語音合成也遵循Scaling Law,太乙真人“原聲放送”講解論文 | 港科大等開源
活久見,太乙真人給講論文了噻!

咳咳,諸位道友且聽我一番嘮叨。
老道我閉關(guān)數(shù)日,所得一篇妙訣,便是此Llasa之法。此術(shù)上個月一出,海外仙長們無不瞠目結(jié)舌,直呼“HOLY SHIT”!

熱度最高時,曾在huggingface上的“丹藥熱度榜”上排第六。

咳咳,書回正傳。
如上引發(fā)圍觀的成果由香港科技大學(xué)等聯(lián)合推出,它驗(yàn)證語音合成模型,也可以遵循Scaling Law,即擴(kuò)展計算資源、語音合成效果可以更好。
它核心提出了一個語音合成的簡單框架Llasa,該框架采用單層VQ編解碼器和單個Transformer架構(gòu),和標(biāo)準(zhǔn)LLM保持一致。
研究團(tuán)隊(duì)提供了TTS模型(1B、3B、8B)、編解碼器的checkpoint以及訓(xùn)練代碼。
一氣呵成TTS系統(tǒng)
近年來,基于Transformer的大型語言模型(LLM)在自然語言處理領(lǐng)域取得了顯著進(jìn)展,尤其是通過擴(kuò)展模型規(guī)模和訓(xùn)練數(shù)據(jù)來提升性能。
然而,當(dāng)前的TTS系統(tǒng)通常需要多階段模型(例如在 LLM 后使用擴(kuò)散模型),這使得在訓(xùn)練或推理階段擴(kuò)展計算資源變得復(fù)雜。
本研究提出了一種單階段TTS框架Llasa,旨在簡化這一過程,同時探索訓(xùn)練時間和推理時間擴(kuò)展對語音合成的影響。
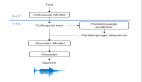
它基于Llama模型,采用單Transformer架構(gòu),結(jié)合了一個設(shè)計良好的語音分詞器(tokenizer),能夠?qū)⒄Z音波形編碼為離散的語音標(biāo)記,并解碼回高質(zhì)量音頻。
該框架的核心在于將語音和文本標(biāo)記聯(lián)合建模,通過預(yù)測下一個語音標(biāo)記來生成語音。
關(guān)鍵組件:
- 語音分詞器(Xcodec2):將語音波形編碼為離散標(biāo)記,同時保留語音的語義和聲學(xué)信息。
- Transformer模型:基于 Llama 初始化,學(xué)習(xí)文本和語音標(biāo)記的聯(lián)合分布。
驗(yàn)證Scaling Law
訓(xùn)練時間擴(kuò)展(Scaling Train-time Compute)
研究者通過擴(kuò)展模型規(guī)模和訓(xùn)練數(shù)據(jù)規(guī)模來研究其對語音合成性能的影響。
實(shí)驗(yàn)表明,增加模型參數(shù)(從1B到8B)和訓(xùn)練數(shù)據(jù)量(從80k小時到250k小時)可以顯著提高語音的自然度、韻律準(zhǔn)確性和情感表達(dá)能力。
關(guān)鍵發(fā)現(xiàn):
- 文本理解能力:更大的模型和更多的數(shù)據(jù)能夠更好地理解復(fù)雜文本(如詩歌、情感文本)。數(shù)據(jù)越多,連生僻字,復(fù)合詞也能辨其真意。
- 零樣本學(xué)習(xí)能力:擴(kuò)展訓(xùn)練資源能夠顯著提高模型對未見說話人的語音克隆能力。
推理時間擴(kuò)展(Scaling Inference-time Compute)
研究還探索了在推理階段通過增加計算資源(例如使用語音理解模型作為驗(yàn)證器)來優(yōu)化生成語音的質(zhì)量。實(shí)驗(yàn)表明,推理時間擴(kuò)展可以顯著提高語音的情感表達(dá)、音色一致性和內(nèi)容準(zhǔn)確性。
關(guān)鍵方法:
- 過程獎勵模型(PRM):通過逐步優(yōu)化生成過程來提高語音質(zhì)量。
- 輸出獎勵模型(ORM):通過評估最終生成的語音來選擇最優(yōu)輸出。
實(shí)驗(yàn)結(jié)果
- 語音分詞器性能:提出的Xcodec2在多個指標(biāo)上優(yōu)于現(xiàn)有分詞器,特別是在低比特率下的語音重建質(zhì)量。
- TTS 性能:Llasa在LibriSpeech、Seed-TTS-Eval和ESD數(shù)據(jù)集上達(dá)到了最先進(jìn)的性能,尤其是在情感相似性、音色相似性和零樣本學(xué)習(xí)能力方面。
- 推理時間擴(kuò)展效果:通過PRM和ORM方法,推理時間擴(kuò)展顯著提高了語音合成的質(zhì)量,尤其是在復(fù)雜任務(wù)中。
“開源渡世”
咳咳,太乙真人重新上線:
老道已將丹方(訓(xùn)練代碼)、丹藥(模型權(quán)重)公之于世,廣邀三界修士共參:
秘方參照:Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis

論文鏈接:https://arxiv.org/abs/2502.04128
Llasa 訓(xùn)練代碼 https://github.com/zhenye234/LLaSA_training
Codec 訓(xùn)練 https://github.com/zhenye234/X-Codec-2.0
Llasa test-time-scaling代碼 https://github.com/zhenye234/LLaSA_inference
模型權(quán)重: https://huggingface.co/collections/HKUSTAudio/llasa-679b87dbd06ac556cc0e0f44