關于計算機視覺中的自回歸模型,這篇綜述一網打盡了
本文是一篇關于自回歸模型在視覺領域發展的綜述論文,由港大、清華、普林斯頓、杜克、俄亥俄州立、UNC、蘋果、字節跳動、香港理工大學等多所高校及研究機構的伙伴聯合發布。
隨著計算機視覺領域的不斷發展,自回歸模型作為一種強大的生成模型,在圖像生成、視頻生成、3D 生成和多模態生成等任務中展現出了巨大的潛力。然而,由于該領域的快速發展,及時、全面地了解自回歸模型的研究現狀和進展變得至關重要。本文旨在對視覺領域中的自回歸模型進行全面綜述,為研究人員提供一個清晰的參考框架。

- 論文標題:Autoregressive Models in Vision: A Survey
- 論文鏈接: https://arxiv.org/abs/2411.05902
- 項目地址:https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey
研究的主要亮點如下:
最新最全的文獻綜述:本文對視覺領域中的自回歸模型進行了全面的文獻綜述,涵蓋了約 250 篇相關參考文獻,包括一些新興領域的相關文獻,比如 3D 醫療、具身智能等。通過對這些文獻的整理和分析,本文能夠為讀者提供一個系統的了解自回歸模型在視覺領域的發展歷程和研究現狀的有效幫助。

基于序列表征的分類:本文根據序列表示策略對自回歸模型進行了分類,包括基于 pixel、基于 token 和基于 scale 的視覺自回歸模型。同時,本文還對不同類型的自回歸模型在圖像生成、視頻生成、3D 生成和多模態生成等任務中的性能進行了比較和分析。通過這些分類和比較,本文能夠幫助讀者更好地理解不同類型的自回歸模型的特點和優勢,為選擇合適的模型提供參考。

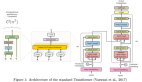
左邊圖展示的是 3 種主流的用于自回歸視覺模型的表征方法。右邊圖展示的是自回歸視覺模型的主要組成:序列表征方法和自回歸序列建模方式。
各種領域的應用總結:本文詳細介紹了自回歸模型在圖像生成、視頻生成、3D 生成和多模態生成等任務中的應用。通過對這些應用的總結和分析,本文能夠為讀者展示自回歸模型在不同領域的應用潛力和實際效果,為進一步推動自回歸模型的應用提供參考。下面是本文的文獻分類框架圖:

挑戰與展望:本文討論了自回歸模型在視覺領域面臨的挑戰,如計算復雜度、模式崩潰等,并提出了一些潛在的研究方向。通過對這些挑戰和展望的討論,本文能夠為讀者提供一個思考和探索的方向,促進自回歸模型在視覺領域的進一步發展。
2. 視覺自回歸模型
基礎知識
視覺自回歸模型有兩個核心的組成部分:序列表示和自回歸序列建模方法。首先,讓我們來了解這兩個關鍵方面:
序列表示:將視覺數據轉化為離散元素序列,如像素、視覺詞元等。這種表示方法類似于自然語言處理(NLP)中的文本生成中把詞分成詞元進行后續處理,為自回歸模型在計算機視覺領域的應用奠定了基礎。舉例來說,對于圖像數據,可以將其劃分為像素序列或者圖像塊序列,每個像素或圖像塊作為序列中的一個元素。這樣,就可以利用自回歸模型依次預測每個元素,從而實現圖像的生成或重建。
自回歸序列建模:基于先前生成的元素,通過條件概率依次預測每個元素。具體來說,對于一個序列中的第 t 個元素,自回歸模型會根據前面 t-1 個元素的信息來預測第 t 個元素的概率分布。訓練目標是最小化負對數似然損失。通過不斷調整模型參數,使得模型預測的概率分布盡可能接近真實數據的分布,從而提高模型的性能。
2.1 通用框架分類
了解了自回歸模型的基礎之后,我們接下來看看不同的通用框架分類。下面我們分別介紹基于像素、基于視覺詞元和基于尺度的模型。
2.1.1 基于像素(pixel)的模型:這類模型直接在像素級別表示視覺數據,如 PixelRNN 和 PixelCNN 等。PixelRNN 通過遞歸神經網絡(RNN)捕捉像素間的依賴關系,從圖像的左上角開始,依次預測每個像素的值。PixelCNN 則使用卷積神經網絡(CNN)來實現像素級別的自回歸建模,通過對圖像進行卷積操作來獲取像素間的局部依賴關系。
但是這類模型在高分辨率圖像生成時面臨計算成本高和信息冗余的挑戰。由于需要對每個像素進行預測,隨著圖像分辨率的提高,計算量會呈指數增長。同時,像素之間的相關性可能導致信息冗余,影響模型的效率和性能。
2.1.2 基于視覺詞元(token)的模型:將圖像壓縮為離散視覺詞元序列,如 VQ-VAE 及其變體。
這類模型先使用編碼器將圖像映射到潛在空間并量化為離散代碼,再用解碼器重建圖像。在此基礎上,采用強大的自回歸模型預測下一個離散視覺詞元。例如,VQ-VAE 通過向量量化將圖像編碼為離散的視覺詞元序列,然后使用自回歸模型對視覺詞元序列進行建模,實現圖像的生成和重建。但是這類模型存在碼本利用率低和采樣速度慢的問題。碼本中的視覺詞元可能沒有被充分利用,導致生成的圖像質量受限。同時,由于需要依次預測每個視覺詞元,采樣速度相對較慢。
2.1.3 基于尺度(scale)的模型:以不同尺度的視覺詞元圖作為自回歸單元,如 VAR。通過多尺度量化自動編碼器將圖像離散化為視覺詞元學習不同分辨率的信息,生成過程從粗到細逐步進行。例如,VAR 首先在低分辨率下生成粗糙的視覺詞元圖,然后逐步細化到高分辨率,從而提高生成圖像的質量和效率。相比基于視覺詞元的模型,它能更好地保留空間局部性,提高視覺詞元生成效率。通過多尺度的建模方式,可以更好地捕捉圖像的局部結構和細節信息。
不同的通用框架分類各有特點,而自回歸模型與其他生成模型也有著緊密的關系。接下來,我們探討自回歸模型與其他生成模型的關系。
2.3 與其他生成模型的關系
自回歸模型與變分自編碼器(VAEs)、生成對抗網絡(GANs)、歸一化流、擴散模型和掩碼自編碼器(MAEs)等生成模型在不同方面有著聯系和區別。
變分自編碼器(VAEs):VAEs 學習將數據映射到低維潛在空間并重建,而自回歸模型直接捕捉數據分布。兩者結合的方法如 VQ-VAE,能有效利用兩者優勢進行圖像合成。VQ-VAE 首先通過編碼器將圖像映射到潛在空間,然后使用向量量化將潛在空間離散化為視覺詞元序列,最后使用自回歸模型對視覺詞元序列進行建模,實現圖像的生成和重建。
生成對抗網絡(GANs):GANs 生成速度快,但訓練不穩定且可能出現模式崩潰。自回歸模型采用似然訓練,過程穩定,雖采樣速度慢,但模型性能隨數據和模型規模提升。在圖像生成任務中,GANs 可以快速生成逼真的圖像,但可能會出現模式崩潰的問題,即生成的圖像缺乏多樣性。自回歸模型則可以通過似然訓練保證生成的圖像具有較高的質量和多樣性。
歸一化流 (Normalizing Flows):通過一系列可逆變換將簡單分布映射到復雜數據分布,與自回歸模型都可通過最大似然估計直接優化。但歸一化流需保證可逆性,自回歸模型則通過離散化數據和順序預測更具靈活性。歸一化流需要設計可逆的變換函數,這在實際應用中可能會比較困難。而自回歸模型可以通過離散化數據和順序預測的方式,更加靈活地捕捉數據的分布特征。
擴散模型 (Diffusion Models):與自回歸模型類似,兩類模型都能生成高質量樣本,但是兩者在生成范式上有根本區別。當前自回歸模型已經逐漸在性能上追趕上擴散模型,且展現了很好的scaling到更大模型的潛力。近期研究嘗試結合兩者的優勢,進一步提高生成模型的性能。
掩碼自編碼器(MAEs):MAEs 通過隨機掩碼輸入數據并重建來學習數據表示,與自回歸模型有相似之處,但訓練方式和注意力機制不同。例如,MAEs 在訓練時隨機掩碼一部分輸入數據,然后通過重建被掩碼的部分來學習數據的表示。自回歸模型則是通過順序預測的方式來學習數據的分布。兩者在訓練方式和注意力機制上存在差異。
3.視覺自回歸模型的應用
自回歸模型在圖像生成、視頻生成、3D 生成和多模態生成等任務中都有著廣泛的應用。結合經典的和最新的相關工作,我們做出以下的分類,感興趣的讀者可以在論文中閱讀每個子類的詳情。
3.1 圖像生成
- 無條件圖像生成:像素級生成逐個像素構建圖像,如 PixelRNN 和 PixelCNN 等。視覺詞元級生成將圖像視為視覺詞元序列,如 VQ-VAE 及其改進方法。尺度級生成從低到高分辨率逐步生成圖像,如 VAR。
- 文本到圖像合成:根據文本條件生成圖像,如 DALL?E、CogView 等。近期研究還探索了與擴散模型、大語言模型的結合,以及向新任務的擴展。
- 圖像條件合成:包括圖像修復、多視圖生成和視覺上下文學習等,如 QueryOTR 用于圖像外繪,MIS 用于多視圖生成,MAE-VQGAN 和 VICL 用于視覺上下文學習。
- 圖像編輯:分為文本驅動和圖像驅動的圖像編輯。文本驅動如 VQGAN-CLIP 和 Make-A-Scene,可根據文本輸入修改圖像。圖像驅動如 ControlAR、ControlVAR 等,通過控制機制實現更精確的圖像編輯。
3.2 視頻生成
- 無條件視頻生成:從無到有創建視頻序列,如 Video Pixel Networks、MoCoGAN 等。近期方法如 LVT、VideoGPT 等結合 VQ-VAE 和 Transformer 提高了生成質量。
- 條件視頻生成:根據特定輸入生成視頻,包括文本到視頻合成、視覺條件視頻生成和多模態條件視頻生成。如 IRC-GAN、CogVideo 等用于文本到視頻合成,Convolutional LSTM Network、PredRNN 等用于視覺條件視頻生成,MAGE 用于多模態條件視頻生成。
- 具身智能:視頻生成在具身智能中用于訓練和增強智能體,如學習動作條件視頻預測模型、構建通用世界模型等。
3.3 3D 生成
在運動生成、點云生成、場景生成和 3D 醫學生成等方面取得進展。如 T2M-GPT 用于運動生成,CanonicalVAE 用于點云生成,Make-A-Scene 用于場景生成,SynthAnatomy 和 BrainSynth 用于 3D 醫學生成。
3.4 多模態:
- 多模態理解框架:通過離散圖像視覺詞元掩碼圖像建模方法學習視覺表示,如 BEiT 及其變體。
- 統一多模態理解和生成框架:將視覺和文本輸出生成相結合,如 OFA、CogView 等早期模型,以及 NEXTGPT、SEED 等近期模型。最近還出現了原生多模態自回歸模型,如 Chameleon 和 Transfusion。
3. 評估指標
評估視覺自回歸模型的性能需要綜合考慮多個方面的指標。我們從視覺分詞器重建和模型生成的角度分別進行度量:
視覺分詞器重建評估:主要關注重建保真度,常用指標包括 PSNR、SSIM、LPIPS 和 rFID 等。例如,PSNR(峰值信噪比)用于衡量重建圖像與原始圖像之間的像素差異,SSIM(結構相似性指數)則考慮了圖像的結構信息和亮度、對比度等因素。
視覺自回歸生成評估:包括視覺質量(如負對數似然、Inception Score、Fréchet Inception Distance 等); 多樣性(如 Precision 和 Recall、MODE Score 等); 語義一致性(如 CLIP Score、R-precision 等); 時間一致性(如 Warping Errors、CLIPSIM-Temp 等); 以人為中心的評估(如人類偏好分數、Quality ELO Score 等)。
另外,我們在論文中總結了自回歸模型、Diffusion、GAN、MAE 等生成方法在四個常用的圖像生成基準上(例如 MSCOCO)的表現,揭示了當前自回歸視覺生成方法與 SOTA 方法的差距。



5. 挑戰與未來工作
自回歸模型在計算機視覺領域雖然取得了一定的成果,但也面臨著一些挑戰:
5.1 視覺分詞器設計:設計能有效壓縮圖像或視頻的視覺分詞器是關鍵挑戰,如 VQGAN 及其改進方法,以及利用層次多尺度特性提高壓縮效果。例如,可以通過改進向量量化算法、引入注意力機制等方式,提高視覺分詞器的性能和壓縮效果。
5.2 離散與連續表征的選擇:自回歸模型傳統上采用離散表示,但連續表示在簡化視覺數據壓縮器訓練方面有優勢,同時也帶來新挑戰,如損失函數設計和多模態適應性。例如,可以探索連續表示下的自回歸模型,設計合適的損失函數,提高模型在多模態數據上的適應性。
5.3 自回歸模型架構中的歸納偏差:探索適合視覺信號的歸納偏差架構,如 VAR 利用層次多尺度視覺詞元化,以及雙向注意力的優勢。例如,可以研究不同的歸納偏差架構對自回歸模型性能的影響,尋找最適合視覺信號的架構。
5.4 下游任務:當前視覺自回歸模型在下游任務上的研究相對滯后,未來需開發能適應多種下游任務的統一自回歸模型。例如,可以將自回歸模型應用于目標檢測、語義分割等下游任務,探索如何提高模型在這些任務上的性能。
6. 總結
本文對計算機視覺中的自回歸模型進行了全面綜述,介紹了自回歸模型的基礎、通用框架分類、與其他生成模型的關系、應用領域、評估指標以及面臨的挑戰和未來工作。自回歸模型在計算機視覺領域具有廣闊的應用前景,但仍需進一步研究解決現有問題,以推動其發展和應用。