RAG(一)RAG開山之作:知識密集型NLP任務的“新范式”

在AI應用爆發的時代,RAG(Retrieval-Augmented Generation,檢索增強生成)技術正逐漸成為AI 2.0時代的“殺手級”應用。它通過將信息檢索與文本生成相結合,突破了傳統生成模型在知識覆蓋和回答準確性上的瓶頸。不僅提升了模型的性能和可靠性,還降低了成本,增強了可解釋性。
今天來看一篇RAG領域的開山之作,2020年Meta AI發表在NIPS上的一篇工作。

先來看下研究動機:大語言模型(LLM)雖然功能強大,但存在一些局限性,例如知識更新不及時、容易產生“幻覺”(即生成與事實不符的內容),以及在特定領域或知識密集型任務中表現不佳。RAG通過引入外部知識庫,檢索相關信息來增強模型的輸出,從而解決這些問題。
1、方法介紹

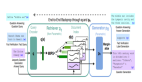
RAG模型結合了一個檢索器(retriever)和一個生成器(generator),這兩個組件協同工作來完成知識密集型的語言生成任務。
- 檢索器 (Retriever)
 :檢索器負責根據輸入序列x檢索文本文檔z。基于DPR(Dense Passage Retriever)構建,使用預訓練的查詢編碼器和文檔編碼器來計算查詢與文檔之間的相似度,并選擇最相關的前K個文檔。
:檢索器負責根據輸入序列x檢索文本文檔z。基于DPR(Dense Passage Retriever)構建,使用預訓練的查詢編碼器和文檔編碼器來計算查詢與文檔之間的相似度,并選擇最相關的前K個文檔。 - 生成器 (Generator)
 :生成器是一個預訓練的序列模型(如BART-large),用于根據輸入序列x和檢索到的文檔z來生成目標序列y。它通過將原始輸入與檢索到的內容拼接起來作為新的上下文來進行解碼。
:生成器是一個預訓練的序列模型(如BART-large),用于根據輸入序列x和檢索到的文檔z來生成目標序列y。它通過將原始輸入與檢索到的內容拼接起來作為新的上下文來進行解碼。 - 最大內積搜索 (Maximum Inner Product Search, MIPS):通過計算查詢向量q(x)和所有文檔向量d(z)之間的內積,找到與查詢最相關的前K個文檔z。
對于整個方法概括來說,用戶提供的文本查詢x 首先被送入查詢編碼器,得到查詢的向量表示q(x)。利用MIPS算法,在文檔索引中快速查找與查詢q(x)最相似的前K個文檔 。這些文檔作為潛在的知識來源,幫助生成更準確的回答。最后,根據輸入序列x 和檢索到的文檔z 來生成目標y。
。這些文檔作為潛在的知識來源,幫助生成更準確的回答。最后,根據輸入序列x 和檢索到的文檔z 來生成目標y。
RAG模型使用概率框架來處理檢索到的文檔作為潛在變量z,這篇文章提出兩種方式來邊緣化這些潛在文檔:
- RAG-Sequence Model:RAG-Sequence 模型使用單一的檢索文檔來生成完整的序列。具體來說,檢索器檢索出 top K 文檔,生成器為每個文檔生成輸出序列的概率
p(y∣x)p(y∣x)p(y ∣ x),然后對這些概率進行邊緣化處理:

- RAG-Token Model:與此不同的是,RAG-Token允許每個輸出token依賴于不同的文檔。這意味著對于每一個token,模型都會重新評估一次所有可能的文檔,并據此調整生成的概率分布。
邊緣化的數學解釋
設輸入序列為 x,目標序列為 y,檢索到的文檔集合為 Z。對于給定的輸入x 和目標y,我們希望找到一個概率p(y∣x),即在給定輸入的情況下生成目標序列的概率。然而,因為我們引入了額外的文檔信息z,所以我們實際上需要考慮的是條件概率p(y∣x,z)。
但是,z 是未知的,所以不能直接使用這個條件概率。為此,我們可以利用貝葉斯公式來將z 積分出去,從而得到不依賴于特定文檔的p(y∣x):

這里p(z∣x)表示給定查詢x 的情況下文檔z 被檢索出來的概率,這由檢索器給出;而p(y∣x,z)則是生成器基于輸入x 和文檔z 生成目標y 的概率。通過遍歷所有可能的文檔 z 并加權求和它們各自的貢獻,這樣就實現了對潛在文檔 z 的邊緣化。
檢索器:DPR
檢索組件 基于 DPR ,DPR 采用雙編碼器架構:
基于 DPR ,DPR 采用雙編碼器架構:

其中,d(z) 是文檔的密集表示,q(x) 是查詢表示。使用預訓練的DPR來初始化檢索器,通過最大內積搜索,計算具有最高先驗概率 的k個文檔列表,并構建文檔索引,將文檔索引稱為非參數化記憶。
的k個文檔列表,并構建文檔索引,將文檔索引稱為非參數化記憶。
生成器:BART
生成器組件 可以使用任何編碼器-解碼器模型來實現,本文使用 BART-large,在生成時將輸入x 與檢索到的內容z 簡單拼接。 BART 生成器的參數θ稱為參數化記憶。
可以使用任何編碼器-解碼器模型來實現,本文使用 BART-large,在生成時將輸入x 與檢索到的內容z 簡單拼接。 BART 生成器的參數θ稱為參數化記憶。
訓練
模型采用了負對數似然損失函數訓練,即最小化給定輸入x 下真實輸出 y 的負對數概率。在訓練期間,不直接監督應該檢索哪些文檔,而是讓模型學習如何更好地利用檢索到的信息來提高生成質量。此外,為了避免頻繁更新龐大的文檔索引帶來的高昂成本,只微調查詢編碼器和生成器。
解碼
測試時,RAG-Sequence 和 RAG-Token 需要不同的方法來近似 。 RAG-Token 模型可以看作是一個標準的自回歸 seq2seq 生成器,其轉移概率為:
。 RAG-Token 模型可以看作是一個標準的自回歸 seq2seq 生成器,其轉移概率為:

解碼可以通過插入修改后的轉移概率 進入常規的束搜索算法完成。
進入常規的束搜索算法完成。
對于RAG-Sequence,整個序列的似然
2、實驗結果
開放域問答
RAG-Token 和 RAG-Sequence 在所有四個任務上均達到了新的最先進水平(僅在TriviaQA的一個特定測試集上除外)。

抽象問答
盡管沒有使用黃金段落,RAG的表現依然接近需要這些段落才能達到最優表現的模型。
RAG 模型比 BART 更少產生幻覺,并且更頻繁地生成符合事實的文本。

Jeopardy 問題生成
表2 顯示了Q-BLEU-1度量的結果。表4展示了人工評估結果。表 3 顯示了每個模型的典型生成。
RAG-Token 模型特別擅長于從多個檢索到的文檔中提取信息并組合成復雜的Jeopardy問題。例如,在生成包含兩個不同書籍標題的問題時,它能夠分別從不同的文檔中獲取每個書名的信息。
圖2 提供了一個具體的例子,展示了當生成“太陽”一詞時,文檔2(提到《太陽照常升起》)的概率較高;而在生成“A Farewell to Arms”時,文檔1(提到海明威的這部作品)的概率較高。
隨著每個書名的第一個token被生成后,文檔概率分布趨于平坦化,這表明生成器能夠在不依賴特定文檔的情況下完成整個題目。
非參數化記憶的作用:通過檢索相關文檔,RAG模型可以引導生成過程,挖掘出存儲在參數化記憶中的具體知識。例如,即使只提供了部分解碼"The Sun",BART基線也能完成生成"The Sun Also Rises",說明這些信息已經存儲在BART的參數中,但RAG能更好地利用外部知識源來增強生成質量。


事實驗證
表2 顯示了FEVER任務上的分類準確性。對于三類分類任務(支持/反駁/信息不足),RAG得分距離最先進模型僅4.3%以內;對于二類分類任務(支持/反駁),差距更是縮小到2.7%以內。
RAG能夠在不依賴檢索監督信號的情況下,通過僅提供聲明并自己檢索證據,實現與復雜管道系統相當的性能。
生成多樣性
RAG-Sequence 的生成更加多樣化,而RAG-Token次之,兩者都顯著優于BART。

檢索機制的有效性
結果表明,學習檢索(即在訓練過程中更新檢索器)對 RAG 模型的性能至關重要。密集檢索器在大多數任務中表現優于傳統的 BM25 檢索器,尤其是在需要語義匹配和復雜查詢處理的任務中。對于某些特定任務(如 FEVER),基于詞重疊的 BM25 方法可能更為有效。

檢索更多文檔的效果

3、總結
RAG的意義簡單總結以下幾點:
- 提升模型性能:RAG顯著提高了生成模型在問答、文本生成等任務中的準確性和可靠性。
- 降低訓練成本:無需大規模預訓練即可實現知識更新和性能提升。
- 增強可解釋性:通過檢索過程為生成結果提供明確依據,增強了用戶對AI系統的信任。
- 推動行業創新:RAG技術在醫療、金融、法律等多個領域的應用,推動了AI在特定領域的深度落地。
總的來說,RAG技術在AI應用爆發的時代,憑借其對生成模型的增強和優化,正在成為推動AI發展的關鍵力量。它不僅提升了模型的性能和可靠性,還降低了成本,增強了可解釋性。隨著技術的不斷演進,RAG將在更多領域實現深度應用,為AI的未來發展提供強大動力。