卷積網(wǎng)絡(luò)又雙叒叕行了?OverLoCK:一種仿生的卷積神經(jīng)網(wǎng)絡(luò)視覺基礎(chǔ)模型
作者是香港大學(xué)俞益洲教授與博士生婁蒙。
你是否注意過人類觀察世界的獨(dú)特方式?
當(dāng)面對(duì)復(fù)雜場景時(shí),我們往往先快速獲得整體印象,再聚焦關(guān)鍵細(xì)節(jié)。這種「縱觀全局 - 聚焦細(xì)節(jié)(Overview-first-Look-Closely-next)」的雙階段認(rèn)知機(jī)制是人類視覺系統(tǒng)強(qiáng)大的主要原因之一,也被稱為 Top-down Attention。
雖然這種機(jī)制在許多視覺任務(wù)中得到應(yīng)用,但是如何利用這種機(jī)制來構(gòu)建強(qiáng)大的 Vision Backbone 卻尚未得到充分研究。
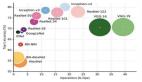
近期,香港大學(xué)將這種認(rèn)知模式引入到了 Vision Backbone 的設(shè)計(jì)中,從而構(gòu)建了一種全新的基于動(dòng)態(tài)卷積的視覺基礎(chǔ)模型,稱為 OverLoCK (Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels)。該模型在 ImageNet、COCO、ADE20K 三個(gè)極具挑戰(zhàn)性的數(shù)據(jù)集上展現(xiàn)出了強(qiáng)大的性能。例如,30M 的參數(shù)規(guī)模的 OverLoCK-Tiny 模型在 ImageNet-1K 達(dá)到了 84.2% 的 Top-1 準(zhǔn)確率,相比于先前 ConvNet, Transformer 與 Mamba 模型具有明顯的優(yōu)勢(shì)。

論文標(biāo)題:OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels
論文鏈接:https://arxiv.org/abs/2502.20087
代碼鏈接:https://github.com/LMMMEng/OverLoCK
動(dòng)機(jī)
Top-down Attention 機(jī)制中的一個(gè)關(guān)鍵特性是利用大腦獲得的反饋信號(hào)作為顯式的信息指導(dǎo),從而在場景中定位關(guān)鍵區(qū)域。然而,現(xiàn)有大多數(shù) Vision Backbone 網(wǎng)絡(luò)(例如 Swin, ConvNeXt, 和 VMamba)采用的仍然是經(jīng)典的金字塔架構(gòu):從低層到高層逐步編碼特征,每層的輸入特征僅依賴于前一層的輸出特征,導(dǎo)致這些方法缺乏顯式的自上而下的語義指導(dǎo)。因此,開發(fā)一種既能實(shí)現(xiàn) Top-down Attention 機(jī)制,又具有強(qiáng)大性能的卷積網(wǎng)絡(luò),仍然是一個(gè)懸而未決的問題。
通常情況下,Top-down Attention 首先會(huì)生成較為粗糙的全局信息作為先驗(yàn)知識(shí),為了充分利用這種信息,token mixer 應(yīng)該具備強(qiáng)大動(dòng)態(tài)建模能力。具體而言,token mixer 應(yīng)當(dāng)既能形成大感受野來自適應(yīng)地建立全局依賴關(guān)系,又能保持局部歸納偏置以捕捉精細(xì)的局部特征。然而我們發(fā)現(xiàn),現(xiàn)有的卷積方法無法同時(shí)滿足這些需求:不同于 Self-attention 和 SSM 能夠在不同輸入分辨率下自適應(yīng)建模長距離依賴,大核卷積和動(dòng)態(tài)卷積由于固定核尺寸的限制,即使面對(duì)高分辨率輸入時(shí)仍局限于有限區(qū)域。此外,盡管 Deformable 卷積能在一定程度上緩解這個(gè)問題,但其可變的 kernel 形態(tài)會(huì)犧牲卷積固有的歸納偏置,從而會(huì)弱化局部感知能力。因此,如何在保持強(qiáng)歸納偏置的前提下,使純卷積網(wǎng)絡(luò)獲得與 Transformer 和 Mamba 相媲美的動(dòng)態(tài)全局建模能力,同樣是亟待解決的關(guān)鍵問題。
方法
讓 Vision Backbone 網(wǎng)絡(luò)具備人類視覺的「兩步走」機(jī)制
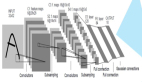
研究團(tuán)隊(duì)從神經(jīng)科學(xué)獲得關(guān)鍵啟發(fā):人類視覺皮層通過 Top-down Attention,先形成整體認(rèn)知再指導(dǎo)細(xì)節(jié)分析(Overview-first-Look-Closely-next)。據(jù)此,研究團(tuán)隊(duì)摒棄了先前 Vision Backbone 網(wǎng)絡(luò)中經(jīng)典的金字塔策略,轉(zhuǎn)而提出了一種新穎的深度階段分解(DDS, Deep-stage Decomposition) 策略來構(gòu)建 Vision Backbone 網(wǎng)絡(luò),該機(jī)制構(gòu)建的 Vision Backbone 具有 3 個(gè)子模型:
- Base-Net:聚焦于提取中低層特征,相當(dāng)于視覺系統(tǒng)的「視網(wǎng)膜」,利用了 UniRepLKNet 中的 Dilated RepConv Layer 來作為 token mixer,從而實(shí)現(xiàn)高效的 low-level 信息感知。
- Overview-Net:提取較為粗糙的高級(jí)語義信息,完成「第一眼認(rèn)知」。同樣基于 Dilated RepConv Layer 為 token mixer,快速獲得 high-level 語義信息作為 Top-down Guidance。
- Focus-Net:在全局先驗(yàn)知識(shí)的引導(dǎo)下進(jìn)行精細(xì)分析,實(shí)現(xiàn)「凝視觀察」。基于一種全新的動(dòng)態(tài)卷積 ContMix 和一種 Gate 機(jī)制來構(gòu)建基本 block,旨在充分利用 Top-down Guidance 信息。
來自 Overview-Net 的 Top-down Guidance 不僅會(huì)在特征和 kernel 權(quán)重兩個(gè)層面對(duì) Focus-Net 進(jìn)行引導(dǎo),還會(huì)沿著前向傳播過程在每個(gè) block 中持續(xù)更新。具體而言,Top-down Guidance 會(huì)同時(shí)參與計(jì)算 Gate 和生成動(dòng)態(tài)卷積權(quán)重,還會(huì)整合到 feature map 中,從而全方位地將 high-level 語義信息注入到 Focus-Net 中,獲得更為魯棒的特征表示能力。

圖 1 OverLoCK 模型整體框架和基本模塊

圖 2 ContMix 框架圖
具有強(qiáng)大 Context-Mixing 能力的動(dòng)態(tài)卷積 --- ContMix
為了能夠更好地適應(yīng)不同輸入分辨率,同時(shí)保持強(qiáng)大的歸納偏置,進(jìn)而充分利用 Overview-Net 提供的 Top-down Guidance,研究團(tuán)隊(duì)提出了一種新的動(dòng)態(tài)卷積模塊 --- ContMix。其核心創(chuàng)新在于通過計(jì)算特征圖中每個(gè) token 與多個(gè)區(qū)域的中心 token 的 affinity map 來表征該 token 與全局上下文的聯(lián)系,進(jìn)而以可學(xué)習(xí)方式將 affinity map 轉(zhuǎn)換為動(dòng)態(tài)卷積核,并將全局上下文信息注入到卷積核內(nèi)部的每個(gè)權(quán)重。當(dāng)動(dòng)態(tài)卷積核通過滑動(dòng)窗口作用于特征圖時(shí),每個(gè) token 都會(huì)與全局信息發(fā)生調(diào)制。簡言之,即便是在局部窗口進(jìn)行操作,ContMix 仍然具備強(qiáng)大的全局建模能力。實(shí)驗(yàn)中,我們發(fā)現(xiàn)將當(dāng)前輸入的 feature map 作為 query,并將 Top-down Guidance 作為 key 來計(jì)算動(dòng)態(tài)卷積核,相較于使用二者級(jí)聯(lián)得到的特征生成的 query/key pairs 具有更好的性能。
實(shí)驗(yàn)結(jié)果
圖像分類
OverLoCK 在大規(guī)模數(shù)據(jù)集 ImageNet-1K 上表現(xiàn)出了卓越的性能,相較于現(xiàn)有方法展現(xiàn)出更為出色的性能以及更加優(yōu)秀的 tradeoff。例如,OverLoCK 在近似同等參數(shù)量的條件下大幅超越了先前的大核卷積網(wǎng)絡(luò) UniRepLKNet。同時(shí),相較于基于 Gate 機(jī)制構(gòu)建的卷積網(wǎng)絡(luò) MogaNet 也具有非常明顯的優(yōu)勢(shì)。

表 1 ImageNet-1K 圖像分類性能比較
目標(biāo)檢測和實(shí)例分割
如表 2 所示,在 COCO 2017 數(shù)據(jù)集上,OverLoCK 同樣展示出了更優(yōu)的性能。例如,使用 Mask R-CNN (1× Schedule) 為基本框架時(shí),OverLoCK-S 在 APb 指標(biāo)上相較于 BiFormer-B 和 MogaNet-B 分別提升了 0.8% 和 1.5%。在使用 Cascade Mask R-CNN 時(shí),OverLoCK-S 分別比 PeLK-S 和 UniRepLKNet-S 提升了 1.4% 和 0.6% APb。值得注意的是,盡管基于卷積網(wǎng)絡(luò)的方法在圖像分類任務(wù)中與 Transformer 類方法表現(xiàn)相當(dāng),但在檢測任務(wù)上卻存在明顯性能差距。以 MogaNet-B 和 BiFormer-B 為例,兩者在 ImageNet-1K 上都達(dá)到 84.3% 的 Top-1 準(zhǔn)確率,但在檢測任務(wù)中前者性能明顯落后于后者。這一發(fā)現(xiàn)有力印證了我們之前的論點(diǎn) — 卷積網(wǎng)絡(luò)固定尺寸的卷積核導(dǎo)致有限感受野,當(dāng)采用大分辨率輸入時(shí)可能會(huì)性能下降。相比之下,我們提出的 OverLoCK 網(wǎng)絡(luò)即使在大分辨率場景下也能有效捕捉長距離依賴關(guān)系,從而展現(xiàn)出卓越性能。

表 2 目標(biāo)檢測和實(shí)例分割性能比較

表 3 語義分割性能比較
語義分割
如表 3 所示,OverLoCK 在 ADE20K 上也進(jìn)行了全面的評(píng)估,其性能在與一些強(qiáng)大的 Vision Backbone 的比較中脫穎而出,并且有著更優(yōu)秀的 tradeoff。例如,OverLoCK-T 以 1.1% mIoU 的優(yōu)勢(shì)超越 MogaNet-S,較 UniRepLKNet-T 提升 1.7%。更值得一提的是,即便與強(qiáng)調(diào)全局建模能力的 VMamba-T 相比,OverLoCK-T 仍保持 2.3% mIoU 的顯著優(yōu)勢(shì)。
消融研究
值得注意的是,所提出的 ContMix 是一種即插即用的模塊。因此,我們基于不同的 token mixer 構(gòu)建了類似的金字塔架構(gòu)。如表 4 所示,我們的 ContMix 相較于其他 mixer 具有明顯的優(yōu)勢(shì),這種優(yōu)勢(shì)在更高分辨率的語義分割任務(wù)上尤為明顯,這主要是因?yàn)?ContMix 具有強(qiáng)大的全局建模能力(更多實(shí)驗(yàn)請(qǐng)參見原文)。

表 4 不同 token mixer 的性能比較
可視化研究
不同 vision backbone 網(wǎng)絡(luò)的有效感受野對(duì)比:如圖 3 所示,OverLoCK 在具有最大感受野的同時(shí)還具備顯著的局部敏感度,這是其他網(wǎng)絡(luò)無法兼?zhèn)涞哪芰Α?/span>
Top-down Guidance 可視化:為了直觀呈現(xiàn) Top-down Guidance 的效果,我們采用 Grad-CAM 對(duì) OverLoCK 中 Overview-Net 與 Focus-Net 生成的特征圖進(jìn)行了對(duì)比分析。如圖 4 所示,Overview-Net 首先生成目標(biāo)物體的粗粒度定位,當(dāng)該信號(hào)作為 Top-down Guidance 注入 Focus-Net 后,目標(biāo)物體的空間定位和輪廓特征被顯著精細(xì)化。這一現(xiàn)象和人類視覺中 Top-down Attention 機(jī)制極為相似,印證了 OverLoCK 的設(shè)計(jì)合理性。

圖 3 有效感受野比較

圖 4 Top-down guidance 可視化