP 棧的簡要過程包括數據發送和數據接收兩個主要方面:
①數據發送過程
- 創建套接字:應用層通過調用 Socket API 中的socket函數創建一個 UDP 套接字。該函數會最終調用內核中的sock_create方法,返回一個文件描述符,內核中會為該套接字創建對應的struct socket和struct sock結構體,其中struct sock包含接收隊列(rx)、發送隊列(tx)和錯誤隊列(err)。
- 構建 UDP 數據報:應用程序調用send、sendto或sendmsg等函數發送數據,這些函數最終會調用內核中的udp_sendmsg函數。udp_sendmsg函數根據目的地址和端口號,將應用層數據封裝成 UDP 數據報,添加 UDP 首部,首部包含源端口號、目的端口號、長度和校驗和(校驗和為可選項)。
- 發送到網絡層:UDP 將構建好的數據報通過調用ip_append_data方法或ip_queue_xmit函數,將數據包發送給網絡層(IP 層)。
- 網絡層處理:IP 層接收到數據包后,添加 IP 首部,進行路由處理,確定下一跳地址。如果數據包長度超過網絡最大傳輸單元(MTU),可能會進行分片處理,最后將處理好的數據包發送到鏈路層。
- 鏈路層發送:鏈路層收到數據包后,添加鏈路層首部(如以太網首部),包含源 MAC 地址和目的 MAC 地址等信息,并通過物理層將數據發送到網絡中。
②數據接收過程
- 物理層接收:物理層從網絡中接收數據幀,將其傳遞給鏈路層。
- 鏈路層解析:鏈路層去除鏈路層首部,根據首部中的協議類型字段,判斷出是 UDP 數據報,將其傳遞給網絡層。
- 網絡層處理:IP 層檢查 IP 首部,進行路由相關處理和校驗等,根據協議字段確定上層協議為 UDP 后,去除 IP 首部,將 UDP 數據報傳遞給 UDP 層。
- UDP 層解析:UDP 層根據 UDP 首部中的目的端口號,將數據報從接收隊列中取出,計算校驗和(若有),驗證數據完整性。如果校驗通過,提取數據載荷部分。
- 交付應用層:UDP 將提取出的數據載荷通過 Socket 接口發送給對應的應用程序,應用程序通過調用recv或recvfrom等函數接收數據,完成數據接收過程。
1.3網絡層:數據的導航者
網絡層如同交通樞紐的調度員,負責數據包在網絡中的傳輸和路由選擇。其核心協議是 IP(Internet Protocol)協議,它為每個網絡節點分配唯一的 IP 地址,使得數據包能夠在不同的網絡之間進行傳輸。當網絡層接收到鏈路層傳來的數據包后,會根據數據包中的目的 IP 地址,通過路由表查找最佳的傳輸路徑,然后將數據包轉發到下一個網絡節點。
此外,網絡層還包括 ICMP(Internet Control Message Protocol)協議,用于網絡診斷和錯誤報告;IGMP(Internet Group Management Protocol)協議,用于多播通信。例如,當我們在瀏覽器中輸入一個網址并訪問時,網絡層會根據目標服務器的 IP 地址,規劃出數據從本地計算機到目標服務器的傳輸路徑,確保數據能夠準確無誤地到達。
網絡層的任務就是選擇合適的網間路由和交換結點, 確保數據及時傳送。網絡層將數據鏈路層提供的幀組成數據包,包中封裝有網絡層包頭,其中含有邏輯地址信息- -源站點和目的站點地址的網絡地址。其主要任務包括 (1)路由處理,即選擇下一跳 (2)添加 IP header(3)計算 IP header checksum,用于檢測 IP 報文頭部在傳播過程中是否出錯 (4)可能的話,進行 IP 分片(5)處理完畢,獲取下一跳的 MAC 地址,設置鏈路層報文頭,然后轉入鏈路層處理。
IP 棧基本處理過程主要包括數據包的接收、校驗、路由選擇、分片以及發送等步驟:
步驟一:鏈路層接收分組并送至網絡層:當網卡收到與自己 MAC 地址匹配或廣播的以太網幀時,會產生硬件中斷,網卡驅動處理該中斷,從 DMA 或其他方式獲取分組數據寫入內存,分配套接字緩沖區 skb,并調用 netif_rx (skb) 函數。
skb 進入到達隊列等待 CPU 處理,同時標記 NET_RX_SOFTIRQ 網絡接收軟中斷。CPU 調用 do_softirq () 處理軟中斷,再調用 net_rx_action (),在 netif_receive_skb 函數中,根據協議將 skb 發送到相關協議處理函數,如 ip_rcv () 用于處理 IP 協議。
步驟二:網絡層處理分組(以 IPv4 為例):
- ip_rcv 函數校驗:skb 被送到 ip_rcv () 函數,驗證 IP 分組,檢查目的地是否為本機地址、校驗和是否正確等。若正確,交給 netfilter 的 NF_IP_ROUTING;否則,丟棄數據包。
- ip_rcv_finish 函數路由判斷:隨后分組進入 ip_rcv_finish () 函數,根據 skb 結構中的目的或路由信息進行處理。若 skb->dst 無路由信息,則通過 ip_route_input () 查找路由,若目的地不可達,丟棄數據包。最后執行 dst_input,根據結果決定數據包下一步處理方式:本機分組由 ip_local_deliver 處理;需要轉發的數據由 ip_forward () 函數處理;組播數據包由 ip_mr_input () 函數處理。
- ip_forward 轉發數據包:若需轉發,ip_forward () 函數會先處理 IP 頭選項,記錄本地 IP 地址和時間戳等,確認分組可轉發后,將 TTL 減 1,若 TTL 為 0 則丟棄。接著根據 MTU 大小和路由信息對數據分組進行分片,最后將數據分組送往外出設備。若轉發失敗,則回應 ICMP 消息說明原因。之后執行 ip_forward_finish () 函數準備發送,再通過 dst_output (skb) 將分組發到轉發的目的主機或本地主機,最后調用 ip_finish_output () 進入鄰居子系統。
- ip_local_deliver 本地處理:對于本機分組,ip_local_deliver 中會對 ip 分片進行重組,經過 LOCAL_IN 鉤子點,然后調用 ip_local_deliver_finish。ip_local_deliver_finish 函數處理原始套接字的數據接收,并調用上層協議的包接收函數,將數據包傳遞到傳輸層。
1.4鏈路層:網絡通信的基石
鏈路層,如同高樓的地基,是網絡通信的基礎。它負責處理與物理網絡設備的直接交互,包括網卡驅動程序以及數據鏈路協議的實現。其主要功能是將網絡層傳來的數據包封裝成數據幀,并通過物理網絡介質進行傳輸。在接收數據時,則進行相反的操作,將接收到的數據幀解封裝,提取出數據包傳遞給網絡層。常見的鏈路層協議有以太網協議、PPP(Point-to-Point Protocol)協議等。例如,在以太網中,鏈路層會在數據包前后添加以太網頭部和尾部,形成以太網幀,其中頭部包含源 MAC 地址和目的 MAC 地址等信息,用于在局域網內標識數據的發送方和接收方。
功能上,在物理層提供比特流服務的基礎上,建立相鄰結點之間的數據鏈路,通過差錯控制提供數據幀(Frame)在信道上無差錯的傳輸,并進行各電路上的動作系列。數據鏈路層在不可靠的物理介質上提供可靠的傳輸。該層的作用包括:物理地址尋址、數據的成幀、流量控制、數據的檢錯、重發等。在這一層,數據的單位稱為幀(frame)。數據鏈路層協議的代表包括:SDLC、HDLC、PPP、STP、幀中繼等。
實現上,Linux 提供了一個 Network device 的抽象層,其實現在 linux/net/core/dev.c。具體的物理網絡設備在設備驅動中(driver.c)需要實現其中的虛函數。Network Device 抽象層調用具體網絡設備的函數。
 圖片
圖片
Part2.數據輸入:從網卡到內核的旅程
2.1網卡接收與中斷處理
在 Linux 系統中,網絡數據的輸入旅程始于網卡。網卡,作為計算機與網絡之間的物理接口,如同一位勤勞的快遞員,時刻監聽著網絡上的數據傳輸。當網卡接收到數據包時,它首先會進行初步的篩選。如果目的地址不是該網卡,且該網卡沒有開啟混雜模式,那么這個數據包就會被網卡無情地丟棄,就好像快遞員發現包裹不是送到自己負責的區域,便會直接退回。
 圖片
圖片
對于符合條件的數據包,網卡會通過 DMA(Direct Memory Access)技術,將其寫入到預先分配好的內存地址中。DMA 技術就像是一條數據高速公路,允許設備直接與內存進行數據傳輸,而無需 CPU 的頻繁干預,大大提高了數據傳輸的效率。例如,在一臺配備千兆網卡的服務器上,通過 DMA 技術,網卡可以快速地將大量的網絡數據包寫入內存,為后續的處理做好準備。
在完成數據寫入后,網卡會通過硬件中斷(IRQ)通知 CPU,就如同快遞員按響門鈴,告訴主人有新的包裹送達。硬件中斷是一種由硬件設備發出的電信號,它會使 CPU 立即暫停當前正在執行的任務,保存現場信息,然后跳轉到對應的中斷處理程序。在 Linux 系統中,每個硬件設備都有一個唯一的中斷號,用于標識該設備發出的中斷請求,這樣 CPU 就能準確地知道是哪個設備在請求服務。
2.2網絡驅動的接力
當 CPU 收到網卡發出的中斷信號后,會調用已經注冊的中斷函數,這個中斷函數會進一步調用到網卡驅動程序中相應的函數。網絡驅動程序就像是一位翻譯官,負責將網卡接收到的原始數據轉換為內核能夠理解的格式。
以常見的 e1000 網卡驅動為例,其硬中斷處理函數 e1000_intr () 會首先禁用網卡的中斷,表示驅動程序已經知曉內存中有數據,讓網卡下次收到數據包時直接寫入內存即可,無需再通知 CPU,以此提高效率,避免 CPU 被頻繁中斷。接著,啟動軟中斷,將耗時較長的數據處理任務交給軟中斷處理函數。
在軟中斷處理函數中,網絡驅動會從內存中讀取數據包,并將其轉換為內核網絡模塊能識別的 skb(socket buffer)格式。skb 是 Linux 內核中用于表示網絡數據包的數據結構,它包含了數據包的各種信息,如數據內容、源地址、目的地址等,就像是一個包裹的詳細清單,方便內核后續的處理。完成格式轉換后,驅動會調用 napi_gro_receive 函數,該函數會處理 GRO(Generic Receive Offload)相關的內容,即將可以合并的數據包進行合并,這樣就只需要調用一次協議棧,減少了系統開銷。
2.3網絡層的初次校驗
當數據包以 skb 格式進入網絡層后,首先會調用 ip_rcv 函數進行處理。這個函數就像是一位嚴格的質檢員,會對數據包進行多項嚴格的檢查,以確保數據包的完整性和正確性。
它會檢查數據包的 IP 首部長度是否符合要求。IP 首部包含了數據包的各種控制信息,如版本號、首部長度、服務類型、總長度等,如果首部長度不正確,那么數據包可能在傳輸過程中出現了錯誤,無法被正確處理。它還會檢查數據包的校驗和。校驗和是一種用于檢測數據傳輸錯誤的機制,通過對數據包的內容進行特定的算法計算得出一個值,接收方在收到數據包后,會重新計算校驗和并與發送方發送的校驗和進行比較,如果兩者不一致,就說明數據包在傳輸過程中可能發生了錯誤。
在進行這些基本檢查的同時,ip_rcv 函數還會與 netfilter 的 NF_IP_PRE_ROUTING 鉤子點交互。netfilter 是 Linux 內核中的一個框架,它提供了一系列的鉤子點,允許用戶通過編寫規則對網絡數據包進行過濾、修改等操作。例如,在一些網絡安全場景中,管理員可以通過在 NF_IP_PRE_ROUTING 鉤子點設置規則,對進入網絡層的數據包進行安全檢查,如檢測是否存在惡意攻擊的特征,如果發現可疑數據包,則可以直接丟棄或進行其他處理,從而保護系統的安全。
2.4路由決策與后續走向
經過網絡層的初次校驗后,數據包會進入 ip_rcv_finish 函數,在這里,路由決策將決定數據包的后續走向。路由決策就像是為數據包規劃一條旅行路線,根據數據包的目的 IP 地址,查找最佳的傳輸路徑。
在進行路由決策時,首先會檢查路由緩存項。路由緩存就像是一本常用路線的速查手冊,記錄了最近使用過的路由信息。如果在緩存中找到了匹配的路由項,那么就可以直接使用該路由項,大大提高了路由查找的效率。如果路由緩存未命中,就需要調用 ip_route_input_slow 函數查找路由表。路由表則是一本詳細的地圖集,包含了網絡中所有可能的路由信息。在查找路由表時,會根據目的 IP 地址、子網掩碼等信息,找到最佳的下一跳地址。
根據路由結果,數據包有兩種可能的走向。如果目的 IP 地址是本地主機的地址,那么數據包將走向本地交付,即被傳遞到本地的應用程序進行處理;如果目的 IP 地址是其他網絡主機的地址,那么數據包將被轉發到下一個網絡節點。在不同的走向下,會設置不同的處理函數。對于本地交付,會設置 ip_local_deliver 函數,負責將數據包傳遞到本地的傳輸層協議進行進一步處理;對于轉發,會設置 ip_forward 函數,負責將數據包轉發到合適的網絡接口,繼續其傳輸旅程。
2.5本地交付的深入剖析
當數據包被確定為本地交付后,會進入 ip_local_deliver 函數進行處理。在這個函數中,首先會對 IP 報文進行分片處理。在網絡傳輸過程中,由于不同網絡鏈路的最大傳輸單元(MTU)可能不同,當數據包的大小超過了鏈路的 MTU 時,就需要將數據包進行分片,將其拆分成多個較小的片段進行傳輸。例如,在一個以太網鏈路中,MTU 通常為 1500 字節,如果一個數據包的大小為 2000 字節,那么就需要將其分成兩個片段,分別為 1500 字節和 500 字節。
ip_local_deliver 函數會對這些分片進行重組,將它們還原成完整的數據包。它會根據 IP 首部中的分片標識、標志位和片偏移等信息,判斷各個分片之間的順序和關系,然后將它們正確地組合起來。完成分片重組后,數據包會被傳遞到 netfilter 的 NF_IP_LOCAL_IN 鉤子點,在這里,用戶可以再次對數據包進行過濾、修改等操作。經過 NF_IP_LOCAL_IN 鉤子點的處理后,數據包最終會到達傳輸層,根據其協議類型(如 TCP、UDP 等),被傳遞到相應的傳輸層協議模塊進行后續的處理,如 TCP 協議的連接管理、數據確認等。在實際的網絡場景中,分片處理非常重要。例如,當我們從互聯網上下載一個大型文件時,文件會被分成多個數據包進行傳輸,這些數據包可能會經過不同的網絡鏈路,由于各鏈路的 MTU 不同,數據包可能會被分片。如果接收方不能正確地對這些分片進行重組,那么就無法得到完整的文件,導致下載失敗。
Part3.數據輸出:從內核到網卡的征程
3.1傳輸層的發起
在 Linux 內核中,網絡數據的輸出是一個復雜而有序的過程,傳輸層在其中扮演著重要的發起角色。以常見的 TCP 和 UDP 協議為例,當應用程序調用 send () 或 sendto () 等系統調用發送數據時,數據首先進入傳輸層。
 圖片
圖片
對于 TCP 協議,以一個 Web 服務器向客戶端發送網頁數據為例,當 Web 服務器的應用程序調用 send () 函數時,數據會被傳遞到 TCP 層。TCP 層會為數據添加 TCP 首部,首部中包含源端口號、目的端口號、序列號、確認號等重要信息。這些信息就像是貨物運輸中的詳細清單,用于建立和維護可靠的連接。在這個過程中,TCP 協議會進行一系列的操作,如擁塞控制、流量控制等,以確保數據能夠穩定、高效地傳輸。擁塞控制就像是交通警察,通過調整發送窗口的大小,避免網絡擁塞,確保數據能夠順利傳輸;流量控制則是根據接收方的接收能力,調整發送方的發送速率,防止接收方緩沖區溢出。
而 UDP 協議則相對簡單,它不提供可靠的傳輸機制,也沒有擁塞控制和流量控制。在視頻直播應用中,為了保證直播的實時性,通常會使用 UDP 協議。當直播服務器調用 sendto () 函數發送視頻數據時,UDP 層同樣會添加 UDP 首部,首部包含源端口號和目的端口號等信息。由于 UDP 協議不需要建立連接,也不保證數據的可靠傳輸,所以它的傳輸效率較高,能夠滿足視頻直播對實時性的要求。
3.2 IP層的處理前奏
當數據從傳輸層傳遞到 IP 層后,首先會到達本地發送數據包在 netfilter 的 NF_IP_LOCAL_OUT 鉤子點。這個鉤子點就像是一個關卡,在這里可以對數據包進行各種自定義的處理,如過濾、修改等。
在一些安全防護場景中,管理員可能會在 NF_IP_LOCAL_OUT 鉤子點設置規則,對本地發送的數據包進行安全檢查。如果發現數據包中包含惡意代碼或違反安全策略的內容,就可以直接丟棄該數據包,從而保護系統的安全。而對于轉發的數據包,由于其來源并非本地生成,所以會跳過 NF_IP_LOCAL_OUT 鉤子點,直接進入后續的處理流程。
這是因為轉發數據包的處理邏輯與本地發送數據包有所不同,轉發數據包更關注的是如何快速、準確地將數據轉發到下一個網絡節點,而不是進行本地的安全檢查等操作。鉤子點的處理對數據包流向起著關鍵的控制作用,通過合理設置鉤子點的規則,可以實現對網絡數據的有效管理和安全防護。
3.3路由與協議設置
在經過 NF_IP_LOCAL_OUT 鉤子點的處理后,數據包會進入 ip_output 函數。在這個函數中,會進行一系列重要的設置,以確保數據包能夠正確地傳輸到目標地址。
ip_output 函數會根據數據包的目的 IP 地址,查找路由表,確定數據包應該從哪個網絡設備發送出去,以及下一跳的地址。這個過程就像是為數據包規劃一條旅行路線,根據目的地的不同,選擇最合適的交通路線。它會設置數據包的網絡設備和協議類型。以一個企業內部網絡為例,當一臺計算機要向外部網絡發送數據時,ip_output 函數會根據路由表的信息,選擇合適的出口網絡設備,如企業的網關設備,并將數據包的協議類型設置為 IP 協議。
完成這些設置后,數據包會被傳遞到 netfilter 的 NF_IP_INET_POST_ROUTING 鉤子點。在這個鉤子點,同樣可以對數據包進行一些最后的處理,如網絡地址轉換(NAT)等。NAT 技術可以將企業內部網絡的私有 IP 地址轉換為合法的公網 IP 地址,使得企業內部的計算機能夠訪問外部網絡。這些設置對數據包傳輸至關重要,它們確保了數據包能夠在復雜的網絡環境中準確無誤地找到自己的傳輸路徑,最終到達目標地址。
3.4數據分片與最終發送
當數據包到達 ip_finish_output 函數時,會對報文長度與 MTU(最大傳輸單元)進行比較。MTU 是指數據鏈路層一次能夠傳輸的最大數據量,不同的網絡鏈路類型,其 MTU 值也不同,例如以太網的 MTU 通常為 1500 字節。
如果報文長度超過了 MTU,就需要進行分片處理。這就好比將一個大包裹拆分成多個小包裹進行郵寄,以確保每個小包裹都能順利通過傳輸鏈路。在分片過程中,會為每個分片分配一個標識,以及片偏移等信息,以便在接收端能夠正確地重組這些分片。以一個發送大型文件的場景為例,假設文件被封裝成一個大小為 3000 字節的數據包,而網絡鏈路的 MTU 為 1500 字節,那么這個數據包就需要被分成兩個分片,第一個分片包含 1500 字節的數據,第二個分片包含剩余的 1500 字節數據。每個分片都會有自己的 IP 首部,首部中的標識字段相同,用于表示它們屬于同一個原始數據包,片偏移字段則表示該分片在原始數據包中的位置。
經過分片處理后,或者如果報文長度小于等于 MTU,數據包會通過鄰居子系統發送到網絡設備。鄰居子系統負責解析目標 IP 地址對應的 MAC 地址,就像是根據收件人的地址找到對應的門牌號。通過 ARP(地址解析協議)等機制,鄰居子系統可以獲取到目標 IP 地址對應的 MAC 地址,并將其添加到數據包的鏈路層首部中。最后,數據包會被發送到網絡設備,通過物理網絡介質傳輸到目標地址。在實際的網絡傳輸中,網絡帶寬是一個重要的因素。如果網絡帶寬較低,而數據包過大,就容易導致網絡擁塞,影響數據傳輸的效率。因此,分片處理可以將大的數據包拆分成多個小的分片,降低每個分片的大小,從而更有效地利用網絡帶寬,提高數據傳輸的成功率。
Part4.實例分析與代碼解讀
4.1選取典型場景
為了更直觀地理解 Linux 內核中網絡數據的輸入輸出流程,我們以 Web 服務器與客戶端的通信為例進行分析。在這個場景中,客戶端通過瀏覽器訪問 Web 服務器,請求獲取網頁內容。當我們在瀏覽器地址欄輸入網址并按下回車鍵后,一系列復雜的網絡數據交互就此展開。
首先,客戶端的瀏覽器會解析 URL,提取出服務器的域名和請求的資源路徑。接著,通過 DNS 解析將域名轉換為對應的 IP 地址。在獲取到服務器的 IP 地址后,客戶端與服務器之間建立 TCP 連接,這一過程通過著名的三次握手來完成。三次握手確保了雙方的通信連接是可靠的,就像在正式開始對話之前,雙方先確認彼此都準備好進行交流。
TCP 連接建立成功后,客戶端向服務器發送 HTTP 請求,請求中包含了請求方法(如 GET、POST 等)、請求頭和請求體等信息。服務器接收到 HTTP 請求后,會根據請求內容進行處理,可能會讀取相應的網頁文件或調用后端程序生成動態內容。然后,服務器將處理結果封裝在 HTTP 響應中返回給客戶端。客戶端收到 HTTP 響應后,對其進行解析,提取出網頁內容,并通過瀏覽器進行渲染,最終將網頁展示在用戶面前。當通信結束后,客戶端和服務器之間會通過四次揮手來斷開 TCP 連接。
4.2關鍵代碼片段解析
結合上述 Web 服務器與客戶端通信的場景,我們來看一些 Linux 內核中實現網絡數據輸入輸出的關鍵代碼片段。
在網絡數據輸入方面,當網卡接收到數據包時,會觸發中斷處理程序。以 e1000 網卡驅動為例,其硬中斷處理函數如下:
irqreturn_t e1000_intr(int irq, void *data) {
struct e1000_adapter *adapter = data;
struct e1000_ring *rx_ring;
struct sk_buff *skb;
u32 status;
int work_done = 0;
// 禁用網卡中斷
e1000_disable_irq(adapter);
// 遍歷接收隊列
for (rx_ring = adapter->rx_ring; rx_ring; rx_ring = rx_ring->next) {
// 循環處理接收隊列中的數據包
while ((status = e1000_clean_rx_irq(adapter, rx_ring))) {
// 從接收隊列中獲取skb
skb = e1000_rx_skb(adapter, rx_ring);
if (skb) {
// 將skb傳遞給協議棧
netif_receive_skb(skb);
work_done++;
}
}
}
// 啟動軟中斷
napi_schedule(&adapter->napi);
// 恢復網卡中斷
e1000_enable_irq(adapter);
return IRQ_RETVAL(work_done);
}在這段代碼中,首先禁用網卡中斷,以避免在處理當前中斷時再次被中斷。然后遍歷接收隊列,調用 e1000_clean_rx_irq 函數清理接收隊列中的數據包,并通過 e1000_rx_skb 函數將數據包轉換為 skb 格式。接著,使用 netif_receive_skb 函數將 skb 傳遞給協議棧進行后續處理。最后,啟動軟中斷,并恢復網卡中斷。
在網絡數據輸出方面,當應用程序調用 send () 函數發送數據時,最終會調用到 tcp_sendmsg 函數。下面是 tcp_sendmsg 函數的簡化代碼:
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size) {
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
int err, copied;
// 分配skb
skb = alloc_skb(size + TCP_HEADER_LEN, GFP_KERNEL);
if (!skb)
return -ENOMEM;
// 設置skb的相關信息
skb_reserve(skb, TCP_HEADER_LEN);
skb->data_len = size;
skb->len = size + TCP_HEADER_LEN;
// 將用戶數據拷貝到skb中
copied = skb_add_data(skb, msg->msg_iov->iov_base, size);
if (copied < size) {
// 拷貝失敗,釋放skb
kfree_skb(skb);
return -EFAULT;
}
// 設置TCP首部信息
tcp_init_skb(skb, sk);
// 調用網絡層發送接口
err = ip_queue_xmit(skb, &(inet->cork.fl));
if (err) {
// 發送失敗,釋放skb
kfree_skb(skb);
}
return err? err : size;
}在這段代碼中,首先分配一個 skb,并預留出 TCP 首部的空間。然后將用戶數據從應用層拷貝到 skb 中,并設置 TCP 首部的相關信息。最后,調用 ip_queue_xmit 函數將 skb 傳遞給網絡層進行發送。如果發送過程中出現錯誤,會釋放 skb 并返回錯誤信息。
通過對這些關鍵代碼片段的解析,我們可以更深入地理解 Linux 內核中網絡數據輸入輸出的實際代碼邏輯,感受到內核開發者在實現網絡通信功能時的精妙設計和嚴謹思考。