













LLM實現自回歸搜索!MIT哈佛等提出「行動思維鏈」COAT,推理能力大提升
OpenAI o1發布后,為提升LLM的推理能力,研究者嘗試了多種方法。
比如用強大的教師模型進行知識蒸餾、采用蒙特卡洛樹搜索(MCTS),以及基于獎勵模型的引導搜索。
近日,來自MIT、新加坡科技設計大學、哈佛大學等機構的華人研究者探索了全新的方向:讓LLM擁有自回歸搜索能力。通過自我反思和探索新策略,提升LLM推理能力。
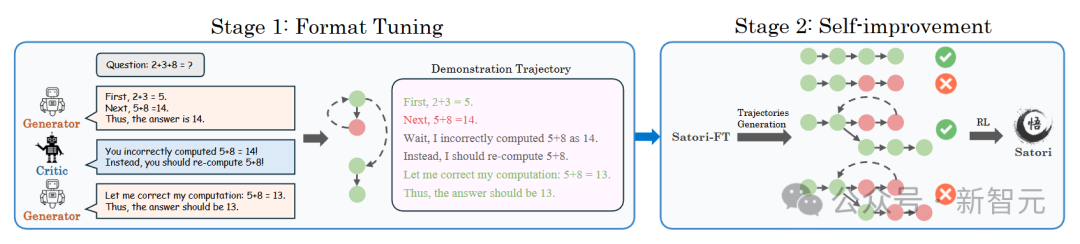
研究者引入了行動-思維鏈(COAT)機制,使LLM在解決問題時能夠執行多種元動作,并提出了一種創新的兩階段訓練框架:
- 小規模格式調優階段:讓LLM熟悉并掌握COAT推理格式。
- 大規模自我優化階段:運用重啟與探索(RAE)技術,通過RL進行優化。
通過這種方法,成功開發出Satori,在數學推理任務中,成績優異。
Satori具有以下核心特點:
- 無需外部指導,即可自我反思與探索。
- 主要依靠自我改進(RL),實現了最先進的推理性能。
- 展現出強大的遷移能力,可應用于數學以外的領域。

論文地址:https://arxiv.org/pdf/2502.02508
開源項目:https://github.com/satori-reasoning/Satori
Satori關鍵設計
研究者把LLM的推理過程看作一個順序決策問題,其中推理就是逐步構建并完善答案的過程。
具體來說,LLM從輸入上下文(初始狀態)開始,生成一個推理步驟(動作),并更新上下文(下一個狀態)。
LLM會重復這個過程,直到得出最終答案。根據最終答案與真實答案的匹配程度,給予LLM獎勵。
通過這種方式,用RL來訓練LLM進行推理,旨在讓LLM生成一系列推理步驟,以最大化期望獎勵。
行動-思維鏈推理(COAT)
實現自回歸搜索時,關鍵挑戰在于讓LLM能夠在沒有外部干預的情況下,判斷何時進行反思、繼續推理,或是探索替代方案。
為解決這個問題,研究者引入了幾種特殊的元行動tokens,來引導LLM的推理過程:
- 繼續推理(<|continue|>):鼓勵LLM依據當前的推理思路,生成下一個中間步驟。
- 反思(<|reflect|>):提醒模型暫停下來,驗證之前的推理步驟是否正確。
- 探索替代解決方案(<|explore|>):提示模型識別推理中的關鍵漏洞,并探索新的解決方案。
這種推理方式稱為行動-思維鏈(COAT)推理。每個COAT推理步驟都是一個tokens序列,并從其中一個元行動tokens開始。
標準LLM無法執行COAT推理,將RL應用于推理面臨兩個關鍵挑戰:
- 對元動作tokens缺乏認知:如果沒有經過訓練,LLM在遇到特殊的元動作tokens時,不會意識到需要反思或者尋找替代解決方案。
- 長期決策與獎勵稀疏:推理涉及長期決策,而獎勵僅在最終階段給出。這意味著LLM必須在得到獎勵之前,連續做出多個正確的推理步驟,一旦出錯,就只能從初始狀態重新開始。因為獎勵非常稀缺,而獎勵對于RL至關重要,這大大增加了學習難度。
一開始,模型對元動作tokens沒有認知。為解決這個問題,研究者設置了一個格式調優階段。
具體做法是,在一個有少量推理軌跡示例的小數據集上對預訓練的LLM進行微調。通過這一步,模型就能熟悉元動作tokens的使用,并且做出相應反應。
另外,推理存在決策時間長、獎勵少的問題。為解決這個難題,借鑒Go-Explore的思路,提出重啟與探索(RAE)策略。
模型會從之前推理過程中的中間步驟重新開始,包括那些推理失敗的節點,這樣它就能專注于改正錯誤,而不用每次都從頭開始。
同時,還增設了探索獎勵,鼓勵模型進行更深入的思考,從而提高得出正確答案的可能性。
通過模仿學習進行格式調優
這個階段的目的是對預訓練的基礎LLM進行微調,讓它能模仿符合COAT推理格式的示范推理軌跡。
為了合成包含試錯過程的COAT推理軌跡,研究者提出多代理數據合成框架,通過三個LLM來完成這項任務:
- 生成器:給定一個輸入問題,生成器會運用經典的鏈式思維(CoT)技術,生成多個推理路徑。
- Critic:負責評估生成器生成的推理路徑是否正確,同時提供反饋以優化推理過程,修正不合理的步驟。
- 獎勵模型:對優化后的推理路徑打分,挑選出最有效的路徑,作為最終的示范軌跡。
這三個模型相互配合,共同構建出高質量的示范軌跡。僅需10K條示范軌跡,就能讓基礎LLM學會遵循COAT推理格式。
通過RL進行自我提升
通過格式調優,LLM已經掌握了COAT推理風格,但遇到新問題時,仍然很難泛化。
RL階段的目標,就是讓LLM通過自我反思,提升推理能力。
以完成格式調優的LLM為基礎,用經典的PPO算法進一步優化,同時引入兩個關鍵策略:
重啟與探索(RAE):受Go-Explore算法啟發,訓練LLM時,不僅讓它從問題本身出發進行推理,還讓它從過去的推理過程中,采樣中間步驟來進行推理。
此外,增設了探索獎勵,鼓勵LLM進行更深入的自我反思,從而增加它找到正確答案的可能性。

迭代自我提升:訓練過程中,LLM的策略可能會陷入局部最優解。
借鑒Kickstarting的思路,在每一輪RL訓練結束后,通過監督微調,把當前教師策略的知識傳遞給基礎模型。以微調后的LLM為起點,再開展下一輪RL訓練。
評估結果
大量實驗結果顯示,Satori在數學推理基準測試中取得了最佳成績,在不同領域的任務上也有很強的泛化能力。
研究者選擇Qwen-2.5-Math-7B作為基礎模型,因為它在數學方面能力很強。訓練數據來源于公開的數學指令數據集,包括OpenMathInstruct-2和NuminaMathCoT。
在多智能體數據合成框架中,生成器需生成高質量的逐步推理軌跡,因此選用Qwen-2.5-MathInstruct。而評論者需要有很強的指令跟隨能力,于是選了Llama3.1-70B-Instruct。
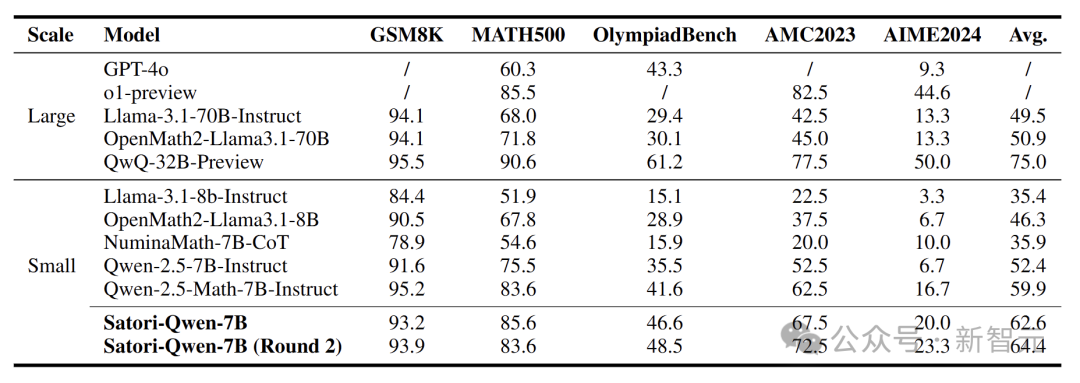
表中展示了數學基準測試的結果,Satori-Qwen-7B在所有小規模基線模型中表現最佳。
盡管Satori-Qwen-7B使用了與Qwen-2.5-Math-7B-Instruct相同的基礎模型,其性能明顯優于后者,所需的SFT數據顯著減少,并更多依賴于自我改進。
同時在數學領域之外的廣泛基準測試上進行了評估,包括邏輯推理(FOLIO、BGQA)、代碼推理(CEUXEval)、常識推理(StrategyQA)、表格推理(TableBench)以及特定領域推理(MMLUPro的STEM子集),覆蓋物理、化學、計算機科學、工程學、生物學和經濟學。
盡管Satori-Qwen-7B只在數學領域的數據集上訓練過,但它的推理能力同樣適用于其他領域。
表中展示了Satori-Qwen-7B在跨領域基準測試中的表現。

和在數學領域的表現類似,Satori-Qwen-7B在多個基準測試里成績優異,超過了Qwen-2.5-Math-7B-Instruct。
特別是在難度較高的BoardgameQA推理基準測試中,Satori-Qwen-7B的表現優于所有同規模的基線模型。
這些結果表明,Satori-Qwen-7B不僅掌握了數學解題技能,還具備了通用的推理能力。
最后一行展示了Satori第二輪訓練的結果。與Satori-Qwen-7B相比,Satori-Qwen-7B(Round 2)在大多數領域表現出持續的性能提升。
這表明迭代自我改進在提升LLM推理性能方面具有顯著的潛力。
Satori展現自我糾錯能力
研究者觀察到Satori在推理過程中經常自我反思,主要出現這兩種情形:一是在推理的中間步驟,二是完成問題后,通過自我反思發起第二次常識。
對第二種情況做定量評估,以衡量Satori的自我糾錯能力。
具體做法是,找出那些自我反思前后最終答案不一樣的回答,然后計算其中正向(從錯誤修正為正確)自我糾錯或負向(從正確改為錯誤)的比例。
表中呈現了Satori在領域內數據集(MATH500和Olympiad)以及領域外數據集(MMLUPro)上的評估結果。

與沒有經過RL訓練階段的Satori-Qwen-FT相比,Satori-Qwen的自我糾錯能力更強。
這種自我糾錯能力在領域外任務(MMLUPro-STEM)中同樣存在。
這些結果說明,RL對于提升模型實際的推理能力起著關鍵作用。
RL使Satori具備測試時擴展能力
接下來,討論RL如何激勵Satori進行自回歸搜索。
首先,從圖中可以看到,隨著RL訓練計算量的增多,Satori策略的準確率不斷上升,同時生成內容的平均token長度也在增加。這表明Satori學會了花更多時間去推理,從而更準確地解決問題。
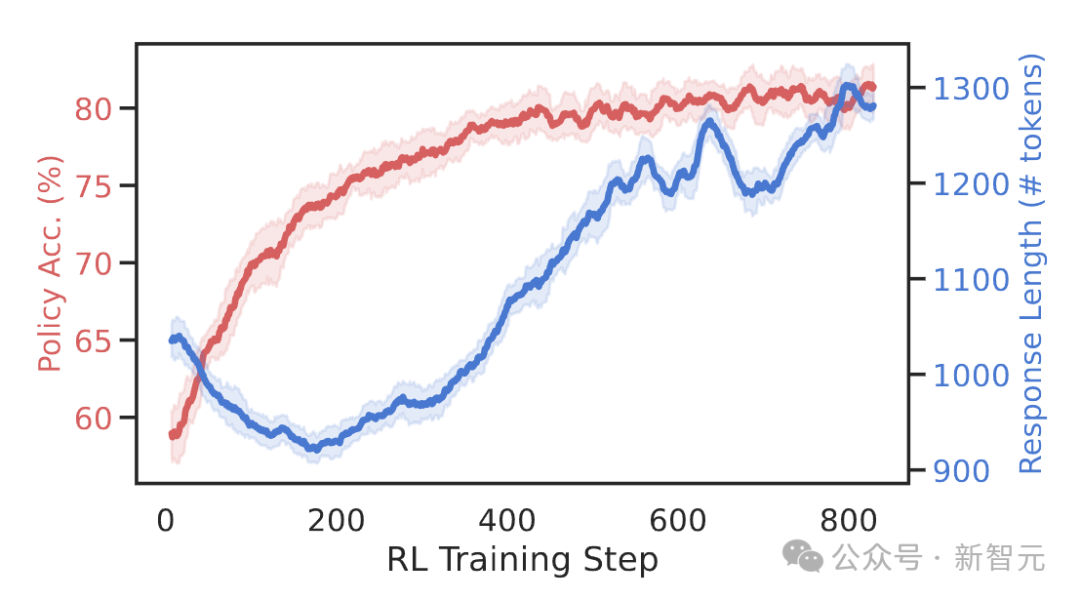
一個有趣的現象是,響應長度在前0到200步時先減少,然后再增加。
通過深入分析模型的響應,發現在早期階段,Satori還未學會自我反思能力。
在這個階段,RL優化可能會先引導模型尋找捷徑來解決問題,減少不必要的思考,所以響應長度會暫時變短。
到了后期,模型慢慢學會通過反思來自我糾錯,找到更好的解法,因此響應長度隨之增加。
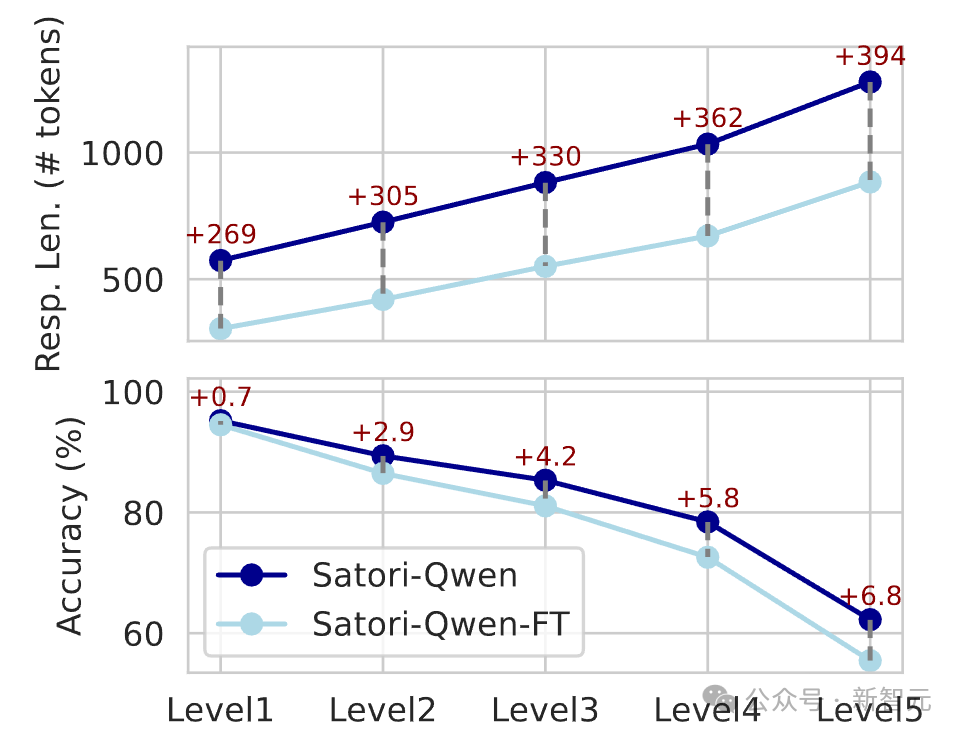
此外,研究人員在不同難度的MATH數據集上,對Satori的測試準確率和響應長度做了評估。
經過RL訓練,Satori在測試時會自動把更多計算資源,用在解決更難的問題上。與只經過格式調優的模型相比,Satori的性能不斷提高。
蒸餾實現從弱到強的泛化能力
最后,我們探究能否借助蒸餾更強的推理模型,提升較弱基礎模型的推理能力。
具體做法是,用Satori-Qwen-7B生成24萬條合成數據,以此訓練Llama-3.1-8B和Granite-3.1-8B這兩個基礎模型。
作為對比,研究者還合成了24萬條格式調優(FT)數據,用于訓練同樣的兩個模型。
之后,在所有數學基準測試數據集上,對這些模型的平均測試準確率進行評估,結果如圖所示。
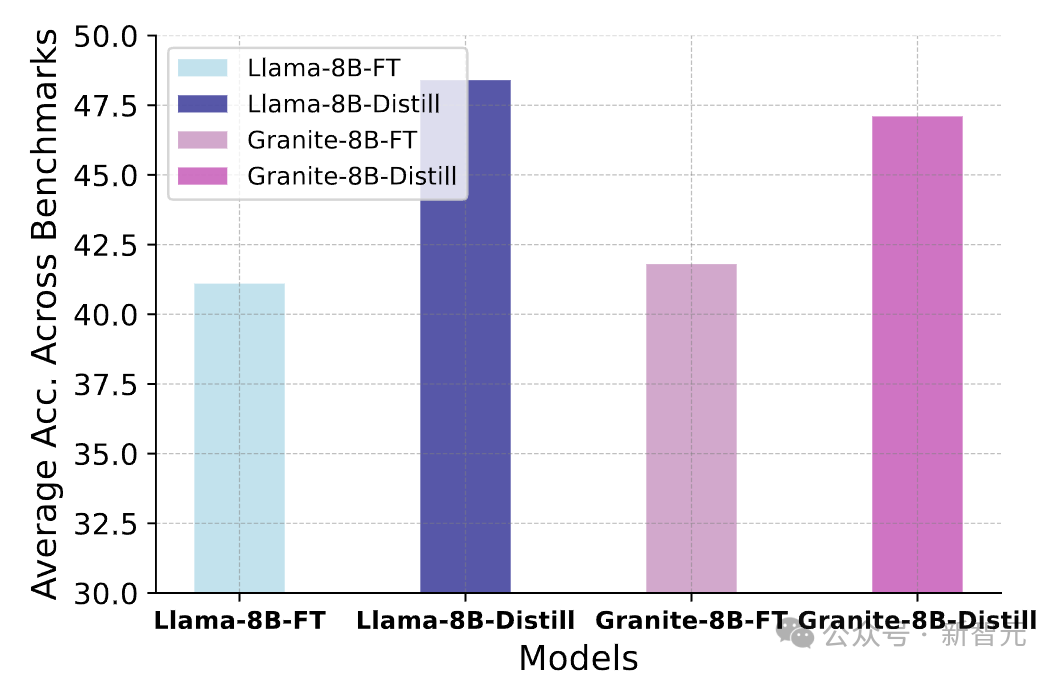
實驗表明,經過蒸餾訓練的模型,性能比僅經過格式調優的模型更好。
這為提升較弱基礎模型的推理能力,提供了一種新的高效方法:
- 通過小規模的格式調優與大規模RL相結合,訓練出像Satori-Qwen-7B這樣的強推理模型。
- 運用蒸餾的方式,將這個強推理模型的能力轉移到較弱的基礎模型中。
由于RL訓練只需答案標簽作為監督信號,所以這種方法合成數據的成本很低,既不需要多智能體數據合成框架,也無需昂貴的人工標注。



























