注意了!Kafka與RabbitMQ千萬(wàn)不要亂用…
作為一個(gè)有豐富經(jīng)驗(yàn)的微服務(wù)系統(tǒng)架構(gòu)師,經(jīng)常有人問(wèn)我,應(yīng)該選擇 RabbitMQ 還是 Kafka?
圖片來(lái)自 Pexels
基于某些原因, 許多開(kāi)發(fā)者會(huì)把這兩種技術(shù)當(dāng)做等價(jià)的來(lái)看待。的確,在一些案例場(chǎng)景下選擇 RabbitMQ 還是 Kafka 沒(méi)什么差別,但是這兩種技術(shù)在底層實(shí)現(xiàn)方面是有許多差異的。
不同的場(chǎng)景需要不同的解決方案,選錯(cuò)一個(gè)方案能夠嚴(yán)重的影響你對(duì)軟件的設(shè)計(jì),開(kāi)發(fā)和維護(hù)的能力。
第一篇文章介紹了 RabbitMQ 和 Apache Kafka 內(nèi)部實(shí)現(xiàn)的相關(guān)概念。本篇文章會(huì)從兩個(gè)方面探討這兩種技術(shù)之間的差異,一個(gè)是這兩種技術(shù)之間的顯著差異,另一個(gè)是對(duì)于軟件架構(gòu)師和開(kāi)發(fā)者需要注意的差異。
我們先來(lái)說(shuō)說(shuō)架構(gòu)模式,也就是我們嘗試著利用這兩種技術(shù)來(lái)實(shí)現(xiàn)的架構(gòu)模式,并且評(píng)估什么時(shí)候該使用哪一個(gè)。
注意 1:如果你對(duì) RabbitMQ 和 Kafka 的內(nèi)部結(jié)構(gòu)還不熟悉,我強(qiáng)烈推薦你閱讀我之前的第一篇文章《講真,應(yīng)該選擇RabbitMQ還是Kafka?》。
如果你不確定,那么可以簡(jiǎn)要的看一下里面的標(biāo)題和圖表,至少對(duì)這些差異有個(gè)大概的了解。
注意 2:上一篇文章發(fā)表之后,有些讀者問(wèn)我對(duì)于 Apache Pulsar 的看法。Pulsar 是另一種類型的消息系統(tǒng),它旨在提供 RabbitMQ 和 Kafka 都有的一些優(yōu)點(diǎn)。
作為一個(gè)現(xiàn)代的消息系統(tǒng),它看上去很有前途;但是像其他平臺(tái)系統(tǒng)一樣,都有各自的優(yōu)缺點(diǎn)。
這邊文章主要是比較 RabbitMQ 和 Kafka,之后我會(huì)嘗試針對(duì) Apache Pulsar 做一個(gè)比較。
RabbitMQ 和 Kafka 的顯著差異
RabbitMQ 是一個(gè)消息代理,但是 Apache Kafka 是一個(gè)分布式流式系統(tǒng)。好像從語(yǔ)義上就可以看出差異,但是它們內(nèi)部的一些特性會(huì)影響到我們是否能夠很好的設(shè)計(jì)各種用例。
例如,Kafka 最適用于數(shù)據(jù)的流式處理,但是 RabbitMQ 對(duì)流式中的消息就很難保持它們的順序。
另一方面,RabbitMQ 內(nèi)置重試邏輯和死信(dead-letter)交換器,但是 Kafka 只是把這些實(shí)現(xiàn)邏輯交給用戶來(lái)處理。
這部分主要強(qiáng)調(diào)在不同系統(tǒng)之間它們的主要差異。
消息順序
對(duì)于發(fā)送到隊(duì)列或者交換器上的消息,RabbitMQ 不保證它們的順序。盡管消費(fèi)者按照順序處理生產(chǎn)者發(fā)來(lái)的消息看上去很符合邏輯,但是這有很大誤導(dǎo)性。
RabbitMQ 文檔中有關(guān)于消息順序保證的說(shuō)明:
“發(fā)布到一個(gè)通道(channel)上的消息,用一個(gè)交換器和一個(gè)隊(duì)列以及一個(gè)出口通道來(lái)傳遞,那么最終會(huì)按照它們發(fā)送的順序接收到。”
——RabbitMQ 代理語(yǔ)義(Broker Semantics)
換話句話說(shuō),只要我們是單個(gè)消費(fèi)者,那么接收到的消息就是有序的。然而,一旦有多個(gè)消費(fèi)者從同一個(gè)隊(duì)列中讀取消息,那么消息的處理順序就沒(méi)法保證了。
由于消費(fèi)者讀取消息之后可能會(huì)把消息放回(或者重傳)到隊(duì)列中(例如,處理失敗的情況),這樣就會(huì)導(dǎo)致消息的順序無(wú)法保證。
一旦一個(gè)消息被重新放回隊(duì)列,另一個(gè)消費(fèi)者可以繼續(xù)處理它,即使這個(gè)消費(fèi)者已經(jīng)處理到了放回消息之后的消息。
因此,消費(fèi)者組處理消息是無(wú)序的,如下表所示:
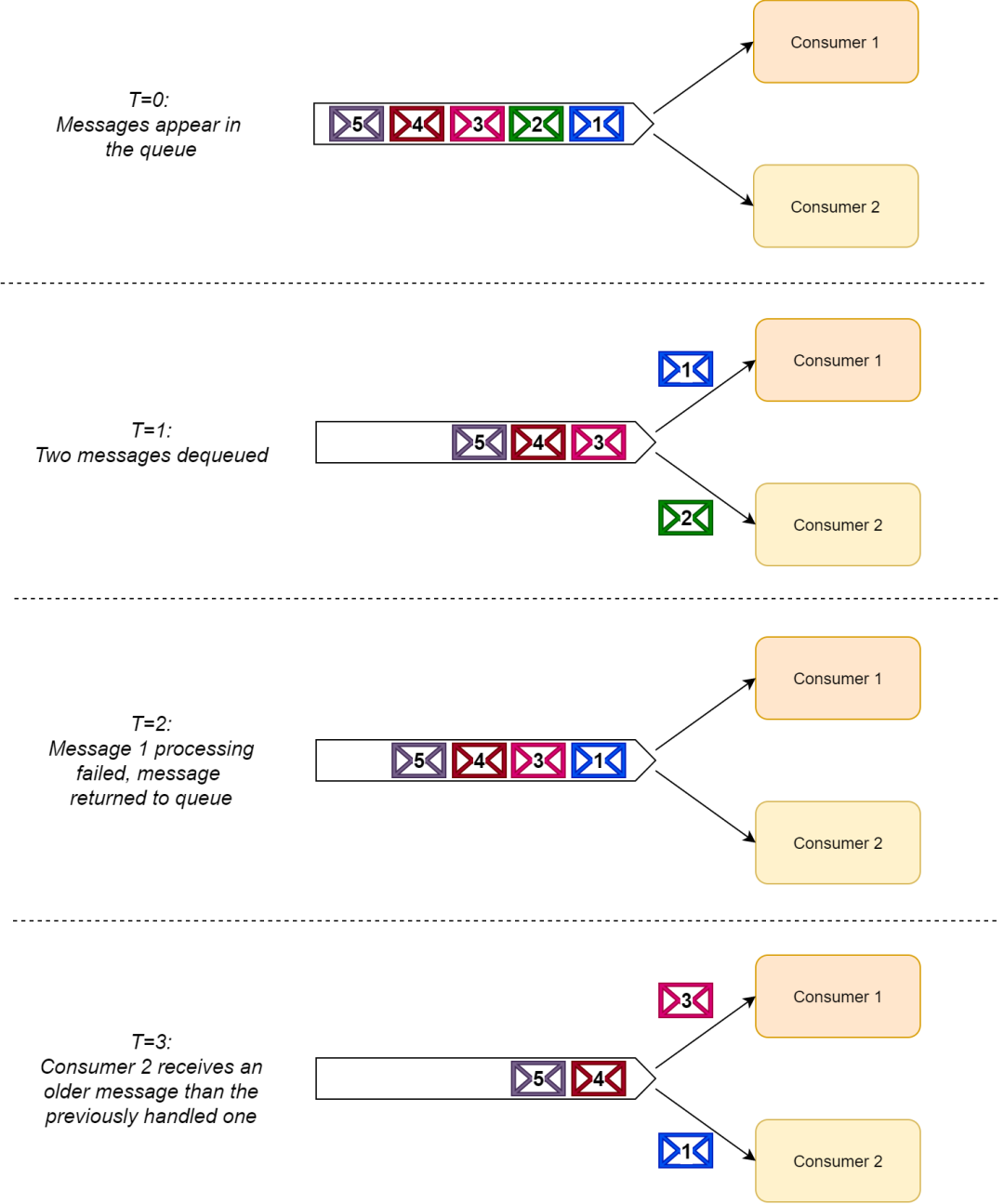
使用 RabbitMQ 丟失消息順序的例子
當(dāng)然,我們可以通過(guò)限制消費(fèi)者的并發(fā)數(shù)等于 1 來(lái)保證 RabbitMQ 中的消息有序性。
更準(zhǔn)確點(diǎn)說(shuō),限制單個(gè)消費(fèi)者中的線程數(shù)為 1,因?yàn)槿魏蔚牟⑿邢⑻幚矶紩?huì)導(dǎo)致無(wú)序問(wèn)題。
不過(guò),隨著系統(tǒng)規(guī)模增長(zhǎng),單線程消費(fèi)者模式會(huì)嚴(yán)重影響消息處理能力。所以,我們不要輕易的選擇這種方案。
另一方面,對(duì)于 Kafka 來(lái)說(shuō),它在消息處理方面提供了可靠的順序保證。Kafka 能夠保證發(fā)送到相同主題分區(qū)的所有消息都能夠按照順序處理。
回顧第一篇文章介紹,默認(rèn)情況下,Kafka 會(huì)使用循環(huán)分區(qū)器(round-robin partitioner)把消息放到相應(yīng)的分區(qū)上。
不過(guò),生產(chǎn)者可以給每個(gè)消息設(shè)置分區(qū)鍵(key)來(lái)創(chuàng)建數(shù)據(jù)邏輯流(比如來(lái)自同一個(gè)設(shè)備的消息,或者屬于同一租戶的消息)。
所有來(lái)自相同流的消息都會(huì)被放到相同的分區(qū)中,這樣消費(fèi)者組就可以按照順序處理它們。
但是,我們也應(yīng)該注意到,在同一個(gè)消費(fèi)者組中,每個(gè)分區(qū)都是由一個(gè)消費(fèi)者的一個(gè)線程來(lái)處理。結(jié)果就是我們沒(méi)法伸縮(scale)單個(gè)分區(qū)的處理能力。
不過(guò),在 Kafka 中,我們可以伸縮一個(gè)主題中的分區(qū)數(shù)量,這樣可以讓每個(gè)分區(qū)分擔(dān)更少的消息,然后增加更多的消費(fèi)者來(lái)處理額外的分區(qū)。
獲勝者:顯而易見(jiàn),Kafka 是獲勝者,因?yàn)樗梢员WC按順序處理消息。RabbitMQ 在這塊就相對(duì)比較弱。
消息路由
RabbitMQ 可以基于定義的訂閱者路由規(guī)則路由消息給一個(gè)消息交換器上的訂閱者。一個(gè)主題交換器可以通過(guò)一個(gè)叫做 routing_key 的特定頭來(lái)路由消息。
或者,一個(gè)頭部(headers)交換器可以基于任意的消息頭來(lái)路由消息。這兩種交換器都能夠有效地讓消費(fèi)者設(shè)置他們感興趣的消息類型,因此可以給解決方案架構(gòu)師提供很好的靈活性。
另一方面,Kafka 在處理消息之前是不允許消費(fèi)者過(guò)濾一個(gè)主題中的消息。一個(gè)訂閱的消費(fèi)者在沒(méi)有異常情況下會(huì)接受一個(gè)分區(qū)中的所有消息。
作為一個(gè)開(kāi)發(fā)者,你可能使用 Kafka 流式作業(yè)(job),它會(huì)從主題中讀取消息,然后過(guò)濾,最后再把過(guò)濾的消息推送到另一個(gè)消費(fèi)者可以訂閱的主題。但是,這需要更多的工作量和維護(hù),并且還涉及到更多的移動(dòng)操作。
獲勝者:在消息路由和過(guò)濾方面,RabbitMQ 提供了更好的支持。
消息時(shí)序(timing)
在測(cè)定發(fā)送到一個(gè)隊(duì)列的消息時(shí)間方面,RabbitMQ 提供了多種能力:
①消息存活時(shí)間(TTL)
發(fā)送到 RabbitMQ 的每條消息都可以關(guān)聯(lián)一個(gè) TTL 屬性。發(fā)布者可以直接設(shè)置 TTL 或者根據(jù)隊(duì)列的策略來(lái)設(shè)置。
系統(tǒng)可以根據(jù)設(shè)置的 TTL 來(lái)限制消息的有效期。如果消費(fèi)者在預(yù)期時(shí)間內(nèi)沒(méi)有處理該消息,那么這條消息會(huì)自動(dòng)的從隊(duì)列上被移除(并且會(huì)被移到死信交換器上,同時(shí)在這之后的消息都會(huì)這樣處理)。
TTL 對(duì)于那些有時(shí)效性的命令特別有用,因?yàn)橐欢螘r(shí)間內(nèi)沒(méi)有處理的話,這些命令就沒(méi)有什么意義了。
②延遲/預(yù)定的消息
RabbitMQ 可以通過(guò)插件的方式來(lái)支持延遲或者預(yù)定的消息。當(dāng)這個(gè)插件在消息交換器上啟用的時(shí)候,生產(chǎn)者可以發(fā)送消息到 RabbitMQ 上,然后這個(gè)生產(chǎn)者可以延遲 RabbitMQ 路由這個(gè)消息到消費(fèi)者隊(duì)列的時(shí)間。
這個(gè)功能允許開(kāi)發(fā)者調(diào)度將來(lái)(future)的命令,也就是在那之前不應(yīng)該被處理的命令。
例如,當(dāng)生產(chǎn)者遇到限流規(guī)則時(shí),我們可能會(huì)把這些特定的命令延遲到之后的一個(gè)時(shí)間執(zhí)行。
Kafka 沒(méi)有提供這些功能。它在消息到達(dá)的時(shí)候就把它們寫(xiě)入分區(qū)中,這樣消費(fèi)者就可以立即獲取到消息去處理。
Kafka 也沒(méi)用為消息提供 TTL 的機(jī)制,不過(guò)我們可以在應(yīng)用層實(shí)現(xiàn)。
不過(guò),我們必須要記住的一點(diǎn)是 Kafka 分區(qū)是一種追加模式的事務(wù)日志。所以,它是不能處理消息時(shí)間(或者分區(qū)中的位置)。
獲勝者:毫無(wú)疑問(wèn),RabbitMQ 是獲勝者,因?yàn)檫@種實(shí)現(xiàn)天然的就限制 Kafka。
消息留存(retention)
當(dāng)消費(fèi)者成功消費(fèi)消息之后,RabbitMQ 就會(huì)把對(duì)應(yīng)的消息從存儲(chǔ)中刪除。這種行為沒(méi)法修改。它幾乎是所有消息代理設(shè)計(jì)的必備部分。
相反,Kafka 會(huì)給每個(gè)主題配置超時(shí)時(shí)間,只要沒(méi)有達(dá)到超時(shí)時(shí)間的消息都會(huì)保留下來(lái)。
在消息留存方面,Kafka 僅僅把它當(dāng)做消息日志來(lái)看待,并不關(guān)心消費(fèi)者的消費(fèi)狀態(tài)。
消費(fèi)者可以不限次數(shù)的消費(fèi)每條消息,并且他們可以操作分區(qū)偏移來(lái)“及時(shí)”往返的處理這些消息。
Kafka 會(huì)周期的檢查分區(qū)中消息的留存時(shí)間,一旦消息超過(guò)設(shè)定保留的時(shí)長(zhǎng),就會(huì)被刪除。
Kafka 的性能不依賴于存儲(chǔ)大小。所以,理論上,它存儲(chǔ)消息幾乎不會(huì)影響性能(只要你的節(jié)點(diǎn)有足夠多的空間保存這些分區(qū))。
獲勝者:Kafka 設(shè)計(jì)之初就是保存消息的,但是 RabbitMQ 并不是。所以這塊沒(méi)有可比性,Kafka 是獲勝者。
容錯(cuò)處理
當(dāng)處理消息,隊(duì)列和事件時(shí),開(kāi)發(fā)者常常認(rèn)為消息處理總是成功的。畢竟,生產(chǎn)者把每條消息放入隊(duì)列或者主題后,即使消費(fèi)者處理消息失敗了,它僅僅需要做的就是重新嘗試,直到成功為止。
盡管表面上看這種方法是沒(méi)錯(cuò)的,但是我們應(yīng)該對(duì)這種處理方式多思考一下。首先我們應(yīng)該承認(rèn),在某些場(chǎng)景下,消息處理會(huì)失敗。
所以,即使在解決方案部分需要人為干預(yù)的情況下,我們也要妥善地處理這些情況。
消息處理存在兩種可能的故障:
- 瞬時(shí)故障:故障產(chǎn)生是由于臨時(shí)問(wèn)題導(dǎo)致,比如網(wǎng)絡(luò)連接,CPU 負(fù)載,或者服務(wù)崩潰。我們可以通過(guò)一遍又一遍的嘗試來(lái)減輕這種故障。
- 持久故障:故障產(chǎn)生是由于永久的問(wèn)題導(dǎo)致的,并且這種問(wèn)題不能通過(guò)額外的重試來(lái)解決。比如常見(jiàn)的原因有軟件 Bug 或者無(wú)效的消息格式(例如,損壞(poison)的消息)
作為架構(gòu)師和開(kāi)發(fā)者,我們應(yīng)該問(wèn)問(wèn)自己:“對(duì)于消息處理故障,我們應(yīng)該重試多少次?每一次重試之間我們應(yīng)該等多久?我們?cè)鯓訁^(qū)分瞬時(shí)和持久故障?”
最重要的是:“所有重試都失敗后或者遇到一個(gè)持久的故障,我們要做什么?”
當(dāng)然,不同業(yè)務(wù)領(lǐng)域有不同的回答,消息系統(tǒng)一般會(huì)給我們提供工具讓我們自己實(shí)現(xiàn)解決方案。
RabbitMQ 會(huì)給我們提供諸如交付重試和死信交換器(DLX)來(lái)處理消息處理故障。
DLX 的主要思路是根據(jù)合適的配置信息自動(dòng)地把路由失敗的消息發(fā)送到 DLX,并且在交換器上根據(jù)規(guī)則來(lái)進(jìn)一步的處理,比如異常重試,重試計(jì)數(shù)以及發(fā)送到“人為干預(yù)”的隊(duì)列。
查看這篇文章[1],它在 RabbitMQ 處理重試上提供了額外的可能模式視角。
在 RabbitMQ 中我們需要記住最重要的事情是當(dāng)一個(gè)消費(fèi)者正在處理或者重試某個(gè)消息時(shí)(即使是在把它返回隊(duì)列之前),其他消費(fèi)者都可以并發(fā)的處理這個(gè)消息之后的其他消息。
當(dāng)某個(gè)消費(fèi)者在重試處理某條消息時(shí),作為一個(gè)整體的消息處理邏輯不會(huì)被阻塞。
所以,一個(gè)消費(fèi)者可以同步地去重試處理一條消息,不管花費(fèi)多長(zhǎng)時(shí)間都不會(huì)影響整個(gè)系統(tǒng)的運(yùn)行。
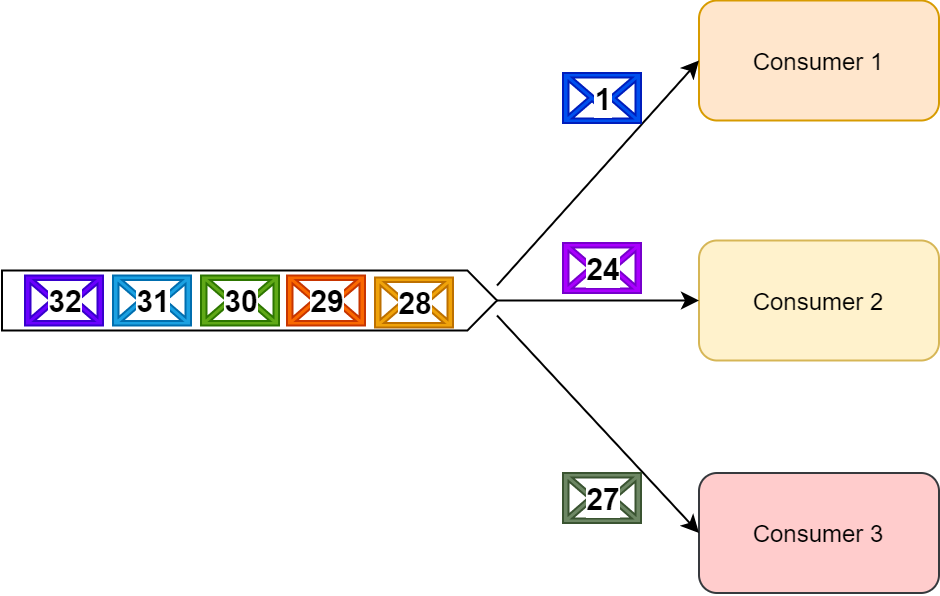
消費(fèi)者 1 持續(xù)的在重試處理消息 1,同時(shí)其他消費(fèi)者可以繼續(xù)處理其他消息
和 RabbitMQ 相反,Kafka 沒(méi)有提供這種開(kāi)箱即用的機(jī)制。在 Kafka 中,需要我們自己在應(yīng)用層提供和實(shí)現(xiàn)消息重試機(jī)制。
另外,我們需要注意的是當(dāng)一個(gè)消費(fèi)者正在同步地處理一個(gè)特定的消息時(shí),那么同在這個(gè)分區(qū)上的其他消息是沒(méi)法被處理的。
由于消費(fèi)者不能改變消息的順序,所以我們不能夠拒絕和重試一個(gè)特定的消息以及提交一個(gè)在這個(gè)消息之后的消息。你只要記住,分區(qū)僅僅是一個(gè)追加模式的日志。
一個(gè)應(yīng)用層解決方案可以把失敗的消息提交到一個(gè)“重試主題”,并且從那個(gè)主題中處理重試;但是這樣的話我們就會(huì)丟失消息的順序。
我們可以在 Uber.com 上找到 Uber 工程師實(shí)現(xiàn)的一個(gè)例子。如果消息處理的時(shí)延不是關(guān)注點(diǎn),那么對(duì)錯(cuò)誤有足夠監(jiān)控的 Kafka 方案可能就足夠了。
如果消費(fèi)者阻塞在重試一個(gè)消息上,那么底部分區(qū)的消息就不會(huì)被處理。
獲勝者:RabbitMQ 是獲勝者,因?yàn)樗峁┝艘粋€(gè)解決這個(gè)問(wèn)題的開(kāi)箱即用的機(jī)制。
伸縮
有多個(gè)基準(zhǔn)測(cè)試,用于檢查 RabbitMQ 和 Kafka 的性能。
盡管通用的基準(zhǔn)測(cè)試對(duì)一些特定的情況會(huì)有限制,但是 Kafka 通常被認(rèn)為比 RabbitMQ 有更優(yōu)越的性能。
Kafka 使用順序磁盤(pán) I/O 來(lái)提高性能。從 Kafka 使用分區(qū)的架構(gòu)上看,它在橫向擴(kuò)展上會(huì)優(yōu)于 RabbitMQ,當(dāng)然 RabbitMQ 在縱向擴(kuò)展上會(huì)有更多的優(yōu)勢(shì)。
Kafka 的大規(guī)模部署通常每秒可以處理數(shù)十萬(wàn)條消息,甚至每秒百萬(wàn)級(jí)別的消息。
過(guò)去,Pivotal 記錄了一個(gè) Kafka 集群每秒處理一百萬(wàn)條消息[2]的例子;但是,它是在一個(gè)有著 30 個(gè)節(jié)點(diǎn)集群上做的,并且這些消息負(fù)載被優(yōu)化分散到多個(gè)隊(duì)列和交換器上。
典型的 RabbitMQ 部署包含 3 到 7 個(gè)節(jié)點(diǎn)的集群,并且這些集群也不需要把負(fù)載分散到不同的隊(duì)列上。這些典型的集群通常可以預(yù)期每秒處理幾萬(wàn)條消息。
獲勝者:盡管這兩個(gè)消息平臺(tái)都可以處理大規(guī)模負(fù)載,但是 Kafka 在伸縮方面更優(yōu)并且能夠獲得比 RabbitMQ 更高的吞吐量,因此這局 Kafka 獲勝。
但是,值得注意的是大部分系統(tǒng)都還沒(méi)有達(dá)到這些極限!所以,除非你正在構(gòu)建下一個(gè)非常受歡迎的百萬(wàn)級(jí)用戶軟件系統(tǒng),否則你不需要太關(guān)心伸縮性問(wèn)題,畢竟這兩個(gè)消息平臺(tái)都可以工作的很好。
消費(fèi)者復(fù)雜度
RabbitMQ 使用的是智能代理和傻瓜式消費(fèi)者模式。消費(fèi)者注冊(cè)到消費(fèi)者隊(duì)列,然后 RabbitMQ 把傳進(jìn)來(lái)的消息推送給消費(fèi)者。RabbitMQ 也有拉取(pull)API;不過(guò),一般很少被使用。
RabbitMQ 管理消息的分發(fā)以及隊(duì)列上消息的移除(也可能轉(zhuǎn)移到 DLX)。消費(fèi)者不需要考慮這塊。
根據(jù) RabbitMQ 結(jié)構(gòu)的設(shè)計(jì),當(dāng)負(fù)載增加的時(shí)候,一個(gè)隊(duì)列上的消費(fèi)者組可以有效的從僅僅一個(gè)消費(fèi)者擴(kuò)展到多個(gè)消費(fèi)者,并且不需要對(duì)系統(tǒng)做任何的改變。
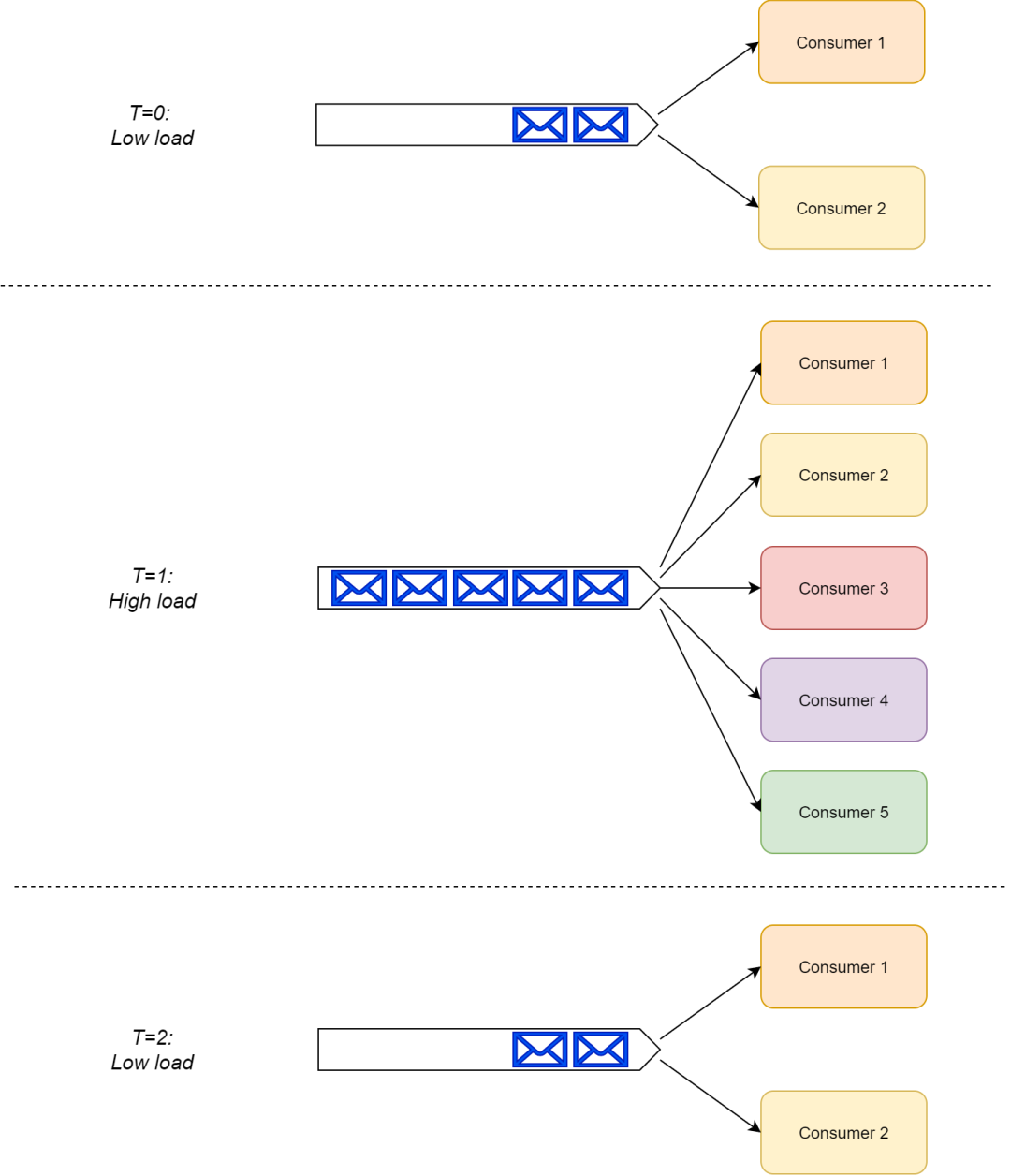
RabbitMQ 高效的伸縮
相反,Kafka 使用的是傻瓜式代理和智能消費(fèi)者模式。消費(fèi)者組中的消費(fèi)者需要協(xié)調(diào)他們之間的主題分區(qū)租約(以便一個(gè)具體的分區(qū)只由消費(fèi)者組中一個(gè)消費(fèi)者監(jiān)聽(tīng))。
消費(fèi)者也需要去管理和存儲(chǔ)他們分區(qū)偏移索引。幸運(yùn)的是 Kafka SDK 已經(jīng)為我們封裝了,所以我們不需要自己管理。
另外,當(dāng)我們有一個(gè)低負(fù)載時(shí),單個(gè)消費(fèi)者需要處理并且并行的管理多個(gè)分區(qū),這在消費(fèi)者端會(huì)消耗更多的資源。
當(dāng)然,隨著負(fù)載增加,我們只需要伸縮消費(fèi)者組使其消費(fèi)者的數(shù)量等于主題中分區(qū)的數(shù)量。這就需要我們配置 Kafka 增加額外的分區(qū)。
但是,隨著負(fù)載再次降低,我們不能移除我們之前增加的分區(qū),這需要給消費(fèi)者增加更多的工作量。
盡管這樣,但是正如我們上面提到過(guò),Kafka SDK 已經(jīng)幫我們做了這個(gè)額外的工作。
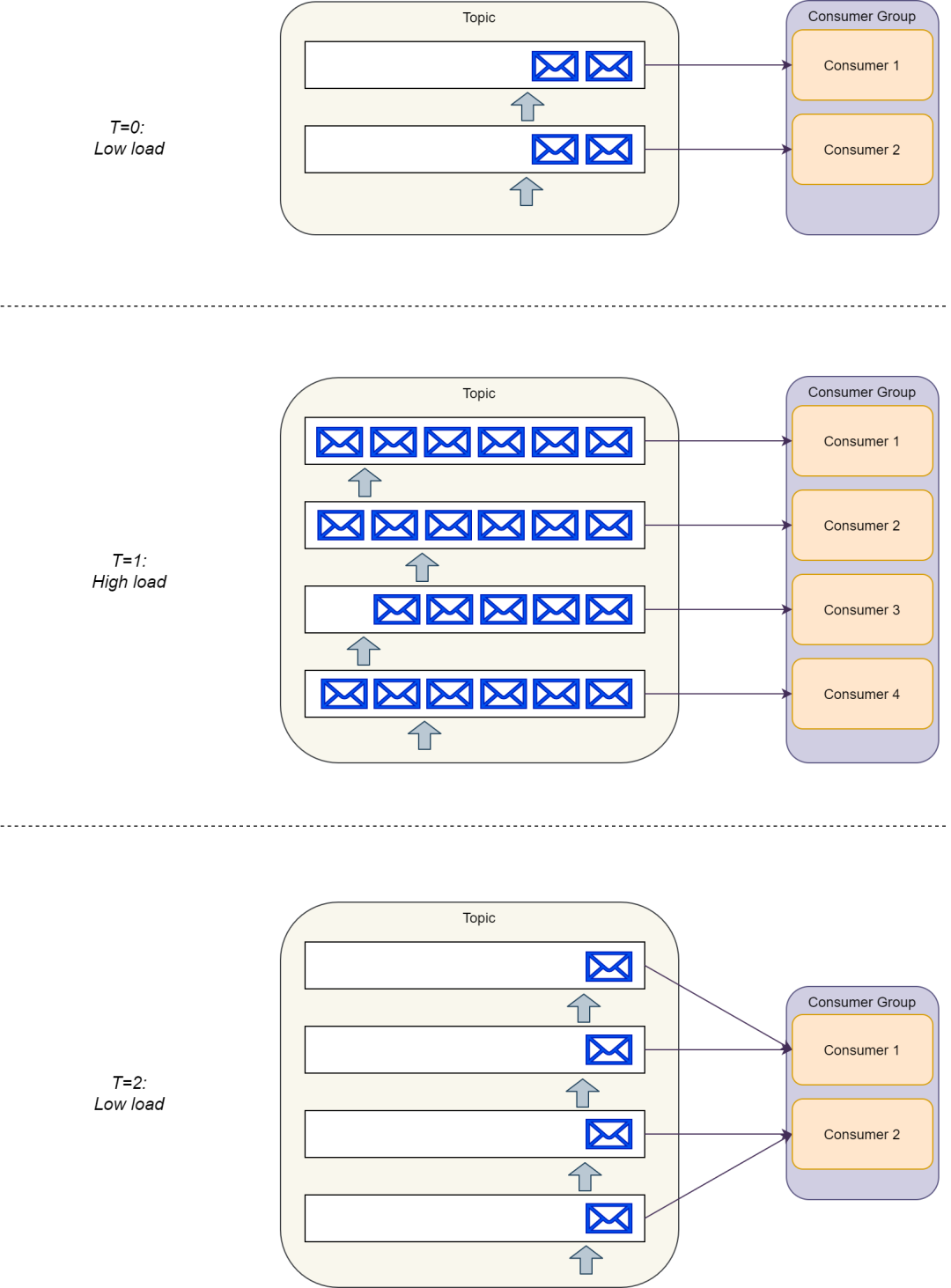
Kafka 分區(qū)沒(méi)法移除,向下伸縮后消費(fèi)者會(huì)做更多的工作
獲勝者:根據(jù)設(shè)計(jì),RabbitMQ 就是為了傻瓜式消費(fèi)者而構(gòu)建的。所以這輪 RabbitMQ 獲勝。
如何選擇?
現(xiàn)在我們就如面對(duì)百萬(wàn)美元問(wèn)題一樣:“什么時(shí)候使用 RabbitMQ 以及什么時(shí)候使用 Kafka?”概括上面的差異,我們不難得出以下結(jié)論:
優(yōu)先選擇 RabbitMQ 的條件:
- 高級(jí)靈活的路由規(guī)則
- 消息時(shí)序控制(控制消息過(guò)期或者消息延遲)
- 高級(jí)的容錯(cuò)處理能力,在消費(fèi)者更有可能處理消息不成功的情景中(瞬時(shí)或者持久)
- 更簡(jiǎn)單的消費(fèi)者實(shí)現(xiàn)
優(yōu)先選擇 Kafka 的條件:
- 嚴(yán)格的消息順序
- 延長(zhǎng)消息留存時(shí)間,包括過(guò)去消息重放的可能
- 傳統(tǒng)解決方案無(wú)法滿足的高伸縮能力
大部分情況下這兩個(gè)消息平臺(tái)都可以滿足我們的要求。但是,它取決于我們的架構(gòu)師,他們會(huì)選擇最合適的工具。
當(dāng)做決策的時(shí)候,我們需要考慮上面著重強(qiáng)調(diào)的功能性差異和非功能性限制。
這些限制如下:
- 當(dāng)前開(kāi)發(fā)者對(duì)這兩個(gè)消息平臺(tái)的了解
- 托管云解決方案的可用性(如果適用)
- 每種解決方案的運(yùn)營(yíng)成本
- 適用于我們目標(biāo)棧的 SDK 的可用性
當(dāng)開(kāi)發(fā)復(fù)雜的軟件系統(tǒng)時(shí),我們可能被誘導(dǎo)使用同一個(gè)消息平臺(tái)去實(shí)現(xiàn)所有必須的消息用例。
但是,從我的經(jīng)驗(yàn)看,通常同時(shí)使用這兩個(gè)消息平臺(tái)能夠帶來(lái)更多的好處。
例如,在一個(gè)事件驅(qū)動(dòng)的架構(gòu)系統(tǒng)中,我們可以使用 RabbitMQ 在服務(wù)之間發(fā)送命令,并且使用 Kafka 實(shí)現(xiàn)業(yè)務(wù)事件通知。
原因是事件通知常常用于事件溯源,批量操作(ETL 風(fēng)格),或者審計(jì)目的,因此 Kafka 的消息留存能力就顯得很有價(jià)值。
相反,命令一般需要在消費(fèi)者端做額外處理,并且處理可以失敗,所以需要高級(jí)的容錯(cuò)處理能力。
這里,RabbitMQ 在功能上有很多閃光點(diǎn)。以后我可能會(huì)寫(xiě)一篇詳細(xì)的文章來(lái)介紹,但是你必須記住:你的里程(mileage)可能會(huì)變化,因?yàn)檫m合性取決于你的特定需求。
總結(jié)
寫(xiě)這兩篇文章是由于我觀察到許多開(kāi)發(fā)者把這 RabbitMQ 和 Kafka 作為等價(jià)來(lái)看待。
我希望通過(guò)這兩篇文章的幫助能夠讓你獲得對(duì)這兩種技術(shù)實(shí)現(xiàn)的深刻理解以及它們之間的技術(shù)差異。
反過(guò)來(lái)通過(guò)它們之間的差異來(lái)影響這兩個(gè)平臺(tái)去給用例提供更好的服務(wù)。這兩個(gè)消息平臺(tái)都很棒,并且都能夠給多個(gè)用例提供很好的服務(wù)。
但是,作為解決方案架構(gòu)師,取決于我們對(duì)每一個(gè)用例需求的理解,以及優(yōu)化,然后選擇最合適的解決方案。
相關(guān)鏈接:
- https://engineering.nanit.com/rabbitmq-retries-the-full-story-ca4cc6c5b493
- https://content.pivotal.io/blog/rabbitmq-hits-one-million-messages-per-second-on-google-compute-engine