













解放人工標注!理想多模態框架UniPLV:開放3D場景理解新SOTA
寫在前面 & 筆者的個人理解
開放世界的3D場景理解旨在從點云等3D數據中識別和區分開放世界的對象和類別,而無需人工標注。這對于真實世界的應用,如自動駕駛和虛擬現實等至關重要。傳統的依賴人工標注的閉集識別方法無法滿足開放世界識別的挑戰,尤其3D語義標注,非常耗費人力和物力。大量的互聯網文本-視覺對數據,使得2D視覺語言模型展現出了杰出的2D開集世界理解能力。同樣道理,為了理解3D開放世界,當前的SOTA方法通過構建點云-文本對數據,再通過CLIP的對比學習方式,達到3D開放世界理解能力。這種方式不僅要求繁瑣的點云-文本對數據制作過程,而且要求大量的點云文本對齊數據。在實際互聯網世界中,大量的3D點云數據難以獲得且是有限的,因而限制了大量點云-文本對數據的制作,進而限制了方法的性能上限。
仔細觀察可以發現,盡管3D點云數據有限,它們通常與圖像成對出現。這就使得我們仔細思考:是否可以利用2D開放世界理解方法的成功,借助圖像作為媒介,在有限的數據中,將2D開放世界理解的能力轉移到3D開放世界理解當中。因此,我們設計了一個點云-圖像-文本統一的多模態學習框架,在數據有限的情況下,將圖像-文本的對齊關系遷移到點云-文本,得到3D開集場景理解模型。這個框架不需要生產點云-文本對,僅通過2D基礎模型得到區域像素-文本對,即可通過多模態統一訓練得到3D開集場景理解模型。同時,推理時不需要依賴圖像即可得到點云的語義信息。在廣泛使用的nuScenes、Waymo以及SeamanticKITTI數據集上進行的多個實驗驗證了多模態框架在3D開集任務上的有效性。

- 論文鏈接:https://arxiv.org/abs/2412.18131
本文提出了一個多模態開集框架UniPLV,將點云、圖像和文本統一到一個范式中,以實現開放世界的3D場景理解。UniPLV利用圖像模態作為橋梁,將3D點云與預對齊的圖像和文本共同嵌入到一個共享的特征空間中,不需要制作對齊的點云和文本數據。為了實現多模態對齊,我們提出了兩個關鍵策略:(i) 圖像和點云分支的邏輯和特征蒸餾模塊;(ii) 一個視覺點云匹配模塊,用于顯式糾正由點云到像素投影引起的錯位。此外,為進一步提升我們統一框架的性能,我們采用了四種特定任務的損失函數和一個兩階段的訓練策略。大量實驗表明,我們的方法在兩個開集任務Base-Annotated和Annotation-Free上的指標平均分別超過最先進方法15.6%和14.8%。
相關工作回顧
3D語義分割。3D語義分割技術可根據對點云的建模方式分為三類:view-based、point-based和voxel-based。view-based將3D點云轉換為距離視圖或鳥瞰視圖,提取2D特征,但會損失3D幾何特性。point-based直接使用3維點作為模型輸入,并設計算法聚合上下文信息。Voxel-based將點云空間劃分為多個體素網格,并使用稀疏卷積技術處理這些體素特征以提高效率。本文采用MinkUNet、SparseUnet32和PTv3作為骨干網絡,分別驗證提出框架的可擴展性和泛化能力。
開放詞匯2D場景理解。開放詞匯的2D場景理解技術隨著大型視覺語言模型的發展,在理解二維開放世界場景的能力上取得了顯著進展。主要有兩大方向:基于CLIP的方法和Grounding方法。基于CLIP的方法通常使用CLIP文本特征代替線性投影特征,并利用對比學習進行特征對齊,如GLEE、DetCLIP系列、RegionCLIP和OWL-ViT等。Grounding任務的輸入是一張圖片和對應的描述,通過不同的描述在圖像中輸出物體框的位置。鑒于2D開放世界理解的成功,我們選擇GLEE和Grounding DINO作為我們的2D開集區域標簽生成算法。
開放詞匯3D場景理解。開放詞匯的3D場景理解旨在識別未被標注的物體。早期的方法主要通過特征區分或生成的方法實現開放場景的理解。隨著視覺語言模型(如CLIP)的成功,出現了許多工作將視覺語言知識遷移到3D場景理解上。Clip2Scene使用凍結的CLIP獲取圖像的語義標簽,然后投影以指導點云的語義分割。OpenMask3D采用3D實例分割網絡創建3D掩碼,并投影以獲得2D掩碼。這些2D掩碼輸入到CLIP中,以提取視覺特征并與文本特征匹配,最終獲得3D語義。由于CLIP是基于完整圖像和文本的對齊進行訓練的,其理解特定區域的能力有限。OpenScene通過將預測結果從凍結的2D視覺模型投影并在圖像與點云特征之間進行蒸餾,實現了點云與文本對齊。然而,OpenScene需要資源密集的特征提取與融合,并且在訓練期間圖像骨干是固定的,難以擴展到更先進的3D網絡和3D場景。RegionPLC和PLA通過構建大量的點云文本對來訓練點云與文本的對齊,實現了開放場景的3D理解。本文提出了一個統一的多模態框架,用于開放場景3D理解,具有輕量級和可擴展的特點,并且不需要生成額外的點云文本對。
UniPLV 方法詳解
UniPLV能夠識別無人工標注的新類別,同時保持對已標注的基礎類別的性能。與之前通過構建3D點-文本對來實現開放詞匯理解的方法不同,我們的工作利用2D基礎模型構建圖像區域語義標簽,將開集能力從二維遷移到三維,而無需額外的3D和文本配對數據。利用二維和三維空間之間的映射關系以及預先對齊的圖像和文本,我們設計了一個多模態統一訓練框架,使用圖像作為橋梁,將點云特征嵌入到圖像和文本的共享特征空間中。我們介紹了所提框架的主要組件、數據流轉換、兩個知識蒸餾模塊以及一個視覺點匹配模塊。我們引入了一種多模態和多任務的訓練策略,以確保點云和圖像分支的穩定和高效訓練。在推理階段,此框架僅需要點云和類別描述作為輸入來計算特征相似性,選擇最相似的類別作為每個點的語義預測。

區域文本生成
我們利用二維視覺-語言基礎模型提取圖像實例和像素語義。具體來說,給定一組圖像和類別文本列表,為每張圖像輸出邊界框、實例掩碼和語義類別。我們使用GLEE進行實例掩碼和邊界框生成,該模型已在大規模數據集上訓練,在準確性和泛化性方面表現出色。另外,我們結合了 Grounding DINO 和 SAM2 ,以生成另一組實例標簽。邊界框通過 Grounding DINO 生成,隨后使用 SAM2 對每個框進一步分割以產生實例掩碼。至此,我們獲得了區域-像素-文本對,以及與圖像時空對齊的點云,用于訓練提出的多模態3D場景理解網絡。本文的實驗結果中,2D 語義標簽來自 GLEE,相關的 Grounding DINO 和 SAM2 實驗可以在補充材料中找到。
模型框架
所提出的UniPLV包括一個凍結的文本編碼器、圖像編碼-解碼器和點云分割網絡,如圖2所示。我們將所有類別名稱作為文本prompt輸入到文本編碼器中,在序列維度上應用全局平均池化來獲取文本特征。為了支持開放世界理解,我們用感知特征與文本特征之間的相似性測量替換了圖像解碼器和3D分割頭的分類器:
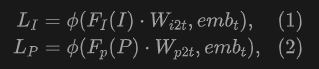
UniPLV可以利用構建的區域圖像-文本對微調圖像的分割和檢測,并提供對應于給定類別的點云分割結果。該框架的最終優化目標是通過多模態聯合訓練將點云特征和圖像-文本特征嵌入到統一的特征空間中,實現點云和文本在開放世界3D場景理解中的對齊。對于圖像和文本分支,我們加載GLEE的第二階段模型作為預訓練權重,以加強文本和圖像的對齊。在訓練過程中,我們使用二維基礎模型構建的數據微調圖像模型,在迭代訓練過程中,模型進行特征聚類,以識別并學習給定類別的共同屬性。這種機制有助于濾除由誤檢引入的噪聲,從而有效清洗偽標簽。
視覺-點云知識蒸餾
為了將圖像作為橋梁,將點云特征和預對齊的圖像-文本對共同嵌入到統一的特征空間,我們從圖像分支到點云分支引入了兩個蒸餾模塊:邏輯蒸餾和特征蒸餾。
邏輯蒸餾。 圖像像素的語義分類概率是通過圖像特征與所有給定類別的文本特征之間的相似性測量獲得的。類似地,點云的語義分類概率也通過計算與文本的相似性獲得。我們設計了邏輯蒸餾來監督新類別的點云分類,新類別語義由圖像分支預測并經過投影得到,使用了交叉熵損失和Dice損失來實現邏輯蒸餾:
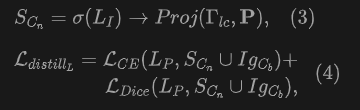
特征蒸餾。 圖像和文本之間的對齊已經使用大規模數據進行預訓練。為了彌合點云與語義文本之間的特征差距,我們進一步使用圖像特征蒸餾點云的特征。我們僅蒸餾在空間映射和語義上同時對齊的2D-3D配對點。特征蒸餾基于相似性計算進行,使用余弦相似度函數在特定配對的點云和圖像之間測量特征相似度:
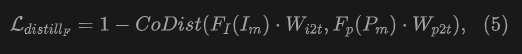
視覺-點云匹配學習
我們引入了視覺-點云匹配(VPM)模塊以進一步學習圖像與點云之間的細粒度對齊。這是一個二分類任務,要求模型預測來自投影的像素點對是正匹配還是負匹配。VPM主要包括一個注意力編碼器模塊和一個二分類器。給定配對的圖像特征和點云特征,圖像特征為查詢向量,而點云特征作為鍵和值向量。自注意力應用于圖像特征以獲得圖像注意力特征。隨后的交叉注意力在圖像和點云特征之間進行,交叉特征經過前饋網絡輸出到一個二分類器獲得匹配概率:
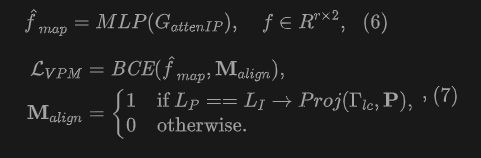
優化目標&多模態訓練
為了實現3D開放世界場景理解,我們聯合訓練圖像像素、3D點云與文本之間的對齊。我們提出的UniPLV有四個特定任務的損失:圖像-文本對齊、點云-文本對齊、像素-點云匹配,以及邏輯和特征蒸餾損失。最終的總損失通過加權結合上述四種損失進行如下計算:
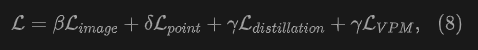
為了達到多模態穩定的訓練,我們提出了一種兩階段多任務訓練策略,用于訓練多模態框架UniPLV。
階段1:獨立圖像分支訓練。 訓練初步階段,我們獨立訓練圖像分支持續總迭代步數的一半,保證兩個模態的網絡梯度同步,并且在圖像分支訓練期間實施梯度剪裁,以防止梯度爆炸,保證訓練穩定。
階段2:統一多模態訓練。 第二階段涉及圖像和點云分支的聯合訓練,采用不同的損失權重以有效平衡它們的損失值。在整個訓練過程中,我們使用AdamW優化器,因其自適應學習能力和收斂穩定而被選擇。優化器參數,特別是學習率和權重衰減,取決于每個分支的主干結構,并且針對圖像和點云分支設置有所不同。這種策略上的優化設置差異確保了兩個分支根據其特定的網絡結構和數據特性進行訓練,最終使得多模態訓練任務達到更優的性能。
推理
推理過程如圖2所示。在推理過程中,我們可以將任意開放詞匯類別編碼為文本查詢,并計算它們與3D點云的相似性。具體來說,我們將每個點與計算出的余弦相似度最高的類別關聯。由于我們已經將圖像-文本對齊蒸餾到點云-文本對齊,因此在推理過程中不需要處理圖像。
實驗結果







結論&未來工作
結論。本文提出了一種用于開放世界3D場景理解的統一多模態學習框架,UniPLV,該框架不需要制作點云文本對,利用圖像作為橋梁,提出了邏輯蒸餾、特征蒸餾和視覺-點云匹配模塊。此外,我們引入了四個特定任務的損失函數和兩階段訓練過程,以實現穩定的多模態學習。我們的方法在nuScenes數據集上顯著超越了最先進的方法。此外,在不同3D骨干網絡以及Waymo和Semantickitti數據集上的實驗結果也顯示了我們方法的可擴展性和輕量級特征。
未來工作。未來有一些工作需要改進和解決。我們提出的框架目前僅在室外數據集上進行了驗證。未來,我們計劃將驗證擴展到室內數據集,如ScanNet,其中2D和3D之間的投影參數更為準確。我們將來會改進和量化圖像分支,使提出的框架能夠同時實現2D和3D開放世界場景理解任務。點云分支也可以替換為OCC占用預測網絡,以擴展開放世界的應用。






























