譯者 | 劉濤
審校 | 重樓
邊緣計算作為一種分布式系統設計架構,旨在將計算與數據存儲功能遷移至最為需求的位置——網絡的 “邊緣”。通過將此類任務部署到網絡邊緣,能夠達成實時計算,進而大幅度削減帶寬成本,并顯著縮短延遲。

然而,邊緣計算環境面臨著諸多挑戰,其中較為突出的是邊緣節點(例如各類本地設備)與中央系統(一般指云平臺或數據中心)之間的數據同步難題。
值得慶幸的是,存在一些工具可助力解決這些問題。本文將詳細闡述如何運用開源數據同步與數據庫復制工具SymmetricDS,作為上述問題解決方案之一。讀者將深入了解該工具在任意業務領域邊緣計算環境中的使用方式。
本文將引導讀者逐步剖析SymmetricDS背后的核心概念,并深入探討其如何助力優化邊緣計算的性能表現。此外,本文還將以零售業數據同步為例,展開實際用例的研究。
什么是SymmetricDS?
SymmetricDS是一款開源軟件工具,主要應用于分布式環境下,旨在實現數據庫之間的數據復制、同步以及集成功能。與傳統的數據同步工具不同的是,傳統工具往往是針對特定平臺進行定制開發的,并且大多局限于相同類型數據庫之間的數據同步操作。而 SymmetricDS 則經過專門設計,具備強大的跨平臺兼容性,能夠在運行于不同平臺的各類數據庫之間高效地實現數據同步。
在實際工作場景中,如果你所處的工作環境相對簡單,僅需使用單一類型的數據庫,并且單向的數據同步方式即可滿足業務需求,那么諸如數據庫復制或者調度ETL作業這類傳統方法,或許是更為簡便直接的選擇。然而,對于那些對數據同步靈活性要求較高、需要實現實時集成的復雜環境而言,尤其是涉及到像 POS 系統以及工業機器等邊緣設備的場景時,SymmetricDS 能夠憑借其獨特優勢,為用戶提供更具適應性和全面性的解決方案。
安裝環境
在安裝 SymmetricDS 之前,需滿足以下各項前提條件:
- Java 運行時環境(JRE):系統必須安裝 Java 8.0 或更高版本。這是確保 SymmetricDS 能夠正常運行的基礎環境要求。
- 數據庫:需運行受支持的數據庫實例,例如 MySQL、PostgreSQL、Oracle、Server 等。同時,用戶應熟悉所選用數據庫的配置方法。
- 系統要求:建議系統配備 2GB 內存,以滿足 SymmetricDS 在運行過程中的基本內存需求,確保其性能穩定。磁盤空間需求則依據數據量大小以及復制所涉及的對象數量而有所不同。
理解SymmetricDS架構
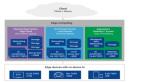
SymmetricDS 為跨多個系統(涵蓋邊緣設備)的數據同步構建了一套靈活的邊緣計算架構體系。該工具可類比為一個靈活多變的網絡,能夠被設置為中心輻射型或對等拓撲結構,以滿足不同應用場景的需求。
在中心輻射型拓撲結構中,存在一個中央節點(可以是云服務器,也可以是本地服務器),它與眾多邊緣節點相互連接。中央節點在整個架構中承擔著關鍵職責,負責管理數據同步的配置參數、協調數據同步流程的編排工作,以及對數據同步過程進行實時監控。而每個邊緣節點則主要負責在本地進行數據的采集與處理操作。
在對等拓撲結構中,架構內不存在單一的中央節點。在此模式下,每個邊緣節點兼具客戶端與服務器的雙重角色,它們能夠與其他對等的邊緣節點直接進行數據共享,形成一種分布式、去中心化的數據交互模式。
每個邊緣節點均運行自身獨立的SymmetricDS引擎,此引擎負責管理其本地數據庫的數據同步工作。數據同步過程采用推拉模型,具體而言,在邊緣節點處,數據的更改會被實時捕獲并排入隊列。隨后,依據預先設定的事件或特定條件觸發相應操作,這些數據更改將被傳輸至中央服務器或者其他節點。
在邊緣計算環境中運用SymmetricDS,具備諸多顯著優勢,其中能夠高效處理離線事務尤為突出。在網絡出現中斷的情況下,邊緣節點能夠保持自主運行狀態,繼續執行本地的相關任務。待網絡連接恢復之后,邊緣節點會自動將離線期間積累的數據更改進行同步。鑒于這一特性,SymmetricDS 在零售POS系統、遠程監控以及物聯網部署等領域展現出極高的適用性。
SymmetricDS主要由以下部分構成:
- 節點:參與同步過程的各個數據庫實例。
- 通道:為達成高效數據路由目的而對表進行的一種邏輯分組方式。
- 觸發器:捕獲數據發生的更改操作,包括插入、更新以及刪除操作。
- 路由器:負責確定數據更新后的發送目的地。
- 批次:數據在進行同步之前,會被歸并為一個個批次。
- 沖突解決機制:用于處理因并發更新所引發的數據沖突問題。
安裝與設置
步驟1:下載并安裝 SymmetricDS
若要開啟 SymmetricDS 的使用之旅,有兩種獲取途徑:一是從 SourceForge.net下載社區版(開源),將下載的文件解壓即可;二是若有更高級需求,可從Jumpmind Inc.獲取專業版,但專業版需獲取相應授權。在安裝之前,請務必確保在你的計算機系統中正確設置了 JAVA_HOME環境變量,這是保障SymmetricDS正常運行的基礎前提。
步驟2:創建數據庫
安裝一個SymmetricDS支持的數據庫,常見的如MySQL、PostgreSQL、Oracle、SQL Server等。安裝完成后,需在該數據庫中創建相應的數據庫模式以及所需的表結構,為后續的數據存儲與操作奠定基礎。
步驟3:配置節點
在SymmetricDS環境中,每個參與數據同步的數據庫均被視為一個節點。節點的配置需在symmetric ds.properties文件中進行定義。以下為一個具體的配置示例:
engine.name=my-node
db.driver=com.mysql.cj.jdbc.Driver
db.url=jdbc:mysql://localhost:3306/mydb
db.user=root
db.password=root
sync.url=http://localhost:31415/sync/my-node
registration.url=http://localhost:31415/sync/hub以下詳細說明上述 SQL 語句各自的作用:
- engine.name=my node:此語句的功能是為 SymmetricDS 實例賦予一個特定名稱。
- db.driver=com.mysql.cj.jdbc.Driver:該語句明確指定了用于連接 MySQL數據庫的JDBC驅動程序。
- db.url=jdbc:mysql://localhost:3306/mydb:此語句用于指定數據庫的訪問路徑,即 URL。
- db.user=root 與 db.password=root:這兩條語句分別定義了訪問數據庫所需的憑證。
- sync.url:該語句用于定義數據同步的目標地址,也就是此節點發送數據的目的地。
- registration.url:此語句指定了用于管理注冊的中心節點的 URL。
步驟4:啟動SymmetricDS
若要啟動SymmetricDS,需在解壓后的文件夾中執行以下命令:
./sym_service start # On Linux/macOS
sym_service.bat start # On Windows執行此命令后,將啟動SymmetricDS引擎,該引擎開始監控配置的數據庫的更改。
定義同步規則
SymmetricDS的同步規則是其核心組件之一,這些規則明確了哪些數據變更需要被捕獲,并規定了數據在各個邊緣節點之間的路由方式。這些規則具有高度的可配置性,旨在精確界定數據在不同數據庫之間傳輸的具體方式以及時機。
在進行同步規則設置時,可參考以下步驟:
步驟1:定義節點組
在SymmetricDS里,配置規則是作用于節點組的。這種方式在分布式環境中,能夠有效控制數據在不同節點間的流動方式。
INSERT INTO SYM_NODE_GROUP (node_group_id, description)
VALUES ('Store', 'Store Node');
INSERT INTO SYM_NODE_GROUP (node_group_id, description)
VALUES ('Corp', 'Corp Node');在此代碼示例中:
- Store組用于表征邊緣節點(例如,實際應用中的門店數據庫)。
- Corp組用于代表中央核心節點。
步驟2:定義組鏈接
組鏈接的作用在于確定由哪個節點組發起數據交換同步操作。通過設置組鏈接,能夠清晰地界定兩個或多個節點組之間的關聯關系,進而明確數據在這些節點組之間的流動方式以及時機。
INSERT INTO SYM_NODE_GROUP_LINK (source_node_group_id, target_node_group_id, data_event_action)
VALUES ('Store', 'Corp', 'P'); // 'P' represents 'Push'
INSERT INTO SYM_NODE_GROUP_LINK (source_node_group_id, target_node_group_id, data_event_action)
VALUES ('Corp', 'Store', 'W'); // 'W' represents 'Wait for Pull'在此處:
- Stores組向Corp節點執行推送(‘P’)數據(例如將門店的銷售數據發送至總部)。
- Stores組處于等待狀態,從Corp節點拉取(‘W’)數據(例如接收總部下發的庫存更新信息)。
步驟3:為數據流定義路由器和觸發路由器
路由器基于特定規則(例如操作類型,如插入、更新、刪除等),對需要同步的數據進行篩選。通過排除不必要的數據傳輸,路由器能夠確保只有必要的數據被準確路由至正確的目的地。
INSERT INTO SYM_ROUTER (router_id, source_node_group_id, target_node_group_id, router_type,
sync_on_update, sync_on_insert, sync_on_delete)
VALUES('corp to store', 'corp', 'store', 'default ', 1, 1, 1);
INSERT INTO SYM_TRIGGER_ROUTER (trigger_id, router_id, initial_load_order)
VALUES('user', 'corp to store', '1');上述代碼實現了以下功能:
- 定義了一個名為“corp to store”的路由器,其作用是將數據從Corp同步至Store。
- 選用 “default”路由器類型。
- “sync_on_update = 1” 表明Corp數據庫中的更新操作所產生的數據變化,都將被同步到Store。
- “sync_on_insert = 1” 意味著Corp中的插入操作數據會同步至 Store。
- “sync_on_delete = 1” 說明Corp里的刪除操作數據也會同步到Store。現在,我們將此路由器鏈接到一個觸發器:
INSERTINTO SYM_TRIGGER_ROUTER (trigger_id, router_id, initial_load_order)
VALUES('user','corp to store','1');
這樣一來,便能夠確保當觸發器監測到用戶表發生變更時,相關數據會依據 “corp to store” 規則進行路由 。
步驟4:定義通道
通道用于對表中的數據進行邏輯分組。通過這種方式,它能夠有效地組織和區分不同的數據流,進而讓數據同步過程變得更加高效,并且使整個系統具備良好的可擴展性。
INSERT INTO SYM_CHANNEL (channel_id, max_batch_size, max_batch_to_send, max_data_to_route,
enabled, batch_algorithm, description)
VALUES ('users', '10000', '100', '500000', '1', 'default', 'user data');此段代碼實現了以下功能:
- 定義了一個名為“users”的通道。
- 設定將數據按照每次同步10,000行的規模進行分批處理。
- 通過限制每次同步的批次數量為100個,且每條路由的數據記錄數為500,000條,以此來保障同步效率。
步驟 5:定義表觸發器
定義表觸發器在整個數據同步流程中具有重要作用,其主要功能是對數據庫表中的數據更改進行檢測與管理。表觸發器如同事件監聽器一般,時刻追蹤源數據庫內發生的變化。若系統中未設置表觸發器,那么系統將無法確定何時啟動同步更改操作,也無法明確具體需要同步哪些數據。
INSERT INTO SYM_TRIGGER (trigger_id, source_table_name, channel_id)
VALUES ('user', 'user', 'user');此段代碼負責跟蹤用戶表中的變動情況。一旦有更改發生,這些更改數據將通過 “users” 通道進行路由傳輸。
步驟 6:測試數據同步
若要對數據同步功能進行測試,可向源數據庫中插入若干測試數據:
INSERT INTO user (id, name, email)
VALUES (1, 'Alice', 'alice@example.com');隨后,運行 SymmetricDS 同步操作,查看該記錄是否會在目標數據庫中出現。
步驟 7:監控與故障排查
可查看 logs/wrapper.log 文件中的日志信息。若某個批次的同步操作失敗,可通過執行以下 SQL 查詢來檢查錯誤情況:
SELECT * FROM SYM_OUTGOING_BATCH WHERE ERROR_FLAG = 1;執行上述查詢后,系統將獲取出現錯誤的批次ID(BATCH_ID)。接下來,運行以下SQL語句,即可獲取失敗批次的具體數據:
SELECT * FROM SYM_DATA WHERE data_id in (select failed_data_id from sym_outgoing_batch WHERE batch_id='XXXXX' and node_id='YYYY');SymmetricDS 在邊緣計算中的優勢
在邊緣計算場景中,數據在更接近源頭的位置(例如銷售點系統、物聯網設備、傳感器等)進行處理。在此背景下,SymmetricDS 展現出諸多優勢,使其成為一款強大的數據同步工具。
- 低延遲:SymmetricDS支持在本地進行數據處理,僅需定期與中央服務器進行同步。這種方式有效減少了在云環境中進行實時數據處理時所產生的延遲,確保數據能夠快速響應業務需求。
- 帶寬優化:該工具在數據同步過程中,僅傳輸數據的增量更改部分,而非整個數據集。這一特性極大地降低了持續數據傳輸的需求,進而有效節省了網絡帶寬資源,提升了系統的整體運行效率。
- 容錯能力:在邊緣計算環境中,網絡連接往往不穩定,甚至可能出現間歇性中斷的情況。SymmetricDS 具備強大的容錯能力,即便在連接斷開的狀態下,依然能夠實現數據復制。這一關鍵特性使其在網絡連接不可靠的場景中表現出色,同時也為離線數據處理提供了有力支持,確保業務流程不受網絡問題的過多干擾。
- 可擴展性:SymmetricDS具備良好的擴展性,能夠輕松擴展至大量的邊緣節點,并支持復雜的系統架構。即使在系統不斷添加更多功能的情況下,依然能夠確保性能的穩步提升,滿足業務規模增長和復雜度增加的需求。
應用案例:SymmetricDS 如何解決零售商的實時數據難題
假定有一家零售連鎖企業,在某一國家、州或特定地區擁有眾多門店。每家門店均配備獨立的本地銷售點(POS)系統、庫存系統以及用于客戶交互的數據庫。
總部在制定關鍵決策時,高度依賴從所有門店收集的實時信息。這些決策涵蓋庫存管理、銷售報告生成、客戶活動監控以及促銷活動策劃等多個方面。因此,實現低延遲地同步來自眾多門店的數據至關重要,這是確保庫存數據準確、交易記錄精準以及門店運營協調順暢的關鍵所在。
在零售業中,各門店之間庫存不一致是較為常見的問題之一。例如,當某家門店售出一件商品時,其庫存系統必須即刻更新,以避免其他門店出現超售或缺貨的情況。然而,傳統的數據同步方式往往容易引發延遲或出現錯誤,從而在部分門店造成缺貨或者導致庫存積壓的情況。
SymmetricDS為所有門店與中央系統之間實現實時數據同步提供了更為可靠的解決方案。無論何時,只要有任何一家門店完成商品銷售操作,SymmetricDS便會迅速更新本地門店系統以及中央數據庫中的庫存數據。通過這種方式,能夠確保其他門店始終獲取到最新的庫存信息,有效避免網絡環境下庫存不一致問題的發生。
結論
SymmetricDS內置一套強大的功能集合,能夠對邊緣計算環境進行優化。該工具聚焦于增量數據同步、數據壓縮以及異步復制等關鍵技術,在延遲控制、帶寬利用以及容錯能力等方面均展現出卓越的性能提升。
在實際應用場景中,邊緣計算環境中引入SymmetricDS能夠顯著提高分布式應用的運行效率。它不僅賦予系統更高的可擴展性,還能助力實現更快速的決策制定過程,同時有效降低對中央服務器的依賴程度。
借助本文所探討的方法,邊緣設備在運行過程中具備高度自主性,能夠成功地與主服務器完成同步操作。即便處于業務高峰等復雜條件下,依然可以維持高性能的數據處理與傳輸輸出,為各類復雜業務場景提供堅實可靠的技術支持。
譯者介紹
劉濤,51CTO社區編輯,某大型央企系統上線檢測管控負責人。
原文標題:Data Synchronization for Edge Computing with SymmetricDS,作者:Divya Valsala Saratchandran