













出人意料!DeepSeek-R1用的GRPO其實沒必要?規模化強化學習訓練用PPO就夠了
DeepSeek-R1 非常熱門,而在其公布的訓練配方中,GRPO(Group Relative Policy Optimization)非常關鍵,是 DeepSeek-R1 核心的強化學習算法。
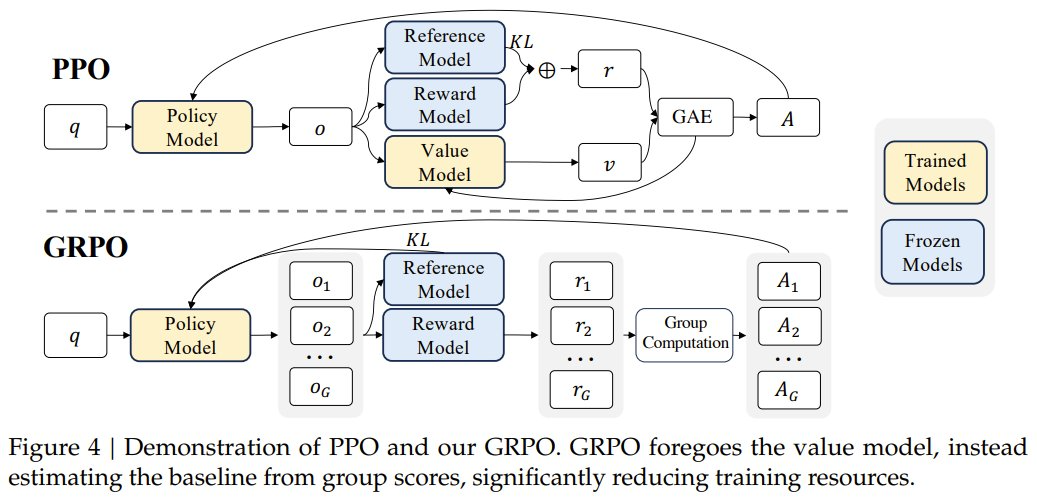
PPO 與 GRPO 的對比,來自論文《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》
相較于 PPO,GRPO 去掉了價值模型,而是通過分組分數來估計基線,從而可極大減少訓練資源。
DeepSeek-R1 技術報告中寫到:「具體來說,我們使用 DeepSeek-V3-Base 作為基礎模型,并采用 GRPO 作為強化學習框架來提高模型的推理性能。在訓練過程中,DeepSeek-R1-Zero 自然地涌現出了許多強大而有趣的推理行為。經過數千個強化學習步驟后,DeepSeek-R1-Zero 在推理基準上表現出超強的性能。」
但現在,有一項研究卻證明 GRPO 對推理模型來說并不很重要。
階躍星辰與清華大學近期的一項研究發現,只需使用帶 GAE (λ= 1,γ= 1)的普通 PPO 以及基于規則的簡單獎勵函數,無需任何 KL 正則化,就足以擴展在推理任務上的響應長度和基準性能,類似于在 DeepSeek-R1-Zero 上觀察到的現象。
使用這種極簡方法,他們打造了 Open-Reasoner-Zero,這是首個面向大規模推理的強化學習訓練的開源實現。并且該實現在 GPQA Diamond 基準上的表現優于 DeepSeek-R1-Zero-Qwen-32B,同時僅需使用 1/30 的訓練步數。需要強調,該團隊不僅開源了代碼,還發布了參數設置、訓練數據和模型權重。

- 論文標題:Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
- 論文地址:https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero/blob/main/ORZ_paper.pdf
- 項目地址:https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero
- Hugging Face:https://huggingface.co/Open-Reasoner-Zero
從基礎模型開始擴展強化學習
下面首先將介紹基礎又關鍵的設置,括數據整編、獎勵函數和近端策略優化 (PPO) 算法的詳細設置。然后會討論從消融實驗中得出的關鍵見解,這些見解可以成功實現規模化強化學習訓練。
基礎設置
實驗中,基礎模型使用的是 Qwen2.5-{7B, 32B},并且不經過任何微調(如蒸餾或 SFT)即開始規模化強化學習訓練。在 Qwen2.5-{7B, 32B} 基礎模型的基礎上,該團隊擴展了標準 PPO 算法,以用于面向推理的強化學習訓練,同時仔細考慮了可擴展性和穩健性。
數據集方面,該團隊精心編排了涉及 STEM、數學和推理任務的數萬對問答數據,目標是增強模型在多樣化和復雜問題求解場景中的能力。
受 DeepSeek-R1 啟發,他們設計的提示詞模板可以引導模型利用推理計算,逐步掌握針對復雜任務的推理能力,如表 1 所示。

此外,他們還基于 OpenRLHF 開發了一個高效的大規模強化學習訓練框架,通過引入更靈活的訓練器,實現了 GPU 共置生成(collocation generation)以及支持卸載和回載的訓練。
數據集
高質量訓練數據對可擴展 Reasoner-Zero 訓練來說非常關鍵。這里作者關注了三個關鍵方面:數量、多樣性和質量。
詳細的收集整理過程請閱讀原論文。最終,他們得到的數據集包含 57k 樣本,涵蓋 STEM、數學和推理領域。
獎勵函數
不同于 DeepSeek-R1-Zero,這里的規模化強化學習訓練采用了簡單的規則式獎勵函數 —— 該函數僅檢查答案的正確性,沒有任何額外的格式獎勵。
具體來說,這個獎勵函數會在訓練時提取 <answer> 與 </answer> 標簽之間的內容,并將其與參考答案比較。
為了保證規模化強化學習清晰又簡單,他們實現了一種二元獎勵方案:如果與參考答案完全匹配,則獎勵為 1;所有其他情況的獎勵為 0。
為了確保評估嚴格且一致,他們采用了被廣泛使用的 Math-Verify 庫,圖 3 展示了其用法。

出人意料的是,該團隊發現,使用新設計的提示,即使是未對齊的基礎模型也能以很高的概率產生格式良好的響應。在早期訓練階段,基礎模型僅通過簡單的基于規則的獎勵函數就能快速學會和強化正確的推理和回答格式,如圖 4 所示。更重要的是,初步實驗表明,復雜的獎勵函數不僅是不必要的,而且可能為獎勵 hacking 留下潛在的空間。

強化學習算法
不同于 DeepSeek-R1-Zero 使用的 GRPO,該團隊為規模化訓練采用的強化學習算法是近端策略優化(PPO)算法。
具體來說,對于每個問題 q(即提示詞),模型會根據基于規則的獎勵函數生成一組響應 {o_1, o_2, ..., o_n} 并接收相應的獎勵 {r_1, r_2, ..., r_n},其中 n 表示采樣軌跡的數量(即每個提示詞的 rollout 大小)。
對于時間步驟 t (即 token t)處的每個響應 o_i ,令 s_t 表示時刻 t 的狀態,包括問題和所有之前生成的 token,并令 a_t 表示在該步驟生成的 token。
對于每個 token,使用 Generalized Advantage Estimation(GAE)計算其優勢估計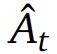 。一般來說,GAE 能在優勢估計中提供偏差與方差的權衡,做法是通過一個由參數 λ 控制的指數加權平均值將 n 步優勢估計組合起來。該優勢估計的計算方式是:
。一般來說,GAE 能在優勢估計中提供偏差與方差的權衡,做法是通過一個由參數 λ 控制的指數加權平均值將 n 步優勢估計組合起來。該優勢估計的計算方式是: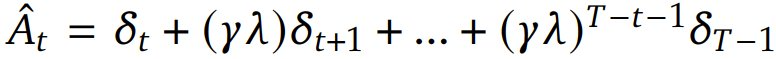 ,其中
,其中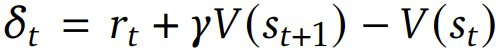 是 TD(temporal difference)殘差,γ 是折扣因子,它決定了未來獎勵相對于即時獎勵的價值。該 PPO 算法通過優化以下目標函數來更新策略模型參數 θ 以最大化預期獎勵和價值模型參數 Φ,從而最小化價值損失:
是 TD(temporal difference)殘差,γ 是折扣因子,它決定了未來獎勵相對于即時獎勵的價值。該 PPO 算法通過優化以下目標函數來更新策略模型參數 θ 以最大化預期獎勵和價值模型參數 Φ,從而最小化價值損失:
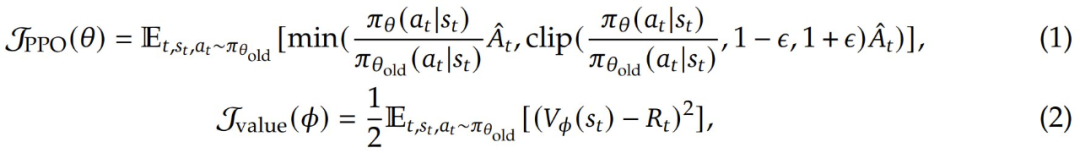
其中 ε 是 clipping 參數,π_θ 是當前策略,π_θ_old 是更新前的舊策略,V_Φ 是價值函數, 是折扣回報。
是折扣回報。
具體到實例上,該團隊為該 PPO 算法精心挑選了一些超參數:GAE 參數 λ = 1.0、折扣因子 γ = 1.0 和 clipping 參數 ε = 0.2。
主要發現
該團隊得到了以下主要發現:
強化學習算法關鍵實現:實證研究表明,原始的 PPO 在不同模型規模和訓練持續時間內能夠提供非常穩定和強大的訓練過程,而無需進行額外的修改。通過廣泛的實驗,他們發現 GAE 參數在 PPO 推理任務中起著關鍵作用。具體來說,設置 λ = 1.0 和 γ = 1.0。雖然這種設置在傳統強化學習場景中通常被認為是次優的,但它卻能實現規模化強化學習訓練的理想平衡。
最小獎勵函數設計:該團隊研究表明,簡單的基于規則的獎勵函數不僅足夠而且是最佳的,因為最小設計不會留下任何潛在的獎勵 hacking 空間。值得注意的是,即使是未對齊的基礎模型也能快速適應所需的格式,這表明這是一項簡單的任務,不需要復雜的獎勵工程設計。
損失函數:該團隊在不依賴任何基于 KL 的正則化技術(例如 KL 形狀的獎勵和損失)的情況下實現了穩定的訓練,這不同于 RLHF 社區和推理器模型普遍使用的方法。這也有很好的潛力實現進一步大規模強化學習。
擴大訓練數據規模:該團隊發現擴大數據量和多樣性對于 Reasoner-Zero 訓練至關重要。雖然在有限的學術數據集(如 MATH)上進行訓練會導致性能快速停滯,但該團隊精細編排的大規模多樣化數據集能夠實現持續擴展,而不會在訓練和測試集上出現飽和跡象。
實驗表現如何?
下面介紹 Open-Reasoner-Zero 模型的全面實驗結果和分析。其中包括兩個方面的初步實驗結果:利用訓練得到的推理器進行蒸餾,在蒸餾得到的模型上使用 Open-Reasoner-Zero 訓練流程以進一步增強其推理能力(類似 DeepSeek-R1 的方法)。訓練的細節和超參數請參閱原論文,這里我們重點來看結果。
訓練曲線
圖 2 顯示了在 Open-Reasoner-Zero 7B 和 32B 上的實驗的訓練獎勵和平均響應長度曲線,而圖 5 展示了在訓練和評估集上對 Open-Reasoner-Zero 7B 的實驗的獎勵 / 準確度和平均響應長度曲線。訓練獎勵曲線和響應長度曲線分別表示生成的響應的平均獎勵和每個生成步驟中生成的響應的平均長度。
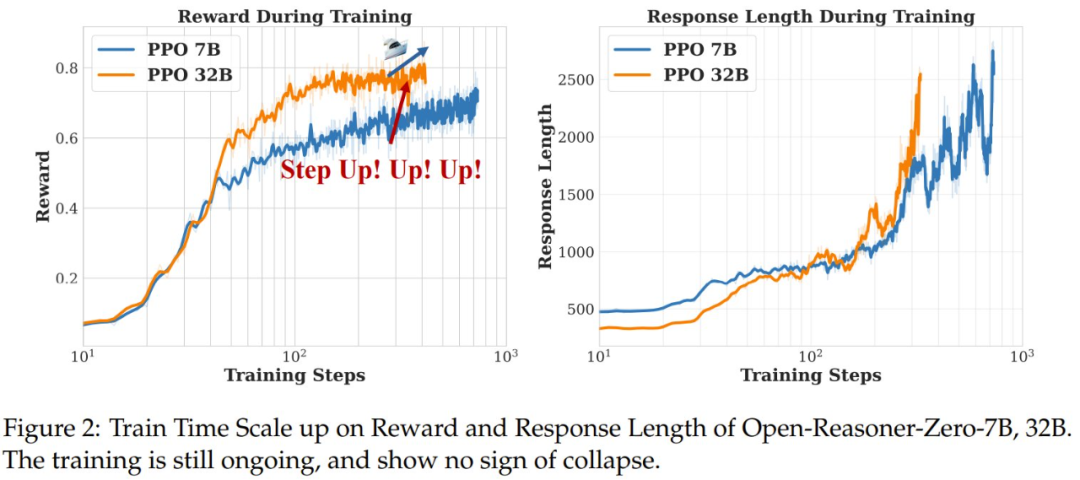

可以看到,這些指標在整個訓練過程中在兩個模型和所有基準上都得到了持續的改進,并有值得注意的觀察結果:OpenReasoner-Zero 表現出一種有趣的「階躍時刻」現象,其中響應指標在訓練過程中突然增加,這表明其涌現出了推理能力。
響應長度擴展與 DeepSeek-R1-Zero
如圖 6 所示,可以看到整個訓練過程中響應長度持續增加,沒有飽和跡象,類似于 DeepSeek-R1-Zero 中看到的行為。
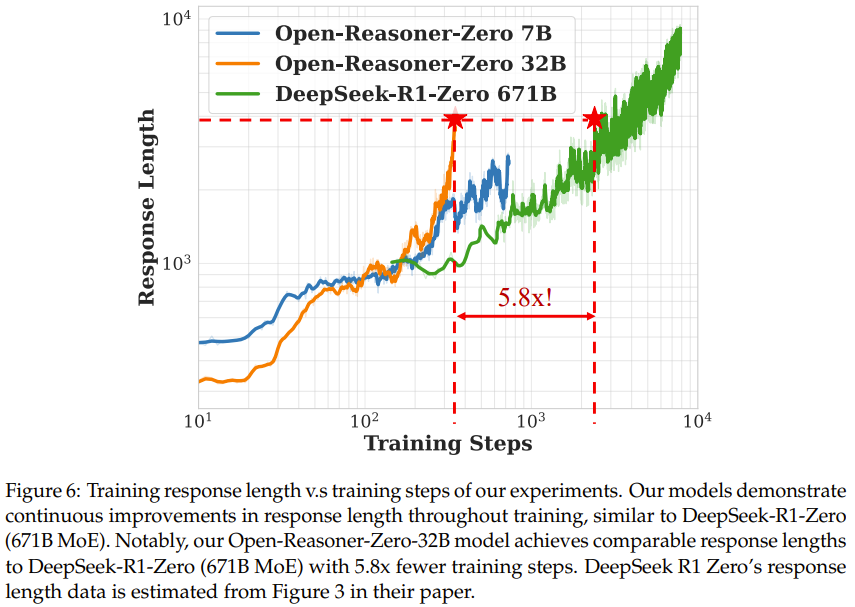
值得注意的是,雖然模型大小和訓練步驟都有助于改善響應長度,但 Open-Reasoner-Zero-32B 模型僅用 1/5.8 的訓練步數就實現了與 DeepSeek-R1-Zero (671B MoE) 相當的響應長度。這種卓越的訓練效率證明了新的極簡主義方法對大規模強化學習訓練的有效性。
質量分析
該團隊也對 Open-Reasoner-Zero 模型生成的響應進行了一些定性分析。為了分析模型的反思能力并觀察像 DeepSeek-R1-Zero 這樣的頓悟時刻,他們遵從之前的方法確定了五種代表性的反思模式(wait、recheck、retry、alternatively、however)。他們將包含任何這些模式的響應數量計為「反思響應」,并確定平均正確反思長度(包含獲得正確答案的反思模式的響應的長度)。
如圖 7 所示,在整個訓練過程中,平均正確反思長度始終超過平均響應長度,這表明包含反思模式的響應利用了更多的「思考時間」來獲得正確答案,類似于 OpenAI o1 中描述的測試時間擴展。
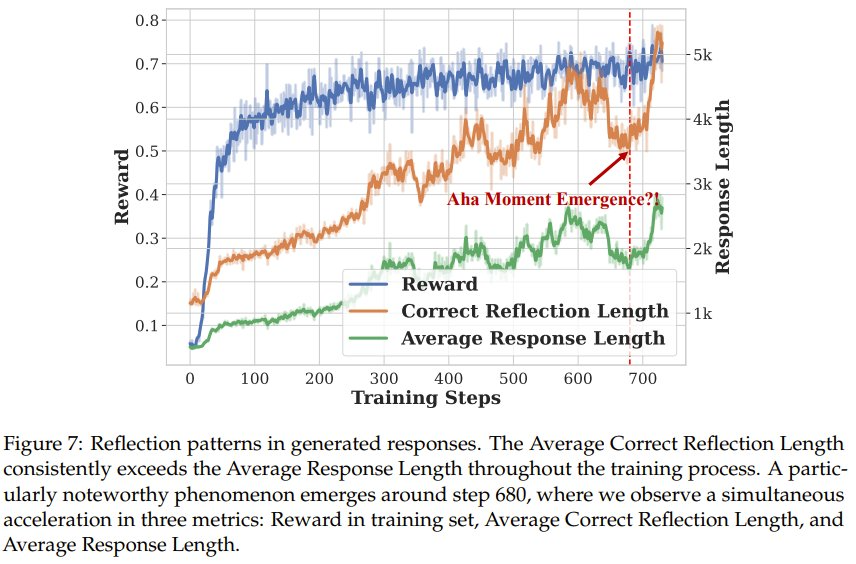
一個特別值得注意的現象出現在步驟 680 左右,該團隊觀察到三個指標同時加速:獎勵、平均正確反思長度和平均響應長度。通過手動檢查步驟 680 之前和之后的模型輸出,該團隊發現之后的響應中有更明顯的反思模式。這種涌現行為值得進一步研究,該團隊表示目前正在進行詳細分析,以了解這種現象的潛在機制。
該團隊也研究了新模型在知識和指令遵從基準 MMLU_PRO 和 IFEval 上的泛化能力,結果見表 2。

可以看到,Open-Reasoner-Zero 32B 模型表現出了強大的泛化能力:無需任何額外的指令微調,在 MMLU、MMLU_PRO 基準上,通過純規模化強化學習訓練在面向推理的任務上顯著優于 Qwen2.5 Instruct 32B。
該團隊也進行了詳細的消融實驗,詳見原論文。

























