













本想去谷歌撈一筆就跑,卻成了改變AI歷史的人|Transformer作者對話Jeff Dean
谷歌兩位大佬回應一切:從PageRank到AGI的25年。
現(xiàn)任首席科學家Jeff Dean、出走又回歸的Transformer作者Noam Shazeer,與知名播客主持人Dwarkesh Patel展開對談。
視頻剛發(fā)幾個小時,就有20萬+網(wǎng)友在線圍觀。
兩人都是谷歌遠古員工,經(jīng)歷了從MapReduce到Transformer、MoE,他們發(fā)明了很多改變整個互聯(lián)網(wǎng)和AI的關鍵技術。
Noam Shazeer卻談到當初入職谷歌只是為了撈一筆就跑,沒想到成了改變世界的那個人。
在兩個多小時的談話中,他們透露了AI算力的現(xiàn)狀:
- 單個數(shù)據(jù)中心已經(jīng)不夠了,Gemini已經(jīng)在跨多個大城市的數(shù)據(jù)中心異步訓練。
也對當下最流行的技術趨勢做了探討:
- 推理算力Scaling還有很大空間,因為與AI對話比讀書仍然便宜100倍
- 未來的模型架構會比MoE更靈活,允許不同的團隊獨立開發(fā)不同的部分
……
網(wǎng)友們也在邊聽邊po發(fā)現(xiàn)的亮點:
比如在內(nèi)存中存儲一個巨大的MoE模型的設想。
以及“代碼中的bug可能有時會對AI模型有正面影響”。
隨著規(guī)模的擴大,某些bug正是讓研究人員發(fā)現(xiàn)新突破的契機。
推理算力Scaling的未來
很多人覺得AI算力很貴,Jeff Dean不這么認為,他用讀書和與AI討論一本書來對比:
當今最先進的語言模型每次運算的成本約為10-18美元,這意味著一美元可以處理一百萬個token。
相比之下,買一本平裝書的成本大約相當于每1美元買1萬個token(單詞數(shù)換算成token)。
那么,與大模型對話就比讀書便宜約100倍。
這種成本優(yōu)勢,為通過增加推理算力來提升AI的智能提供了空間。
從基礎設施角度來看,推理時間計算的重要性增加可能會影響數(shù)據(jù)中心規(guī)劃。
可能需要專門為推理任務定制硬件,就像谷歌初代TPU一樣,它最初是為推理的目的設計,后來才被改造為也支持訓練。
對推理的依賴增加可能意味著不同的數(shù)據(jù)中心不需要持續(xù)通信,可能導致更分布式、異步的計算。
在訓練層面,Gemini 1.5已經(jīng)開始使用多個大城市的計算資源,通過高速的網(wǎng)絡連接將不同數(shù)據(jù)中心中的計算結果同步,成功實現(xiàn)了超大規(guī)模的訓練。
對于大模型來說,訓練每一步的時間可能是幾秒鐘,因此即使網(wǎng)絡延遲有50毫秒,也不會對訓練產(chǎn)生顯著影響。

到了推理層面,還需要考慮任務是否對延遲敏感。如果用戶在等待即時響應,系統(tǒng)需要針對低延遲性能進行優(yōu)化。然而,也有一些非緊急的推理任務,比如運行復雜的上下文分析,可以承受更長的處理時間。
更靈活和高效的系統(tǒng)可能能夠異步處理多個任務,在提高整體性能的同時最大限度地減少用戶等待時間。
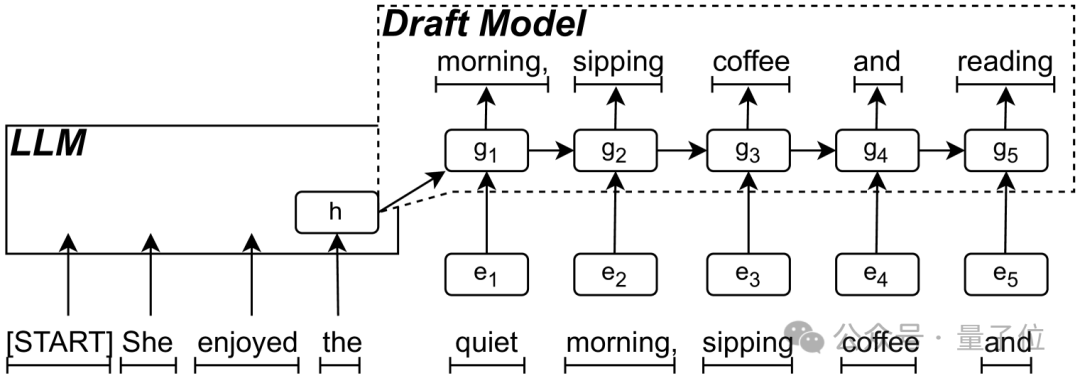
此外,算法效率的提升,如使用較小的草稿(Draft)模型,可以幫助緩解推理過程中的瓶頸。在這種方法中,較小的模型生成潛在的token,然后傳遞給較大的模型進行驗證。這種并行化可以顯著加快推理過程,減少一次一個token的限制。
Noam Shazeer補充,在進行異步訓練時,每個模型副本會獨立進行計算,并將梯度更新發(fā)送到中央系統(tǒng)進行異步套用。雖然這種方式會使得模型參數(shù)略有波動,理論上會有影響,但實踐證明它是成功的。
相比之下,使用同步訓練模式能提供更加穩(wěn)定和可重復的結果,這是許多研究者更加青睞的模式。
在談到如何保證訓練的可重復性時,Jeff Dean提到一種方法是記錄操作日志,尤其是梯度更新和數(shù)據(jù)批次的同步記錄。通過回放這些操作日志,即使在異步訓練的情況下,也能夠確保結果的可重復性。這種方法可以讓調(diào)試變得更加可控,避免因為環(huán)境中的其他因素導致結果不一致。
Bug也有好處
順著這個話題,Noam Shazeer提出一個有意思的觀點:
訓練模型時可能會遇到各種各樣的bug,但由于噪音的容忍度,模型可能會自我調(diào)整,從而產(chǎn)生未知的效果。
甚至有的bug會產(chǎn)生正面影響,隨著規(guī)模的擴大,因為某些bug在實驗中可能會表現(xiàn)出異常,讓研究人員發(fā)現(xiàn)新的改進機會。

當被問及如何在實際工作中調(diào)試bug時,Noam Shazeer介紹他們通常會在小規(guī)模下進行大量實驗,這樣可以快速驗證不同的假設。在小規(guī)模實驗中,代碼庫保持簡單,實驗周期在一到兩個小時而不是幾周,研究人員可以快速獲得反饋并做出調(diào)整。
Jeff Dean補充說,很多實驗的初期結果可能并不理想,因此一些“看似不成功”的實驗可能在后期仍然能夠為研究提供重要的見解。
與此同時,研究人員面臨著代碼復雜性的問題:雖然不斷疊加新的改進和創(chuàng)新是必要的,但代碼的復雜性也會帶來性能和維護上的挑戰(zhàn),需要在系統(tǒng)的整潔性和創(chuàng)新的推進之間找到平衡。
未來模型的有機結構
他們認為,AI模型正在經(jīng)歷從單一結構向模塊化架構的重要轉變。
如Gemini 1.5Pro等模型已經(jīng)采用了專家混合(Mixture of Expert)架構,允許模型根據(jù)不同任務激活不同的組件。例如在處理數(shù)學問題時會激活擅長數(shù)學的部分,而在處理圖像時則會激活專門處理圖像的模塊。
然而,目前的模型結構仍然較為僵化,各個專家模塊大小相同,且缺乏足夠的靈活性。
Jeff Dean提出了一個更具前瞻性的設想:未來的模型應該采用更有機的結構,允許不同的團隊獨立開發(fā)或改進模型的不同部分。
例如,一個專注于東南亞語言的團隊可以專門改進該領域的模塊,而另一個團隊則可以專注于提升代碼理解能力。
這種模塊化方法不僅能提高開發(fā)效率,還能讓全球各地的團隊都能為模型的進步做出貢獻。
在技術實現(xiàn)方面,模型可以通過蒸餾(Distillation)技術來不斷優(yōu)化各個模塊。這個過程包括將大型高性能模塊蒸餾為小型高效版本,然后在此基礎上繼續(xù)學習新知識。
路由器可以根據(jù)任務的復雜程度,選擇調(diào)用合適規(guī)模的模塊版本,從而在性能和效率之間取得平衡,這正是谷歌Pathway架構的初衷。
這種新型架構對基礎設施提出了更高要求。它需要強大的TPU集群和充足的高帶寬內(nèi)存(HBM)支持。盡管每個調(diào)用可能只使用模型的一小部分參數(shù),但整個系統(tǒng)仍需要將完整模型保持在內(nèi)存中,以服務于并行的不同請求。
現(xiàn)在的模型能將一個任務分解成10個子任務并有80%的成功率,未來的模型能夠將一個任務分解成100或1000個子任務,成功率達到90%甚至更高。
“Holy Shit時刻”:準確識別貓
回過頭看,2007年對于大模型(LLMs)來說算得上一個重要時刻。
當時谷歌使用2萬億個tokens訓練了一個N-gram模型用于機器翻譯。
但是,由于依賴磁盤存儲N-gram數(shù)據(jù),導致每次查詢需大量磁盤I/O(如10萬次搜索/單詞),延遲非常高,翻譯一個句子就要12小時。
于是后來他們想到了內(nèi)存壓縮、分布式架構以及批處理API優(yōu)化等多種應對舉措。
- 內(nèi)存壓縮:將N-gram數(shù)據(jù)完全加載到內(nèi)存,避免磁盤I/O;
- 分布式架構:將數(shù)據(jù)分片存儲到多臺機器(如200臺),實現(xiàn)并行查詢;
- 批處理API優(yōu)化:減少單次請求開銷,提升吞吐量。
過程中,計算能力開始遵循摩爾定律在之后逐漸呈現(xiàn)爆發(fā)式增長。
從2008年末開始,多虧了摩爾定律,神經(jīng)網(wǎng)絡真正開始起作用了。
那么,有沒有哪一個時刻屬于“Holy shit”呢?(自己都不敢相信某項研究真的起作用了)
不出意外,Jeff談到了在谷歌早期團隊中,他們讓模型從油管視頻幀中自動學習高級特征(如識別貓、行人),通過分布式訓練(2000臺機器,16000核)實現(xiàn)了大規(guī)模無監(jiān)督學習。
而在無監(jiān)督預訓練后,模型在監(jiān)督任務(ImageNet)中性能提升了60%,證明了規(guī)模化訓練和無監(jiān)督學習的潛力。

接下來,當被問及如今谷歌是否仍只是一家信息檢索公司的問題,Jeff用了一大段話表達了一個觀點:
AI履行了谷歌的原始任務
簡單說,AI不僅能檢索信息,還能理解和生成復雜內(nèi)容,而且未來想象力空間巨大。
至于谷歌未來去向何方,“我不知道”。
不過可以期待一下,未來將谷歌和一些開源源代碼整合到每個開發(fā)者的上下文中。
換句話說,通過讓模型處理更多tokens,在搜索中搜索,來進一步增強模型能力和實用性。
當然,這一想法已經(jīng)在谷歌內(nèi)部開始了實驗。
實際上,我們已經(jīng)在內(nèi)部代碼庫上為內(nèi)部開發(fā)人員進行了關于Gemini模型的進一步培訓。
更確切的說法是,谷歌內(nèi)部已經(jīng)達成25%代碼由AI完成的目標。
在谷歌最快樂的時光
有意思的是,這二位還在對話中透露了更多與谷歌相關的有趣經(jīng)歷。
對1999年的Noam來說,本來沒打算去谷歌這樣的大公司,因為憑直覺認為去了也可能無用武之地,但后來當他看到谷歌制作的每日搜索量指數(shù)圖表后,立馬轉變了想法:
這些人一定會成功,看起來他們還有很多好問題需要解決
于是帶著自己的“小心思”就去了(主動投了簡歷):
掙一筆錢,然后另外開開心心去搞自己感興趣的AI研究

而加入谷歌后,他就此結識了導師Jeff(新員工都會有一個導師),后來兩人在多個項目中有過合作。
談到這里,Jeff也插播了一條他對谷歌的認同點:
喜歡谷歌對RM愿景(響應式和多模態(tài),Responsive and Multimodal)的廣泛授權,即使是一個方向,也能做很多小項目。
而這也同樣為Noam提供了自由空間,以至于當初打算“干一票就跑”的人長期留了下來。
與此同時,當話題轉向當事人Jeff時,他的一篇關于平行反向傳播的本科論文也被再次提及。
這篇論文只有8頁,卻成為1990年的最優(yōu)等本科論文,被明尼蘇達大學圖書館保存至今。
其中,Jeff探討了兩種基于反向傳播來平行訓練神經(jīng)網(wǎng)絡的方法。
- 模式分割法(pattern-partitioned approach):將整個神經(jīng)網(wǎng)絡表示在每一個處理器上,把各種輸入模式劃分到可用的處理器上;
- 網(wǎng)絡分割法(network-partitioned approach)流水線法(pipelined approach):將神經(jīng)網(wǎng)絡的神經(jīng)元分布到可用的處理器上,所有處理器構成一個相互通信的環(huán)。然后,特征通過這個pipeline傳遞的過程中,由每個處理器上的神經(jīng)元來處理。
他還構建了不同大小的神經(jīng)網(wǎng)絡,用幾種不同的輸入數(shù)據(jù),對這兩種方法進行了測試。
結果表明,對于模式分割法,網(wǎng)絡大、輸入模式多的情況下加速效果比較好。
當然最值得關注的還是,我們能從這篇論文中看到1990年的“大”神經(jīng)網(wǎng)絡是什么樣:
3層、每層分別10、21、10個神經(jīng)元的神經(jīng)網(wǎng)絡,就算很大了。

論文地址:https://drive.google.com/file/d/1I1fs4sczbCaACzA9XwxR3DiuXVtqmejL/view
Jeff還回憶道,自己測試用的處理器,最多達到了32個。
(這時的他應該還想不到,12年后他會和吳恩達、Quoc Le等人一起,用16000個CPU核心,從海量數(shù)據(jù)中找出貓。)

不過Jeff坦言,如果要讓這些研究成果真正發(fā)揮作用,“我們需要大約100萬倍的計算能力”。
后來,他們又談到了AI的潛在風險,尤其是當AI變得極其強大時可能出現(xiàn)的反饋循環(huán)問題。
換句話說,AI通過編寫代碼或改進自身算法,可能進入不可控的加速改進循環(huán)(即“智能爆炸”)。
這將導致AI迅速超越人類控制,甚至產(chǎn)生惡意版本。就像主持人打的比方,有100萬個像Jeff這樣的頂尖程序員,最終變成“100萬個邪惡的Jeff”。
(網(wǎng)友):新的噩夢解鎖了哈哈哈!
最后,談及在谷歌最快樂的時光,二人也分別陷入回憶。
對Jeff來說,在谷歌早期四五年的日子里,最快樂的莫過于見證谷歌搜索流量的爆炸式增長。
建造一個如今20億人都在使用的東西,這非常不可思議。
至于最近,則很開心和Gemini團隊構建一些,即使在5年前人們都不敢相信的東西,并且可以預見模型的影響力還將擴大。
而Noam也表達了類似經(jīng)歷和使命,甚至喜滋滋cue到了谷歌的“微型廚房區(qū)域”。
據(jù)介紹,這是一個大約有50張桌子的特別空間,提供咖啡小吃,人們可以在這里自由自在閑聊,碰撞想法。

一說到這個,連Jeff也手舞足蹈了(doge):

Okk,以上為兩位大佬分享的主要內(nèi)容。
























