月之暗面開源音頻模型Kimi-Audio,從「語音轉文字」到「讀心對話」,讓AI聽懂人類 “弦外之音”!
近期,Kimi在語音交互領域發布了Kimi-Audio模型,這是一個開源音頻基礎模型,在音頻理解、生成和對話方面表現出色。

AI讓機器不僅 “聽到” 聲音,更能 “聽懂” 語言背后的情感、意圖和語境。Kimi-Audio 的核心突破,在于構建了一個全流程端到端的實時語音對話系統。能夠在一個統一的框架內處理各種音頻處理任務。主要功能包括:
- 通用功能:處理各種任務,如自動語音識別 (ASR)、音頻問答 (AQA)、自動音頻字幕 (AAC)、語音情感識別 (SER)、聲音事件/場景分類 (SEC/ASC) 和端到端語音對話。
- 最先進的性能:在眾多音頻基準測試中取得 SOTA 結果(參見評估和技術報告)。
- 大規模預訓練:對超過 1300 萬小時的不同音頻數據(語音、音樂、聲音)和文本數據進行預訓練,實現強大的音頻推理和語言理解。
- 新穎的架構:采用混合音頻輸入(連續聲學向量+離散語義標記)和具有并行頭的 LLM 核心來生成文本和音頻標記。
- 高效推理:采用基于流匹配的分塊流式去標記器,實現低延遲音頻生成。
- 開源:發布預訓練和指令微調的代碼和模型檢查點,并發布全面的評估工具包以促進社區研究和開發。
相關鏈接
- 論文:
- 模型:https://huggingface.co/moonshotai/Kimi-Audio-7B
- 代碼:https://github.com/MoonshotAI/Kimi-Audio
論文介紹
 Kimi-Audio是一個在音頻理解、生成和對話方面表現卓越的開源音頻基礎模型。論文介紹了 Kimi-Audio 的構建實踐,包括模型架構、數據整理、訓練方案、推理部署和評估。
Kimi-Audio是一個在音頻理解、生成和對話方面表現卓越的開源音頻基礎模型。論文介紹了 Kimi-Audio 的構建實踐,包括模型架構、數據整理、訓練方案、推理部署和評估。
具體而言,我們利用 12.5Hz 音頻分詞器,設計了一種基于 LLM 的新型架構,以連續特征作為輸入,以離散分詞作為輸出,并開發了一個基于流匹配的分塊式流式去分詞器。作者整理了一個包含超過 1300 萬小時音頻數據的預訓練數據集,涵蓋語音、聲音和音樂等多種模態,并構建了用于構建高質量且多樣化的訓練后數據的流水線。Kimi-Audio 基于預訓練的 LLM 進行初始化,并通過多個精心設計的任務,在音頻和文本數據上進行持續預訓練,然后進行微調以支持各種音頻相關任務。
廣泛的評估表明,Kimi-Audio 在一系列音頻基準測試中均達到了最佳性能,包括語音識別、音頻理解、音頻問答和語音對話。
架構概述
 Kimi-Audio 由三個主要組件組成:
Kimi-Audio 由三個主要組件組成:
- 音頻標記器:將輸入音頻轉換為:使用矢量量化的離散語義標記(12.5Hz)。來自 Whisper 編碼器的連續聲學特征(下采樣至 12.5Hz)。
- 音頻 LLM:基于轉換器的模型(由預訓練的文本 LLM(如 Qwen 2.5 7B)初始化),具有處理多模態輸入的共享層,然后是并行頭,用于自回歸生成文本標記和離散音頻語義標記。
- 音頻解析器:使用流匹配模型和聲碼器(BigVGAN)將預測的離散語義音頻標記轉換回高保真波形,支持分塊流傳輸,并采用前瞻機制實現低延遲。
評估
Kimi-Audio 在廣泛的音頻基準測試中實現了最先進的 (SOTA) 性能。
以下是整體表現:
在各種基準測試中的表現。") Kimi-Audio 與之前的音頻語言模型(包括 Qwen2-Audio、Baichuan Audio、Step-Audio 和 Qwen2.5-Omni)在各種基準測試中的表現。
Kimi-Audio 與之前的音頻語言模型(包括 Qwen2-Audio、Baichuan Audio、Step-Audio 和 Qwen2.5-Omni)在各種基準測試中的表現。

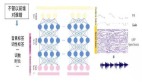
音頻預訓練數據的處理流程

Kimi-Audio 中用于實時語音對話的客戶端-服務器通信。 Kimi-Audio 實時語音對話生產部署流程
Kimi-Audio 實時語音對話生產部署流程