一文讀懂 NVIDIA GPU 產(chǎn)品線
Hello folks,我是 Luga,今天我們來聊一下人工智能應(yīng)用場景中一個至關(guān)重要的組成部分:構(gòu)建高效、靈活的計(jì)算架構(gòu)的基石—NVIDIA GPU 產(chǎn)品線。
在人工智能和深度學(xué)習(xí)領(lǐng)域,NVIDIA 憑借其強(qiáng)大的 GPU 產(chǎn)品線占據(jù)著舉足輕重的地位。NVIDIA 擁有數(shù)十款功能各異的 GPU 產(chǎn)品,可用于部署和運(yùn)行不同規(guī)模的機(jī)器學(xué)習(xí)模型,從邊緣設(shè)備到大規(guī)模數(shù)據(jù)中心,幾乎涵蓋了所有應(yīng)用場景。

然而,NVIDIA GPU 的命名規(guī)則較為復(fù)雜,涉及架構(gòu)代號(如 Ampere、Hopper)、性能等級(如 A100、A40)以及其他技術(shù)特征等多重維度,這使得用戶在選擇時容易感到困惑。要充分理解這些不同顯卡的性能特征、成本效益,乃至僅僅記住它們繁復(fù)的命名規(guī)則,對許多用戶來說都是一項(xiàng)不小的挑戰(zhàn)。
一、如何挑選適合的數(shù)據(jù)中心 GPU?
在人工智能領(lǐng)域,特別是生成式人工智能工作負(fù)載和機(jī)器學(xué)習(xí)模型推理方面,擁有強(qiáng)大且經(jīng)濟(jì)高效的硬件解決方案是每個從業(yè)者的共同追求。
然而,數(shù)據(jù)中心級 GPU 的選型并非像在商店里隨意性挑選電子產(chǎn)品那樣簡單明了——后者通常只有少數(shù)幾個配置選項(xiàng)和清晰的升級路徑可供選擇。相反,GPU 的選擇更類似于購買汽車:我們的預(yù)算、具體應(yīng)用場景以及對性能的需求將在眾多具有不同功能、價(jià)格和市場可用性的車型和年份中引導(dǎo)我們的最終決策。
為了幫助大家更好地應(yīng)對這一挑戰(zhàn),本文將首先深入解析 NVIDIA 數(shù)據(jù)中心級 GPU 的命名規(guī)則,幫助大家快速識別一款顯卡的底層架構(gòu)和性能層級。NVIDIA 的命名體系通常采用字母數(shù)字組合的形式,這些看似復(fù)雜的代碼實(shí)際上蘊(yùn)含著關(guān)于 GPU 核心架構(gòu)、顯存容量、計(jì)算能力等關(guān)鍵技術(shù)規(guī)格的重要信息。掌握這些命名規(guī)則,是進(jìn)行有效選型的基礎(chǔ)。
在此基礎(chǔ)上,本文還將提供一系列清晰且直接的方法,用于對不同 GPU 的性能進(jìn)行客觀比較。我們將從浮點(diǎn)運(yùn)算能力、內(nèi)存帶寬、互聯(lián)技術(shù)等多個維度進(jìn)行剖析,并提供一個包含多款常用于模型訓(xùn)練、微調(diào)和模型服務(wù)的數(shù)據(jù)中心級 GPU 的關(guān)鍵技術(shù)規(guī)格對比表格。通過本文的解析,大家將能夠根據(jù)自身的實(shí)際需求,在眾多 NVIDIA GPU 產(chǎn)品中做出明智的選擇,從而構(gòu)建高效且經(jīng)濟(jì)的 AI 計(jì)算平臺。
二、GPU 命名規(guī)則解讀
企業(yè)生產(chǎn)級或數(shù)據(jù)中心級 GPU 的命名規(guī)則乍看之下可能較為復(fù)雜,例如 K80、T4、A100、L40 等名稱,初學(xué)者往往難以理解其含義。然而,這些看似隨機(jī)的字母和數(shù)字組合并非隨意排列,而是經(jīng)過精心設(shè)計(jì)的,它們實(shí)際上編碼了關(guān)于 GPU 架構(gòu)、性能參數(shù)和關(guān)鍵技術(shù)規(guī)格的重要信息。
NVIDIA 數(shù)據(jù)中心 GPU 的命名規(guī)則通常包含以下幾個維度的信息:
1.字母:
或稱之為“架構(gòu)代號(Architecture)”代表 GPU 的核心架構(gòu),通常用一個或多個字母表示,代表 GPU 的微架構(gòu)。例如:
- K:Kepler 架構(gòu)
- T:Turing 架構(gòu)
- A:Ampere 架構(gòu)
- H:Hopper 架構(gòu)
- L: Ada Lovelace 架構(gòu)
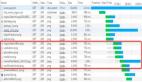
在 NVIDIA GPU 的命名體系中,首字母通常代表該 GPU 采用的微架構(gòu)。微架構(gòu)是 GPU 芯片設(shè)計(jì)的核心,決定了其基本的運(yùn)算方式、指令集以及內(nèi)部結(jié)構(gòu)。每隔幾年,NVIDIA 都會針對其消費(fèi)級和數(shù)據(jù)中心產(chǎn)品線推出全新的微架構(gòu),以實(shí)現(xiàn)性能和能效比的顯著提升。

圖:NVIDIA GPU 架構(gòu)發(fā)展歷程
從本質(zhì)上來講,每個新的架構(gòu)通常代表著性能、能效比和新技術(shù)的顯著提升。GPU 的微架構(gòu)是影響其性能和功能的最關(guān)鍵因素之一。不同的架構(gòu)在設(shè)計(jì)理念、內(nèi)部結(jié)構(gòu)和支持的技術(shù)特性上可能存在顯著差異。
例如,某些架構(gòu)可能更側(cè)重于通用計(jì)算性能,而另一些架構(gòu)則可能針對特定的工作負(fù)載(例如深度學(xué)習(xí)、圖形渲染)進(jìn)行優(yōu)化。因此,理解 GPU 的架構(gòu)對于選擇合適的硬件至關(guān)重要。
2.性能層級(Tier):
通常用數(shù)字表示,數(shù)字越大通常代表性能越強(qiáng)。
在同一微架構(gòu)下,NVIDIA 會根據(jù)不同的市場定位和應(yīng)用需求,推出多款不同性能層級的 GPU 產(chǎn)品,以滿足各種計(jì)算負(fù)載的需求。這些不同的層級通常通過數(shù)字來區(qū)分,數(shù)字越大,代表該 GPU 的性能越強(qiáng)、價(jià)格越高,通常也意味著更高的功耗。
不同層級的 GPU 針對不同的計(jì)算負(fù)載進(jìn)行了優(yōu)化,以下是近年來一些常見層級的特點(diǎn)和應(yīng)用場景:
(1) “4” 系列:入門級或低功耗級
“4” 系列 GPU 通常是同代產(chǎn)品中體積最小、功耗最低的型號,其設(shè)計(jì)目標(biāo)是在有限的功耗預(yù)算下提供足夠的計(jì)算性能。這類 GPU 適合對性能要求不高、注重成本效益的應(yīng)用場景,例如:
- 輕量級的模型推理任務(wù),例如圖像分類、自然語言處理等。
- 邊緣計(jì)算設(shè)備或低功耗服務(wù)器。
- 對成本敏感的應(yīng)用部署。
(2)“10” 系列:中端推理優(yōu)化級
“10” 系列 GPU 通常是針對人工智能推理應(yīng)用進(jìn)行優(yōu)化的中端產(chǎn)品。它們在性能、功耗和成本之間取得了較好的平衡,適合需要較高推理吞吐量和較低延遲的應(yīng)用場景,例如:
- 大規(guī)模的在線推理服務(wù)。
- 視頻分析和圖像處理。
- 實(shí)時語音識別和翻譯。
(3)“40” 系列:高端圖形和虛擬工作站級
“40” 系列 GPU 通常是面向?qū)I(yè)圖形應(yīng)用和虛擬工作站的高端產(chǎn)品。它們擁有強(qiáng)大的圖形渲染能力和計(jì)算性能,適合對圖形處理和計(jì)算性能要求較高的應(yīng)用場景,例如:
- 專業(yè)級圖形設(shè)計(jì)和渲染。
- 高性能計(jì)算可視化。
- 虛擬桌面基礎(chǔ)設(shè)施 (VDI)。
(4)“100” 系列:旗艦級高性能計(jì)算和人工智能級
“100” 系列 GPU 是同代產(chǎn)品中性能最強(qiáng)、價(jià)格最高的旗艦級產(chǎn)品。它們擁有最多的內(nèi)核數(shù)量、最大的顯存容量和最高的內(nèi)存帶寬,專為處理最 demanding 的計(jì)算負(fù)載而設(shè)計(jì),例如:
- 大規(guī)模的模型訓(xùn)練和微調(diào)。
- 高性能科學(xué)計(jì)算和模擬。
- 超大規(guī)模數(shù)據(jù)中心部署。
3.其他標(biāo)識符:
有時還會包含其他字母或數(shù)字,用于表示特定的變體、配置或目標(biāo)應(yīng)用場景。例如:
- T4 中的 "4" 可能暗示其定位是推理(Inference)應(yīng)用。
- 某些針對特定工作負(fù)載優(yōu)化的 GPU 可能會帶有后綴。
在實(shí)際的業(yè)務(wù)場景中,理解 NVIDIA GPU 的性能層級對于根據(jù)自身需求選擇合適的硬件至關(guān)重要。錯誤地選擇過高或過低的層級都可能導(dǎo)致資源浪費(fèi)或性能瓶頸。
例如,如果只需要進(jìn)行簡單的模型推理,選擇 “100” 系列的 GPU 顯然是過度投資;而如果需要進(jìn)行大規(guī)模的模型訓(xùn)練,選擇 “4” 系列的 GPU 則無法滿足性能需求。
三、常見的GPU 型號對比解析:基于 GPU 命名推斷顯卡特性
結(jié)合前文所述的架構(gòu)代號(字母)和性能層級(數(shù)字)這兩個關(guān)鍵因素,我們可以通過 GPU 名稱中的字母和數(shù)字組合來推斷出關(guān)于該顯卡的一些重要信息,從而更好地進(jìn)行選型。以下通過幾個具體的示例進(jìn)行說明:
示例一:T4 與 L4 的比較
L4 是 T4 的直接后繼者,屬于同一性能層級,針對相似的應(yīng)用場景設(shè)計(jì)。然而,兩者在微架構(gòu)和技術(shù)規(guī)格上存在顯著差異:
- 微架構(gòu): L4 采用更新的 Ada Lovelace 架構(gòu)(2023 年發(fā)布),而 T4 則采用較早的 Turing 架構(gòu)(2018 年發(fā)布)。
- 顯存容量: L4 配備了更大的顯存容量,達(dá)到 24 GB,而 T4 僅有 16 GB。
- 核心數(shù)量和性能: L4 擁有更多且更強(qiáng)大的計(jì)算核心,因此在性能上優(yōu)于 T4。
雖然兩者的目標(biāo)功耗相似,但 L4 憑借更先進(jìn)的架構(gòu)和更高的顯存容量,在相同的功耗下能夠提供更強(qiáng)的計(jì)算性能,更適合處理對顯存容量有較高要求的任務(wù)。
示例二:A10 與 A100 的比較
A100 是基于 Ampere 架構(gòu)的旗艦級產(chǎn)品,而 A10 則是該架構(gòu)下的一個較低層級的型號。兩者都基于相同的 Ampere 微架構(gòu),但在規(guī)模和性能上存在顯著差異:
- 核心數(shù)量和性能: A100 擁有遠(yuǎn)多于 A10 的計(jì)算核心,因此在計(jì)算性能上遠(yuǎn)超 A10。
- 顯存容量: A100 配備了更大的顯存容量,以支持更大規(guī)模的模型訓(xùn)練和推理。
- 功耗: 由于規(guī)模更大、性能更強(qiáng),A100 的功耗也高于 A10。
因此,A100 更適合需要處理大規(guī)模模型訓(xùn)練、微調(diào)和高吞吐量推理等 demanding 計(jì)算任務(wù)的場景,而 A10 則更適合對成本和功耗敏感、對性能要求相對較低的應(yīng)用場景。
示例三:K80 與 T4 的比較
比較不同架構(gòu)和不同層級的 GPU 通常較為復(fù)雜。K80 采用了相對古老的 Kepler 架構(gòu)(發(fā)布于十多年前),而 T4 則采用了更現(xiàn)代的 Turing 架構(gòu)。
雖然 K80 擁有雙 GPU 芯片,但由于架構(gòu)的落后,其性能和能效比遠(yuǎn)不及 T4。因此,對于大多數(shù)現(xiàn)代機(jī)器學(xué)習(xí)任務(wù)而言,T4 不僅速度更快,而且由于功耗更低,每分鐘運(yùn)行成本也更低。這個例子也說明了架構(gòu)的重要性,即使核心數(shù)量更多,落后的架構(gòu)也可能導(dǎo)致性能不如新架構(gòu)。
示例四:T4 與 A10 的模型服務(wù)能力比較
T4 和 A10 都屬于針對推理優(yōu)化的 GPU,但由于性能層級的不同,它們在模型服務(wù)能力上也存在差異。T4 適合服務(wù)中等規(guī)模的模型,例如圖像分類、目標(biāo)檢測等。而 A10 則擁有更強(qiáng)的計(jì)算能力和更大的顯存容量,可以服務(wù)更大規(guī)模的模型,例如大型語言模型 (LLM) 的推理。
通過以上示例,我們可以看到,結(jié)合 GPU 名稱中的字母(架構(gòu))和數(shù)字(層級),可以有效地推斷出該 GPU 的一些關(guān)鍵特性,并根據(jù)自身的需求選擇合適的硬件。理解這些命名規(guī)則,有助于更好地理解 NVIDIA 的 GPU 產(chǎn)品線,并做出明智的購買決策。
通過以上更詳細(xì)的解釋和示例,大家可以更深入地理解如何根據(jù) GPU 名稱進(jìn)行選型,并了解到不同架構(gòu)和層級 GPU 之間的差異。
Happy Coding ~
Reference :
[1] https://www.nvidia.com/en-us/data-center/data-center-gpus/