為什么都用哈希? Hash 表認知
Hash 表的時間復雜度為什么是 O(1)
講 Hash 之前,簡單聊聊數組(直接尋址表)
數組
數組是內存中一塊連續的空間,并且數組中必須存放相同的類型,所以存放數組只需要記住 首地址的位置就可以,而且數組的長度必須是定長。
以 int 數據類型為例,每個 int 占 4 字節內存空間,所以對一個一個長度單位為 5 的整形數組,所占用的字節為 4*5=20 字節,知道首地址,數組每個元素定長,可以輕易算出每個數據的內存下標地址。
+------------+------------+------------+------------+------------+
| arr[0] | arr[1] | arr[2] | arr[3] | arr[4] |
+------------+------------+------------+------------+------------+
| 內存地址 1 | 內存地址 2 | 內存地址 3 | 內存地址 4 | 內存地址 5 |
+------------+------------+------------+------------+------------+在這個例子中,arr[0] 存儲在內存地址1,arr[1] 存儲在內存地址2,依此類推。每個元素之間的間隔是4個字節(一個整數的大小)。
這樣,通過首地址和元素的大小,我們可以計算出數組中任意元素的內存地址。
數組的首地址假設為 base_address = 1000,那么:
- arr[0] 的地址是 base_address
- arr[1] 的地址是 base_address + 4
- arr[2] 的地址是 base_address + 8
- arr[3] 的地址是 base_address + 12
- arr[4] 的地址是 base_address + 16
所以只讀取數組元素的時候,可以直接通過下標,也就是索引進行讀取,即我們常講的直接尋址,時間復雜度為 O(1). 所以在算法導論中也會把數組稱為直接尋址表
隨機快速讀寫是數組的一個特性,在 Java 中有個 標志性接口 RandomAccess 用于表示此類特性,比如我們經常用的 ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
.......
}這也是常講 對于 ArrayList 來說 通過索引訪問要優于通過迭代器訪問。知道索引下標后,下標乘以元素大小,再加上數組的首地址,就可以獲得目標訪問地址,直接獲取數據。通過迭代器方法,需要通過方法先獲取索引,中間多了一步,并且最好指定初始容量,數組定長,所以每一次的擴容都要進行一次數組拷貝
在數組的情況下,由于元素是連續存儲的,序列化過程可以直接將整個內存塊復制到磁盤或網絡中,這樣可以減少 CPU 的開銷,提高效率。所以數組尤其適合于需要高性能數據傳輸的場景。
相比在鏈表中,由于節點是分散存儲的,序列化時必須遍歷每一個節點,將其值逐個寫入到連續的內存中,這樣不僅需要更多的計算時間,還可能在內存分配上引入額外的開銷。
Hash 表
回頭來看 Hash 表,數組可以直接尋址,但是缺點很明顯,必須定長,元素大小相等,實際中使用的時候,往往可能不知道需要多長,希望是一個動態集合。
這個時候可以定義一個很大的數組,但是存在一種情況,當要存放的元素遠遠小于定義某個長度的數組的時候,就會造成資源浪費。
所以我們需要一種數據結構來實現上面的功能,可以根據要放的元素動態的定義數組的大小,這也就是哈希表,算法導論中也叫散列表。
索引計算
哈希表會通過哈希函數把要放的元素轉換為一個哈希值,往往是一個 Int 型 的數值,如何得到索引,最簡單的方法就是余數法,使用 Hash 表的數組長度對哈希值求余, 余數即為 Hash 表數組的下標,使用這個下標就可以直接訪問得到 Hash 表中存儲的數據。。每次讀寫元素的時候會計算哈希值得到索引然后讀寫。
因為哈希函數的執行時間是常量,數組的隨機訪問也是常量,時間復雜度就是 O(1)。
在編程語言中,為了避免哈希沖突,會對哈希函數的數據做進一步處理,對于 Java 來講,HashMap 的 hash 方法接收一個 Object 類型的 key 參數,然后根據 key 的 hashCode() 方法計算出的哈希值 h。
然后會執行位運算 h >>> 16(將 h 的高 16 位右移 16 位),然后將結果與原始哈希值 h 進行異或操作(^),最后返回計算得到的哈希值。
Java 的 HashSet 也是基于 HashMap 的只是 Val 做了單獨處理。
下面為 HashMap 的擾動函數
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}Object 的 哈希函數是一個原生的方法,即由 JVM 提供,可能通過 C 或者 C++ 實現。
public native int hashCode();通過一個具體的例子來解釋 Java 中 HashMap 的 hash 方法是如何工作的,以及為什么通過對原始哈希值的高 16 位和低 16 位進行異或操作可以減少哈希沖突
假設我們有一個字符串鍵 "example",其 hashCode() 方法返回的原始哈希值為 1047298352 一個 int 值.
即4字節32 位: 0011 1110 0110 1100 1000 0001 0011 0000
原始哈希值:h = 1047298352
- 高 16 位:0011 1110 0110 1100(二進制)
- 低 16 位:1000 0001 0011 0000(二進制)
右移操作:h >>> 16,高位填0,原來的高位變低位
- 結果:0000 0000 0000 0000 0011 1110 0110 1100(二進制)
- 這個操作將原始哈希值的高位信息“復制”到了低位。
異或操作:h ^ (h >>> 16)
- 結果:1047298352 ^ 15980 = 1047560497(十進制)=00111110011011001011111101011100 (二進制)
- 異或操作將高位的信息混合到了低位,使得高位的變化能夠影響到低位。
通過對原始哈希值的高 16 位和低 16 位進行異或操作,HashMap 的 hash 方法試圖達到以下目的:
- 均勻分布:這種混合操作有助于在哈希表中更均勻地分布鍵,因為高位的變化現在能夠影響到低位,從而減少了只依賴低位導致的分布不均。
- 減少沖突:由于高位信息現在也被考慮在內,因此具有相似高位但不同低位的鍵更有可能產生不同的哈希值,從而減少了哈希沖突的可能性。
當調用 putVal 方法插入鍵值對時,會傳入通過 hash 方法計算得到的哈希值作為 hash 參數,然后計算索引
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);這里的 n 為數組的長度,那么數組長度如何確定?
長度計算
索引的問題解決了,那么長度是如何解決的,我們知道既然使用數組,那么一定是定長才行
和 ArrayList 類似,在Java中,Hash 表的長度是有一個一個默認長度的,當負載因子超過閾值時會自動擴容,擴容同樣涉及數組拷貝,哈希值計算。所以一般也需要指定初始容量。
所以 Java 中在創建 HashMap 時,會根據初始容量和負載因子來確定實際的對象數組大小。需要注意 HashMap 的內部實現會確保實際容量為最接近且大于或等于給定初始容量的 2 的冪次方。這樣可以充分利用位運算的優勢,提高哈希表的性能。
實際中指定初始容量后還會進行進一步的運算,例如,如果初始容量為 16,實際對象數組大小將為 16;如果初始容量為 17,實際對象數組大小將為 32(最接近且大于 17 的 2 的冪次方)。
計算方式通過下面的函數:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}獲取到長度之后,通過下面的方式獲取索引。
index = hash_value & (table_size - 1)可以看到在 Java 中,這里使用了位運算,而不是之前我們講的取模運算,
位與運算(bitwise AND)和取模運算(modulo operation,使用%符號)都可以用來將哈希值映射到哈希表的索引范圍內,但它們的工作原理和適用場景有所不同。
位與運算(bitwise AND) ,當哈希表的大小是2的冪時,可以使用位與運算來計算索引,這種方法的優點是速度快,因為它只涉及一次位運算。但是,它要求哈希表的大小必須是2的冪。
取模運算(modulo operation),取模運算可以用于任何大小的哈希表,不僅限于2的冪:
index = hash_value % table_size這也是上面為什么要容量是2的冪,除法運算通常比位運算慢,位運算可以直接映射到硬件層面操作。
那么位運算又是如何計算出索引的?這里的原理是基于二進制的特性以及位運算的規則。
首先,數組的大小是 2 的冪次方,例如 16(2^4)。當數組大小為 2 的冪次方時,它的二進制表示形式中只有一個位為 1,其余位為 0。例如,16 的二進制表示為 10000。
使用按位與運算(&)計算索引。
對哈希碼和數組大小減 1(例如 15,見上面的公式)進行按位與運算時,實際上是在將哈希碼的二進制表示中的高位全部置為 0,只保留低位的數值。這是因為數組大小減 1 的二進制表示形式中,所有低位都為 1,而高位都為 0。例如,15 的二進制表示為 01111。
使用上面Demo中的數據。
0011 1110 0110 1100 1000 0001 0011 0000(2) 1047298352(擾動前哈希值)
0011 1110 0110 1100 1011 1111 0101 1100(2) 1047560497(擾動后哈希值 h >>> 16)
0000 0000 0000 0000 0000 0000 0000 1111(2) 15(哈希表容量-1)
& ---------------------------------------
0000 0000 0000 0000 0000 0000 0000 0000(2) 0 (擾動前計算的索引)
0000 0000 0000 0000 0000 0000 0000 1100(2) 12(擾動后計算的索引)通過按位與運算,我們可以得到哈希碼的低 4 位(在這個例子中),這些低 4 位就是我們要找的索引值。這個過程相當于對哈希碼進行模運算(取余數),使用位運算來實現會更高效。這里也可以看到擾動函數的作用,利用高位影響低位。
在Java 中當哈希表的元素個數超過容量乘以加載因子(默認為0.75)時,會觸發擴容,擴容會重新計算大小,擴容后的大小為。newCap = oldCap << 1 ,即左移一位,增加當前容量的一倍。
......
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && // 如果擴容后的容量小于最大容量,并且當前容量大于等于默認初始容量
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 將閾值也擴容為原來的兩倍
}
....實際上在 Java 中,,如果類實現了哈希方法,會使用自己覆蓋的哈希方法,如果關鍵字是字符串,會使用 BKDR 哈希算法將其轉換為自然數,再,對它進行求余,就得到了數組下標。
下面為 字符串類 String 覆寫的 哈希函數。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}哈希沖突
當多個不同的元素通過哈希函數生成的哈希值后計算的索引一樣,就會觸發哈希沖突。
我們看一個生產的 Demo,下面為兩個樓宇編碼,需要批量生成每棟樓房間的鎖號,這里我們通過樓宇編碼生成哈希值,拼接到鎖號最前面當樓宇標識。
- 西輔樓: RLD836092851942064128
- 西平房: RLD836132304567926784
這里我們有 8 棟樓宇,所以長度為8.
public static void main(String[] args) {
String b1 = "RLD836092851942064128";
String b2 = "RLD836132304567926784";
int b1i = b1.hashCode() & (8 - 1);
int b2i = b2.hashCode() & (8 - 1);
System.out.println(b1.hashCode()+"| "+b1i);
System.out.println(b2.hashCode()+"| "+b2i);
}可以看到,雖然哈希值不一樣,但是算完的索引一樣,
-652344316| 4
1275548884| 4這兩個字符串都會落到下標 4 中,這就產生了沖突。就會促發哈希沖突,解決辦法一般有兩種:
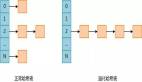
鏈接法(Separate Chaining):
落到數組同一個位置中的多個數據,通過鏈表串在一起。使用哈希函數查找到這個位置后,再使用鏈表遍歷的方式查找數據。Java 中的哈希表就使用鏈接法解決沖突。在 Java8 之后,鏈表節點超過8個自動轉為紅黑樹,小于6個會自動轉為鏈表。
鏈表法即把沖突的元素放到一個鏈表里面,鏈表第一個元素地址放到哈希表索引的元素位置。
所以說最壞的情況下,即所有的元素都哈希沖突,時間復雜度為鏈表的時間復雜度 O(n).
- 優點:
實現簡單,容易處理動態擴容。
允許負載因子大于1,能夠處理更多的元素。
可以靈活應對哈希沖突,即使哈希表中的桶很少也能保持性能。
- 缺點:
需要額外的內存用于指針存儲,因此每個桶可能需要額外的空間,這導致內存使用不連續。
在序列化時,指針和內存的不連續性會導致效率降低,尤其是在需要將整個哈希表序列化并存儲到文件時,可能需要更多的時間來處理指針和數據結構。
空桶可能會浪費空間。
開放尋址法
插入時若發現對應的位置已經占用,或者查詢時發現該位置上的數據與查詢關鍵字不同,開放尋址法會按既定規則變換哈希函數(例如哈希函數設為 H(key,i),順序地把參數 i 加 1),計算出下一個數組下標,繼續在哈希表中探查正確的位置,
- 優點:
所有的元素都存儲在數組中,避免了指針導致的內存不連續問題。
序列化效率較高,可以直接將內存中的數組映射到磁盤(如 Linux 的 mmap 機制),這對于大規模數據的備份非常高效。
操作系統的內存映射機制自動處理數據的同步,但為了保證數據一致性和準確性,可能還需要顯式調用 msync 來確保內存內容被寫入磁盤。
- 缺點:
需要考慮負載因子,如果填充太滿,性能會顯著下降,特別是插入和刪除操作可能會退化為線性時間。
如果哈希表太大,擴展時可能會涉及到大量數據的重新計算和復制。
public void put(String key) {
int index = hash(key);
while (table[index] != null) { // 線性探測
index = (index + 1) % capacity; // 循環處理
}
table[index] = key;
}實際中可能還要做容量檢測,避免死循環。在選擇沖突解決策略時,需要綜合考慮以下因素:
內存使用:如果內存連續性和序列化效率是關鍵,開放尋址法可能更適合,尤其是在需要高效序列化的情況下。鏈接法雖然更靈活,但可能會因為指針和內存不連續性導致序列化和備份成本增加。
數據大小和存儲:對于大型哈希表,應該關注內存布局和存儲策略,采用分塊、壓縮或稀疏存儲等方式來優化序列化過程。
性能和一致性:在使用內存映射等技術時,確保數據的一致性和完整性依然是關鍵,可能需要額外的同步操作。
如何減少哈希沖突
理論上頻繁發生哈希沖突時,會直接影響時間復雜度,所以檢索速度會急劇降低,通過哪些手段減少沖突概率?
- 一是調優哈希函數
- 二是擴容
擴容
裝載因子(當前元素個數/數組容量)越接近于 1,沖突概率就會越大。不能改變元素的數量,只能通過擴容提升哈希桶的數量,減少沖突。
哈希表的擴容會導致所有元素在新數組中的位置發生變化,因此必須在擴容過程中同時保留舊哈希表和新哈希表。擴容時,需要遍歷舊哈希表中的所有元素,并使用新的哈希函數將它們重新放入合適的新哈希桶中。
上面我們講到 Java 中 HashMap 會在數組元素個數超過數組容量的 0.75 進行擴容, 擴容機制與上面類似,擴容后的容量始終為 2的冪,
比如如何 HashMap 的初始容量設置為 100,那么擴容后的容量將按照以下公式計算:
newCapacity = oldCapacity * 2`在這種情況下,oldCapacity 是初始容量 100。但是,HashMap 的容量始終是 2 的冪次方,因此實際的初始容量會被調整為大于或等于 100 的最小的 2 的冪次方,即 128(2^7)。
當 HashMap 需要擴容時,新的容量將是當前容量的兩倍。因此,如果初始容量為 128,擴容后的新容量將是:
newCapacity = 128 * 2 = 256(2^8)所以,初始容量設置為 100,擴容后的容量將為 256。這一過程涉及大量數據操作,擴容是一個極其耗時的操作,尤其在元素數量達到億級時。
所以在初始化的時候制定容量很有必要,會避免多次擴容,同時可以考慮其他的擴容手段,比如漸進式擴容和雙緩存技術.
調優哈希函數
上面我們講到 Java 中 String 類通過 BKDR 哈希算法計算哈希值,這里的 31 為基數,哈希函數為什么基數必須是素數,歡迎小伙伴們留言討論 ^_^
它的計算量很小:n*31 ,實際上可以通過先把 n 左移 5 位,再減去 n 的方式替換,即(n*31 == n<<5 - n),因為理論上位運算通常比乘法運算更快
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = n<<5 - n + val[i];
}
hash = h;
}
return h;
}也可以在除以一個質數,這里 prime 是一個大質數,用于減少哈希沖突。
public class BKDRHash {
private static final int BASE = 31; // 基數
private static final int PRIME = 1000000007; // 質數
public static int hash(String str) {
int hash = 0;
for (int i = 0; i < str.length(); i++) {
hash = (hash * BASE + str.charAt(i)) % PRIME;
}
return hash;
}
}也可以使用其他的哈希算法,或者雙重哈希處理,在分布式場景通過 一致性哈希 來處理數據的均勻分布,分散數據,降低局部密度,提交分布均勻性,減少沖突的概率。
一致性哈希(Consistent Hashing)算法
分布式系統中數據分布和負載均衡會經常使用一種叫 一致性哈希(Consistent Hashing)的技術。用于解決在集群節點變化(如添加或移除節點)時,如何最小化數據遷移的問題(Ceph,Redis )。以及在網絡協議層流量負載均衡如何選擇合適的后端節點(haproxy)。
一致性哈希由 哈希環,數據映射,負載均衡 組成
哈希環:
一致性哈希將整個哈希值空間視為一個虛擬的環。每個節點(如服務器)和數據項(如緩存中的數據)都通過哈希函數映射到這個環上。
比如 Redis Cluster 將整個數據集劃分為 16384 個哈希槽。每個鍵通過哈希函數(CRC16)計算出一個哈希值,然后對 16384 取模,得到該鍵對應的哈希槽。每個節點負責一部分哈希槽。
節點和數據映射:
節點和數據項都被哈希到這個環上。數據項被存儲在順時針方向的第一個節點上。例如,如果數據項 A 被哈希到位置 x,而節點 N1 在 x 的順時針方向上,那么 A 就存儲在 N1 上。
負載均衡:
通過將數據均勻地分布在環上,可以實現負載均衡。即使添加或刪除節點,也只會影響到少量數據項的遷移。總體的哈希容量不變,所以計算完的哈希值不會變,只是對 Hash 空間細劃。
一致性哈希的優勢
最小化數據遷移:當節點加入或離開時,只需重新映射少量數據項,而不是重新分配所有數據。這使得系統在擴展或縮減時更為高效。
動態擴展:系統可以在不影響現有數據的情況下動態擴展,增加新的節點或移除舊的節點。
- 當需要增加新的節點時,只需要將新節點插入到環中的適當位置,并將原節點的一部分數據(即一部分哈希空間)遷移到新節點上。
- 同樣地,當需要移除節點時,該節點負責的數據可以遷移到其順時針方向的下游節點上
容錯性:一致性哈希能夠容忍節點的故障,數據可以在節點故障后快速恢復。
實現步驟
- 選擇哈希函數:選擇一個合適的哈希函數,將節點和數據項映射到哈希環上。
- 構建哈希環:使用哈希函數生成節點和數據項的哈希值,并將它們放置在環上。
- 數據存儲:當存儲數據時,計算數據項的哈希值,并在環上找到順時針方向的第一個節點,將數據存儲在該節點上。
- 節點變動:當節點加入或離開時,重新計算受影響的數據項,進行必要的遷移。
以下是一個簡單的一致性哈希的 Python 示例:
import hashlib
class ConsistentHashing:
def __init__(self):
self.ring = {} #鍵和節點的映射
self.sorted_keys = [] # 哈希環,于存儲已經排序好的哈希鍵值
self.nodes_with_weights = {} # 用于存儲節點及其權重信息
def _hash(self, key):
"""
對給定的鍵進行哈希處理,返回一個整數形式的哈希值。
:param key: 要進行哈希的鍵,可以是節點名稱或者數據項名稱等。
:return: 整數形式的哈希值。
"""
return int(hashlib.md5(key.encode('utf-8')).hexdigest(), 16)
def add_node(self, node, weight=1):
"""
向哈希環中添加一個節點。
:param node: 要添加的節點名稱。
:param weight: 節點的權重,默認為1,權重越高,在哈希環上對應的副本數量越多。
"""
replicas = weight * 3 # 簡單根據權重設定副本數量,這里可根據實際需求調整倍數關系
for i in range(replicas):
key = f"{node}:{i}"
hashed_key = self._hash(key)
self.ring[hashed_key] = node
self.sorted_keys.append(hashed_key)
self.nodes_with_weights[node] = weight
self.sorted_keys.sort()
def remove_node(self, node):
"""
從哈希環中刪除一個節點。
:param node: 要刪除的節點名稱。
"""
weight = self.nodes_with_weights.get(node, 1)
replicas = weight * 3
for i in range(replicas):
key = f"{node}:{i}"
hashed_key = self._hash(key)
del self.ring[hashed_key]
self.sorted_keys.remove(hashed_key)
del self.nodes_with_weights[node]
def get_node(self, key):
"""
確定一個數據項應該映射到哪個節點上。
:param key: 數據項的名稱。
:return: 數據項映射到的節點名稱,如果哈希環為空則返回 None。
"""
if not self.ring:
return None
hashed_key = self._hash(key)
for node_key in self.sorted_keys:
if hashed_key <= node_key:
return self.ring[node_key]
# 將數據項映射到了哈希環上第一個節點(按照哈希值從小到大排序后的第一個節點)
return self.ring[self.sorted_keys[0]]
# 示例使用
if __name__ == "__main__":
ch = ConsistentHashing()
# 添加節點及設置不同權重
ch.add_node('Node1', weight=1)
ch.add_node('Node2', weight=2)
ch.add_node('Node3', weight=3)
data_items = ['data1', 'data2', 'data3', 'data4', 'data5', 'data6', 'data7', 'data8', 'data9', 'data10']
for item in data_items:
node = ch.get_node(item)
print(f"{item} 映射到的節點: {node}")
# 模擬刪除一個節點
ch.remove_node('Node2')
print("刪除Node2后:")
for item in data_items:
node = ch.get_node(item)
print(f"{item} 映射到的節點: {node}")輸出結果,可以看到刪除 Node2 之后,Node3 和 Node1 之前映射的數據并有沒有改變,只是原來Node2 的數據被映射到了 Node3
data1 映射到的節點: Node3
data2 映射到的節點: Node1
data3 映射到的節點: Node3
data4 映射到的節點: Node3
data5 映射到的節點: Node1
data6 映射到的節點: Node3
data7 映射到的節點: Node2
data8 映射到的節點: Node1
data9 映射到的節點: Node1
data10 映射到的節點: Node2
刪除Node2后:
data1 映射到的節點: Node3
data2 映射到的節點: Node1
data3 映射到的節點: Node3
data4 映射到的節點: Node3
data5 映射到的節點: Node1
data6 映射到的節點: Node3
data7 映射到的節點: Node3
data8 映射到的節點: Node1
data9 映射到的節點: Node1
data10 映射到的節點: Node3