實戰SQL:微信、微博等社交網絡的友好、粉絲關系分析
如今,社交軟件已經成為了我們生活必不可少的一部分。相信絕大多數人每天起來,都少不了會打開微信、QQ 刷刷朋友圈,或者打開微博、知乎看看最新熱點。那么,今天我們就來看看這些軟件如何建立網絡社交關系。簡單來說,網絡社交關系主要分為兩類:
- 好友關系。在微信、QQ、Facebook 等軟件中,兩個人可以互加好友,從而和朋友、同事、同學以及周圍的人保持互動交流。
- 粉絲關注。在微博、CSDN、知乎、Twitter 等軟件中,我們可以通過關注成為其他人的粉絲,了解他/她們的最新動態。關注可以是單向的,也可以互相關注。
那么對于微信、微博等這些社交軟件而言,它們如何存儲好友或者關注關系呢?利用這些存儲的數據,我們又能夠進行哪些分析、獲取哪些隱藏的信息呢?
數據結構
社交網絡是一個復雜的非線性結構,通常使用圖(Graph)這種數據結構進行表示。
好友關系圖
對于微信好友這種關系,每個用戶是一個頂點(Vertex);兩個用戶之間互加好友,就會在兩者之間建立一條邊(Edge)。以下是一個簡單的示意圖:
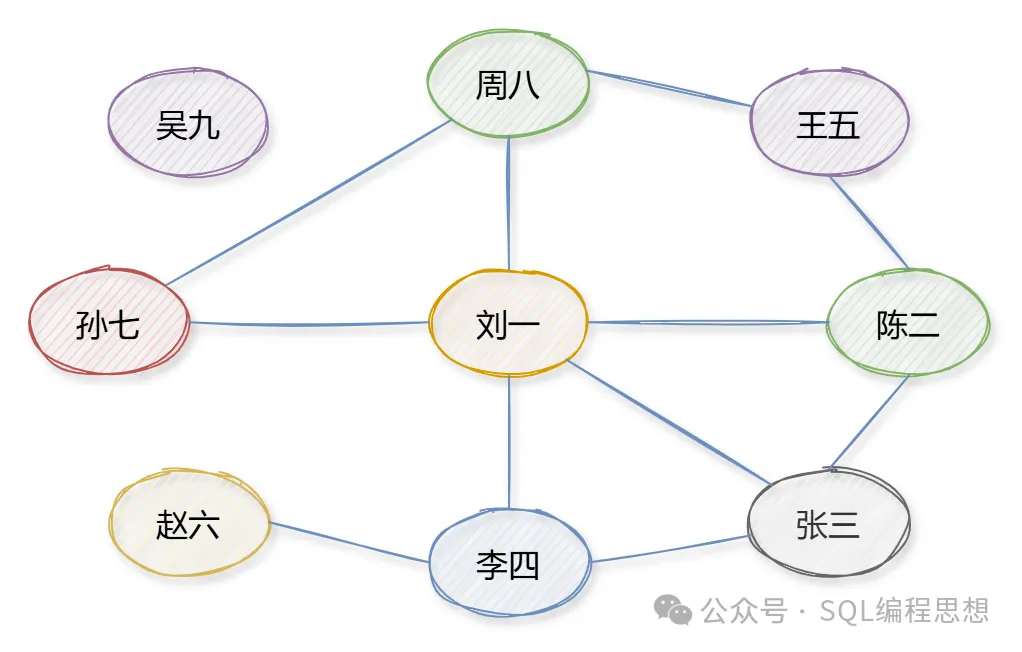
顯然,好友關系是一種無向圖(Undirected Graph);不存在 A 是 B 的好友,但 B 不是 A 的好友。另外,一個用戶有多少個好友,連接到該頂點的邊就有多少條。這個也叫做頂點的度(Degree),上圖中“劉一”的度為 5(微信中表示好友數)。
對于 QQ 中的好友關系而言,還包含了額外的信息,就是好友親密度。這種關系可以使用加權圖(Weighted Graph)表示,其中的邊可以分配一個數字,表示權重。
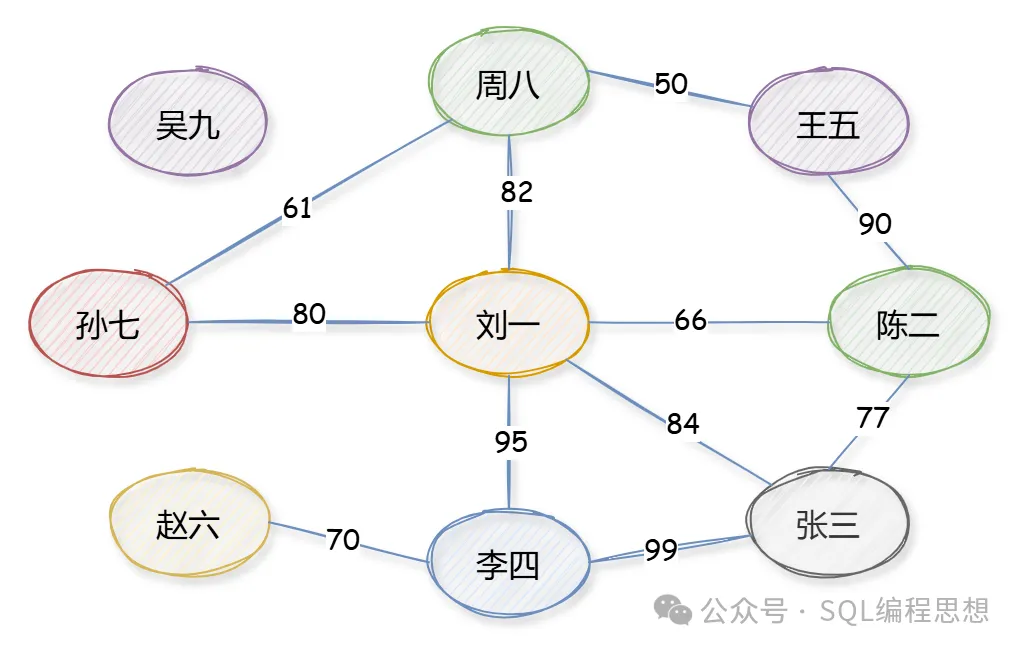
其中,“張三”和“李四”的關系最親密,權重是 99。
加權圖常見的應用還包括飛機航線圖;機場是頂點,航線是邊,邊的權重可以是飛行時間或者機票價格。另一個例子是地鐵換乘路線圖,每個站點是頂點,地鐵軌道是邊,時間是權重。
粉絲關系圖
對于微博這種粉絲關注關系而言,需要使用有向圖(Directed Graph)表示。因為關注是單向關聯,A 關注了 B,但是 B 不一定關注 A。這種有向圖的示意圖如下:
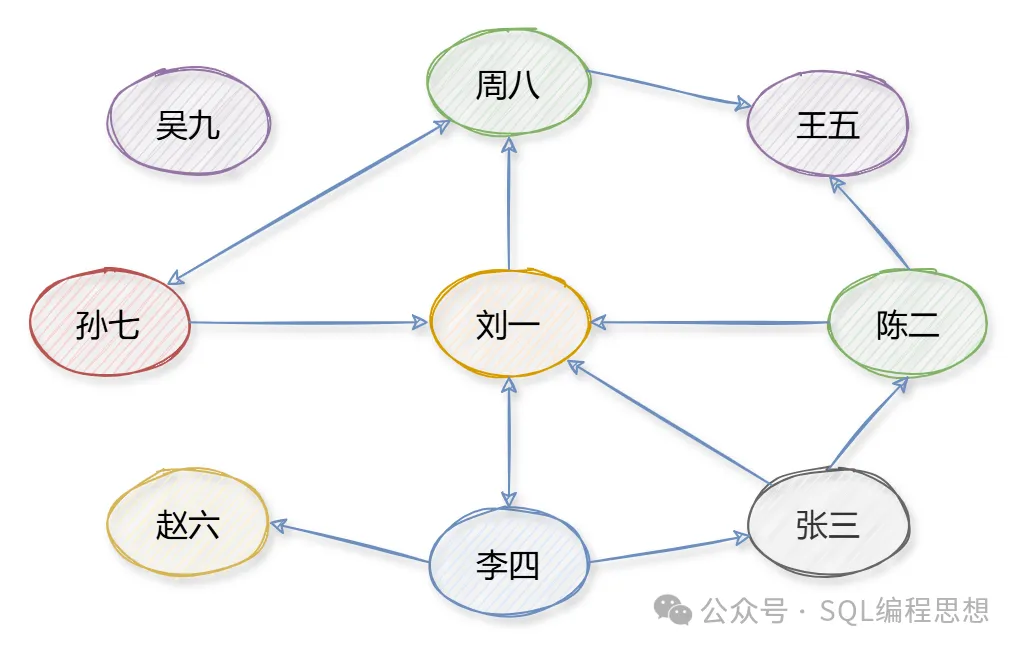
如果 A 關注了 B,圖中就會存在一條從 A 到 B 的帶箭頭的邊。上圖中,“劉一”關注了“周八”,“劉一”和“李四”相互關注。對于有向圖而言,度又分為入度(In-degree)和出度(Out-degree)。入度表示有多少條邊指向該頂點,出度表示有多少條邊是以該頂點為起點。“劉一”的入度為 4(微博中表示粉絲數),出度為 2(微博中表示關注的人數)。
數據存儲
對于圖的存儲而言,我們只要把頂點和邊儲存起來,那么圖的所有信息就保存完整了。所以,一般有兩種存儲結構:鄰接矩陣(Adjacency Matrix)和鄰接列表(Adjacency List)。
鄰接矩陣就是一個二維數組。對于上面的好友關系可以使用下面的矩陣表示:
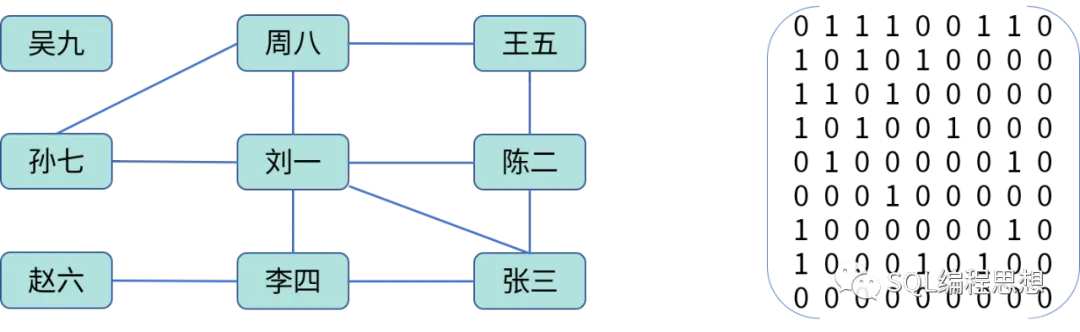
對于無向圖,如果頂點 i 與頂點 j 之間有邊那么 A[i][j] 和 A[j][i] 都為 1;上面的 A[1][2] 表示“劉一”和“陳二”是好友。
對于有向圖,如果存在從頂點 i 指向頂點 j 的邊,那么 A[i][j] 就為 1;如果也存在從頂點 j 指向頂點 i 的邊,那么 A[j][i] 也為 1。對于加權圖,數組中存儲的數字代表了應的權重。
鄰接矩陣雖然方便計算,獲取兩個頂點之間的關系時非常高效,但是存儲空間利用率太低。首先,無向圖中 A[i][j] 和 A[j][i] 表示相同的意義,只需要存儲其中一個;因此浪費了一半的空間。其次,大多數的社交關系都屬于稀疏矩陣(Sparse Matrix),頂點很多但是邊很少。例如,微信用戶數量已經超過 10 億,但是大多數人的好友在幾百人;意味著鄰接矩陣中絕大多數都是零,浪費了大量的存儲空間。
實際上我們能夠在社交網絡穩定交往的人數是大概是 150,參考鄧巴數字。同時,許多社交軟件也設置了好友人數上限,目前普通 QQ 用戶通過 QQ 客戶端添加好友的最高上限1500人。
我們再來看看鄰接列表。上面的粉絲關注可以使用下面的列表描述:
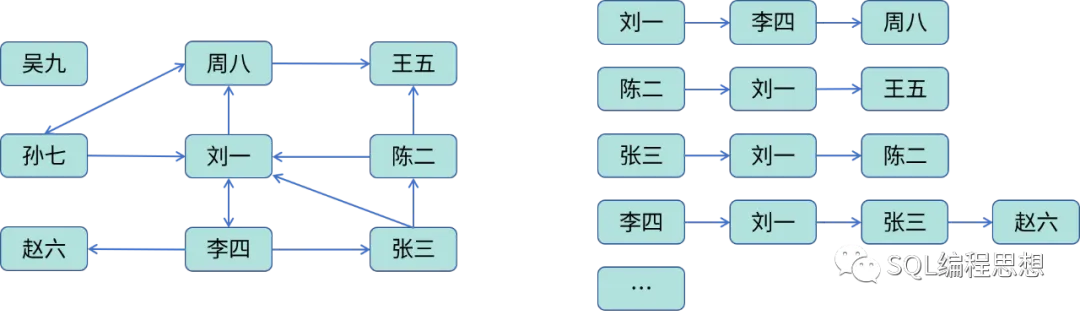
其中,每個頂點都有一個記錄著與它相關的頂點列表。“劉一”關注了“李四”和“周八”,所以上面是一個關注列表。我們也可以創建一個逆向的鄰接列表,存儲了用戶的粉絲。
對于好友關系這種無向圖,可以認為每條邊都是雙向的,同樣可以使用鄰接列表存儲。
鄰接列表的存儲更加高效,大部分操作也更快,例如增加頂點(用戶)、增加邊(增加好友、關注某人);但是查找兩個頂點是否相鄰時,可能需要遍歷整個列表,效率相對低一些。
具體到數據庫,我們可以為頂點創建一個表,為頂點之間的邊創建一個表,從而實現鄰接表模型。以下內容在 MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite 數據庫中進行了驗證。
好友關系分析
我們首先創建一個用戶表和好友關系表:
create table t_user(user_id int primary key, user_name varchar(50) not null);
insert into t_user values(1, '劉一');
insert into t_user values(2, '陳二');
insert into t_user values(3, '張三');
insert into t_user values(4, '李四');
insert into t_user values(5, '王五');
insert into t_user values(6, '趙六');
insert into t_user values(7, '孫七');
insert into t_user values(8, '周八');
insert into t_user values(9, '吳九');
create table t_friend(
user_id int not null,
friend_id int not null,
created_time timestamp not null,
primary key (user_id, friend_id)
);
insert into t_friend values(1, 2, current_timestamp);
insert into t_friend values(2, 1, current_timestamp);
insert into t_friend values(1, 3, current_timestamp);
insert into t_friend values(3, 1, current_timestamp);
insert into t_friend values(1, 4, current_timestamp);
insert into t_friend values(4, 1, current_timestamp);
insert into t_friend values(1, 7, current_timestamp);
insert into t_friend values(7, 1, current_timestamp);
insert into t_friend values(1, 8, current_timestamp);
insert into t_friend values(8, 1, current_timestamp);
insert into t_friend values(2, 3, current_timestamp);
insert into t_friend values(3, 2, current_timestamp);
insert into t_friend values(2, 5, current_timestamp);
insert into t_friend values(5, 2, current_timestamp);
insert into t_friend values(3, 4, current_timestamp);
insert into t_friend values(4, 3, current_timestamp);
insert into t_friend values(4, 6, current_timestamp);
insert into t_friend values(6, 4, current_timestamp);
insert into t_friend values(5, 8, current_timestamp);
insert into t_friend values(8, 5, current_timestamp);
insert into t_friend values(7, 8, current_timestamp);
insert into t_friend values(8, 7, current_timestamp);其中,t_user 表用于存儲用戶信息;t_friend 表存儲好友關系,每個好友關系存儲兩條記錄。
如果是單向圖結構(組織結構樹),可以使用一個表進行存儲。通常是為 id 增加一個父級節點 parent_id。
查看好友列表
微信中的通訊錄,顯示的就是我們的好友。同樣,我們可以查看“王五”(user_id = 5)的好友:
select u.user_id as friend_id,u.user_name as friend_name
from t_user u
join t_friend f on (u.user_id = f.friend_id and f.user_id = 5);
friend_id|friend_name|
---------|-----------|
2|陳二 |
8|周八 |“王五”有兩個好友,分別是“陳二”和“周八”。
查看共同好友
利用好友關系表,我們還可以獲取更多關聯信息。例如,以下語句可以查看“張三”和“李四”的共同好友:
with f1(friend_id) as (
select f.friend_id
from t_user u
join t_friend f on (u.user_id = f.friend_id and f.user_id = 3)),
f2(friend_id) as (
select f.friend_id
from t_user u
join t_friend f on (u.user_id = f.friend_id and f.user_id = 4))
select u.user_id as friend_id,u.user_name as friend_name
from t_user u
join f1 on (u.user_id = f1.friend_id)
join f2 on (u.user_id = f2.friend_id);
friend_id|friend_name|
---------|-----------|
1|劉一 |上面的語句中我們使用了通用表表達式(Common Table Expression)定義了兩個臨時查詢結果集 f1 和 f2,分別表示“張三”的好友和“李四”的好友;然后通過連接查詢返回他們的共同好友。關于通用表表達式以及各種數據庫中的語法可以參考這篇文章。
可能認識的人
很多社交軟件都可以實現推薦(你可能認識的)好友功能。一方面可能是讀取了你的手機通訊錄,找到已經在系統中注冊但不屬于你的好友的用戶;另一方面就是找出和你不是好友,但是有共同好友的用戶。
以下語句用于找出可以推薦給“陳二”的用戶:
with friend(id) as (
select f.friend_id
from t_user u
join t_friend f on (u.user_id = f.friend_id and f.user_id = 2)),
fof(id) as (
select f.friend_id
from t_user u
join t_friend f on (u.user_id = f.friend_id)
join friend on (f.user_id = friend.id and f.friend_id != 2))
select u.user_id, u.user_name, count(*)
from t_user u
join fof on (u.user_id = fof.id)
where fof.id not in (select id from friend)
group by u.user_id, u.user_name;
user_id|user_name|count(*)|
-------|---------|--------|
4|李四 | 2|
7|孫七 | 1|
8|周八 | 2|我們同樣使用了通用表表達式,friend 代表了“陳二”的好友,fof 代表了“陳二”好友的好友(排除了“陳二”自己);最后排除 fof 中已經是“陳二”好友的用戶,并且統計了他們和“陳二”的共同好友數量。
根據查詢結果,我們可以向“陳二”推薦 3 個可能認識的人;并且告訴他和“李四”有 2 位共同好友等。
最遙遠的距離
在社會學中存在一個六度關系理論(Six Degrees of Separation),指地球上所有的人都可以通過六層以內的關系鏈和任何其他人聯系起來。在社交網絡中,也有一些相關的實驗。例如 2011年,Facebook 以一個月內訪問 的 7.21 億活躍用戶為研究對象,計算出其中任何兩個獨立的用戶之間平均所間隔的人數為4.74。
我們以“趙六”和“孫七“為例,查找任意兩個人之間的關系鏈:
with recursive t(id, fid, hops, path) as (
select user_id, friend_id, 0, CAST(CONCAT(user_id , ',', friend_id) AS CHAR(1000))
from t_friend
where user_id = 6
union all
select t.id, f.friend_id, hops+1, CONCAT(t.path, ',', f.friend_id)
from t join t_friend f
on (t.fid = f.user_id) and (FIND_IN_SET(f.friend_id, t.path) = 0) and hops < 5
)
select *
from t where t.fid = 7
order by hops;
id|fid|hops|path |
--|---|----|-------------|
6| 7| 2|6,4,1,7 |
6| 7| 3|6,4,3,1,7 |
6| 7| 3|6,4,1,8,7 |
6| 7| 4|6,4,3,1,8,7 |
6| 7| 4|6,4,3,2,1,7 |
6| 7| 5|6,4,1,2,5,8,7|
6| 7| 5|6,4,3,2,1,8,7|
6| 7| 5|6,4,3,2,5,8,7|查詢結果顯示,“趙六”和“孫七“之間最近的距離是通過兩個人(”李四“和”劉一“)進行聯系。我們也可以統計示例表中任何兩個用戶之間的平均間隔人數:
with recursive t(id, fid, hops, path) as (
select user_id, friend_id, 0, CAST(CONCAT(user_id , ',', friend_id) AS CHAR(1000))
from t_friend
where user_id = 6
union all
select t.id, f.friend_id, hops+1, CONCAT(t.path, ',', f.friend_id)
from t join t_friend f
on (t.fid = f.user_id) and (FIND_IN_SET(f.friend_id, t.path) = 0) and hops < 5
)
select avg(hops)
from t
order by hops;
avg(hops)|
---------|
3.5116|對于 QQ 這種加權圖,可以在 t_friend 表中增加一個權重字段,從而分析好友的親密度。
粉絲關系分析
對于微博這種有向圖,對應的表結構可以設計如下:
-- 粉絲
create table t_follower(
user_id int not null,
follower_id int not null,
created_time timestamp not null,
primary key (user_id, follower_id)
);
insert into t_follower values(1, 2, current_timestamp);
insert into t_follower values(1, 3, current_timestamp);
insert into t_follower values(1, 4, current_timestamp);
insert into t_follower values(1, 7, current_timestamp);
insert into t_follower values(2, 3, current_timestamp);
insert into t_follower values(3, 4, current_timestamp);
insert into t_follower values(4, 1, current_timestamp);
insert into t_follower values(5, 2, current_timestamp);
insert into t_follower values(5, 8, current_timestamp);
insert into t_follower values(6, 4, current_timestamp);
insert into t_follower values(7, 8, current_timestamp);
insert into t_follower values(8, 1, current_timestamp);
insert into t_follower values(8, 7, current_timestamp);
-- 關注
create table t_followed(
user_id int not null,
followed_id int not null,
created_time timestamp not null,
primary key (user_id, followed_id)
);
insert into t_followed values(1, 4, current_timestamp);
insert into t_followed values(1, 8, current_timestamp);
insert into t_followed values(2, 1, current_timestamp);
insert into t_followed values(2, 5, current_timestamp);
insert into t_followed values(3, 1, current_timestamp);
insert into t_followed values(3, 2, current_timestamp);
insert into t_followed values(4, 1, current_timestamp);
insert into t_followed values(4, 3, current_timestamp);
insert into t_followed values(4, 6, current_timestamp);
insert into t_followed values(7, 1, current_timestamp);
insert into t_followed values(7, 8, current_timestamp);
insert into t_followed values(8, 5, current_timestamp);
insert into t_followed values(8, 7, current_timestamp);其中,t_follower 存儲粉絲,t_followed 存儲關注的人。每次有用戶關注其他人,往這兩個表中插入相應的記錄。
由于粉絲相對于好友是一種弱關系,能夠分析的內容相對簡單一些。
我的關注
我們看看“劉一”關注了哪些用戶:
select f.followed_id, u.user_name
from t_followed f
join t_user u on (u.user_id = f.followed_id)
where f.user_id = 1;
followed_id|user_name|
-----------|---------|
4|李四 |
8|周八 |“劉一”關注了“李四”和“周八”。
共同關注
我們還可以進一步獲取和“劉一”具有相同關注的人的用戶:
select r.follower_id, r.user_id
from t_followed d
join t_follower r on (r.user_id = d.followed_id and r.follower_id != d.user_id)
where d.user_id = 1;
follower_id|user_id|
-----------|-------|
7| 8|結果顯示,“劉一”和“孫七”共同關注了“周八”。
我的粉絲
我們再來看看哪些用戶是“劉一”的粉絲:
select f.follower_id, u.user_name
from t_follower f
join t_user u on (u.user_id = f.follower_id)
where f.user_id = 1;
follower_id|user_name|
-----------|---------|
2|陳二 |
3|張三 |
4|李四 |
7|孫七 |“劉一”有 4 個粉絲。
相互關注
最后,我們看看哪些用戶之間互為粉絲,或者互相關注:
select r.user_id, r.follower_id
from t_follower r
join t_followed d on (r.user_id = d.user_id and r.follower_id = d.followed_id and r.user_id < r.follower_id);
user_id|follower_id|
-------|-----------|
1| 4|
7| 8|結果顯示,“劉一”和“李四”互為粉絲,而“孫七”和“周八”則互相關注。
總結
本文介紹了如何將微信、微博這類圖結構的社交網絡數據使用鄰接列表進行描述,并且最終存儲為結構化的關系表。利用 SQL 語句中的連接查詢、通用表表達式的遞歸查詢等功能對其進行分析,發行其中隱藏的社交關系。
除了社交網絡關系分析之外,這些 SQL 功能也可以用于飛機航班查找、地鐵換乘路線查詢,甚至用于實現各種推薦系統,例如產品的猜你喜歡與電影推薦。