一文講清數據庫的分庫分表
想必大家在面試的時候都被問到過數據庫的分庫分表應該怎么做。
分庫分表指的是是將大型數據庫分割成多個小型數據庫或表格的技術,旨在通過分散數據來提升性能、增加可擴展性和簡化管理。隨著數據量的增長,傳統的單體數據庫可能會遭遇性能瓶頸,而分庫分表能有效解決這些問題,支持系統線性擴展,確保高效的數據處理和響應速度,同時降低運維復雜度和成本。
今天我就分享一下我對此的一些見解。(如有錯誤,歡迎指正)
一、選擇合適的數據庫驅動和ORM框架(如果使用)
- 數據庫驅動
Golang支持多種數據庫驅動,如database/sql包提供了與數據庫交互的標準接口。對于MySQL,常用的驅動是github.com/go - sql - driver/mysql。確保在項目中正確導入和初始化驅動,例如:
import (
"database/sql"
_ "github.com/go - sql - driver/mysql"
)
func main() {
db, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/database_name")
if err!= nil {
// 處理錯誤
}
defer db.Close()
}- ORM框架(可選)
如果項目使用ORM框架,如GORM,它可以簡化數據庫操作,包括分庫分表的實現。GORM提供了方便的API來定義模型和執行數據庫操作。導入GORM和相關的數據庫驅動(以MySQL為例):
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
func main() {
dsn := "user:password@tcp(127.0.0.1:3306)/database_name?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})
if err!= nil {
// 處理錯誤
}
}二、確定分庫分表策略
- 水平分表策略
對于用戶表,按照用戶ID進行哈希取模分表。假設要將用戶數據分散到10張表中,可以計算user_id % 10,根據結果將用戶數據存儲到user_0、user_1等對應的表中。在查詢用戶數據時,同樣先計算哈希值,然后確定要查詢的表。
例如,對于抽獎記錄,按照時間范圍進行分表。可以每月創建一張新表,表名可以采用lottery_records_202401(表示2024年1月的抽獎記錄)這樣的格式。在代碼中,需要根據抽獎時間來確定操作哪一張表。
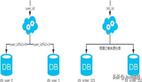
按范圍劃分
按哈希劃分
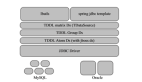
- 垂直分庫策略
按照業務模塊劃分數據庫。例如,將用戶信息存儲在一個數據庫(user_db)中,抽獎規則存儲在另一個數據庫(lottery_rule_db)中,抽獎結果存儲在第三個數據庫(lottery_result_db)等。在代碼中,需要根據操作的業務模塊來選擇不同的數據庫連接。
三、實現分庫分表邏輯
- 基于SQL操作實現(不使用ORM)
在查詢用戶數據時:
水平分表操作示例(按哈希劃分用戶表)
func QueryUser(db *sql.DB, userID int) (*User, error) {
tableName := fmt.Sprintf("user_%d", userID%10)
querySQL := fmt.Sprintf("SELECT * FROM %s WHERE user_id =? ", tableName)
row := db.QueryRow(querySQL, userID)
user := &User{}
err := row.Scan(&user.ID, &user.Name, &user.Age)
if err!= nil {
return nil, err
}
return user, nil
}- 在插入用戶數據時:func InsertUser(db *sql.DB, user *User) error {
tableName := fmt.Sprintf("user_%d", user.ID%10)
insertSQL := fmt.Sprintf("INSERT INTO %s (user_id, name, age) VALUES (?,?,?)", tableName)
stmt, err := db.Prepare(insertSQL)
if err!= nil {
return err
}
defer stmt.Close()
_, err = stmt.Exec(user.ID, user.Name, user.Age)
return err
}- 垂直分庫操作示例(選擇不同數據庫連接)
假設已經有兩個數據庫連接userDB和lotteryRuleDB:
func QueryUserInfo(userDB *sql.DB, userID int) (*UserInfo, error) {
querySQL := "SELECT * FROM user_info WHERE user_id =?"
row := userDB.QueryRow(querySQL, userID)
userInfo := &UserInfo{}
err := row.Scan(&userInfo.ID, &userInfo.Email, &userInfo.Address)
if err!= nil {
return nil, err
}
return userInfo, nil
}
func QueryLotteryRule(lotteryRuleDB *sql.DB, ruleID int) (*LotteryRule, error) {
querySQL := "SELECT * FROM lottery_rule WHERE rule_id =?"
row := lotteryRuleDB.QueryRow(querySQL, ruleID)
lotteryRule := &LotteryRule{}
err := row.Scan(&lotteryRule.ID, &lotteryRule.Probability, &lotteryRule.PrizeType)
if err!= nil {
return nil, err
}
return lotteryRule, nil
}- 基于ORM框架(如GORM)實現
可以通過自定義GORM插件來實現分表邏輯。首先定義插件結構體:
水平分表操作示例(按哈希劃分用戶表)
type ShardingPlugin struct{}
```
- 實現GORM的Plugin接口方法,在`Name`方法中返回插件名稱,在`Initialize`方法中實現分表邏輯:
- ```Go
func (p ShardingPlugin) Name() string {
return "ShardingPlugin"
}
func (p ShardingPlugin) Initialize(db *gorm.DB) error {
// 根據用戶ID計算表名
db.Callback().Query().Before("gorm:query").Register("sharding:query", func(db *gorm.DB) {
userID, ok := db.Statement.Vars["user_id"].(int)
if ok {
tableName := fmt.Sprintf("user_%d", userID%10)
db.Statement.Table(tableName)
}
})
db.Callback().Create().Before("gorm:create").Register("sharding:create", func(db *gorm.DB) {
userID, ok := db.Statement.Vars["user_id"].(int)
if ok {
tableName := fmt.Sprintf("user_%d", userID%10)
db.Statement.Table(tableName)
}
})
return nil
}在初始化GORM時注冊這個插件:
func main() {
dsn := "user:password@tcp(127.0.0.1:3306)/database_name?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
Plugins: []gorm.Plugin{ShardingPlugin{}},
})
if err!= nil {
// 處理錯誤
}
}- 垂直分庫操作示例(選擇不同數據庫連接)
在GORM中,可以通過定義不同的數據庫連接實例來操作不同的數據庫。假設已經定義了userDB和lotteryRuleDB兩個GORM數據庫實例:
func QueryUserInfo(userDB *gorm.DB, userID int) (*UserInfo, error) {
userInfo := &UserInfo{}
err := userDB.Where("user_id =?", userID).First(userInfo).Error
if err!= nil {
return nil, err
}
return userInfo, nil
}
func QueryLotteryRule(lotteryRuleDB *gorm.DB, ruleID int) (*LotteryRule, error) {
lotteryRule := &LotteryRule{}
err := lotteryRuleDB.Where("rule_id =?", ruleID).First(lotteryRule).Error
if err!= nil {
return nil, err
}
return lotteryRule, nil
}四、數據遷移和同步
- 初始數據遷移
當實施分庫分表策略時,需要將原有數據遷移到新的數據庫結構中。如果是水平分表,可以編寫數據遷移腳本,按照分表策略將數據從舊表復制到新表。例如,對于按時間范圍分表的抽獎記錄:
func MigrateLotteryRecords() error {
oldDB, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/old_database_name")
if err!= nil {
return err
}
defer oldDB.Close()
newDB, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/new_database_name")
if err!= nil {
return err
}
defer newDB.Close()
rows, err := oldDB.Query("SELECT * FROM old_lottery_records")
if err!= nil {
return err
}
defer rows.Close()
for rows.Next() {
record := &LotteryRecord{}
err := rows.Scan(&record.ID, &record.UserID, &record.LotteryDate)
if err!= nil {
return err
}
// 根據抽獎日期確定新表名
newTableName := fmt.Sprintf("lottery_records_%d", record.LotteryDate.Year()*100 + int(record.LotteryDate.Month()))
insertSQL := fmt.Sprintf("INSERT INTO %s (id, user_id, lottery_date) VALUES (?,?,?)", newTableName)
stmt, err := newDB.Prepare(insertSQL)
if err!= nil {
return err
}
defer stmt.Close()
_, err = stmt.Exec(record.ID, record.UserID, record.LotteryDate)
if err!= nil {
return err
}
}
return nil
}- 數據同步機制
在分庫分表后,可能需要建立數據同步機制,以確保數據的一致性。例如,在分布式系統中,當一個服務更新了用戶表的數據,可能需要通過消息隊列(如Kafka)將更新事件發送到其他相關服務,其他服務收到消息后對相應的分表進行更新操作。以下是一個簡單的示例,使用Kafka進行數據同步:
import (
"github.com/Shopify/sarama"
)
func UpdateUserAndSync(userDB *sql.DB, kafkaProducer sarama.SyncProducer, user *User) error {
// 更新用戶數據
err := UpdateUser(userDB, user)
if err!= nil {
return err
}
// 發送數據更新消息到Kafka
message := &sarama.ProducerMessage{
Topic: "user_update_topic",
Value: sarama.StringEncoder(fmt.Sprintf("user_id:%d", user.ID)),
}
_, _, err = kafkaProducer.SendMessage(message)
return err
}
func KafkaConsumerLoop(kafkaConsumer sarama.Consumer, userDB *sql.DB) {
consumer, err := kafkaConsumer.ConsumePartition("user_update_topic", 0, sarama.OffsetNewest)
if err!= nil {
// 處理錯誤
}
defer consumer.Close()
for message := range consumer.Messages() {
// 解析消息,獲取用戶ID
userIDStr := string(message.Value)
userID, err := strconv.Atoi(userIDStr[len("user_id:"):])
if err!= nil {
// 處理錯誤
}
// 根據用戶ID更新其他分表中的用戶數據
user, err := QueryUser(userDB, userID)
if err!= nil {
// 處理錯誤
}
// 更新其他分表...
}
}五、性能測試和優化
- 性能測試
在實施分庫分表后,需要對系統進行性能測試,以驗證是否達到了預期的性能提升效果。可以使用性能測試工具,如go - bench來測試數據庫操作的性能。例如,測試查詢用戶數據的性能:
func BenchmarkQueryUser(b *testing.B) {
db, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/database_name")
if err!= nil {
b.Fatal(err)
}
defer db.Close()
for i := 0; i < b.N; i++ {
userID := i
QueryUser(db, userID)
}
}- 優化調整
根據性能測試結果,對分庫分表策略和代碼進行優化調整。例如,如果發現某些查詢操作仍然較慢,可以考慮優化索引策略、調整分片規則或者增加緩存機制等。如果是使用ORM框架,還可以優化ORM的配置,如調整GORM的Preload和Joins策略來減少不必要的數據庫查詢。
本文轉載自微信公眾號「王中陽」,作者「王中陽」,可以通過以下二維碼關注。

轉載本文請聯系「王中陽」公眾號。