MyBatis 批量操作的五個(gè)坑,千萬(wàn)不要踩了!
大家好,我是君哥。
在日常開發(fā)中,為了提高操作數(shù)據(jù)庫(kù)效率,我們往往會(huì)選擇批量操作,比如批量插入、批量更新,這樣可以減少程序和數(shù)據(jù)庫(kù)的交互,減少執(zhí)行時(shí)間。但是批量操作往往隱藏著一些坑,使用不當(dāng),很可能會(huì)造成生產(chǎn)事故。
今天來(lái)分享使用 MyBatis 批量操作可能會(huì)遇到的一些坑。下面我們以一張員工信息表為例進(jìn)行講解,建表 SQL 如下(MySQL):
CREATE TABLE `staff` (
`staff_id` tinyint(3) NOT NULL COMMENT '員工編號(hào)',
`name` varchar(20) DEFAULT NULL COMMENT '員工姓名',
`age` tinyint(3) DEFAULT NULL COMMENT '年齡',
`sex` tinyint(1) DEFAULT '0' COMMENT '性別,0:男 1:女',
`address` varchar(300) DEFAULT NULL COMMENT '家庭住址',
`email` varchar(200) DEFAULT NULL COMMENT '郵件地址',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '創(chuàng)建時(shí)間',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時(shí)間',
PRIMARY KEY (`staff_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf81.查詢條數(shù)
<select id="getStaffList" parameterType="int" resultType="Admin">
select * from staff limit #{offset},50000
</select>對(duì)應(yīng) Java 代碼如下:
public List<Staff> processStaffList(){
int offset = 0;
List<Staff> staffList = staffDao.getStaffList(offset);
while(true){
//...處理邏輯
if(staffList.size() < 10000){
break;
}
offset += 10000;
staffList = staffDao.getStaffList(offset);
}
}上面的查詢想一次想查回 50000 條數(shù)據(jù),很有可能數(shù)據(jù)庫(kù)不能返回 50000 條。一般數(shù)據(jù)庫(kù)都有查詢結(jié)果集限制,比如 MySQL 會(huì)受兩個(gè)參數(shù)的限制:
- max_allowed_packet,返回結(jié)果集大小,默認(rèn) 4M,超過(guò)這個(gè)大小結(jié)果集就會(huì)被截?cái)啵?/li>
- max_execution_time,一次查詢執(zhí)行時(shí)間,默認(rèn)值是 0 表示沒(méi)有限制,如果超過(guò)這個(gè)時(shí)間,MySQL 會(huì)終止查詢,返回結(jié)果。
所以,如果結(jié)果集太大不能全部返回,而我們?cè)诖a中每次傳入的 offset 都是基于上次的 offset 加 50000,那必定會(huì)漏掉部分?jǐn)?shù)據(jù)。
2.分頁(yè)問(wèn)題
<select id="getStaffList" resultType="Staff">
select * from staff limit #{offset},1000
</select>如果單表數(shù)據(jù)量非常大,offset 會(huì)很大造成深度分頁(yè)問(wèn)題,查詢效率低下。我們可以通過(guò)傳入一個(gè)起始的 staffId 來(lái)解決深度分頁(yè)問(wèn)題。
我們修改一下 xml 中的代碼:
<select id="getStaffList" resultType="Staff">
select * from staff
<if test="staffId != null">
WHERE staff_id > #{staffId}
</if>
order by staff_id limit 1000
</select>對(duì)應(yīng) Java 代碼如下:
public List<Staff> processStaffList(){
List<Staff> staffList = staffDao.getStaffList(null);
while(true){
//...處理邏輯
if(staffList.size() < 1000){
break;
}
Staff lastStaffInPage = staffList.get(staffList.size() - 1);
staffList = staffDao.getStaffList(lastStaffInPage.getStaffId());
}
}3.參數(shù)數(shù)量
下面看一下這一條插入 SQL:
<insert id="batchInsertStaff">
INSERT INTO staff (`staff_id`, `name`, `age`, `sex`, `address`, `email`) VALUES
<foreach collection="staffList" index="" item="item" separator=",">
(#{item.staffId,}, #{item.name},#{item.age},#{item.sex},#{item.address},#{item.email})
</foreach>
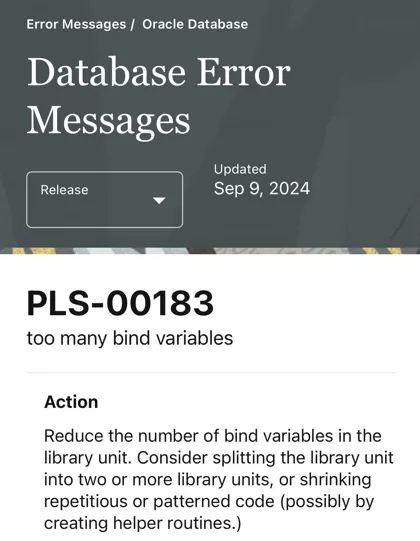
</insert>上面的代碼如果 staffList 數(shù)量太大,會(huì)導(dǎo)致整條語(yǔ)句參數(shù)過(guò)多。如果使用 Oracle 數(shù)據(jù)庫(kù),參數(shù)數(shù)量超過(guò) 65535,會(huì)報(bào) ORA-7445([opiaba]when using more than 65535 bind variables) 的錯(cuò)誤,導(dǎo)致數(shù)據(jù)庫(kù)奔潰。一定要對(duì)參數(shù)數(shù)量進(jìn)行限制。參數(shù)太多,也可能會(huì)拋出下面異常。
4.參數(shù)類型
上一節(jié)的代碼中,插入語(yǔ)句并沒(méi)有指定參數(shù)類型。這樣會(huì)有一個(gè)問(wèn)題,雖然一個(gè)字段我們定義成可以為空,但是通過(guò)參數(shù)傳進(jìn)來(lái)的這個(gè)字段值是空,就會(huì)拋出下面異常導(dǎo)致插入失敗。
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.type.TypeException: Could not set parameters for mapping:
ParameterMapping{property='_frch_item_50.name', mode=IN, javaType=class java.lang.Object, jdbcType=null, numericScale=null, resultMapId='null', jdbcTypeName='null',
expressinotallow='null'}. Cause: org.apache.ibatis.type.TypeException: Error setting null for parameter #5 with JdbcType OTHER .
Try setting a different JdbcType for this parameter or a different jdbcTypeForNull configuration property. Cause: java.sql.SQLException: 無(wú)效的列類型: 1111要保證程序健壯性,就要給插入語(yǔ)句中參數(shù)指定類型,上面代碼優(yōu)化后如下:
<insert id="batchInsertStaff">
INSERT INTO staff (`staff_id`, `name`, `age`, `sex`, `address`, `email`) VALUES
<foreach collection="staffList" index="" item="item" separator=",">
(#{item.staffId,jdbcType=TINYINT}, #{item.name,jdbcType=VARCHAR},#{item.age,jdbcType=TINYINT},#{item.sex,jdbcType=TINYINT},#{item.address,jdbcType=VARCHAR},#{item.email,jdbcType=VARCHAR})
</foreach>
</insert>5.批量條數(shù)
批量操作是為了減少應(yīng)用和數(shù)據(jù)庫(kù)的交互,提高操作效率。但是如果對(duì)插入、更新這些批量操作不做條數(shù)限制,很可能會(huì)導(dǎo)致操作效率低下甚至數(shù)據(jù)庫(kù) hang 住。我們可以通過(guò)分頁(yè)操作對(duì)批量條數(shù)做一些限制,看下面示例代碼:
public List<Staff> processStaffList(){
List<Staff> staffList = ...;
int pageSize = 500;
int pageCount = staffList / pageSize;
for(int i = 0; i < pageCount + 1; i++){
List<Staff> subList = (i == pageCount)? staffList.subList(i * pageSize, staffList.size()) :
staffList.subList(i * pageSize, (i + 1) * pageSize);
staffDao.batchInsertStaff(subList);
}
}總結(jié)
作為一個(gè) orm 框架,無(wú)論我們選擇 JDBC、MyBatis 還是 MyBatis-Plus,批量操作最終都是要操作底層數(shù)據(jù)庫(kù),批次性能怎么樣、會(huì)不會(huì)出問(wèn)題,主要還得參考底層數(shù)據(jù)庫(kù)的能力。因此,想用好批量,首先要了解數(shù)據(jù)庫(kù)的特性。