復旦主導,中美等8個國家25家單位44名學者聯合發布大模型安全技術綜述
近年來,隨著大模型的快速發展和廣泛應用,其安全問題引發了社會各界的廣泛關注。例如,近期發生的「全球首例利用 ChatGPT 策劃的恐襲事件」再次敲響了警鐘,凸顯了大模型安全問題的緊迫性和重要性。
為應對這一挑戰,來自中美英德等 8 個國家 25 家高校和科研機構的 44 位 AI 安全領域學者聯合發布了一篇系統性技術綜述論文。該論文的第一作者是復旦大學馬興軍老師,通信作者是復旦大學姜育剛老師,領域內眾多知名學者共同參與。

- 論文標題:Safety at Scale: A Comprehensive Survey of Large Model Safety
- 論文地址:https://arxiv.org/abs/2502.05206
- GitHub 主頁:https://github.com/xingjunm/Awesome-Large-Model-Safety
這篇綜述論文全面調研了近年來大模型安全相關的 390 篇研究工作,并采用簡單直接的三級目錄結構對內容進行了系統梳理(如圖 3 所示):一級目錄聚焦模型類型,二級目錄區分攻擊與防御類型,三級目錄細化技術路線。
研究覆蓋了視覺基礎模型、大語言模型、視覺-語言預訓練模型、視覺-語言模型、文生圖擴散模型和智能體等 6 種主流大模型,以及對抗攻擊、后門攻擊、數據投毒、越獄攻擊、提示注入、能量延遲攻擊、成員推理攻擊、模型抽取攻擊、數據抽取攻擊和智能體攻擊等 10 種攻擊類型。

論文總結了 4 個重要研究趨勢(參考下圖 1 和 2):
1. 研究規模顯著增長
過去 4 年,大模型安全研究論文數量成倍增長,2024 年相關研究已突破 200 篇,充分體現了學術界和產業界對該領域的高度關注。
2. 攻防研究比例失衡
在現有研究中,約 60% 的工作聚焦于攻擊方法,而防御相關研究僅占 40%。這種攻防研究的不平衡狀態凸顯了當前防御技術的不足,亟需更多資源投入以提升大模型的安全性。
3. 重點攻擊目標
大語言模型、文生圖擴散模型以及視覺基礎模型(包括預訓練 ViT 和 SAM)是目前最受攻擊者關注的三類模型。這些模型因其廣泛的應用場景和高影響力,成為安全研究的核心焦點。
4. 主流攻擊類型
對抗攻擊、后門和投毒攻擊以及越獄攻擊是目前被研究最多的三大攻擊類型。這些攻擊手段因其高成功率和潛在危害性,成為大模型安全領域的主要挑戰。
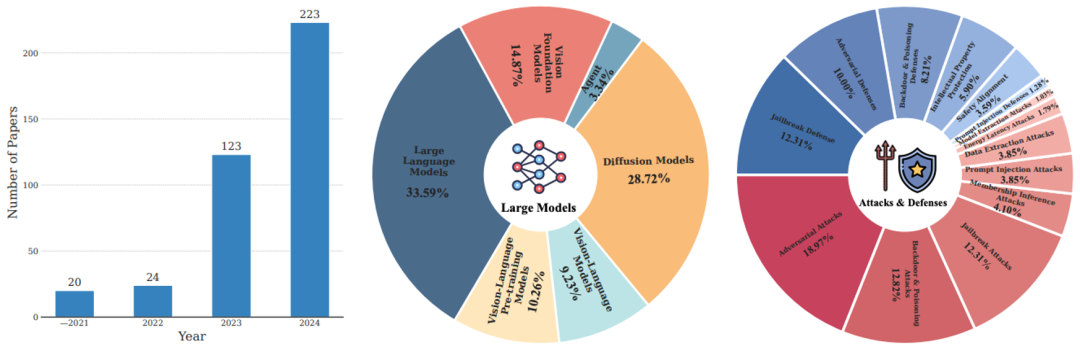
圖 1. (左)過去四年發表的大模型安全研究論文數量;(中)各類大模型的研究分布;(右)各類攻擊 / 防御的研究分布。

圖 2. (左)不同模型上研究論文數量的季度變化趨勢;(中)各類大模型與對應攻防研究之間的比例對應關系;(右)各類攻防研究論文年度發表數量的變化趨勢(從高到低上下排序)。
除了介紹針對各類模型的攻擊與防御方法,論文還歸納了研究常用的數據集和評估基準,為初學者快速了解領域進展和實驗設置提供了參考。論文的組織結構清晰,內容詳實,不僅為學術界和產業界提供了全面的研究指南,也為未來大模型安全研究指明了方向。
最后,論文總結了大模型安全領域的主要挑戰,并呼吁學術界與國際社會協同合作,共同應對這些難題:
1. 根本脆弱性理解不足
領域需要增加對大模型根本脆弱性的理解。比如大語言模型的脆弱性根源是什么,不同模態間的脆弱性是否會相互傳播?文生圖和文生視頻類大模型語言能力的缺乏是否會讓它們更難對齊?此外,大模型是否真的會記憶原始訓練數據或者以何種方式、多大程度記憶訓練數據?
2. 安全評測的局限性
當前評估方法存在顯著不足。單一參考攻擊成功率無法全面衡量模型安全性,基于靜態數據集的基準評測難以應對各類攻擊。盡管對抗性評測不可或缺,但在實際環境中,其全面性、準確性和動態性仍需提升。
3. 防御機制亟待加強
現有防御措施存在明顯短板,當前防御體系缺乏主動機制和有效檢測手段。安全對齊技術并不是萬能的,在面對更先進的攻擊時仍可被繞過。隨著具身智能發展和通用智能的接近,領域亟需更具系統性、實用性和前瞻性的防御方案。
4. 呼吁全球合作
為應對日益多樣化的挑戰,倡議發展以防御為導向的大模型安全研究,開發更強大的安全防御工具。呼吁模型開源、呼吁商業模型提供專用安全 API、呼吁建立開源安全平臺。呼吁全球合作,只有通過學術界、產業界和國際社會的共同努力,才能構建更安全可信的人工智能生態系統。