













不蒸餾R1也能超越DeepSeek,上海 AI Lab 用RL突破數學推理極限
僅通過強化學習,就能超越DeepSeek!
上海AI Lab提出了基于結果獎勵的強化學習新范式——
從Qwen2.5-32B-Base模型出發,僅通過微調和基于結果反饋的強化學習,在不蒸餾超大模型如DeepSeek-R1的情況下,就能超越DeepSeek-R1-Distill-Qwen32B和OpenAI-O1系列的超強數學推理性能。

團隊發現,當前大模型數學推理任務面臨”三重門”困局:

- 稀疏獎勵困境:最終答案對錯的二元反饋,使復雜推理的優化變得困難
- 局部正確陷阱:長思維鏈中部分正確步驟反而可能誤導模型學習
- 規模依賴魔咒:傳統蒸餾方法迫使研究者陷入”參數規模軍備競賽”
因此,研究團隊重新審視了當前基于結果獎勵的強化學習算法,經過嚴格的理論推導與證明,重新設計了一個新的結果獎勵強化學習算法,并在這個過程中得出了三點重要結論:
- 對于正樣本:在二元反饋環境下,通過最佳軌跡采樣(BoN)的行為克隆即可學習最優策略
- 對于負樣本:需要使用獎勵重塑來維護策略優化目標的一致性
- 對于長序列:不同的序列部分對結果的貢獻不同,因此需要更細粒度的獎勵分配函數,這個函數可以通過結果獎勵習得
通俗來說,就是通過對正確樣本模仿學習,錯誤樣本偏好學習,關鍵步驟重點學習,無需依賴超大規模的模型(例如DeepSeek-R1)進行蒸餾,僅通過強化學習即可達到驚人的效果。
除此之外,團隊也對不同起點模型進行了強化學習訓練對比和分析,發現強化學習的起點模型和訓練數據分布對最終的模型效果也很重要。因此,研究團隊將RL訓練的數據、起點和最終模型一起完整開源,來推動社區的公平比較和進一步研究。項目鏈接已放文末。
從頭設計結果獎勵強化學習
針對數學推理任務中強化學習面臨的稀疏獎勵和局部正確難題,團隊提出新的策略優化框架OREAL。
通過理論創新實現針對性的算法改進,在用實驗說明“怎么做更好”之前,首先論證“為什么這么做更好”
正負樣本獎勵重塑,解決稀疏獎勵困境
在數學推理任務的采樣流程中,團隊經過理論分析推導,提出核心見解:在二元反饋機制下,采樣任意數量包含正確答案的BoN(Best-of-N)設置,其正確軌跡的分布具有一致性特征。這一發現表明,通過直接行為克隆(behaviorcloning)采樣得到的正確軌跡,已經構成了正樣本訓練中的最優設置。
在對正樣本做模仿學習的基礎上,團隊提出直接懲罰負樣本會導致梯度偏差問題,對負樣本的訓練原則應當是維護優化梯度形式與學習BoN分布一致。通過深入分析正負樣本的訓練梯度,研究者們提出了基于平均準確率p的獎勵重塑因子來維護上述一致性,為GRPO等算法的改進提供了理論依據。這種設置使模型既能有效吸收成功經驗,又能精確識別關鍵錯誤邊界,對訓練性能有明顯幫助。

結果獎勵「因果溯源」,跳出局部正確陷阱
針對復雜的長推理鏈問題,OREAL創新性地設計了token重要性估計器。通過構建序列累計形式的獎勵函數,我們將結果獎勵逆向分解到每個推理步驟(見下面的token-level RM熱力圖)。這種方法能夠精確定位核心錯誤步驟,在訓練時實現更精細的梯度更新,顯著提升了模型在長序列任務中的表現。

OREAL框架
將幾項認知組合起來,團隊提出的最優強化學習策略可以概括為:在正確樣本上模仿學習,在錯誤樣本上偏好學習,對關鍵步驟做重點學習。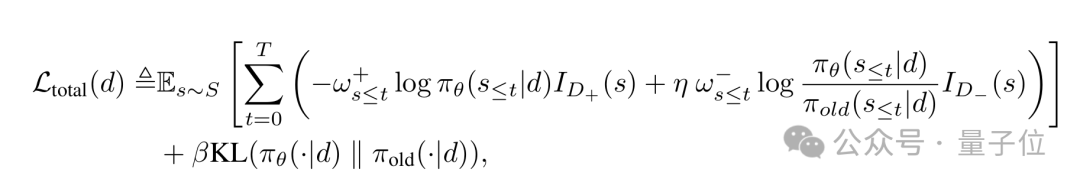
通過合理的分析和實踐,一步步將強化學習性能推到最佳水平。
強化學習超越蒸餾,擺脫規模依賴魔咒
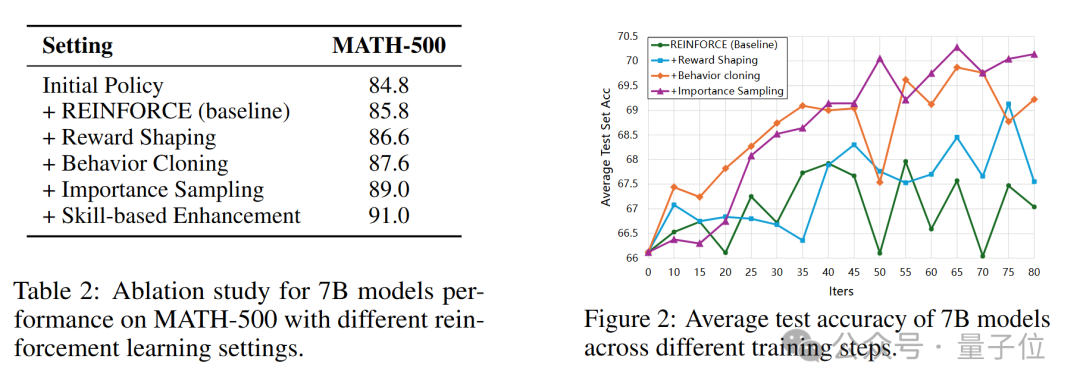
團隊在7B和32B兩個規模的模型上僅使用4千條高質量訓練樣本進行了訓練和測試,
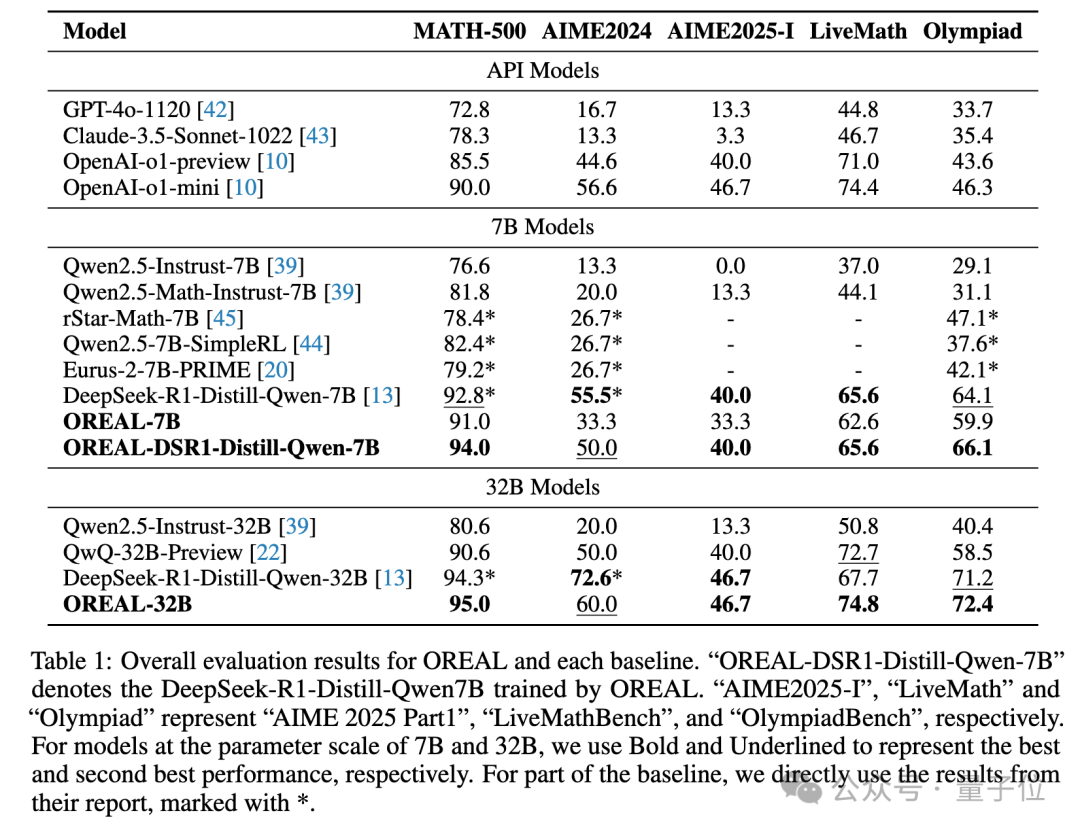
在7B量級上,Oreal-7B在MATH-500上取得了91.0的pass@1準確率。這是首次通過強化學習而非蒸餾方法達到了如此高的精度。這一成績不僅為基于RL的方法樹立了新的里程碑,還超越了更大參數量的模型,包括QWQ-32B-Preview和OpenAI-O1-Mini。
此外,將Oreal應用于此前最佳的7B模型(DeepSeek-r1-Distill-Qwen-7B)后,得到的新模型OREAL-DSR1-Distill-Qwen-7B在MATH-500上取得了94.0的pass@1精度,創下了7B模型的記錄。千問的基座,經過DeepSeek的蒸餾訓練,再經過上海AI Lab的強化學習訓練,達到了中國原創新高度。
對于32B模型,Oreal-32B在MATH-500上也達到了95.0的分數,超越了同級別的DeepSeek-r1-Distill-Qwen-32B,實現32B模型的新SOTA。
One More Thing
最后,研究團隊還對比了不同基座模型下的性能表現,發現不同性能起點的策略模型RL后性能上限是不同的,起點模型越強,RL后的性能越好。
并且,盡管在多個基座模型上,大部分benchmark性能都會在RL后有所提升,偶爾也會出現持平(OREAL-32B在AIME2025-I)或者性能下降(相比于DSR1-Distill-Qwen-7B在AIME2024)。
研究認為,這些情況的出現可能與訓練語料的質量、難度和數量等方面準備的不夠充分有關,這也給未來的研究留下了空間。

因此,除了強大的RL算法,團隊還提出兩個關鍵因素對于RL在數學推理任務中的成功至關重要:
強大的起點模型是RL可以有效激發模型潛在能力的前提。
在RL階段使用的數據也必須在質量、難度、數量和多樣性方面都得到充分保證。高質量的數據集能夠讓模型通過面對廣泛的挑戰和學習機會,充分發揮其潛力。
模型數據全面開源,助力強化學習研究
研究團隊同時也注意到,盡管DeepSeek-R1的出現引發了社區對于大語言模型強化學習的學習和研究熱情,大家使用的訓練起點模型、訓練數據、訓練算法和超參細節都不盡相同,影響了算法和模型性能的清晰比較。
因此,研究團隊將整個RL訓練過程中用到的訓練數據、起點模型和RL后模型都進行了全面開源,訓練代碼也將開源到XTuner。
歡迎下載體驗:
項目鏈接:
https://github.com/InternLM/OREAL
論文地址:
https://arxiv.org/abs/2502.06781
RL 訓練數據鏈接:
https://huggingface.co/datasets/internlm/OREAL-RL-Prompts
系列模型地址:
https://huggingface.co/collections/internlm/oreal-67aaccf5a8192c1ba3cff018





























