













DeepSeek 系列模型詳解之 DeepSeek LLM
DeepSeek LLM發布于2024年1月,收集了2萬億個詞元用于預訓練,在模型層面沿用了LLaMA的架構,并將余弦退火學習率調度器替換為多階段學習率調度器,便于持續訓練。并從多種來源收集了超過100萬個實例進行監督微調(SFT)。此外,利用直接偏好優化(DPO)技術進一步提升模型的對話能力。

一、預訓練
1. 數據
為了全面提升數據集的豐富性和多樣性,將數據構建方法分為三個關鍵階段:去重、過濾和混洗。
(1) 去重階段
采用激進的去重策略,擴大去重范圍。分析表明,對整個Common Crawl語料庫進行去重比單獨處理單個數據包更能有效去除重復實例。如表展示了在跨91個數據包進行去重時,消除的重復文檔數量是單個數據包方法的4倍。

各種Common Crawl數據包的去重比率
(2) 過濾階段
在過濾階段,專注于制定用于文檔質量評估的穩健標準。
(3) 混洗階段
調整策略以解決數據不平衡問題,側重于增加代表性不足領域的數據。
DeepSeek LLM基于分詞器庫(Huggingface)實現了字節級字節對編碼(BBPE)算法。與GPT-2類似,采用預分詞處理,以防止來自不同字符類別的(如換行符、標點符號和中日韓(CJK)字符)合并。
此外,將數字拆分為單個數字,且將詞匯表中的常規標記數量設定為100000。該分詞器在一個約24GB的多語言語料庫上進行訓練,并在最終詞匯表中增加了15個特殊詞元標記,使得詞表總大小達到100015個。同時,為確保訓練期間的計算效率并為未來可能需要的額外特殊標記預留空間,將模型的詞匯表大小配置為102400。
2. 架構
(1) 微觀設計
DeepSeek LLM微觀設計主要沿用了LLama的設計思路,具體包括:
- 歸一化結構:采用Pre-Norm結構,使用RMSNorm歸一化函數。
- 激活函數:在前饋網絡(FFN)中使用SwiGLU激活函數,中間層維度為。
- 位置編碼:使用旋轉嵌入(RoPE)進行位置編碼。
- 注意力機制:為優化推理成本,67B模型采用分組查詢注意力機制(Grouped-Query Attention,GQA),而非傳統的多頭注意力(MHA)。
(2) 宏觀設計
在宏觀設計方面,DeepSeek LLM與大多數現有模型有所不同:
- 層數調整:70億參數的DeepSeek LLM是一個30 層的網絡,670億參數的DeepSeek LLM有95層。這種層數調整不僅保持了與其他開源模型的參數一致性,還便于模型的流水線劃分,從而優化訓練和推理過程。
- 參數擴展策略:選擇了增加網絡深度而不是拓寬FFN層的中間寬度來擴展67B模型的參數,以追求更好的性能。
詳細的網絡規格如表所示。

DeepSeek LLM系列模型的詳細規格
3. 超參數
DeepSeek LLM的初始化標準差為0.006,并使用AdamW優化器進行訓練,具體超參數設置如下:
- 動量參數:
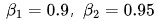
- 權重衰減:weight_decay = 0.1
- 梯度裁剪:訓練階段的梯度裁剪值設為1.0
在預訓練過程中,采用了多階段學習率調度器,而非傳統的余弦退火調度器。具體的學習率變化策略如下:
- 預熱階段:學習率在前2000個warmup steps后線性增加到最大值。
- 第一階段:處理完80%的訓練詞元后,學習率降低到最大值的31.6%。
- 第二階段:處理完90%的訓練詞元后,學習率進一步降低到最大值的10%。
通過這種方式,多階段學習率調度器能夠在保持最終性能與余弦調度器一致的同時,提供更方便的持續訓練支持。如圖(a)所示,盡管訓練損失曲線的趨勢有所不同,但最終性能基本一致。
調整不同階段的比例可以略微提升性能,如圖(b)所示。然而,為了平衡持續訓練中的復用比例和模型性能,選擇了80%、10%和10%的三階段分布。
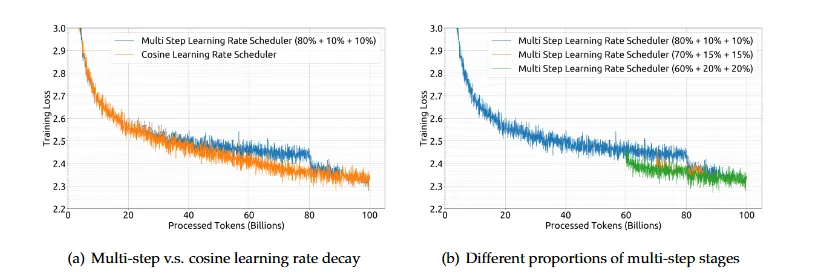
不同學習率調度器的訓練損失曲線
此外,batch size和學習率會隨模型規模的不同而變化。具體可參見DeepSeek LLM系列模型的詳細規格表。
4. 基本框架
DeepSeek LLM使用的是高效且輕量級的訓練框架HAI-LLM。該框架集成了數據并行、張量并行、序列并行和1F1B流水線并行技術。此外,還利用閃存注意力機制(Flash Attention)技術來提高硬件利用率。采用ZeRO-1方法在數據并行節點之間劃分優化器狀態。
(1) 計算與通信優化
為了最小化額外的等待開銷,采取了以下措施:
- 計算與通信重疊:包括最后一個微批次的反向傳播過程和ZeRO-1中的reduce-scatter操作,以及序列并行中的矩陣乘法(GEMM)計算和all-gather/reduce-scatter操作。
- 層/運算符融合:通過融合LayerNorm、盡可能多的矩陣乘法運算和Adam更新,加速訓練過程。
- 精度優化:模型以bf16精度進行訓練,但梯度累積以fp32精度進行,以提高訓練穩定性。
- 交叉熵優化:采用in-place交叉熵計算,減少GPU內存消耗。具體來說,在交叉熵CUDA內核中動態地將bf16對數幾率(logits)轉換為fp32精度,并計算相應的bf16梯度,覆蓋對數幾率(logits)以存儲其梯度。
(2) 模型保存與恢復
模型權重和優化器狀態每5分鐘異步保存一次,這意味著即使在偶爾的硬件或網絡故障情況下,最多也只會丟失5分鐘的訓練進度。這些臨時模型檢查點會定期清理,以避免占用過多的存儲空間。并支持從不同的3D并行配置恢復訓練,以應對計算集群負載的動態變化。
(3) 模型評估
在生成任務中,使用vLLM進行評估;而在非生成任務中,采用連續批處理方法,以避免手動調整批處理大小和減少token填充,從而提高評估效率。
二、Scalling lows
關于縮放定律(Scalling lows)的最早研究是在大模型出現之前的。研究表明,通過增加計算預算(C)、模型規模(N)和數據規模(D),可以提升模型性能。當模型規模(N)由模型參數表示,數據規模(D)由詞元數量表示時,計算預算(C)可以近似為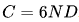 。
。
為了減少實驗成本和擬合難度,采用了Chinchilla中的IsoFLOP profile方法來擬合縮放曲線。為了更準確地表示模型規模,使用了新的模型表示法——非嵌入FLOPs/token-M,取代了之前使用的模型參數(N),并將計算預算公式從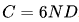 改為更精確的
改為更精確的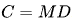 。實驗結果提供了關于最優模型/數據擴展分配策略和性能預測的見解,并準確預測了DeepSeek LLM 7B和67B模型的預期性能。
。實驗結果提供了關于最優模型/數據擴展分配策略和性能預測的見解,并準確預測了DeepSeek LLM 7B和67B模型的預期性能。
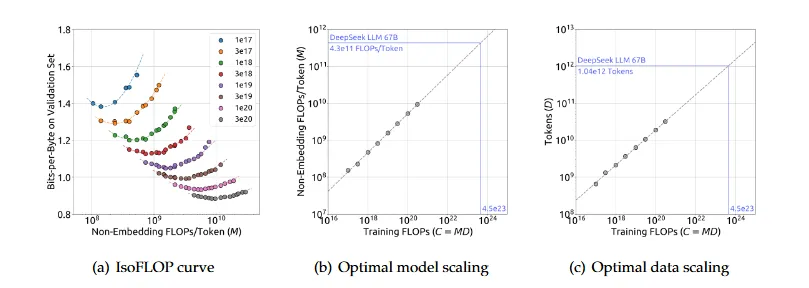
IsoFLOP曲線和最優模型/數據分配
該研究在縮放定律方面的貢獻和發現可以總結如下:
- 建立了超參數的縮放定律,為確定最優超參數提供了一個經驗框架。
- 采用非嵌入FLOPs (M) 表示模型規模,更準確的最優模型/數據擴展分配策略和更好的大模型泛化損失預測。
- 提出預訓練數據質量影響最優模型/數據擴展分配策略,數據質量越高,增加的計算預算應更多地分配給模型擴展。
- 證明了縮放定律的普遍適用性,并預測了未來更大規模模型的性能。
1. 超參數縮放定律
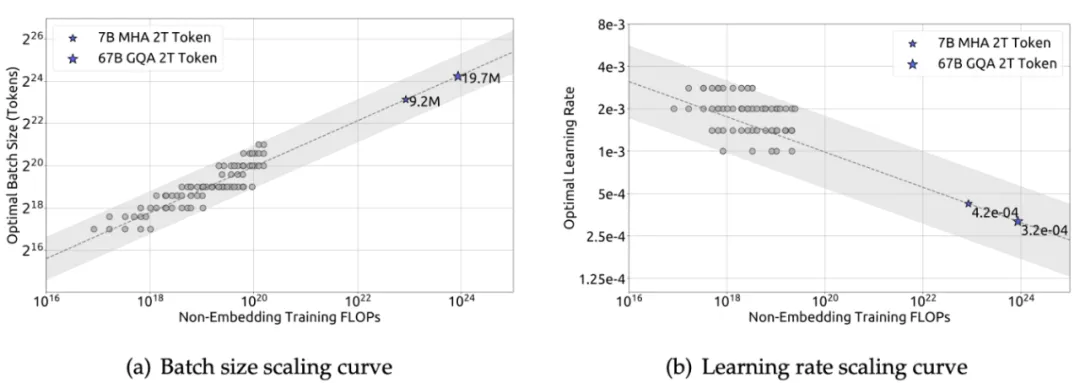
DeepSeek LLM 最初在計算預算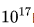 的小規模實驗中對批量大小和學習率進行了網格搜索,針對特定模型規模(每詞元1.77億次浮點運算)的實驗結果如下圖所示。結果顯示,在廣泛的批量大小和學習率選擇范圍內,泛化誤差保持穩定。這表明,可以在相對寬泛的參數空間內實現接近最優的性能。
的小規模實驗中對批量大小和學習率進行了網格搜索,針對特定模型規模(每詞元1.77億次浮點運算)的實驗結果如下圖所示。結果顯示,在廣泛的批量大小和學習率選擇范圍內,泛化誤差保持穩定。這表明,可以在相對寬泛的參數空間內實現接近最優的性能。

利用上述多步學習率調度器,通過復用第一階段的訓練成果,對多個具有不同批量大小、學習率以及計算預算(范圍從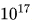 到
到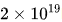 FLOPs的模型進行了有效訓練。考慮到參數空間中的冗余,將泛化誤差不超過最小值0.25%的模型視為近似最優超參數。
FLOPs的模型進行了有效訓練。考慮到參數空間中的冗余,將泛化誤差不超過最小值0.25%的模型視為近似最優超參數。
隨后,擬合了批量大小B和學習率 與計算預算C的關系。如下圖所示,隨著計算預算C的增加,最優批量大小B逐漸增加,而最優學習率
與計算預算C的關系。如下圖所示,隨著計算預算C的增加,最優批量大小B逐漸增加,而最優學習率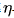 逐漸減小。這與模型擴量時對批量大小和學習率的直觀經驗設置相符。此外,所有近似最優超參數都落在一個較寬的區間內,表明在這個區間內選擇近似最優參數相對容易。
逐漸減小。這與模型擴量時對批量大小和學習率的直觀經驗設置相符。此外,所有近似最優超參數都落在一個較寬的區間內,表明在這個區間內選擇近似最優參數相對容易。
最終擬合出的批量大小和學習率公式如下:
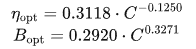
DeepSeek LLM 在一系列計算預算為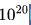 FLOPs的模型上驗證了這些公式,特定模型規模(每詞元2.94億次浮點運算)的驗證結果如上圖 (b) 所示。結果顯示,擬合參數集中在最優參數空間內。
FLOPs的模型上驗證了這些公式,特定模型規模(每詞元2.94億次浮點運算)的驗證結果如上圖 (b) 所示。結果顯示,擬合參數集中在最優參數空間內。
需要注意的是,目前的研究尚未考慮超出計算預算C的其他因素對最優超參數的影響。這與一些早期研究成果不一致,后者認為最優批量大小可以建模為僅與泛化誤差L相關。此外,在計算預算相同但模型/數據分配不同的模型中,最優參數空間存在細微差異。
2. 估算最優模型和數據規模
在推導出擬合近似最優超參數的公式后,開始擬合縮放曲線并分析最優模型/數據擴展分配策略。這一策略旨在找到分別滿足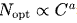 和
和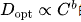 的模型擴展指數a和數據擴展指數b,其中數據規模D可以用數據集中的詞元數量來表示。
的模型擴展指數a和數據擴展指數b,其中數據規模D可以用數據集中的詞元數量來表示。
在早期的研究中,模型規模通常由模型參數表示,包括非嵌入參數 和完整參數
和完整參數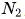 ,計算預算C與模型/數據規模之間的關系可以近似描述為
,計算預算C與模型/數據規模之間的關系可以近似描述為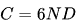 ,即可以用
,即可以用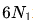 或
或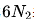 來近似模型規模。
來近似模型規模。
然而,由于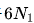 和
和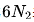 都沒有考慮注意力操作的計算開銷,并且
都沒有考慮注意力操作的計算開銷,并且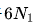
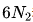 還包括了對模型容量貢獻較小的詞匯表計算,因此在某些設置下存在顯著的近似誤差。
還包括了對模型容量貢獻較小的詞匯表計算,因此在某些設置下存在顯著的近似誤差。
為了減少這些誤差,引入了一種新的模型規模表示法:非嵌入層每詞元浮點運算次數M, M包括了注意力操作的計算開銷,但不考慮詞表計算。使用M表示模型規模時,計算預算C可以簡單地表示為。 、
、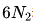 和
和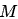 的具體差異如下:
的具體差異如下:
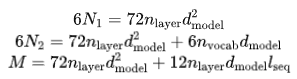
其中,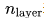 表示層數,
表示層數,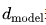 表示模型寬度,
表示模型寬度,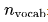 是詞表大小,
是詞表大小,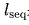 是序列長度。
是序列長度。
如下表所示,在不同規模的模型上評估了這三種表示法的差異。
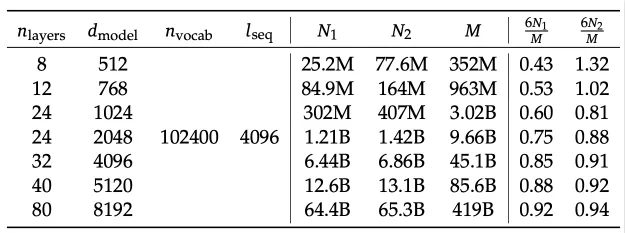
不同模型規模表示法的差異及非嵌入參數N1和完整參數N2相對于每詞元非嵌入M的差異
結果表明,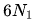 和
和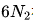 在不同規模的模型中都會高估或低估計算成本,這種差異在小規模模型中尤為明顯,最大可達50%。這種不準確性在擬合縮放曲線時會引入顯著的統計誤差。
在不同規模的模型中都會高估或低估計算成本,這種差異在小規模模型中尤為明顯,最大可達50%。這種不準確性在擬合縮放曲線時會引入顯著的統計誤差。
采用M表示模型規模后,目標可以清晰的描述為:給定計算預算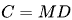 ,找到最小化模型泛化誤差的最佳模型規模
,找到最小化模型泛化誤差的最佳模型規模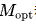 和數據規模
和數據規模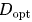 。這個目標可以形式化為:
。這個目標可以形式化為:
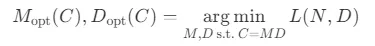
為了減少實驗成本和擬合難度,采用Chinchilla模型的等浮點運算量(IsoFLOP)配置方法來擬合縮放曲線。DeepSeek LLM選取了從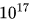 到
到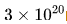 的8個不同的計算預算,并為每個預算設計了大約10種不同的模型/數據規模分配方案。每個預算的超參數由擬合得到的批量大小和學習率公式確定,并在獨立驗證集上計算泛化誤差,該驗證集與訓練集分布相似,包含1億個詞元。
的8個不同的計算預算,并為每個預算設計了大約10種不同的模型/數據規模分配方案。每個預算的超參數由擬合得到的批量大小和學習率公式確定,并在獨立驗證集上計算泛化誤差,該驗證集與訓練集分布相似,包含1億個詞元。
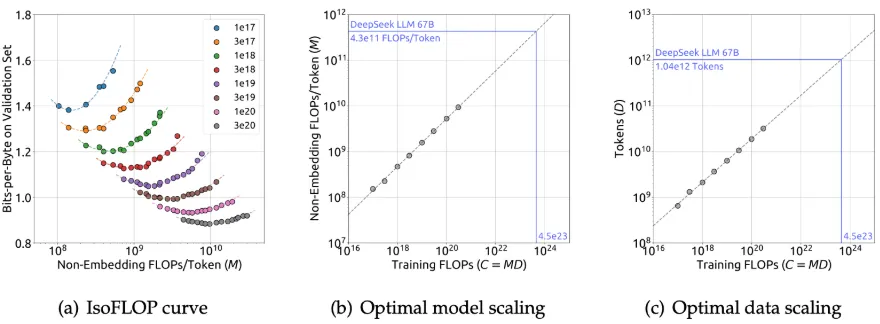
上圖展示了IsoFLOP曲線和模型/數據縮放曲線,這些曲線是通過使用每個計算預算下的最優模型/數據分配擬合得出的。最優非嵌入層每詞元浮點運算次數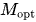 和
和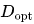 最優詞元數量的公式如下:
最優詞元數量的公式如下:
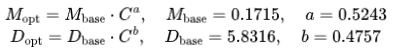
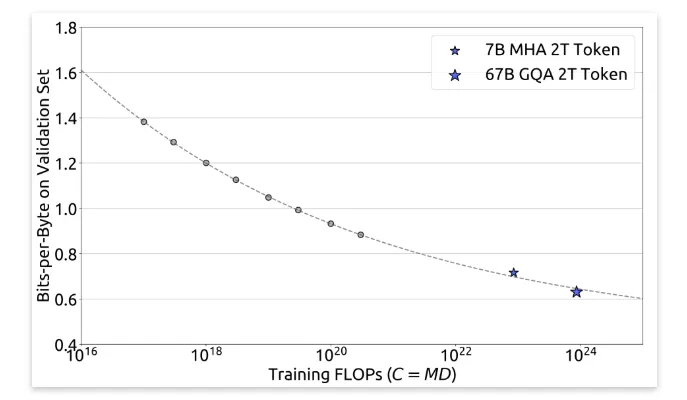
此外,根據計算預算C和最優泛化誤差擬合了損失縮放曲線,并預測了DeepSeek LLM 7B和67B模型的泛化誤差,如圖所示。結果顯示,利用小規模實驗能夠準確預測計算預算為其1000倍的模型的性能。
三、對齊
為確保實際應用的有用性和安全性,DeepSeek LLM收集了大約150萬條英文和中文的指令數據實例,涵蓋了廣泛的有益性和無害性話題。其中,有益數據包含120萬個實例,具體分布為:31.2%為一般語言任務,46.6%為數學問題,22.2%為編程練習。安全數據則由30萬個實例組成,覆蓋了各種敏感話題。
對齊流程
DeepSeek LLM對齊流程分為兩個階段:監督微調(Supervised Fine-Tuning, SFT)和直接偏好優化(Direct Preference Optimization, DPO)。
(1) 監督微調(SFT)
①訓練設置:
- 對7B模型進行4個epoch的微調,對67B模型僅進行2個epoch的微調,因為觀察到67B模型存在嚴重的過擬合問題。
- 7B和67B模型學習率分別為
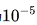 和
和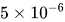 。
。 - 微調過程中,不僅監控基準準確度,還評估聊天模型的重復率。共收集了3868個中英文提示,并確定生成響應未能終止而是無限重復文本序列的比例。
- 觀察到隨著數學SFT數據量的增加,重復率有上升趨勢。這可能是由于數學SFT數據中偶爾包含類似的推理模式,導致較弱的模型難以掌握這些模式,從而產生重復響應。
②解決重復問題:
- 嘗試了兩階段微調和DPO方法,這兩種方法都能幾乎保持基準分數并顯著減少重復。
(2) 直接偏好優化(DPO)
①訓練設置:
- 為了進一步增強模型的能力,使用了直接偏好優化算法DPO,這是一種簡單但有效的方法,用于LLM的對齊。
- 構建了關于有益性和無害性的偏好數據。對于有益性數據,收集了涵蓋創意寫作、問答、指令跟隨等類別的多語言提示,并使用DeepSeek Chat模型生成響應候選。對于無害性偏好數據,也采用了類似的操作。
- DPO訓練了一個epoch,學習率為,批量大小為512,使用了學習率預熱和余弦學習率調度器。
②效果:
- DPO可以強化模型的開放式生成能力,同時在標準基準性能上幾乎沒有差異。
參考:https://arxiv.org/abs/2401.02954


























