













DeepSeek-R1、o1都在及格線掙扎!字節開源全新知識推理測評集,覆蓋285個學科
大模型刷榜 MMLU、屠榜 GPQA 的玩法一夜變天???
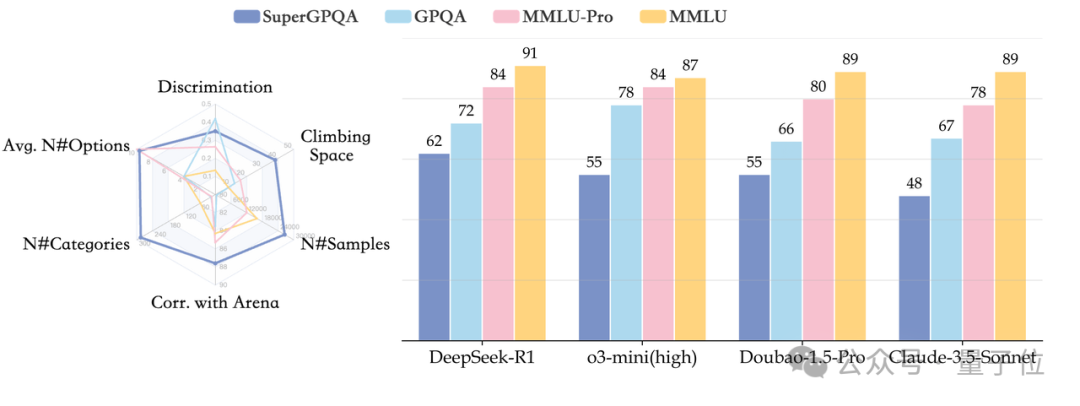
要知道,過去幾年,各種通用評測逐漸同質化,越來越難以評估模型真實能力。GPQA、MMLU-pro、MMLU等流行基準,各家模型出街時人手一份,但局限性也開始暴露,比如覆蓋范圍狹窄(通常不足 50 個學科),不含長尾知識;缺乏足夠挑戰性和區分度,比如 GPT-4o 在 MMLU-Pro 上準確率飆到 92.3%。
不過別慌,大模型通用知識推理評測“強化版”來了,堪稱大模型評測里的“黃岡密卷”!
近日,字節跳動豆包大模型團隊聯合 M-A-P 開源社區,推出了全新評測基準 SuperGPQA。
我們翻看論文,細品一番,足足 256 頁。據了解,該評測搭建工作耗時半年,近百位學界學者及名校碩博、業界工程師參與標注。
研究團隊構建了迄今為止最全面,覆蓋 285 個研究生級學科、包含 26529 道專業題目的評估體系。
實驗證明,即便最強的 DeepSeek-R1 在 SuperGPQA 上準確率也才 61.82%,在及格線上掙扎,顯著低于其在傳統評估指標上的表現。
SuperGPQA 精準直擊大模型評測的三大痛點:
- 學科覆蓋不全:傳統基準僅覆蓋 5% 長尾學科,圖書館學、植物學、歷史地理學等眾多學科長期缺席
- 題目質量存疑:公開題庫存在數據污染風險,簡單改編無法反映真實學術水平
- 評測維度單一:多數測試停留在知識記憶層面,缺乏高階推理能力評估
除此之外,SuperGPQA 也公開了嚴格的數據構建過程。整個體系依靠大規模人機協作系統,結合專家標注、眾包注釋和大模型協同驗證三重流程,確保入選題目具有足夠高的質量和區分度。
目前, SuperGPQA 已在 HuggingFace 和 GitHub 開源,直接沖上了 Trending 榜單。

首次 「全學科覆蓋」,填補行業空白
研究人員透露,現在大語言模型評估體系主要有兩大“困境”:學科覆蓋嚴重失衡、評測基準挑戰性失效。
以 MMLU 和 GPQA 為代表的傳統基準,盡管在數學、物理等主流學科中建立了標準化測試框架,但其覆蓋的學科數量通常不足 50 個,無法涵蓋人類積累的多樣化和長尾知識。
而且,GPT-4o 和 DeepSeek-R1 在傳統基準上準確率都破 90% 了,導致評測體系失去區分度,無法有效衡量模型在真實復雜場景中的推理上限。
根源就在于傳統基準構建范式太單一,數據來源、質量篩選都相對粗糙。傳統基準僅依賴教科書例題或在線題庫,例如 GPQA 中 42% 的問題來自維基百科,導致題目缺乏專業深度,且易被模型通過記憶機制“破解”。
數據顯示,GPT-4o 對在線練習網站答案的重復率高達 67.3%,暗示其性能提升可能源于題目數據泄露而非真實推理能力。
此外,眾包標注的專業水平參差和主觀性問題難度評估進一步加劇了基準的不可靠性——早期嘗試中,僅 37% 的眾包標注問題通過專家審核,導致超過 60% 的標注資源浪費。
為解決上述困境,豆包大模型團隊聯合 M-A-P 開源社區推出 SuperGPQA,旨在深度挖掘 LLMs 潛力,其特點如下:
- 全面且具區分性:STEM(科學、工程、醫學)領域問題占比 77.2%,確保在復雜推理任務中的高效評估。盡管非 STEM 學科(如哲學、文學、歷史)問題較少,但仍能有效區分不同 LLMs 的性能。
- 難度分布多樣:各學科問題難度均衡分布;在工程和科學領域,難題比例較高。42.33% 的問題需要數學計算或嚴謹推理,確保模型在高難度任務中的表現。
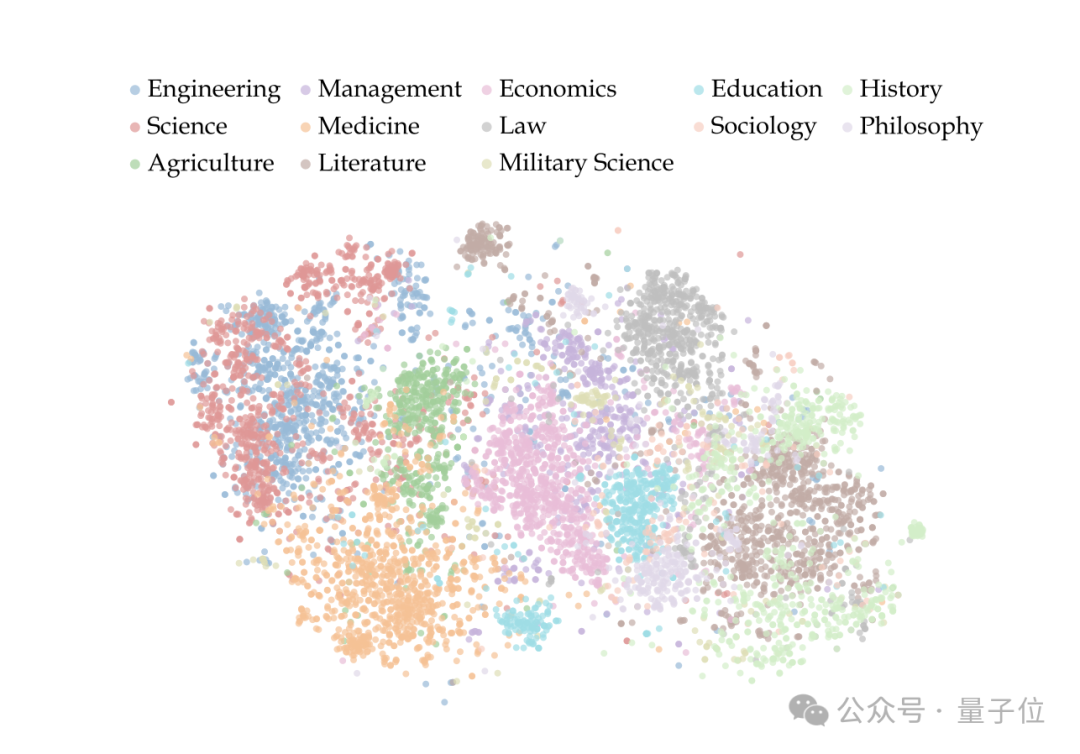
- 語義結構豐富:t-SNE 可視化顯示跨學科聚類模式,工程和科學類問題語義相似,人文學科知識中心獨特,不同領域語言特色鮮明。
- 題目設計一致:平均問題長度 58.42 字,選項長度統一,迷惑性和挑戰性拉滿,評測公平又可靠。
作為基準測試,SuperGPQA 非常全面,覆蓋 13 個門類、72 個一級學科和 285 個二級學科,共 26,529 個問題,把現有 GPQA(448 題)和 MMLU-Pro(12,032 題)遠遠甩在身后。同時,每題平均 9.67 個選項,也比傳統 4 選項格式挑戰性高得多。
人機協作三步質檢,杜絕“刷題黨”
SuperGPQA 核心架構分三步:來源篩選、轉錄、質量檢測。
團隊設計時,深知眾包注釋方法在高復雜度題目上的不足,因此引入了專家注釋員,確保題目來源靠譜、難度合適。再結合最先進的 LLMs 輔助質量檢測,效率拉滿,也通過多模型協作降低了題目數據泄漏的風險。
此外,團隊還強調嚴格流程管理和持續質量反饋,保證每階段輸出都達標。靠著系統化、專業化流程,SuperGPQA 題庫質量飆升,后期修正成本和時間大幅減少。

來源篩選
為保證題目高質量,團隊直接拋棄眾包注釋員收集資源的老路,轉而讓專家注釋員從可信來源(教科書、權威練習網站)篩選、收集原始問題。
這招一出,避免了早期大量無效問題的產生,并通過要求提供來源截圖,大幅提升了質量檢測的效率和準確性。
轉錄
轉錄階段,專家注釋員對收集的原始問題進行語言規范化、格式轉換,確保所有問題都有統一學術語言和標準多項選擇題格式。
團隊發現,即使是最先進的語言模型(LLMs)在生成干擾項時也存在漏洞,因此需要專家統一重寫,以提高干擾項的準確性和有效性,確保題目的挑戰性和區分度。
質量檢測
質量檢測階段采用多層次的檢測機制,包括 :
1)基于規則的初步過濾:識別并過濾格式明顯不合規范的題目。
2)基于 LLM 的質量檢測:多個先進 LLMs(如 GPT-4、Gemini-flash 等)齊上陣,有效性、負面和極端詢問檢測、多模態排除、領域相關性評估、區分度標記都不在話下。
3)專家復審:專家注釋員對可疑題目進行二次審核,確保題庫的高可靠性和高區分度。
推理模型霸榜,但表現仍低于人類水平
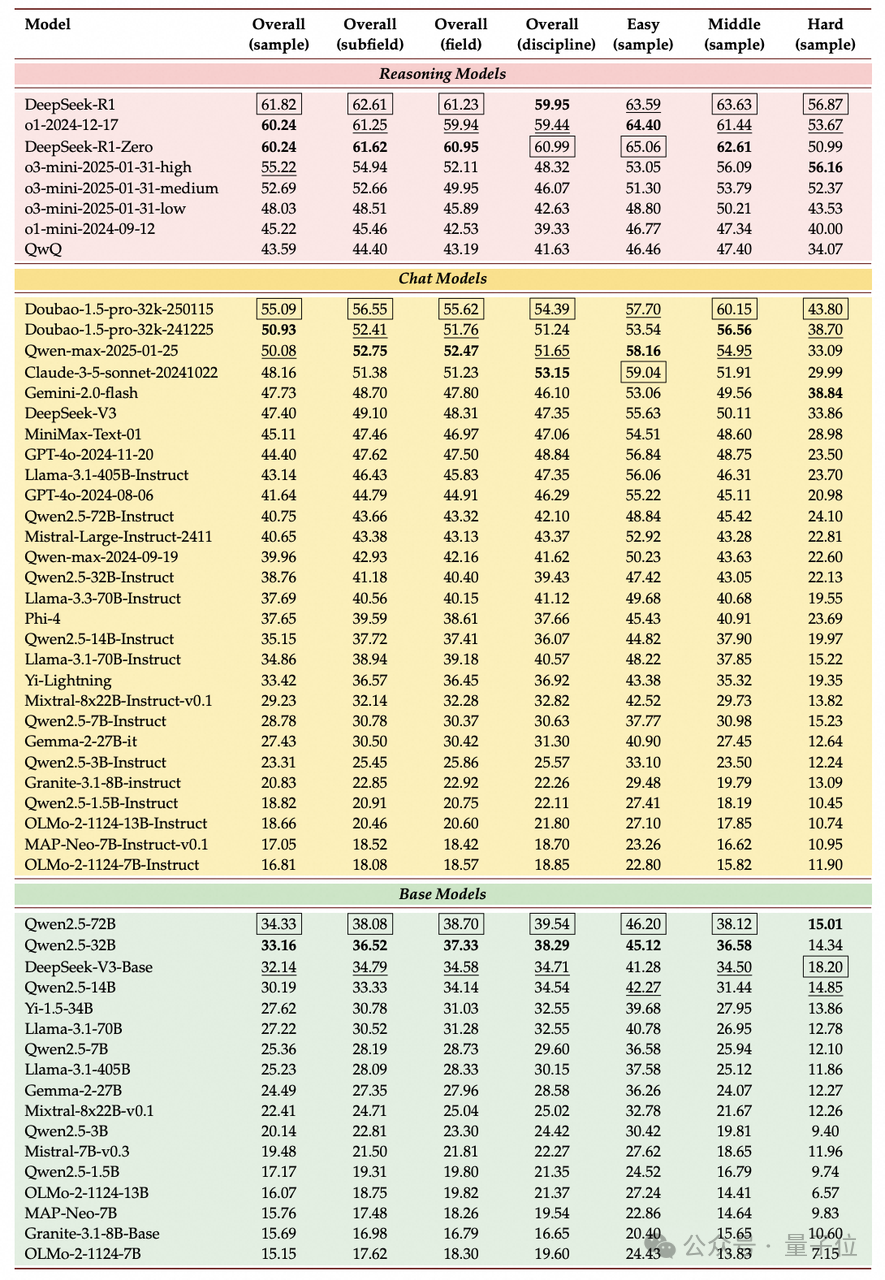
△LLMs 在不同劃分層級上的表現
 △LLMs 在不同學科上的表現
△LLMs 在不同學科上的表現
SuperGPQA 還做了全面的實驗,來測試業界主流 LLM 的能力表現。評估涵蓋 6 個推理模型、28 個聊天模型、17 個基礎模型,閉源、開源、完全開源模型全覆蓋。
團隊發現,在涵蓋 51 個模型的橫向評測中,DeepSeek-R1 以 61.82% 準確率登頂,但其表現仍顯著低于人類研究生水平(平均 85%+)。
我們從論文中還扒到三大值得關注的結論:
1、推理能力決定上限
- 推理模型(DeepSeek-R1、O1-2024-12-17)包攬前 3,領先聊天模型超 10 個百分點
- DeepSeek-V3 和 Qwen2.5-72B-Instruct 的得分(47.40 和 40.75)遠超其基礎版本(32.14 和 34.33),說明指令微調顯著提升性能
2、國內模型突圍
- 豆包大模型(Doubao-1.5-pro)以 55.09% 準確率位列聊天模型第一,超越 GPT-4o-2024-11-20(44.40%)
- Qwen 系列展現強泛化能力:Qwen2.5-72B 在基礎模型中排名第 4,超越 Llama-3.1-405B
3、學科表現失衡 * STEM 領域優勢顯著:在「理論流體力學」「運籌學和控制論」等子領域,Top 模型準確率超 75%
- 人文社科仍是短板:在「舞蹈研究」「設計藝術」等領域,最優模型準確率不足 50%
One More Thing
一直以來,評估數據集對提升大模型的效果上限至關重要,甚至有可能是“最關鍵的部分”。
但評測數據集的搭建耗費大量人力,很大程度依靠開源貢獻。早在去年,字節就在開源評測數據集上有所行動,覆蓋超 11 類真實場景、16 種編程語言的代碼大模型評估基準 Fullstack Bench 受到開發者好評。
此番字節再次亮出耗時半年打造的SuperGPQA,進一步打破外部關于“字節對基礎工作投入不足”的印象。另一方面,也側面暴露字節內部對模型能力的極高目標。
結合近期我們關注到的 DeepMind 大牛吳永輝加入,全員會定下“追求智能上限”的目標。
2025 年,豆包模型究竟能沖到什么水平?不妨讓子彈再飛一會。
論文鏈接: https://arxiv.org/pdf/2502.14739





























