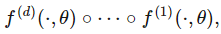神經網絡的泛化能力:數學分析與提升策略
從圖像識別到語音處理,從自然語言理解到復雜系統的預測,神經網絡的應用無處不在。
然而,一個關鍵問題始終困擾著研究人員和實踐者:神經網絡的泛化能力。
泛化能力決定了神經網絡在面對新的、未見過的數據時,能否準確地進行預測和決策。
本文將深入探討神經網絡的泛化能力,從數學的角度進行分析,并提出有效的提升策略,幫助讀者更好地理解和應用神經網絡。
PART1.泛化能力的數學定義
首先,我們用一個簡單的例子來解釋泛化能力。假設你正在訓練一個神經網絡模型來識別貓和狗的圖片。在訓練過程中,模型看到了大量的貓和狗的圖片,并學會了區分它們。
 圖片
圖片
但是,當模型遇到一張它從未見過的貓的圖片時,它能否正確地識別出這是一只貓呢?這就是泛化能力所關注的問題。
泛化能力是指神經網絡在新的、未見過的數據上表現的能力。
在數學上,泛化能力可以通過泛化誤差來定義。泛化誤差是指神經網絡在真實數據分布上的誤差,即網絡在所有可能的數據上的平均誤差。用公式表示為:

以下是衡量模型泛化能力的常見指標:
1. 測試誤差:測試誤差是衡量泛化能力最直接的方法。它是在獨立的測試數據集上計算的誤差。
 圖片
圖片
測試數據集是網絡在訓練過程中從未見過的數據,因此測試誤差能夠很好地反映網絡在新數據上的表現。
2. 交叉驗證誤差:交叉驗證是一種更穩健的評估方法。它將數據集分成多個子集,每次用其中一個子集作為測試集,其余子集作為訓練集。
 圖片
圖片
通過多次訓練和測試,計算平均誤差來評估網絡的泛化能力。這種方法可以減少測試誤差的偶然性,更準確地反映網絡的泛化性能。
3. 泛化誤差的估計:在實際應用中,我們通常無法直接計算泛化誤差,因為它涉及到對真實數據分布的期望。
 圖片
圖片
但是,我們可以通過一些統計方法來估計泛化誤差。例如,使用 Hoeffding 不等式可以給出泛化誤差的一個概率上界,幫助我們了解網絡泛化能力的可靠性。
PART2.影響泛化能力的因素分析
模型的泛化能力是衡量其在未見過的新數據上表現能力的關鍵指標,而模型復雜度、數據質量與數量、訓練算法與優化策略是影響泛化能力的三個主要因素。以下是對這些因素的詳細分析:
1.設計思想
模型復雜度是影響泛化能力的關鍵因素之一。一個復雜的神經網絡模型,如深度很大的網絡或參數數量很多的網絡,具有很強的擬合能力。
它可以完美地擬合訓練數據,甚至包括數據中的噪聲。然而,這種過度擬合會導致網絡在新的數據上表現不佳。
 圖片
圖片
例如,一個過擬合的網絡可能會將訓練數據中的某些特定特征誤認為是分類的依據,而在測試數據中這些特征可能并不存在,從而導致錯誤的預測。
另一方面,如果模型過于簡單,也可能導致泛化能力不足。
這種情況下,網絡無法捕捉到數據中的復雜模式,從而在訓練數據和測試數據上都表現不佳。
 圖片
圖片
例如,一個只有幾層的簡單神經網絡可能無法有效地學習到圖像中復雜的紋理和形狀特征,導致分類錯誤率較高。
2.數據質量與數量
高質量的數據對于神經網絡的泛化能力至關重要。數據質量包括數據的準確性、完整性和代表性。
如果數據中存在錯誤或缺失值,或者數據不能很好地代表真實世界的情況,那么網絡的泛化能力將受到嚴重影響。
 圖片
圖片
例如,在一個醫療診斷任務中,如果訓練數據中的病例不完整或存在錯誤診斷,那么網絡可能會學習到錯誤的模式,導致在實際應用中誤診。
數據數量也是影響泛化能力的重要因素。一般來說,數據量越大,網絡的泛化能力越強。
更多的數據可以提供更豐富的信息,幫助網絡更好地學習數據中的模式和規律。
例如,在一個語言模型中,大量的文本數據可以幫助網絡學習到語言的復雜結構和語義關系,從而在生成文本或翻譯文本時表現得更好。
3.訓練算法與優化策略
不同的訓練算法對神經網絡的泛化能力有不同的影響。
 圖片
圖片
例如,隨機梯度下降(SGD)算法在訓練過程中引入了隨機性,這有助于網絡跳出局部最優解,找到更全局的最優解,從而提高泛化能力。
而一些更復雜的優化算法,如 Adam 或 RMSprop,雖然在訓練速度上可能更快,但在某些情況下可能會導致網絡過擬合。
正則化技術是提高泛化能力的重要手段。常見的正則化方法包括 L1 和 L2 正則化。
L1 正則化通過在損失函數中加入參數的絕對值來懲罰模型的復雜度,促使網絡學習到更稀疏的參數。
 圖片
圖片
L2 正則化則通過加入參數的平方來懲罰模型的復雜度,使網絡的參數更平滑。
這些正則化技術可以有效地防止網絡過擬合,提高泛化能力。
PART3.提升泛化能力的數學策略
為了提升模型的泛化能力,可以采用以下數學策略:數據增強、正則化、早停法。
這些策略從不同的角度出發,通過增加數據的多樣性、限制模型的復雜度以及合理控制訓練過程,有效地提高了模型在未見過的新數據上的表現。
1.正則化
如上所述,L1 和 L2 正則化是兩種常用的模型正則化方法。
通過對模型參數的范數進行約束,有效地防止模型過度擬合訓練數據,使模型在新數據上具有更好的泛化能力。
Dropout 則是另一種特殊的正則化技術。
在訓練過程中,Dropout 隨機地丟棄網絡中的一些神經元,使網絡在每次訓練時都使用不同的子網絡。
 圖片
圖片
這種方法可以防止神經元之間的共適應,提高網絡的泛化能力。
例如,在一個深度神經網絡中,使用 Dropout 可以使網絡在訓練過程中學習到更魯棒的特征,從而在測試數據上表現更好。
2.早停法
早停法是一種在訓練過程中提前停止訓練的方法,以防止網絡過擬合。其基本原理是通過監控網絡在驗證集上的誤差,在誤差開始上升時停止訓練。
從數學角度來看,早停法可以通過監控驗證誤差的變化來實現。
假設驗證誤差為 驗證,訓練誤差為 訓練,那么早停法的目標是找到一個合適的停止點 ,使得 驗證 最小化。具體來說,早停法可以通過以下步驟實現:
- 初始化網絡參數 。
- 在每個訓練步驟 上,計算訓練誤差 訓練 和驗證誤差 驗證。
- 如果 驗證 在連續 個步驟上沒有下降,則停止訓練,返回當前的網絡參數 。
 圖片
圖片
如上圖,當網絡開始過擬合時,驗證誤差會逐漸增加,而訓練誤差會繼續下降。
所以,通過早停法在網絡過擬合之前停止訓練,可以有效地防止網絡過擬合,提高泛化能力。同時,也可以節省訓練時間,提高訓練效率。
3.數據增強
數據增強是一種通過生成新的訓練數據來提高泛化能力的方法。它的基本原理是通過對原始數據進行變換,如旋轉、縮放、裁剪、顏色調整等,生成新的數據樣本。
從數學角度來看,數據增強可以通過數據分布的擴展來描述。
假設原始數據的分布為 原始,通過數據增強生成的新數據的分布為 增強,那么數據增強的目標是使 增強 更接近真實數據分布 真實。
這些新的數據樣本在一定程度上模擬了真實世界中的數據變化,從而幫助網絡學習到更魯棒的特征。
 圖片
圖片
例如,在圖像識別任務中,通過對圖像進行旋轉和縮放,網絡可以學習到物體在不同角度和大小下的特征,從而在面對新的圖像時能夠更準確地識別。
結 語
在本文中,我們深入探討了神經網絡的泛化能力,從數學的角度進行了分析,并提出了多種提升策略。
我們首先定義了泛化能力,并介紹了衡量泛化能力的指標,如測試誤差和交叉驗證誤差。
然后,我們分析了影響泛化能力的因素,包括模型復雜度、數據質量與數量以及訓練算法與優化策略。
接著,我們提出了多種提升泛化能力的策略,如數據增強、模型正則化和早停法。