













2024 十大圖像分割模型
圖像分割是一門教會機器不是以像素,而是以物體、邊界和等待被理解的故事來看待世界的藝術。圖像分割是計算機視覺中的一個關鍵任務,它涉及將圖像分割成多個部分,從而更容易分析圖像內的不同物體或區域。近年來,為了在這一領域實現最先進的性能,開發了許多模型,每個模型都帶來了獨特的優勢。下面,我們探討了2024年的十大圖像分割模型,詳細說明了它們的工作原理、優點和缺點。

1. 由Meta AI開發的Segment Anything Model(SAM)
論文:https://arxiv.org/abs/2304.02643
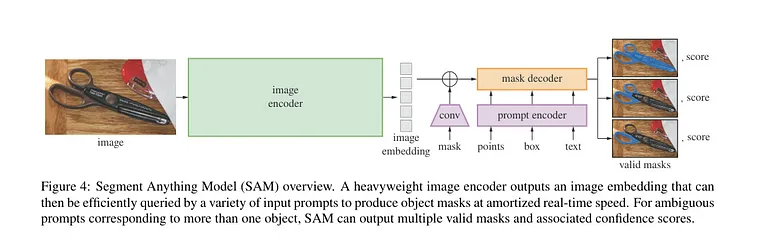
SAM是一個多功能的分割模型,旨在與任何圖像一起工作,允許用戶通過幾次點擊就能執行物體分割。它支持各種類型的輸入提示,如邊界框或文本,使其非常靈活。SAM利用大規模標注圖像數據集,采用基于提示的分割方法。它使用視覺變換器(ViTs)作為骨干,并根據用戶指定的提示適應不同的分割需求。
優點:
- 多功能:可以處理多種類型的分割提示。
- 可擴展:在大規模數據集上預訓練,使其具有很高的泛化能力。
- 快速:接近實時性能,適用于交互式應用。
缺點:
- 高計算需求:訓練和推理需要大量資源。
- 有限的細粒度控制:在復雜圖像中可能難以處理小而精確的細節。
2. 由FAIR開發的DINOv2
論文:https://arxiv.org/abs/2304.07193

DINOv2基于自監督學習,產生高質量的圖像特征,這些特征可以用于分割和其他視覺任務。與其前身不同,DINOv2不需要手動標記的數據進行訓練。DINOv2使用ViT架構,通過自監督學習訓練以理解物體邊界和語義。預訓練后可以微調以用于分割任務。
優點:
- 無標簽依賴:在不需要標記數據集的情況下實現高性能。
- 可轉移特征:可以適應各種下游任務。
缺點:
- 不專門用于分割:需要微調以在分割中獲得最佳性能。
- 潛在過擬合:在微調期間可能在特定數據集上過擬合。
3. Mask2Former
論文:https://arxiv.org/abs/2112.01527
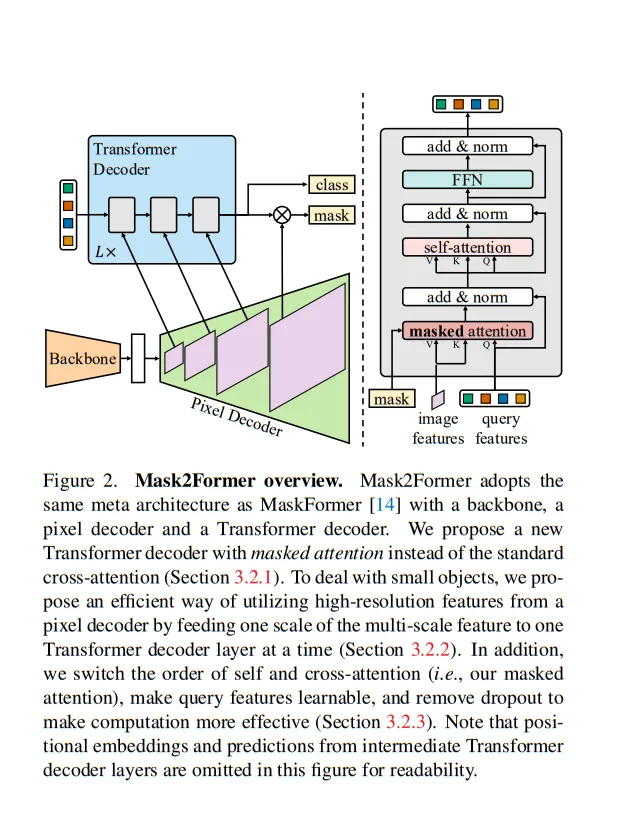
Mask2Former是一個通用的圖像分割模型,將語義分割、實例分割和全景分割任務統一到一個框架中。該模型引入了一個掩碼注意力變換器,其中注意力機制應用于掩碼標記。這使得模型能夠專注于重要區域并相應地進行分割。
優點:
- 統一框架:可以高效處理多種分割任務。
- 高準確度:在各種基準測試中取得了最先進的結果。
缺點:
- 復雜架構:基于變換器的方法資源密集型。
- 訓練難度:需要大量的計算能力進行訓練。
4. Swin Transformer
論文:https://arxiv.org/abs/2103.14030

Swin Transformer是一個為計算機視覺任務設計的層次變換器模型,包括圖像分割。它通過引入移位窗口機制,建立在將變換器用于視覺任務的思想之上。Swin Transformer采用基于窗口的注意力機制,每個窗口處理圖像的局部區域,允許高效且可擴展的分割。
優點:
- 高效注意力:基于窗口的機制減少了計算負荷。
- 層次表示:產生多尺度特征圖,提高分割準確度。
缺點:
- 有限的全局上下文:專注于局部區域,可能錯過全局上下文。
- 復雜性:實現和微調需要高級知識。
5. SegFormer
論文:https://arxiv.org/abs/2105.15203
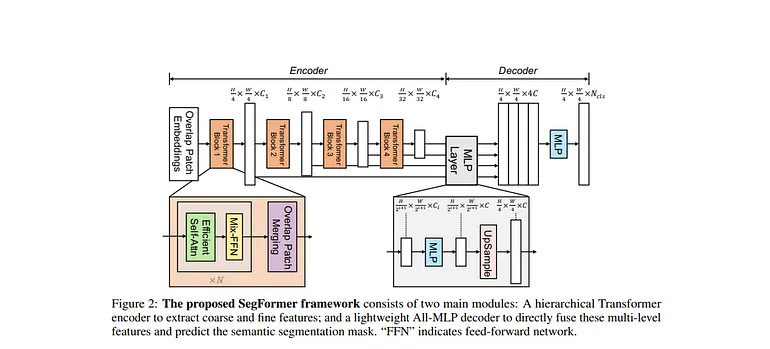
SegFormer是一個簡單而高效的基于變換器的模型,用于語義分割,不依賴于位置編碼,并使用層次架構進行多尺度特征表示。SegFormer將輕量級MLP解碼器與變換器集成,創建多尺度特征層次結構,既提高了性能又提高了效率。
優點:
- 簡單高效:避免了像位置編碼這樣的復雜設計選擇。
- 強大的泛化能力:在各種分割任務中表現良好。
缺點:
- 僅限于語義分割:不如其他一些模型多功能。
- 缺乏細粒度控制:可能在較小的物體上掙扎。
6. MaxViT
論文:https://arxiv.org/abs/2204.01697
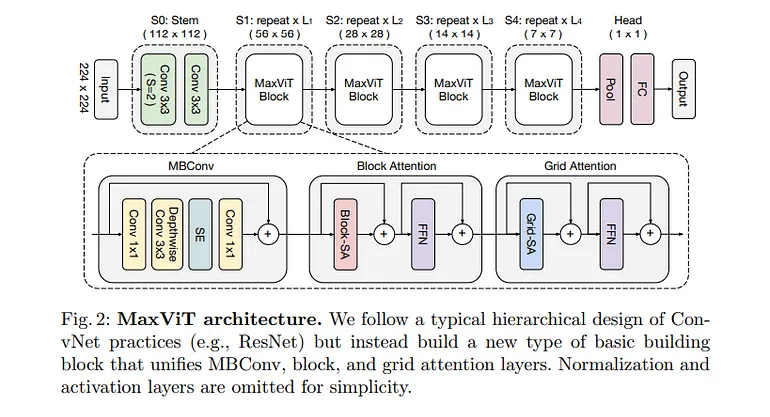
MaxViT引入了一個多軸變換器架構,結合了局部和全局注意力機制,為各種視覺任務,包括分割,提供了強大的結果。MaxViT利用基于窗口和基于網格的注意力,允許模型有效地捕捉局部和全局依賴關系。
優點:
- 全面注意力:在局部和全局特征提取之間取得平衡。
- 多功能:在各種視覺任務中表現良好。
缺點:
- 高復雜性:需要大量的計算資源進行訓練和推理。
- 難以實施:復雜的架構使其在實踐中更難應用。
7. HRNet
論文:https://arxiv.org/pdf/1908.07919v2
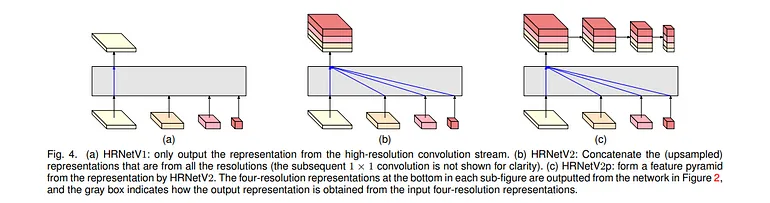
HRNet旨在在整個模型中保持高分辨率表示,與傳統架構不同,后者會下采樣中間特征圖。HRNet使用并行卷積構建高分辨率表示,確保在整個網絡中保留空間信息。
優點:
- 高分辨率輸出:在分割過程中擅長保留細節。
- 強大的性能:在基準測試中始終提供高準確度。
缺點:
- 重型模型:計算成本高且體積大。
- 推理速度慢:比一些更輕的模型慢,因此不太適合實時應用。
8. Deeplabv3+
論文:https://arxiv.org/abs/1802.02611

DeepLabv3+是一個用于語義分割的強大且廣泛使用的模型,它利用了空洞卷積和空間金字塔池化模塊來捕獲多尺度上下文信息。DeepLabv3+在多個速率下應用空洞卷積以捕獲多尺度特征,然后是解碼器模塊用于精確的物體邊界。
優點:
- 高度準確:在語義分割任務中取得了頂級性能。
- 支持良好:在工業和研究中廣泛使用,有多種實現可用。
缺點:
- 資源密集型:需要大量的內存和計算能力。
- 不適合實時應用:與最新模型相比相對較慢。
9. U-Net++
論文:https://arxiv.org/abs/1807.10165
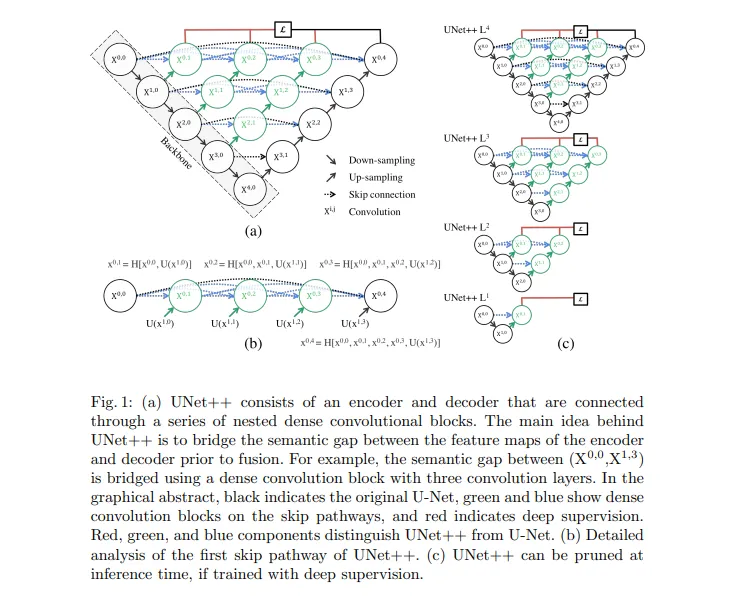
U-Net++是流行的U-Net架構的嵌套版本,旨在提高醫學圖像分割的性能。U-Net++通過一系列嵌套和密集的跳躍連接修改了原始的U-Net,幫助更好地捕獲空間特征。
優點:
- 在醫學應用中強大:專門為醫學圖像分割任務設計。
- 提高準確性:在許多情況下比原始的U-Net取得了更好的結果。
缺點:
- 醫學專注:不如列表中的其他模型通用。
- 資源需求:由于其嵌套架構,需要更多資源。
10. GC-Net(全局上下文網絡)
論文:https://arxiv.org/abs/2012.13375
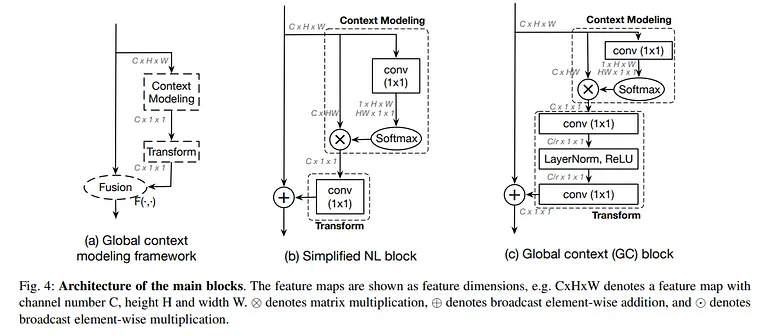
GC-Net引入了一個全局上下文模塊,該模塊捕獲圖像中的長距離依賴關系,使其適用于語義和實例分割任務。全局上下文模塊從整個圖像中聚合上下文信息,允許在復雜場景中更好地分割準確度。GC-Net使用全局上下文塊通過從整個圖像而不是僅局部區域捕獲上下文來增強特征圖。這種全局視圖允許模型更準確地分割物體,特別是在上下文重要的情況下(例如,大型或被遮擋的物體)。
優點:
- 捕獲長距離依賴關系:非常適合分割上下文重要的復雜圖像。
- 高效:盡管功能強大,全局上下文模塊計算效率高,適合各種應用。
缺點:
- 有限的實時應用:盡管效率高,但在需要極快速推理時間的場景中仍可能掙扎。
- 未針對小物體優化:由于其專注于全局上下文,可能在小物體上掙扎。
TIPS: 上述突出顯示的模型代表了2024年的頂級圖像分割,每個模型都提供了針對不同任務和上下文的獨特優勢。從像SAM和Mask2Former這樣的多功能框架到像U-Net++和GC-Net這樣的高度專業化架構,該領域隨著效率和準確性的進步不斷發展。在選擇分割模型時,考慮特定用例和資源限制至關重要。像Swin Transformer和DeepLabv3+這樣的高性能模型提供了出色的準確性,但像SegFormer和GC-Net這樣的更輕、更高效的模型可能更適合實時應用。這個動態且快速發展的領域無疑將繼續看到突破,新模型將推動計算機視覺領域的可能性邊界。






























