













實現(xiàn)AGI,強化學習就夠了?Sutton:獎勵機制足夠?qū)崿F(xiàn)各種目標
幾十年來,在人工智能領(lǐng)域,計算機科學家設計并開發(fā)了各種復雜的機制和技術(shù),以復現(xiàn)視覺、語言、推理、運動技能等智能能力。盡管這些努力使人工智能系統(tǒng)在有限的環(huán)境中能夠有效地解決特定的問題,但卻尚未開發(fā)出與人類和動物一般的智能系統(tǒng)。
人們把具備與人類同等智慧、或超越人類的人工智能稱為通用人工智能(AGI)。這種系統(tǒng)被認為可以執(zhí)行人類能夠執(zhí)行的任何智能任務,它是人工智能領(lǐng)域主要研究目標之一。關(guān)于通用人工智能的探索正在不斷發(fā)展。近日強化學習大佬 David Silver、Richard Sutton 等人在一篇名為《Reward is enough》的論文中提出將智能及其相關(guān)能力理解為促進獎勵最大化。

論文地址:
https://www.sciencedirect.com/science/article/pii/S0004370221000862
該研究認為獎勵足以驅(qū)動自然和人工智能領(lǐng)域所研究的智能行為,包括知識、學習、感知、社交智能、語言、泛化能力和模仿能力,并且研究者認為借助獎勵最大化和試錯經(jīng)驗就足以開發(fā)出具備智能能力的行為。因此,他們得出結(jié)論:強化學習將促進通用人工智能的發(fā)展。

AI 的兩條路徑
創(chuàng)建 AI 的一種常見方法是嘗試在計算機中復制智能行為的元素。例如,我們對哺乳動物視覺系統(tǒng)的理解催生出各種人工智能系統(tǒng),這些系統(tǒng)可以對圖像進行分類、定位照片中的物體、定義物體的邊界等。同樣,我們對語言的理解也幫助開發(fā)了各種自然語言處理系統(tǒng),比如問答、文本生成和機器翻譯。
但這些都是狹義人工智能的實例,只是被設計用來執(zhí)行特定任務的系統(tǒng),而不具有解決一般問題的能力。一些研究者認為,組裝多個狹義人工智能模塊將產(chǎn)生更強大的智能系統(tǒng),以解決需要多種技能的復雜問題。
而在該研究中,研究者認為創(chuàng)建通用人工智能的方法是重新創(chuàng)建一種簡單但有效的規(guī)則。該研究首先提出假設:獎勵最大化這一通用目標,足以驅(qū)動自然智能和人工智能中至少大部分的智能行為。」
這基本上就是大自然自身的運作方式。數(shù)十億年的自然選擇和隨機變異讓生物不斷進化。能夠應對環(huán)境挑戰(zhàn)的生物才能得以生存和繁殖,其余的則被淘汰。這種簡單而有效的機制促使生物進化出各種技能和能力來感知、生存、改變環(huán)境,以及相互交流。
研究者說:「人工智能體未來所面臨的環(huán)境和動物與人類面臨的自然世界一樣,本質(zhì)上是如此復雜,以至于它們需要具備復雜的能力才能在這些環(huán)境中成功生存。」因此,以獎勵最大化來衡量的成功,需要智能體表現(xiàn)出相關(guān)的智能能力。從這個意義上說,獎勵最大化的一般目標包含了許多甚至可能是所有的智能目標。并且,研究者認為最大化獎勵最普遍和可擴展的方式是借助與環(huán)境交互學習的智能體。
獎勵就足夠了
與人工智能的許多交互式方法一樣,強化學習遵循一種協(xié)議,將問題分解為兩個隨時間順序交互的系統(tǒng):做出決策的智能體(解決方案)和受這些決策影響的環(huán)境(問題)。這與其他專用協(xié)議形成對比,其他專用協(xié)議可能考慮多個智能體、多個環(huán)境或其他交互模式。
基于強化學習的思想,該研究認為獎勵足以表達各種各樣的目標。智能的多種形式可以被理解為有利于對應的獎勵最大化,而與每種智能形式相關(guān)的能力能夠在追求獎勵的過程中隱式產(chǎn)生。因此該研究假設所有智能及相關(guān)能力可以理解為一種假設:「獎勵就足夠了」。智能及其相關(guān)的能力,可以理解為智能體在其環(huán)境中的行為獎勵最大化。
這一假設很重要,因為如果它是正確的,那么一個獎勵最大化智能體在服務于其實現(xiàn)目標的過程中,就可以隱式地產(chǎn)生與智能相關(guān)的能力,具備出色智能能力的智能體將能夠「適者生存」。研究者從以下幾個方面論述了「獎勵就足夠了」這一假設。
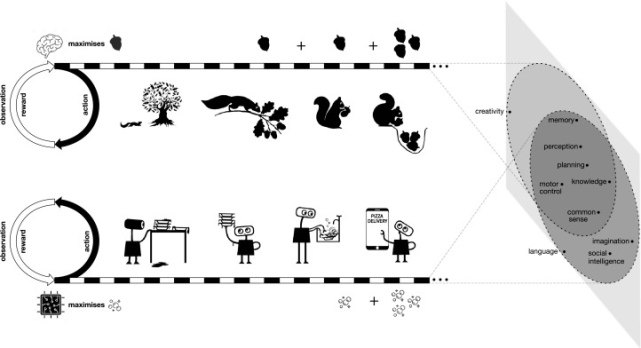
知識和學習
該研究將知識定義為智能體內(nèi)部信息,例如,知識可以包含于用于選擇動作、預測累積獎勵或預測未來觀測特征的函數(shù)參數(shù)中。有些知識是先驗知識,有些知識是通過學習獲得的。獎勵最大化的智能體將根據(jù)環(huán)境情況包含前者,例如借助自然智能體的進化和人工智能體的設計,并通過學習獲取后者。隨著環(huán)境的不斷豐富,需求的平衡將越來越傾向于學習知識。
感知
人類需要各種感知能力來積累獎勵,例如分辨朋友和敵人,開車時進行場景解析等。這可能需要多種感知模式,包括視覺、聽覺、嗅覺、軀體感覺和本體感覺。
相比于監(jiān)督學習,從獎勵最大化的角度考慮感知,最終可能會支持更廣泛的感知行為,包括如下具有挑戰(zhàn)性和現(xiàn)實形式的感知能力:
動作和觀察通常交織在多種感知形式中,例如觸覺感知、視覺掃視、物理實驗、回聲定位等;
感知的效用通常取決于智能體的行為;
獲取信息可能具有顯式和隱式成本;
數(shù)據(jù)的分布通常依賴于上下文,在豐富的環(huán)境中,潛在數(shù)據(jù)多樣性可能遠遠超過智能體的容量或已存在數(shù)據(jù)的數(shù)量——這需要從經(jīng)驗中獲取感知;
感知的許多應用程序無法獲得有標記的數(shù)據(jù)。
社交智能
社交智能是一種理解其他智能體并與之有效互動的能力。根據(jù)該研究的假設,社交智能可以被理解為在智能體環(huán)境中的某一智能體最大化累積獎勵。按照這種標準智能體 - 環(huán)境協(xié)議,一個智能體觀察其他智能體的行為,并可能通過自身行為影響其他智能體,就像它觀察和影響環(huán)境的其他方面一樣。一個能夠預測和影響其他智能體行為的智能體通常可以獲得更大的累積獎勵。因此,如果一個環(huán)境需要社交智能(例如包含動物或人類的環(huán)境),獎勵最大化將能夠產(chǎn)生社交智能。
語言
語言一直是自然和人工智能領(lǐng)域大量研究的一個主題。由于語言在人類文化和互動中起著主導作用,智能本身的定義往往以理解和使用語言的能力為前提,尤其是自然語言。
然而,當前的語言建模本身不足以產(chǎn)生更廣泛的與智能相關(guān)的語言能力,包括:
語言通常是上下文相關(guān)的,不僅與所說的內(nèi)容相關(guān),還與智能體周圍環(huán)境中正在發(fā)生的其他事情有關(guān),有時需要通過視覺和其他感官模式感知。此外,語言經(jīng)常穿插其他表達行為,例如手勢、面部表情、音調(diào)變化等。
語言是有目的并能對環(huán)境產(chǎn)生影響的。例如,銷售人員學習調(diào)整他們的語言以最大化銷售額。
語言的具體含義和效用因智能體的情況和行為而異。例如,礦工可能需要有關(guān)巖石穩(wěn)定性的語言,農(nóng)民可能需要有關(guān)土壤肥力的語言。此外,語言可能存在機會成本,例如討論農(nóng)業(yè)的人并不一定是從事農(nóng)業(yè)工作)。
在豐富的環(huán)境中,語言處理不可預見事件的潛在用途可能超出任何語料庫的能力。在這些情況下,可能需要通過經(jīng)驗動態(tài)地解決語言問題。例如開發(fā)一項新技術(shù)或找到一種方法來解決一個新的問題。
該研究認為基于「獎勵就足夠了」的假設,豐富的語言能力,包括所有這些更廣泛的能力,都應該源于對獎勵的追求。
泛化
泛化能力通常被定義為將一個問題的解決方案轉(zhuǎn)換為另一個問題的解決方案的能力。例如,在監(jiān)督學習中,泛化可能專注于將從一個數(shù)據(jù)集(例如照片)學到的解決方案轉(zhuǎn)移到另一個數(shù)據(jù)集(例如繪畫)。
根據(jù)該研究的假設,泛化可以通過在智能體和單個復雜環(huán)境之間的持續(xù)交互流中最大化累積獎勵來實現(xiàn),這同樣遵循標準的智能體 - 環(huán)境協(xié)議。人類世界等環(huán)境需要泛化,因為智能體在不同的時間會面對環(huán)境的不同方面。例如,一只吃水果的動物可能每天都會遇到一棵新樹,這個動物也可能會受傷、遭受干旱或面臨入侵物種。在每種情況下,動物都必須通過泛化過去狀態(tài)的經(jīng)驗來快速適應新狀態(tài)。動物面臨的不同狀態(tài)并沒有被整齊地劃分為具有不同標簽的任務。相反,狀態(tài)取決于動物的行為,它可能結(jié)合了在不同時間尺度上重復出現(xiàn)的各種元素,可以觀察到狀態(tài)的重要方面。豐富的環(huán)境同樣需要智能體從過去的狀態(tài)泛化到未來的狀態(tài),以及所有相關(guān)的復雜性,以便有效地積累獎勵。
模仿
模仿是與人類和動物智能相關(guān)的一種重要能力,它可以幫助人類和動物快速獲得其他能力,例如語言、知識和運動技能。在人工智能中,模仿通常被表述為通過行為克隆,從演示中學習,并提供有關(guān)教師行為、觀察和獎勵的明確數(shù)據(jù)時。相比之下,觀察學習的自然能力包括從觀察到的其他人類或動物的行為中進行的任何形式的學習,并且不要求直接訪問教師的行為、觀察和獎勵。這表明,與通過行為克隆的直接模仿相比,在復雜環(huán)境中可能需要更廣泛和現(xiàn)實的觀察學習能力,包括:
其他智能體可能是智能體的環(huán)境的組成部分(例如嬰兒觀察其母親),而無需假設存在包含教師數(shù)據(jù)的特殊數(shù)據(jù)集;
智能體可能需要學習它自己的狀態(tài)與另一個智能體的狀態(tài)之間的關(guān)聯(lián),或者智能體自己的動作和另一個智能體的觀察結(jié)果,這可能會產(chǎn)生更高的抽象級別;
其他智能體可能只能被部分觀察到,因此他們的行為或目標可能只是被不完美地推斷出來;
其他智能體可能會表現(xiàn)出應避免的不良行為;
環(huán)境中可能有許多其他智能體,表現(xiàn)出不同的技能或不同的能力水平。
該研究認為這些更廣泛的觀察學習能力能夠由獎勵最大化驅(qū)動的,從單個智能體的角度來看,它只是將其他智能體視為其環(huán)境的組成部分,這可能會帶來許多與行為克隆相同的好處。例如樣本高效的知識獲取,但這需要更廣泛和更綜合的背景下。
通用智能
基于該研究的假設,通用智能可以理解為通過在單一復雜的環(huán)境中最大化一個特殊獎勵來實現(xiàn)。例如,自然智能在其整個生命周期中都面向從與自然世界的互動中產(chǎn)生的連續(xù)經(jīng)驗流。動物的經(jīng)驗流足夠豐富和多樣,它可能需要靈活的能力來實現(xiàn)各種各樣的子目標(例如覓食、戰(zhàn)斗、逃跑等),以便成功地最大化其整體獎勵(例如饑餓或繁殖) 。類似地,如果人工智能體的經(jīng)驗流足夠豐富,那么單一目標(例如電池壽命或生存)可能隱含地需要實現(xiàn)同樣廣泛的子目標的能力,因此獎勵最大化應該足以產(chǎn)生一種通用人工智能。
強化學習智能體
該研究的主要假設是智能及其相關(guān)能力可以被理解為促進獎勵最大化,這與智能體的性質(zhì)無關(guān)。因此,如何構(gòu)建最大化獎勵的智能體是一個重要問題。該研究認為這個問題同樣可以通過問題本身,即「獎勵最大化」來回答。具體來說,研究者設想了一種具有一般能力的智能體,然后從他們與環(huán)境交互的持續(xù)經(jīng)驗中學習如何最大化獎勵。這種智能體,被稱之為強化學習智能體。
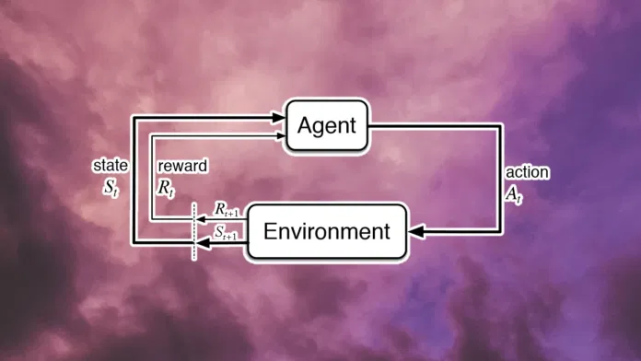
在所有可能的最大化獎勵的解決方法中,最自然的方法當然是通過與環(huán)境交互,從經(jīng)驗中學習。隨著時間的推移,這種互動體驗提供了大量關(guān)于因果關(guān)系、行為后果以及如何積累獎勵的信息。與其預先確定智能體的行為(相信設計者對環(huán)境的預知),不如賦予智能體發(fā)現(xiàn)自己行為的一般能力(相信經(jīng)驗)是很自然的。更具體地說,最大化獎勵的設計目標是通過從經(jīng)驗中學習最大化獎勵的行為的持續(xù)內(nèi)部過程來實現(xiàn)的。
獎勵真的足夠了嗎?
對于該研究「獎勵就足夠了」的觀點,有網(wǎng)友表示不贊成:「這似乎是對個人效用函數(shù)這一共同概念的重新語境化。所有生物都有效用函數(shù),他們的目標是最大化他們的個人效用。效用理論有著深厚而豐富的歷史淵源,但本文對效用理論的認識并不多見。Silver 和 Sutton 都是 RL 領(lǐng)域的大牛,但對我而言,這篇論文給我的感覺很糟糕。」
還有網(wǎng)友認為這是重新包裝進化論:

甚至有人質(zhì)疑「備受尊敬的研究者更容易陷入過度自信」:
還有網(wǎng)友表示:「這篇文章沒有對可以做什么和不能做什么設置任何界限。難道無需直接分析函數(shù)即可知道在嘗試最大化函數(shù)時可以或不能出現(xiàn)什么嗎?獎勵函數(shù)與獲得這些獎勵的系統(tǒng)相結(jié)合,完全確定了 “可出現(xiàn)” 行為的空間,而無論出現(xiàn)什么,對它們來說都是智能行為。」
不過,也有人提出了一個合理的問題:

最終目標獎勵是否會產(chǎn)生一般的智能,或者是否會產(chǎn)生一些額外的信號?純獎勵信號是否會陷入局部最大值?他們的論點是,對于一個非常復雜的環(huán)境,它不會。
但如果你有一個足夠復雜的環(huán)境,模型有足夠的參數(shù),并且你不會陷入局部最大值,那么一旦系統(tǒng)解決了問題中的瑣碎,簡單的部分,唯一的方法是提高性能,創(chuàng)建更通用的解決方案,即變得更智能。


























