













編輯 | 言征、伊風(fēng)
相信連DeepSeek的創(chuàng)始人梁文鋒自己都沒有想到,春節(jié)前的一次發(fā)布,讓全球AI圈都陷入了“冰與火”之中,一方面大洋兩岸都在驚嘆:一家出自浙江的非“六小龍”公司能歐這么短時(shí)間就能用開源的方式,推出性能堪比甚至趕超OpenAI o1的模型,成本卻更是出奇的低。
一時(shí)間,全球AI玩家紛紛快速推出自己的“DeepSeek-R1”復(fù)刻版。抱抱臉、伯克利、港科大很快就用實(shí)力證明了:DeepSeek R1 是名副其實(shí)的國產(chǎn)推理模型的巨大勝利!

不過甚至有傳言說大洋彼岸的Meta都被R1打了個(gè)措手不及,內(nèi)部都在“恨鐵不成鋼”:為什么Llama3被超越了?
甚至受R1爆火影響,日本半導(dǎo)體市場的股市行情也迎來了大跌:軟銀集團(tuán)股價(jià)一度下跌5.4%,創(chuàng)下11月1日以來的最大跌幅;東京電子和Disco均跌超3%。

當(dāng)然,不止國外的半導(dǎo)體廠商,國內(nèi)的寒武紀(jì)也迎來了一波暴跌,10.7%。

DeepSeek的爆火,確實(shí)與眾不同
這次火得有點(diǎn)不同,sora也火,但沒有實(shí)際推出。而DeepSeek真正做到了大洋兩岸都開花。
從OpenAI奧特曼對(duì)DeepSeek的“陰陽”開始,硅谷對(duì)DeepSeek的討論和警惕就正式拉開了序幕。

Scale AI創(chuàng)始人Alexandr Wang提到,他們發(fā)布了“人類最后一次考試”,這是一個(gè)評(píng)估或基準(zhǔn)測試人工智能模型的新方法,我們通過邀請(qǐng)數(shù)學(xué)、生物學(xué)和化學(xué)教授提供他們能夠想象到的最難的問題來制定這些測試。Deep Sea,作為領(lǐng)先的中國人工智能實(shí)驗(yàn)室,其模型實(shí)際上在性能上與美國最好的模型相當(dāng),甚至更勝一籌。
值得一提的是,Alexandr Wang不相信DeepSeek R1是低端GPU創(chuàng)造出來的“奇跡”,他公開表示:“DeepSeek大約有5萬張H100計(jì)算卡,他們顯然不能談?wù)撨@件事,因?yàn)檫@違反了美國實(shí)施的出口管制。我認(rèn)為這是真的,我認(rèn)為他們的籌碼比其他人預(yù)期的要多。他們將受到芯片控制和出口管制的限制。”
微軟CEO薩蒂亞·納德拉也公開表示,“他們(DeepSeek)切實(shí)有效地開發(fā)出了一款開源模型,在推理計(jì)算方面表現(xiàn)出色,且超級(jí)計(jì)算效率極高。”納德拉還強(qiáng)調(diào),“我們必須非常、非常認(rèn)真地對(duì)待中國的這些進(jìn)展”。
甚至,連OpenAI安全研究員也來關(guān)心了一把DeepSeek的AI安全問題:DeepSeek有任何安全方面的研究人員嗎?梁文鋒(DeepSeek CEO)怎么看待AI安全?

同時(shí),DeepSeek的火爆遠(yuǎn)不止于AI圈大佬們的公開討論,其應(yīng)用版驚人的下載量驗(yàn)證了DeepSeek的“出圈”程度。1 月 27 日,DeepSeek 登頂中國區(qū)應(yīng)用商店免費(fèi)應(yīng)用排行榜,同時(shí)也在美區(qū)蘋果 App Store 免費(fèi)榜升至第一位。
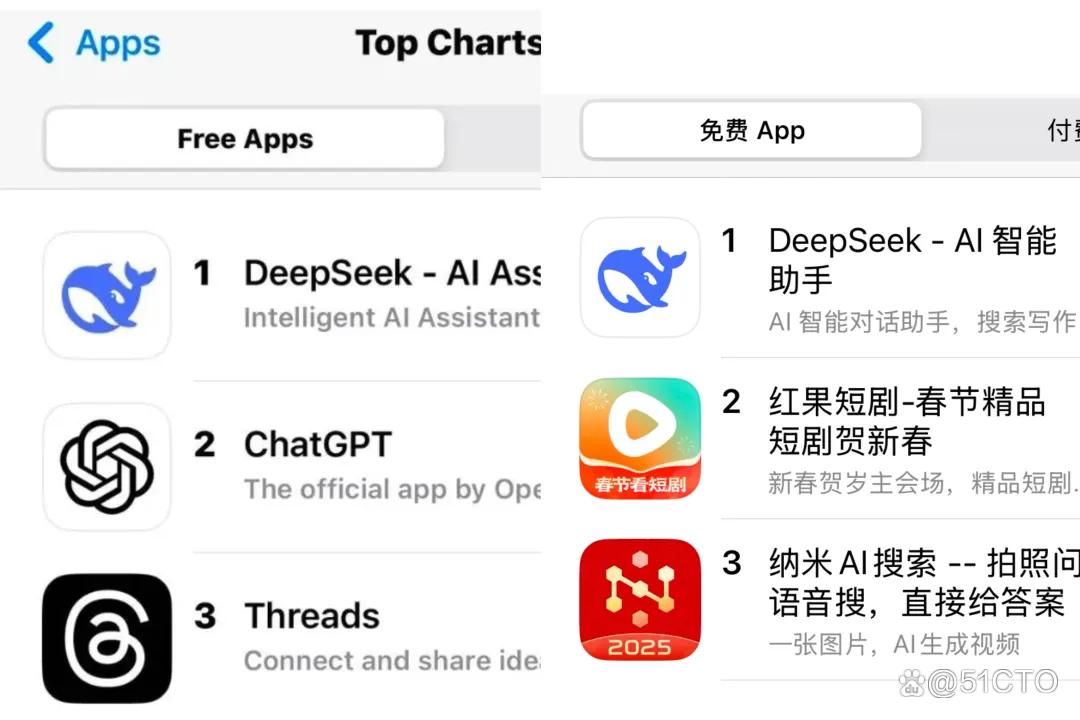
上圖:左美區(qū)蘋果 App Store免費(fèi)榜,右為中國區(qū)
討論DeepSeek強(qiáng)在哪里,不如來探討一下為什么火
為什么火?
一個(gè)是證明了一眾小模型(低至1.5B)也可以實(shí)現(xiàn)深度推理模型,這也就意味著沒有顯卡儲(chǔ)備的普通的學(xué)生也可以在自己電腦上做實(shí)驗(yàn)。

一臺(tái)Mac就可以跑出o1mini的模型,試問哪個(gè)理工科的學(xué)生不會(huì)手癢嘗試下?只需要從抱抱臉或Github上下載下模型,就可以在自己電腦上運(yùn)行、微調(diào)和訓(xùn)練了。


其次,對(duì)于企業(yè)而言,價(jià)格低到幾乎可以忽略不計(jì)的使用成本,完全可以打消投入產(chǎn)出比的顧慮。
DeepSeek 同步上線的 R1 模型的 API,價(jià)格一直都非常良心,只有 o1 模型的 5%。
輸入百萬tokens緩存命中只需要1塊錢,不命中需要4塊錢。而輸出方面,百萬tokens只需要16塊錢,對(duì)比o1模型的價(jià)格——百萬緩存命中輸入Token $7.50,百萬輸入緩存不命中Tokens $15.00,每百萬輸出Tokens $60.00,可以說,企業(yè)的成本將是后者的50/1。

奧特曼甚至都似乎被R1推出帶來的價(jià)格風(fēng)暴震驚到了,表示之后會(huì)“大甩賣”:ChatGPT Plus會(huì)員可以每天獲得100條o3-mini查詢,下一個(gè)智能體Plus會(huì)員首發(fā)就能用。
第三,重要的是,推理模型的開源,代碼流程公開透明,使得不管是普通開發(fā)者還是企業(yè)部署,都有了靈活可定制自身推理模型的潛力。
第四,當(dāng)然,不得不提。DeepSeek-R1的爆火,已經(jīng)沖擊了全球的算力的邏輯。分析師Holger Zschaepitz表示:“中國的DeepSeek可能代表了對(duì)美國股市最大的威脅,因?yàn)樵摴舅坪跻詷O低的價(jià)格建立了一個(gè)突破性的人工智能模型,而無需依賴最先進(jìn)的芯片,這引發(fā)了對(duì)數(shù)百億美元資本支出是否有用的質(zhì)疑,這些資金正被投入到這個(gè)行業(yè)中。”
Sumitomo Life Insurance Co.的平衡組合投資總經(jīng)理Masayuki Murata表示,DeepSeek可能引發(fā)科技股下跌:
“大型科技公司在AI上投入了大量資金,幾乎達(dá)到了一國政府預(yù)算的規(guī)模,但一直存在一個(gè)問題,即產(chǎn)生的回報(bào)能否與其投資規(guī)模相匹配。“
據(jù)報(bào)道,DeepSeek實(shí)驗(yàn)室只花了560萬美元來建造DeepSeek V3。相比之下,OpenAI每年花費(fèi)50億美元,而谷歌預(yù)計(jì)2024年的資本支出將飆升至超過500億美元。還有微軟,僅投資OpenAI就花費(fèi)了超過130億美元。
然而,這也并不意味著高端芯片從此失去市場。Perplexity AI CEO Aravind Srinivas在采訪中說:我想從快速行動(dòng)的角度出發(fā),你肯定想用高端芯片,而且你會(huì)想比你的競爭對(duì)手更快地推進(jìn)。我認(rèn)為最優(yōu)秀的人才仍然想加入那個(gè)最先實(shí)現(xiàn)這一目標(biāo)的團(tuán)隊(duì)。你知道,總會(huì)有人覺得誰做到了這件事,誰是真正的先驅(qū),誰是跟隨者。
當(dāng)然,即便算力高端市場大概率不會(huì)變天,但在大模型撞墻的質(zhì)疑聲不斷的語境中,為什么不學(xué)習(xí)DeepSeek,從工程的角度使用更少的算力達(dá)到同樣的效果呢?
所以總結(jié)來看,R1的爆火在于解決了以o1為代表的大模型現(xiàn)存的幾大問題:太貴、部署門檻高、不透明、靈活性差(不可定制)。R1 解決了所有問題。
企業(yè)角度看,公司可以購買自己的GPU,運(yùn)行這些模型,而不必?fù)?dān)心額外成本或緩慢/無響應(yīng)的 OpenAI 服務(wù)器”;個(gè)人愛好者或開發(fā)者可以快速通過開源的模型或工具在自己的電腦上微調(diào)自己的模型、甚至很快開發(fā)一個(gè)“智能體”出來硬剛OpenAI的“Operator”。這已經(jīng)是事實(shí)。
前兩天,Twitter上就有不少極客曬出了自己的“Operator”:無需向OpenAI支付 200 美元,就可以自己用100%開源的工具創(chuàng)建一個(gè)使用 Web 瀏覽器的代理,而無需手動(dòng)編寫一行代碼,只需要結(jié)合 DeepSeek R1 和“BrowserUse”。


投資市場的角度看,DeepSeek-R1拉低了大模型應(yīng)用的門檻,所以大模型公司降低硬成本的時(shí)機(jī)或許已經(jīng)到來,單純看誰存卡多的邏輯已經(jīng)受到了嚴(yán)重挑戰(zhàn),甚至有人開始懷疑未來大家需要那么多英偉達(dá)的GPU嗎?
不過,很多AI從業(yè)者認(rèn)為在短期波動(dòng)后,從長遠(yuǎn)看對(duì)英偉達(dá)依舊是利好的,隨著AI“盤子”的擴(kuò)大,需求總體將是穩(wěn)步提升的趨勢。

不管是從企業(yè)還是個(gè)人還是創(chuàng)投層面看,DeepSeek都是一個(gè)游戲規(guī)則改變者。
本質(zhì):一場開源的巨大勝利
說到底這次火,根由上還是因?yàn)榇蠹覍?duì)于開源追上閉源的速度相當(dāng)迅猛,這種迅猛更是疊加了:低技術(shù)門檻和幾乎忽略不計(jì)的費(fèi)用兩大標(biāo)簽。
昨日,AI教父楊立昆說,那些解讀“中國在人工智能方面正在超越美國”的人錯(cuò)了。
其實(shí)是“開源模型正在超越專有模型”。
他表示,DeepSeek從開放研究和開源(例如 Meta的 PyTorch 和 Llama)中獲利他們提出了新的想法,并將其建立在其他人的工作之上。因?yàn)樗麄兊墓ぷ魇且寻l(fā)布的和開源的,所以每個(gè)人都可以從中受益。

外媒CNBC專題報(bào)告《中國的新AI模型DeepSeek如何威脅美國領(lǐng)先地位》,給出了一個(gè)相同的結(jié)論:(DeepSeek的成功)這可能意味著全球AI領(lǐng)域的主流模式將是開源。因?yàn)楦鲊徒M織逐漸認(rèn)識(shí)到,協(xié)作和去中心化可以比封閉的專有生態(tài)系統(tǒng)更快速、更高效地推動(dòng)創(chuàng)新。中國提供的一個(gè)更便宜、更高效、廣泛采用的開源模型,可能會(huì)導(dǎo)致動(dòng)態(tài)發(fā)生重大變化。
說到底這次火,根由上還是因?yàn)榇蠹覍?duì)于開源追上閉源的速度,相當(dāng)迅猛,這種迅猛附加了:低技術(shù)門檻和幾乎忽略不計(jì)的費(fèi)用兩大標(biāo)簽。
但這并不意味著,開源就是“無國界”的。
即使楊立昆出來給開源陣營拉大旗,也掩蓋不了Meta的工程師們正在焦頭爛額地分析DeepSeek的AI恐慌。根據(jù)一線員工的匿名爆料,管理層正在擔(dān)心如何證明龐大的AI組織的成本是合理的,因?yàn)镸eta的生成式AI部門里的每位“領(lǐng)導(dǎo)”的薪資都超過了DeepSeek-V3的訓(xùn)練成本。
Perplexity AI CEO Aravind Srinivas 更直說 “這樣(開源領(lǐng)先)更危險(xiǎn)”。他表示:“因?yàn)檫@樣他們(DeepSeek)就能掌控市場份額和生態(tài)系統(tǒng)。開源也總有一天可能不再是開源,對(duì)嗎?目前這些許可證很有用,但它們可以隨著時(shí)間改變?cè)S可。重要的是,我們得有美國人在這里建設(shè),所以Meta是如此重要。
CNBC總結(jié)稱,采用中國的開源模型規(guī)模化使用,可能會(huì)削弱美國的領(lǐng)導(dǎo)地位,同時(shí)讓中國更加深入地融入全球科技基礎(chǔ)設(shè)施。
在復(fù)雜的地緣因素之下,競爭對(duì)手們的集體恐慌再次驗(yàn)證了一個(gè)事實(shí):中國是一股重要的AI力量。
Perplexity AI CEO Aravind Srinivas說,很多人(錯(cuò)誤地)認(rèn)為中國只是模仿者,所以如果我們停止在美國寫研究論文,如果我們停止描述我們基礎(chǔ)設(shè)施或架構(gòu)的細(xì)節(jié),停止開源,他們就無法趕上。但現(xiàn)實(shí)情況是,DeepSeek V3中的一些細(xì)節(jié)非常好,我不會(huì)很驚訝如果Meta看過它并將一些內(nèi)容融入Llama 4中。我不會(huì)說這是抄襲,這完全是分享科學(xué)、工程技術(shù)。但關(guān)鍵是,情況在變化,中國不僅僅是模仿者,他們也在創(chuàng)新。
寫在最后:了不起的國產(chǎn)創(chuàng)新
現(xiàn)代管理學(xué)之父德魯克對(duì)于創(chuàng)新有個(gè)很容易理解的解釋:一是讓昂貴的東西變得便宜,老百姓能用;二是讓高門檻東西變得低門檻,普通人可用。
Deepseek R1的推出和開源,很顯然,這兩點(diǎn)都做到了。
參考鏈接:
1.https://zhuanlan.zhihu.com/p/709867165。
2.https://www.zhihu.com/question/10152040622/answer/84383440957。
3.https://www.youtube.com/watch?v=WEBiebbeNCA。




























