o3通關(guān)「俄羅斯方塊」,碾壓Gemini奪冠!UCSD新基準(zhǔn)擊碎寶可夢(mèng)
誰(shuí)能想到,作為童年回憶的寶可夢(mèng),現(xiàn)在竟搖身一變,成了大模型的試金石!
在無(wú)數(shù)人的童年記憶中,《寶可夢(mèng)》是一款意義非凡的游戲——簡(jiǎn)單的操作哪怕是年紀(jì)尚小的孩子也能輕松上手。
然而,要真正通關(guān)這款游戲,仍然需要縝密的規(guī)劃和大量的時(shí)間投入。
如今,這款承載童年回憶的游戲,已悄然成為各大科技公司測(cè)試最新LLM的「香餑餑」。
從Anthropic到Google,從Claude到Gemini,各家模型紛紛亮出「通關(guān)寶可夢(mèng)」的戰(zhàn)績(jī)作為展示推理、規(guī)劃與長(zhǎng)期記憶能力的證據(jù)。
而且通關(guān)后,谷歌的CEO劈柴都要親自發(fā)帖來(lái)慶祝。
 圖片
圖片
真的令人好奇,都2025年了,為何AI通關(guān)《寶可夢(mèng)》就成了個(gè)大新聞?
更何況,寶可夢(mèng)最早的發(fā)售是1995年,30年前的游戲?yàn)楹纬蔀榱藱z驗(yàn)最新AI頂級(jí)模型的試金石?
這是因?yàn)樽钕冗M(jìn)的AI也不一定擁有人類幼兒的感知和行動(dòng)能力。
莫拉維克悖論
在LLM還未出現(xiàn)的1980年代,早期的人工智能似乎已經(jīng)開始展現(xiàn)「智慧」。
人工智能的先驅(qū)漢斯·莫拉維克、羅德尼·布魯克斯、馬文·閔斯基等人發(fā)現(xiàn)一個(gè)悖論。
要讓電腦如成人般地下棋是相對(duì)容易的,但是要讓電腦有如一歲小孩般的感知和行動(dòng)能力卻是相當(dāng)困難甚至是不可能的。
語(yǔ)言學(xué)家和認(rèn)知科學(xué)家史迪芬·平克認(rèn)為這是人工智能學(xué)者的最重要發(fā)現(xiàn)。經(jīng)過(guò)35年人工智能的研究,他發(fā)現(xiàn)最重要的課題是:
困難的問(wèn)題是易解的,簡(jiǎn)單的問(wèn)題是難解的。
四歲小孩具有的本能——辨識(shí)人臉、舉起鉛筆、在房間內(nèi)走動(dòng)、回答問(wèn)題——事實(shí)上卻是工程領(lǐng)域內(nèi)目前為止最難解的問(wèn)題。
當(dāng)新一代的AI出現(xiàn)后,股票分析師、石化工程師都要小心他們的位置被取代,但是園丁、接待員和廚師至少十年內(nèi)都不用擔(dān)心被人工智能所取代。
這也是目前所有頂級(jí)模型都希望通過(guò)寶可夢(mèng)游戲證明的——目前的LLM到底有沒(méi)有感知能力?
 圖片
圖片
Claude Opus 4還在直播玩寶可夢(mèng),已經(jīng)繼續(xù)了12萬(wàn)+步。
寶可夢(mèng)作為評(píng)測(cè)基準(zhǔn),合理嗎?
寶可夢(mèng)被越來(lái)越多地用于評(píng)估現(xiàn)代大型語(yǔ)言模型,但存在一個(gè)很大的問(wèn)題——目前的挑戰(zhàn)都缺乏標(biāo)準(zhǔn)化。
Anthropic為Cladue模型提供了導(dǎo)航和讀取游戲狀態(tài)內(nèi)存的工具。
該模型進(jìn)行了幾場(chǎng)道館對(duì)戰(zhàn),大約執(zhí)行了35,000個(gè)游戲內(nèi)動(dòng)作才到達(dá)電系道館首領(lǐng)。
但Anthropic并未詳細(xì)說(shuō)明什么具體算作一個(gè)「動(dòng)作」,也未說(shuō)明允許多少次重試。
 圖片
圖片
Google的Gemini 2.5 Pro已經(jīng)完成了《寶可夢(mèng) 藍(lán)》(并在《寶可夢(mèng) 紅》中獲得了第五個(gè)徽章)。
然而,它依賴額外的外部代碼來(lái)提取更全面的游戲狀態(tài)文本表示并指導(dǎo)決策。
 圖片
圖片
并且運(yùn)行完成游戲需要大量的時(shí)間,僅獲得第五個(gè)徽章,就需要超過(guò)500個(gè)小時(shí)。
同時(shí)API的使用會(huì)產(chǎn)生大量費(fèi)用。
如何才能將大模型最愛(ài)玩的《寶可夢(mèng)》游戲轉(zhuǎn)化為標(biāo)準(zhǔn)化評(píng)估框架,甚至是多種游戲的評(píng)估框架?
這就是今天介紹的Lmgame Bench,它精心選取了一批難度適中的游戲,并提供了分層測(cè)試機(jī)制,更適合衡量大模型的真實(shí)能力。
 圖片
圖片
博客地址:https://lmgame.org/#/blog/pokemon_red
該測(cè)試基準(zhǔn)由UCSD等重磅出品,研究了如何使用流行的視頻游戲來(lái)評(píng)估現(xiàn)代LLM。
 圖片
圖片
論文地址:https://arxiv.org/pdf/2505.15146
Lmgame基準(zhǔn)測(cè)試
Lmgame Bench使用模塊化測(cè)試框架——如感知、記憶和推理模塊——系統(tǒng)地?cái)U(kuò)展模型的游戲能力。
這些測(cè)試框架使模型能夠通過(guò)迭代交互循環(huán)與模擬游戲環(huán)境進(jìn)行交互。
Lmgame-Bench采用了一種標(biāo)準(zhǔn)化的提示優(yōu)化技術(shù),以降低對(duì)提示的敏感性。
 圖片
圖片
為了在沒(méi)有任何外部定制游戲「腳手架」的情況下區(qū)分模型能力,Lmgame Bench精選了一系列中等難度的視頻游戲。
這些游戲包括:
推箱子:得分計(jì)算方式為所有關(guān)卡中推到目標(biāo)位置的箱子總數(shù),統(tǒng)計(jì)范圍從非常簡(jiǎn)單的關(guān)卡一直到Sokoban 1989中最難的關(guān)卡,直到出現(xiàn)第一個(gè)死局為止。
 圖片
圖片
超級(jí)馬里奧兄弟:分?jǐn)?shù)是馬里奧在所有關(guān)卡中累計(jì)的橫向移動(dòng)距離(游戲單位),直到失去全部三條生命或完成最終關(guān)卡為止。具備更強(qiáng)物理直覺(jué)和空間推理能力的模型通常能夠獲得更高的分?jǐn)?shù)。
 圖片
圖片
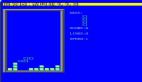
俄羅斯方塊:分?jǐn)?shù)是已注冊(cè)的總方塊數(shù)加上消除的總行數(shù)(乘以10倍系數(shù)),計(jì)算至游戲結(jié)束為止。不同的模型持續(xù)游戲的時(shí)間各不相同,這取決于它們高效處理下落方塊的能力。例如,o3-pro能夠有效清除超過(guò)10行,從而持續(xù)保持游戲進(jìn)行。
 圖片
圖片
2048:合并方塊值的總和(例如,合并兩個(gè)2會(huì)獲得+4),記錄直到棋盤停滯(連續(xù)十次回合沒(méi)有合并或改變棋盤的移動(dòng))。然后我們會(huì)報(bào)告它們的總得分。由于游戲可以持續(xù)超過(guò)10萬(wàn)步,這為區(qū)分模型在較長(zhǎng)時(shí)間范圍內(nèi)的能力提供了強(qiáng)有力的依據(jù)。
 圖片
圖片
糖果消除:在固定的50步會(huì)話中消除的糖果總數(shù)。盡管游戲相對(duì)簡(jiǎn)單,但它能有效區(qū)分模型在優(yōu)化移動(dòng)步驟和清除糖果方面的能力。
 圖片
圖片
逆轉(zhuǎn)裁判:在所有案件關(guān)卡中正確操作(提交證據(jù)、對(duì)話選擇等)的總次數(shù),直到用盡五次錯(cuò)誤決定機(jī)會(huì)(生命值)。此游戲用于評(píng)估模型的上下文理解和推理能力。
 圖片
圖片
模塊設(shè)計(jì)
許多模型在視覺(jué)理解上存在脆弱性,導(dǎo)致對(duì)游戲狀態(tài)頻繁誤判。
想要在游戲中取得成功,需要有效的記憶機(jī)制來(lái)實(shí)現(xiàn)長(zhǎng)期決策。
Lmgame針對(duì)性的開發(fā)了三大模塊。
感知模塊:將原始游戲幀或UI元素轉(zhuǎn)換為結(jié)構(gòu)化的符號(hào)/文本狀態(tài)描述,減少對(duì)脆弱視覺(jué)的依賴。
內(nèi)存模塊:存儲(chǔ)最近的狀態(tài)、動(dòng)作和反思筆記,以縮小動(dòng)作空間并支持長(zhǎng)期規(guī)劃。
推理模塊:綜合所有其他模塊的信息,并可選地開啟長(zhǎng)鏈?zhǔn)剿季S推理。
 o3玩2048的記憶模塊展示
o3玩2048的記憶模塊展示
Gym風(fēng)格標(biāo)準(zhǔn)接口
不過(guò)研究人員發(fā)現(xiàn),使用計(jì)算機(jī)直接操作智能體進(jìn)行基準(zhǔn)測(cè)試存在重大缺陷。
每款游戲都對(duì)計(jì)算機(jī)的操作要求不同,依賴基于屏幕截圖的觀測(cè)容易出現(xiàn)感知錯(cuò)誤。
 圖片
圖片
并且在對(duì)延遲敏感的的游戲中存在不可預(yù)測(cè)的延遲,這些問(wèn)題都削弱了測(cè)試結(jié)果的一致性和可比性。
為此研究團(tuán)隊(duì)實(shí)現(xiàn)了一個(gè)采用Gym風(fēng)格API的新標(biāo)準(zhǔn)化接口,來(lái)統(tǒng)一評(píng)估設(shè)置。
結(jié)合輕量級(jí)的感知與記憶輔助模塊設(shè)計(jì),穩(wěn)定提示帶來(lái)的差異并消除數(shù)據(jù)污染。
 圖片
圖片
在13個(gè)領(lǐng)先模型上的實(shí)驗(yàn)表明,Lmgame-Bench具有挑戰(zhàn)性,同時(shí)仍能有效區(qū)分不同模型。
 圖片
圖片
排行榜前列由o3占據(jù),這款模型以其強(qiáng)大的視覺(jué)感知、空間推理和長(zhǎng)視野規(guī)劃能力而著稱。
不過(guò)令人意外的是,o3雖然完全拿下了2048、推箱子和俄羅斯方塊,但是在糖果消除中遠(yuǎn)遠(yuǎn)落后。
 圖片
圖片
現(xiàn)在,借助Lmgame提供的開源代碼,任何人都可以通過(guò)一條命令為任何受支持的模型-游戲組合啟動(dòng)評(píng)估。
 圖片
圖片
近期所有模型的進(jìn)步表明,在數(shù)學(xué)和編程任務(wù)重,整合強(qiáng)化學(xué)習(xí)可以顯著增強(qiáng)LLMs的推理能力。
即使是最簡(jiǎn)單的RL算法也能改善模型的規(guī)劃和決策能力,這種能力在與復(fù)雜環(huán)境互動(dòng)時(shí)顯得尤為重要。
這些進(jìn)展凸顯了游戲環(huán)境作為評(píng)估LLMs的有效基準(zhǔn)作用。
過(guò)去那些經(jīng)典的游戲經(jīng)過(guò)精心的設(shè)計(jì),用來(lái)挑戰(zhàn)人類的思維和認(rèn)知能力。
 圖片
圖片
同樣地,這些游戲是極具價(jià)值但尚未被充分利用的AI基準(zhǔn)測(cè)試資源。
同時(shí),在經(jīng)典游戲之外,我們現(xiàn)在還有眾多的3A大作,可以預(yù)見,未來(lái)的評(píng)估體系將具有高度可擴(kuò)展的發(fā)展路徑。
 圖片
圖片
Lmgame Bench的誕生,正是在這個(gè)背景下給出答案:真正的智能不僅要能寫代碼、做數(shù)學(xué)題,更要能在復(fù)雜、開放、動(dòng)態(tài)的環(huán)境中持續(xù)思考、規(guī)劃并行動(dòng)。
而這場(chǎng)測(cè)試,還遠(yuǎn)未結(jié)束。