













深入理解 Linux 的 TCP 三次握手
作者 | zorrozou
前言
TCP協議是一個大家好像都熟悉,又好像都不熟悉的協議。說熟悉,是因為我們基本每天都要用到它,所有人似乎對三次握手、四次揮手、滑動窗口、慢啟動、擁塞避免、擁塞控制等概念好像都有些了解。說不熟悉,是因為TCP協議相當的復雜,而且在運行過程中網絡環境會變化,TCP的相關機制也會因為不 同的變化而產生相關的適應行為,真的要說清楚其相關概念和運行過程又真的很不容易。
本系列文章希望從另一個角度交代清楚Linux上TCP實現的部分細節,當然能力有限,有些交代不清楚的地方還希望大家海涵。本文就從TCP建立連接的三次握手開始,希望對你有所幫助。本文內核代碼版本基于linux-5.3。

什么是可靠和面向連接?
說到TCP,不可不說的就是其是一個面向連接和可靠的傳輸層協議。相對的就是UDP,不可靠且非面向連接。其實IP的交付就是面向無連接和不可靠的協議,而UDP只是簡單的在IP層協議上加了個傳輸層的端口封裝,所以自然繼承了IP的交付質量。TCP之所以復雜,就是因為它的設計需要在一個面向無連接、不可靠的IP上實現一個面向連接、可靠的傳輸層協議。所以,我們需要先從工程角度理解清楚到底什么是面向連接?什么是可靠?才能理解TCP為啥要這么復雜。
我們先來概述一下這幾個問題:
什么是面向連接:
連接:在一個連接中傳輸的數據是有關系狀態的,比如需要確定傳輸的對端正處在等待發送或接收的狀態上。需要維護傳輸數據的關系,比如數據流的順序。典型的例子就是打電話。
無連接:不用關心對端是否在線。每一個數據段的發送都是獨立的一個數據個體,數據和數據之間沒有關系,無需維護其之間的關系。典型的例子就是發短信。
什么是可靠:
主要是指數據在傳輸過程中不會被損壞或者丟失,保證數據可以正確到達。而不做以上保證的就是不可靠。
如何解決面向連接問題:
使用建立連接,傳輸數據,斷開連接的三步創建一個長期的數據傳輸機制,在同一個連接中的數據傳輸是有上下文關系的。所以就要引申出以下概念:
- 需要維護seq序列號字段維護數據的順序關系保證按序交付,和解決數據包重復的問題。
- 需要部分特殊的狀態標記的包來專門創建、斷開和維護一個連接:syn,ack,fin,rst
如何解決可靠性問題:
引入數據傳輸的確認機制,即數據發送之后等待對方確認。于是需要維護確認字段Acknowledgement和ack狀態。即:停止等待協議。
引入數據確認機制(停止等待協議)之后,引發了帶寬利用律不高的問題,如何解決?解決方案是引入窗口確認機制和滑動窗口,即不在以每個包發送之后進行確認,而是發送多個包之后一起確認。
引入窗口之后,如何在不同延時的網絡上選擇不同窗口大小?解決方法是引入窗口變量,和窗口監測通告:
發送方維護:
- 已發送并確認ack偏移量(窗口左邊界)
- 已發送未確認ack偏移量(窗口當前發送字節位置)
- 即將發送偏移量(窗口右邊界)
接收方維護:
- 已接受并確認偏移量(窗口左邊界)
- 接受后會保存的窗口大小(窗口右邊界)
接收方會給發送方回復ack確認,ack中會有最新窗口通告長度,以便發送方調整窗口長度。此處會引入sack選擇確認行為和窗口為0時的堅持定時器行為。
引入滑動窗口之后,帶寬可以充分被利用了,但是網絡環境是復雜的,隨時可能因為大量的數據傳輸導致網絡上的擁塞。于是要引入擁塞控制機制:當出現擁塞的時候,tcp應該能保證帶寬是被每條tcp連接公平分享的。所以在擁塞的情況下,要能將占用帶寬較大的連接調整為占用帶寬變小,占用小的調大。以達到公平占用資源的目的。
擁塞控制對帶寬占用的調整本質上就是調整滑動窗口的大小來實現的,所以需要在接受端引入一個新的變量叫做cwnd:擁塞窗口,來反應當前網絡的傳輸能力,而之前的通告窗口可以表示為awnd。此時發送端實際可用的窗口為cwnd和awnd的較小者。
由此引發的各種問題和概念不一而足,比如:如何決定實際的通告窗口大小?慢啟動是什么?擁塞避免過程如何工作?擁塞控制是怎么作用的?等等等等......
TCP之所以復雜,根本原因就是要在工程上解決這些問題。思路概述完了,我們先來看三次握手到底是干嘛的。
為什么要三次?
為什么要三次握手,而不是兩次,或者四次?或者其他次數?
首先我們要先理解建立連接的目的,有兩個:
- 確認對端在線,即我請求你的時候你能立即給出響應。(面向連接)
- 如果傳輸的數據多的話,要保證包的順序,所以要確認這個鏈接中傳輸數據的起始序列號。因為數據是雙向傳輸的,所以兩邊都要確認對端的序列號。
確認了第二個目的之后,我們就能理解,兩次握手至少讓一段無法確定對端是否了解了你的起始序列號。即,假設我是服務端。對端syn給我發了序列號,我也給對端回了我的序列號,但是如果我給對方發的這個數據包丟了怎么辦?于是我沒法確認對端是否收到,所以需要對端再跟我確認一下他確實收到了 。
那么非要四次的話也不是不行,只是太啰嗦了,所以三次是最合理的。不能免俗,我們還是用這個經典的圖來看一下三次握手的過程。
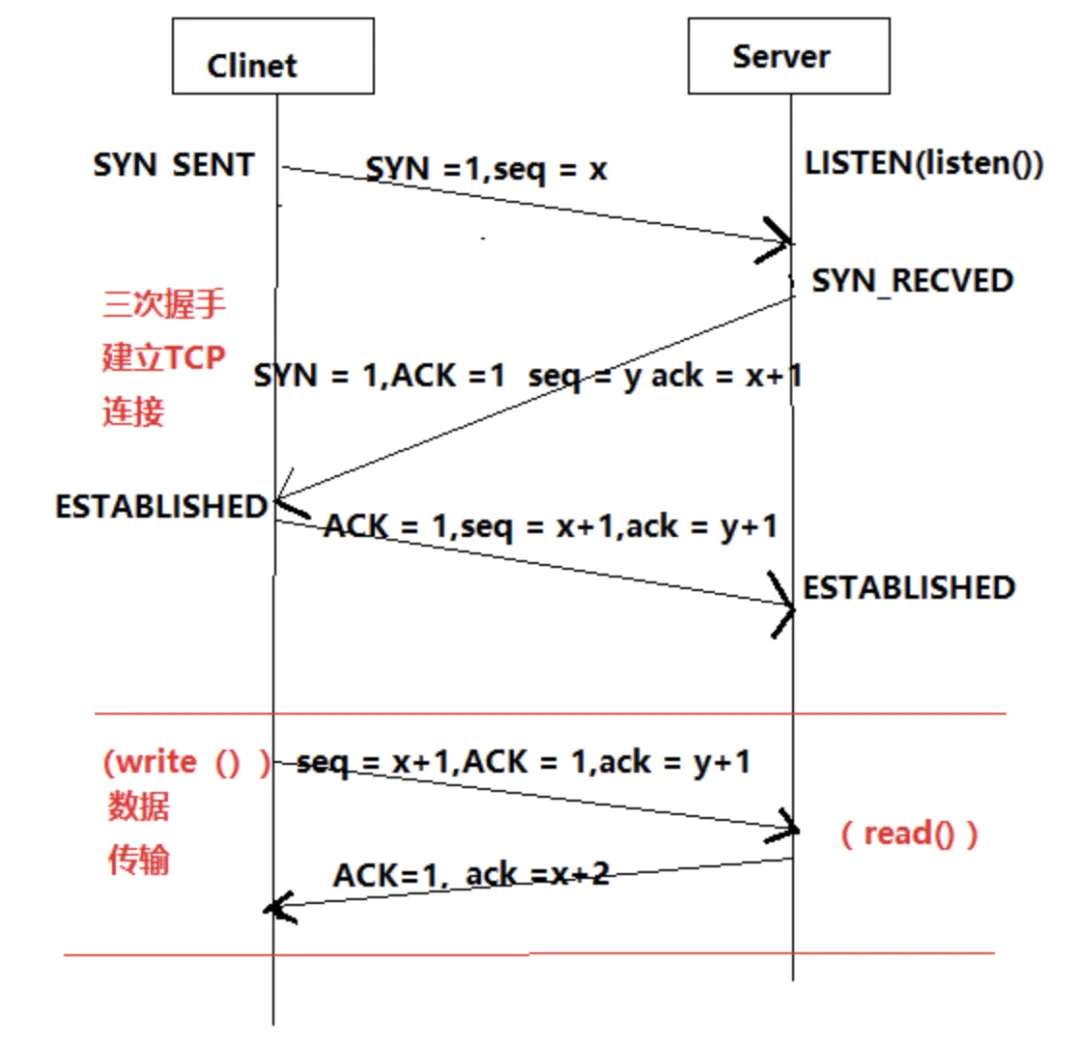
我面試別人的時候經常會在這里問一個比較弱智的問題:如果服務端A,在收到客戶端B發來的syn之后,并且回復了syn+ack之后,收到了從另一個客戶端C發來的ack包,請問此時服務端A會跟C建立后續的ESTABLISHED連接嗎?
畫成圖的話是這樣:
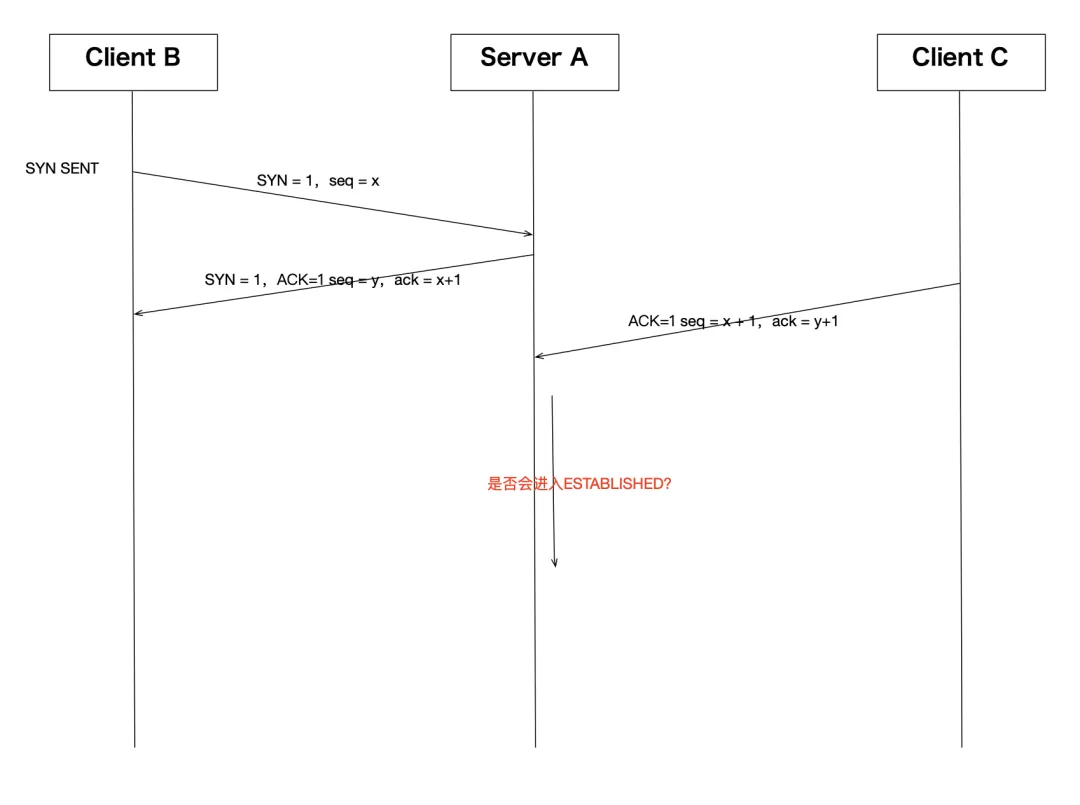
這個問題之所以說是比較弱智,是因為大多數人都覺得不會,但是如果再追問為什么的話,又很少人能真正答出來。那么為什么呢?其實也很簡單,一個新的客戶端的ip+port都不一樣,直接給我發一個ack的話,根據tcp協議會直接回復rst,自然不會創建連接。這里其實引申出一個問題,內核在這里要能識別出給我發這個ack請求的到底是第一次給我發的,還是之前有發過syn并且我已經回復了syn+ack的。內核會通過四元組進行查詢,這個查詢會在tcp_v4_rcv()中執行,就是tcp處理的總人口,其中調用__inet_lookup()進行查找。
static inline struct sock *__inet_lookup(struct net *net,
struct inet_hashinfo *hashinfo,
struct sk_buff *skb, int doff,
const __be32 saddr, const __be16 sport,
const __be32 daddr, const __be16 dport,
const int dif, const int sdif,
bool *refcounted)
{
u16 hnum = ntohs(dport);
struct sock *sk;
sk = __inet_lookup_established(net, hashinfo, saddr, sport,
daddr, hnum, dif, sdif);
*refcounted = true;
if (sk)
return sk;
*refcounted = false;
return __inet_lookup_listener(net, hashinfo, skb, doff, saddr,
sport, daddr, hnum, dif, sdif);
}查找分兩步,先檢查established中是否有連接,再檢查linstener中是否有連接,如果沒有就直接send_reset。確認連接存在后,如果是TCP_ESTABLISHED狀態,直接tcp_rcv_established()接收數據,否則進入tcp_rcv_state_process()處理tcp的各種狀態。如果是第一次握手,就是TCP_LISTEN狀態,進入:
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
此時conn_request為tcp_v4_conn_request(),在這個方法中進行第一次握手的處理。如果是第三次握手,此時tcp狀態應為:TCP_SYN_RECV。
服務端在SYN RECVED的狀態下,要在緩存中紀錄客戶端syn包中的內容,以便在收包的過程中進行查找,占用部分slab緩存。這個緩存在內核中有個上限,用/proc/sys/net/ipv4/tcp_max_syn_backlog來限制緩存的個數。這個值決定了tcp再正常狀態下可以同時維持多少個TCP_SYN_RECV狀態的連接,即服務端半連接個數。一般服務器上的這個值默認為1024-2048,這個值默認情況會根據你的總內存大小自動產生,內存大的值會大一些。
如果這個半連接隊列被耗盡了會怎么樣?我們依然可以在內核中找到答案,在tcp_conn_request()中可以看到這樣一段:
if (!want_cookie && !isn) {
/* Kill the following clause, if you dislike this way. */
if (!net->ipv4.sysctl_tcp_syncookies &&
(net->ipv4.sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) <
(net->ipv4.sysctl_max_syn_backlog >> 2)) &&
!tcp_peer_is_proven(req, dst)) {
/* Without syncookies last quarter of
* backlog is filled with destinations,
* proven to be alive.
* It means that we continue to communicate
* to destinations, already remembered
* to the moment of synflood.
*/
pr_drop_req(req, ntohs(tcp_hdr(skb)->source),
rsk_ops->family);
goto drop_and_release;
}
isn = af_ops->init_seq(skb);
}這里相關幾個概念:
- syncookie是什么?
- inet_csk_reqsk_queue_len(sk)是什么?
我們后面會詳細說syncookie機制,這里先知道這樣一個結論即可:當syncookie開啟的情況下,半連接隊列可認為無上限。從inet_csk_reqsk_queue_len的定義可以知道其查看的是request_sock_queue結構體中的qlen。結構體定義如下:
/*
* For a TCP Fast Open listener -
* lock - protects the access to all the reqsk, which is co-owned by
* the listener and the child socket.
* qlen - pending TFO requests (still in TCP_SYN_RECV).
* max_qlen - max TFO reqs allowed before TFO is disabled.
*
* XXX (TFO) - ideally these fields can be made as part of "listen_sock"
* structure above. But there is some implementation difficulty due to
* listen_sock being part of request_sock_queue hence will be freed when
* a listener is stopped. But TFO related fields may continue to be
* accessed even after a listener is closed, until its sk_refcnt drops
* to 0 implying no more outstanding TFO reqs. One solution is to keep
* listen_opt around until sk_refcnt drops to 0. But there is some other
* complexity that needs to be resolved. E.g., a listener can be disabled
* temporarily through shutdown()->tcp_disconnect(), and re-enabled later.
*/
struct fastopen_queue {
struct request_sock *rskq_rst_head; /* Keep track of past TFO */
struct request_sock *rskq_rst_tail; /* requests that caused RST.
* This is part of the defense
* against spoofing attack.
*/
spinlock_t lock;
int qlen; /* # of pending (TCP_SYN_RECV) reqs */
int max_qlen; /* != 0 iff TFO is currently enabled */
struct tcp_fastopen_context __rcu *ctx; /* cipher context for cookie */
};
/** struct request_sock_queue - queue of request_socks
*
* @rskq_accept_head - FIFO head of established children
* @rskq_accept_tail - FIFO tail of established children
* @rskq_defer_accept - User waits for some data after accept()
*
*/
struct request_sock_queue {
spinlock_t rskq_lock;
u8 rskq_defer_accept;
u32 synflood_warned;
atomic_t qlen;
atomic_t young;
struct request_sock *rskq_accept_head;
struct request_sock *rskq_accept_tail;
struct fastopen_queue fastopenq; /* Check max_qlen != 0 to determine
* if TFO is enabled.
*/
};這里又引申出一個新概念:TFO - TCP Fast Open,這里我們依舊先略過,放到后面講。這個結構體中的qlen會在tcp_conn_request()函數執行結束后增加:
if (fastopen_sk) {
af_ops->send_synack(fastopen_sk, dst, &fl, req,
&foc, TCP_SYNACK_FASTOPEN);
/* Add the child socket directly into the accept queue */
if (!inet_csk_reqsk_queue_add(sk, req, fastopen_sk)) {
reqsk_fastopen_remove(fastopen_sk, req, false);
bh_unlock_sock(fastopen_sk);
sock_put(fastopen_sk);
goto drop_and_free;
}
sk->sk_data_ready(sk);
bh_unlock_sock(fastopen_sk);
sock_put(fastopen_sk);
} else {
tcp_rsk(req)->tfo_listener = false;
if (!want_cookie)
inet_csk_reqsk_queue_hash_add(sk, req,
tcp_timeout_init((struct sock *)req));
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE);
if (want_cookie) {
reqsk_free(req);
return 0;
}
}可以理解為,qlen為服務端listen端口的半連接隊列當前長度。于是這一段可以理解為:
if (!net->ipv4.sysctl_tcp_syncookies &&
(net->ipv4.sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) <
(net->ipv4.sysctl_max_syn_backlog >> 2)) &&
!tcp_peer_is_proven(req, dst)) {當沒開啟syncookie時,如果當前半連接池剩余長度小于最大長度的四分之一后,就不再處理新建連接請求了。這也就是著名的synflood攻擊的原理:
針對一個沒有syncookie功能的服務器,任意客戶端都可以通過構造一個不完整三次握手過程,只發syn,不回第三次握手的ack來占滿服務端的半連接池,導致服務端無法再跟任何客戶端進行tcp新建連接。
那么我們也就知道syncookie這個功能的設計初衷了:防止synflood。
syncookie如何防止synflood?
既然已經明確synflood是針對半連接池上限的攻擊,那么我們就需要想辦法繞過去半連接池。能否讓服務器端不紀錄第一個syn發來的四元組信息,還能再第三次握手的時候做驗證呢?其實也是可能的:既然三次握手的第二次是服務端回包,那為什么不把第一次握手得到的信息放到回包里,讓客戶端在第三 次握手的時候再把這個信息帶回來,然后我們拿到第三次握手的四元組信息和其中記錄的信息做驗證不就好了?當然,為了包內容盡量小,我們把需要記錄到包里的信息做一下hash運算,運算出來的新數據就叫cookie。
具體處理方法描述如下:
在tcp_conn_request()中調用以下代碼產生cookie:
if (want_cookie) {
isn = cookie_init_sequence(af_ops, sk, skb, &req->mss);
req->cookie_ts = tmp_opt.tstamp_ok;
if (!tmp_opt.tstamp_ok)
inet_rsk(req)->ecn_ok = 0;
}追溯到實際產生cookie的方法為:
static __u32 secure_tcp_syn_cookie(__be32 saddr, __be32 daddr, __be16 sport,
__be16 dport, __u32 sseq, __u32 data)
{
/*
* Compute the secure sequence number.
* The output should be:
* HASH(sec1,saddr,sport,daddr,dport,sec1) + sseq + (count * 2^24)
* + (HASH(sec2,saddr,sport,daddr,dport,count,sec2) % 2^24).
* Where sseq is their sequence number and count increases every
* minute by 1.
* As an extra hack, we add a small "data" value that encodes the
* MSS into the second hash value.
*/
u32 count = tcp_cookie_time();
return (cookie_hash(saddr, daddr, sport, dport, 0, 0) +
sseq + (count << COOKIEBITS) +
((cookie_hash(saddr, daddr, sport, dport, count, 1) + data)
& COOKIEMASK));
}根據包的四元組信息和當前時間算出hash值,并記錄在isn中。發送synack使用tcp_v4_send_synack()函數,其中調用tcp_make_synack(),判斷cookie_ts是不是被設置,如果被設置則初始化tcp選項信息到timestamp中的低6位。
#ifdef CONFIG_SYN_COOKIES
if (unlikely(req->cookie_ts))
skb->skb_mstamp_ns = cookie_init_timestamp(req);
else
#endif這樣把synack發回給客戶端,包中包含了cookie信息。客戶端在回復最后一個ack時將seq+1,就是說服務端收到最后一個ack的時候,只要將ack的seq序列號-1,就能拿到之前送出去的cookie。然后再根據包的四元組信息算一遍cookie,驗證算出來的cookie和返回的cookie是不是一樣就行了。具體方法在cookie_v4_check()中,有興趣可以自行檢索代碼。
經過這樣的驗證,將原來需要內存資源進行處理的過程,完全轉變成了CPU運算,這樣即使有synflood攻擊,攻擊的也不再是內存上限,而是會轉換成CPU運算,這樣會使攻擊的效果大大減弱。
syncookie功能內核默認是打開的,開關在:
/proc/sys/net/ipv4/tcp_syncookies
這個文件默認值為1,代表打開syncookie功能。要注意的是,這種場景下,只有在tcp_max_syn_backlog上限被耗盡之后,新建的連接才會使用syncookie。設置0為關閉syncookie,設置為2為忽略tcp_max_syn_backlog半連接隊列,直接使用syncookie。
listen backlog
這里還要額外說明一下的是listen系統調用的backlog參數。我們都知道,要讓一個端口處在監聽狀態,需要調用socket、bind、listen三個系統調用,而最終TCP進入LISTEN狀態,就是由listen系統調用來做的。這個系統調用的第二個參數backlog在man page中解釋如下:
The backlog argument defines the maximum length to which the queue of pending connections for sockfd may grow. If a connection request arrives when the queue is full, the client may receive an error with an indication of ECONNREFUSED or, if the underlying protocol supports retransmission, the request may be ignored so that a later reattempt at connection succeeds.從描述上看,這個backlog似乎限制了tcp的半連接隊列,但是如果你看man page可以細心一點,再往下翻翻,就可以看到這段內容:
NOTES
To accept connections, the following steps are performed:
1. A socket is created with socket(2).
2. The socket is bound to a local address using bind(2), so that other sockets may be connect(2)ed to it.
3. A willingness to accept incoming connections and a queue limit for incoming connections are specified with listen().
4. Connections are accepted with accept(2).
POSIX.1-2001 does not require the inclusion of <sys/types.h>, and this header file is not required on Linux. However, some historical (BSD) implementations required this header file, and portable applications are probably wise to include it.
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. See tcp(7) for more information.
If the backlog argument is greater than the value in /proc/sys/net/core/somaxconn, then it is silently truncated to that value; the default value in this file is 128. In kernels before 2.4.25, this limit was a hard coded value, SOMAXCONN, with the value 128.這段內容真正解釋了這個backlog的真實含義。簡單來說就是,一個tcp連接的建立主要包括4部:
(1) 創建一個socket。socket()
(2) 將socket和本地某個地址和端口綁定。bind()
(3) 將socket值為listen狀態。listen()
此時,客戶端就可以跟對應端口的socket創建連接了,當然這里如果創建連接的話,主要是可以完成三次握手。而還不能創建一個應用可讀寫的連接。最終要創建一個真正可用的連接還需要第四部:
(4) 服務端accept一個新建連接,并建立一個新的accept返回的fd。accept()
這之后,服務端才可以用這個新的accept fd跟客戶端進行通信。而這里的listen backlog,限制的就是,如果服務端處在LISTEN狀態,并且有客戶端跟我建立連接,但是如果服務端沒有及時accept新建連接的話,那么這種還未accpet的請求隊列是多大?這里還有個問題,當這個連接隊列超限之后,是什么 效果?
我們可以寫一個簡單的服務端程序來測試一下這個狀態,server端代碼如下:
[root@localhost basic]# cat server.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <string.h>
int main()
{
int sfd, afd;
socklen_t socklen;
struct sockaddr_in saddr, caddr;
sfd = socket(AF_INET, SOCK_STREAM, 0);
if (sfd < 0) {
perror("socket()");
exit(1);
}
bzero(&saddr, sizeof(saddr));
saddr.sin_family = AF_INET;
saddr.sin_port = htons(8888);
if (inet_pton(AF_INET, "0.0.0.0", &saddr.sin_addr) <= 0) {
perror("inet_pton()");
exit(1);
}
//saddr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
if (bind(sfd, (struct sockaddr *)&saddr, sizeof(saddr)) < 0) {
perror("bind()");
exit(1);
}
if (listen(sfd, 5) < 0) {
perror("listen()");
exit(1);
}
pause();
while (1) {
bzero(&caddr, sizeof(caddr));
afd = accept(sfd, (struct sockaddr *)&caddr, &socklen);
if (afd < 0) {
perror("accept()");
exit(1);
}
if (write(afd, "hello", strlen("hello")) < 0) {
perror("write()");
exit(1);
}
close(afd);
}
exit(0);
}代碼很簡單,socket、bind、listen之后直接pause,我們來看看當前狀態:
[root@localhost basic]# ./server &
[1] 14141
[root@localhost basic]# ss -tnal
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 5 0.0.0.0:8888 0.0.0.0:*此時,對于ss命令顯示的LISTEN狀態連接,Send-Q數字的含義就是listen backlog的長度。我們使用telnet作為客戶端連接當前8888端口,并抓包看TCP的連接過程和其變化。
[root@localhost basic]# tcpdump -i ens33 -nn port 8888
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
10:54:41.863704 IP 192.168.247.130.45790 > 192.168.247.129.8888: Flags [S], seq 3982567931, win 64240, options [mss 1460,sackOK,TS val 1977602046 ecr 0,nop,wscale 7], length 0
10:54:41.863788 IP 192.168.247.129.8888 > 192.168.247.130.45790: Flags [S.], seq 3708893655, ack 3982567932, win 28960, options [mss 1460,sackOK,TS val 763077058 ecr 1977602046,nop,wscale 7], length 0
10:54:41.864005 IP 192.168.247.130.45790 > 192.168.247.129.8888: Flags [.], ack 1, win 502, options [nop,nop,TS val 1977602046 ecr 763077058], length 0三次握手建立沒問題。
[root@localhost zorro]# ss -antl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 1 5 0.0.0.0:8888 0.0.0.0:*ss顯示可知,LISTEN狀態的Recv-Q就是當前在backlog隊列里排隊的連接個數,我們多創建幾個看超限會如何:
[root@localhost zorro]# ss -antl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 6 5 0.0.0.0:8888 0.0.0.0:*
[root@localhost basic]# tcpdump -i ens33 -nn port 8888
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
11:00:40.674176 IP 192.168.247.130.45804 > 192.168.247.129.8888: Flags [S], seq 3183080621, win 64240, options [mss 1460,sackOK,TS val 1977960856 ecr 0,nop,wscale 7], length 0
11:00:41.682431 IP 192.168.247.130.45804 > 192.168.247.129.8888: Flags [S], seq 3183080621, win 64240, options [mss 1460,sackOK,TS val 1977961864 ecr 0,nop,wscale 7], length 0
11:00:43.728894 IP 192.168.247.130.45804 > 192.168.247.129.8888: Flags [S], seq 3183080621, win 64240, options [mss 1460,sackOK,TS val 1977963911 ecr 0,nop,wscale 7], length 0
11:00:47.761967 IP 192.168.247.130.45804 > 192.168.247.129.8888: Flags [S], seq 3183080621, win 64240, options [mss 1460,sackOK,TS val 1977967944 ecr 0,nop,wscale 7], length 0
11:00:56.017547 IP 192.168.247.130.45804 > 192.168.247.129.8888: Flags [S], seq 3183080621, win 64240, options [mss 1460,sackOK,TS val 1977976199 ecr 0,nop,wscale 7], length 0
11:01:12.402559 IP 192.168.247.130.45804 > 192.168.247.129.8888: Flags [S], seq 3183080621, win 64240, options [mss 1460,sackOK,TS val 1977992584 ecr 0,nop,wscale 7], length 0
11:01:44.657797 IP 192.168.247.130.45804 > 192.168.247.129.8888: Flags [S], seq 3183080621, win 64240, options [mss 1460,sackOK,TS val 1978024840 ecr 0,nop,wscale 7], length 0當連接個數超過6再創建新的連接后,新連接已經無法完成三次握手了,client的syn沒有收到回應,開始重試,重試6次結束連接。客戶端報錯為:
[root@localhost zorro]# telnet 192.168.247.129 8888
Trying 192.168.247.129...
telnet: connect to address 192.168.247.129: Connection timed out第一次握手的syn沒有收到回應的情況下重試次數收到這個內核參數限制:
/proc/sys/net/ipv4/tcp_syn_retries
設置第一次握手syn在沒有收到synack的情況下,最大重試次數,默認為6次。可以修改這個值達到改變重試次數的目的。但是時間規則無法改變。間隔時間是按照2的指數增長的,就是說第一次重試是1秒,第二次為2秒,然后是4秒,8秒以此類推。所以默認情況下tcp_syn_retries最多等待63秒。另外還有一個文件用來規定第二次握手的重試次數:
/proc/sys/net/ipv4/tcp_synack_retries
設置第二次握手synack發出之后,在沒有收到最后一個ack的情況下,最大重試次數,默認值為5。所以tcp_synack_retries最多等待31秒。
根據以上測試我們發現,當listen backlog隊列被耗盡之后,新建連接是不能完成三次握手的,這有時候會跟synflood攻擊產生混淆,因為這跟synflood導致的效果類似。在內核中的tcp_conn_request()處理過程中我們可以看到內核應對synflood和listen backlog滿的分別應對方法:
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
struct tcp_fastopen_cookie foc = { .len = -1 };
__u32 isn = TCP_SKB_CB(skb)->tcp_tw_isn;
struct tcp_options_received tmp_opt;
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
struct sock *fastopen_sk = NULL;
struct request_sock *req;
bool want_cookie = false;
struct dst_entry *dst;
struct flowi fl;
/* TW buckets are converted to open requests without
* limitations, they conserve resources and peer is
* evidently real one.
*/
if ((net->ipv4.sysctl_tcp_syncookies == 2 ||
inet_csk_reqsk_queue_is_full(sk)) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, rsk_ops->slab_name);
if (!want_cookie)
goto drop;
}
if (sk_acceptq_is_full(sk)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
......當sk_acceptq_is_full(sk)時直接drop,并且會增加LINUX_MIB_LISTENOVERFLOWS對應的計數器。查詢計數器對應關系我們可知,LINUX_MIB_LISTENOVERFLOWS對應的是:
SNMP_MIB_ITEM("ListenOverflows", LINUX_MIB_LISTENOVERFLOWS)
也就是/proc/net/netstat中的ListenOverflows計數。這個計數也對應netstat -s中顯示的listen queue of a socket overflowed。從sk_acceptq_is_full的代碼中我們可以看到,為什么listen backlog設置為5時,必須連接數超過5+1才會連接超時,因為當前連接個數必須大于最大上限:
static inline bool sk_acceptq_is_full(const struct sock *sk)
{
return sk->sk_ack_backlog > sk->sk_max_ack_backlog;
}從listen的man page中我們可以知道,listen backlog的內核限制文件為:
/proc/sys/net/core/somaxconn
針對某個listen socket,當前生效的配置是somaxconn和backlog的最小值。
在一般情況下,這個值是不用做優化的。我們可以想象一下什么時候我們的應用程序會在連接建立的時候來不及accept?大多數情況是當你系統負載壓力特別大,以至于來不及處理新建連接的accept時,這種情況下更重要的應該去擴容了,而非增加這個隊列。在這種情況下,有時甚至我們應該調小這個隊列,并把客戶端的syn重試次數減少,以便能夠讓客戶端更快速的失敗,防止連接積累過多導致雪崩。當然,部分并發處理架構設計不好的軟件也會在非負載壓力大的時候耗盡這個隊列,這時候主要該調整的是軟件架構或其他設置。
TFO - TCP Fast Open
從上面代碼中我們可以知道,當前Linux TCP協議棧是支持TFO的。TFO,中文名字叫TCP快速打開。顧名思義,其主要目的就是簡化三次握手的過程,讓TCP在大延時網絡上打開速度更快。那么TFO是如何工作的呢?我們可以先從一個實際的例子來觀察TFO的行為。
我們在一臺服務器上開啟web服務,另一臺服務器使用curl訪問web服務器的80端口之后訪問其/頁面后退出,抓到的包內容如下:
[root@localhost zorro]# tcpdump -i ens33 -nn port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
11:31:07.390934 IP 192.168.247.130.58066 > 192.168.247.129.80: Flags [S], seq 4136264279, win 64240, options [mss 1460,sackOK,TS val 667677346 ecr 0,nop,wscale 7], length 0
11:31:07.390994 IP 192.168.247.129.80 > 192.168.247.130.58066: Flags [S.], seq 1980017862, ack 4136264280, win 28960, options [mss 1460,sackOK,TS val 4227985538 ecr 667677346,nop,wscale 7], length 0
11:31:07.391147 IP 192.168.247.130.58066 > 192.168.247.129.80: Flags [.], ack 1, win 502, options [nop,nop,TS val 667677347 ecr 4227985538], length 0
11:31:07.391177 IP 192.168.247.130.58066 > 192.168.247.129.80: Flags [P.], seq 1:80, ack 1, win 502, options [nop,nop,TS val 667677347 ecr 4227985538], length 79: HTTP: GET / HTTP/1.1
11:31:07.391185 IP 192.168.247.129.80 > 192.168.247.130.58066: Flags [.], ack 80, win 227, options [nop,nop,TS val 4227985538 ecr 667677347], length 0
11:31:07.391362 IP 192.168.247.129.80 > 192.168.247.130.58066: Flags [.], seq 1:2897, ack 80, win 227, options [nop,nop,TS val 4227985538 ecr 667677347], length 2896: HTTP: HTTP/1.1 200 OK
11:31:07.391441 IP 192.168.247.129.80 > 192.168.247.130.58066: Flags [P.], seq 2897:4297, ack 80, win 227, options [nop,nop,TS val 4227985539 ecr 667677347], length 1400: HTTP
11:31:07.391497 IP 192.168.247.130.58066 > 192.168.247.129.80: Flags [.], ack 2897, win 496, options [nop,nop,TS val 667677347 ecr 4227985538], length 0
11:31:07.391632 IP 192.168.247.130.58066 > 192.168.247.129.80: Flags [.], ack 4297, win 501, options [nop,nop,TS val 667677347 ecr 4227985539], length 0
11:31:07.398223 IP 192.168.247.130.58066 > 192.168.247.129.80: Flags [F.], seq 80, ack 4297, win 501, options [nop,nop,TS val 667677354 ecr 4227985539], length 0
11:31:07.398336 IP 192.168.247.129.80 > 192.168.247.130.58066: Flags [F.], seq 4297, ack 81, win 227, options [nop,nop,TS val 4227985545 ecr 667677354], length 0
11:31:07.398480 IP 192.168.247.130.58066 > 192.168.247.129.80: Flags [.], ack 4298, win 501, options [nop,nop,TS val 667677354 ecr 4227985545], length 0這是一次完整的三次握手和四次揮手過程,還有一個http的數據傳輸過程。當然,我們當前并沒有開啟tfo,我們還是用一個圖來表達一下這個連接過程:
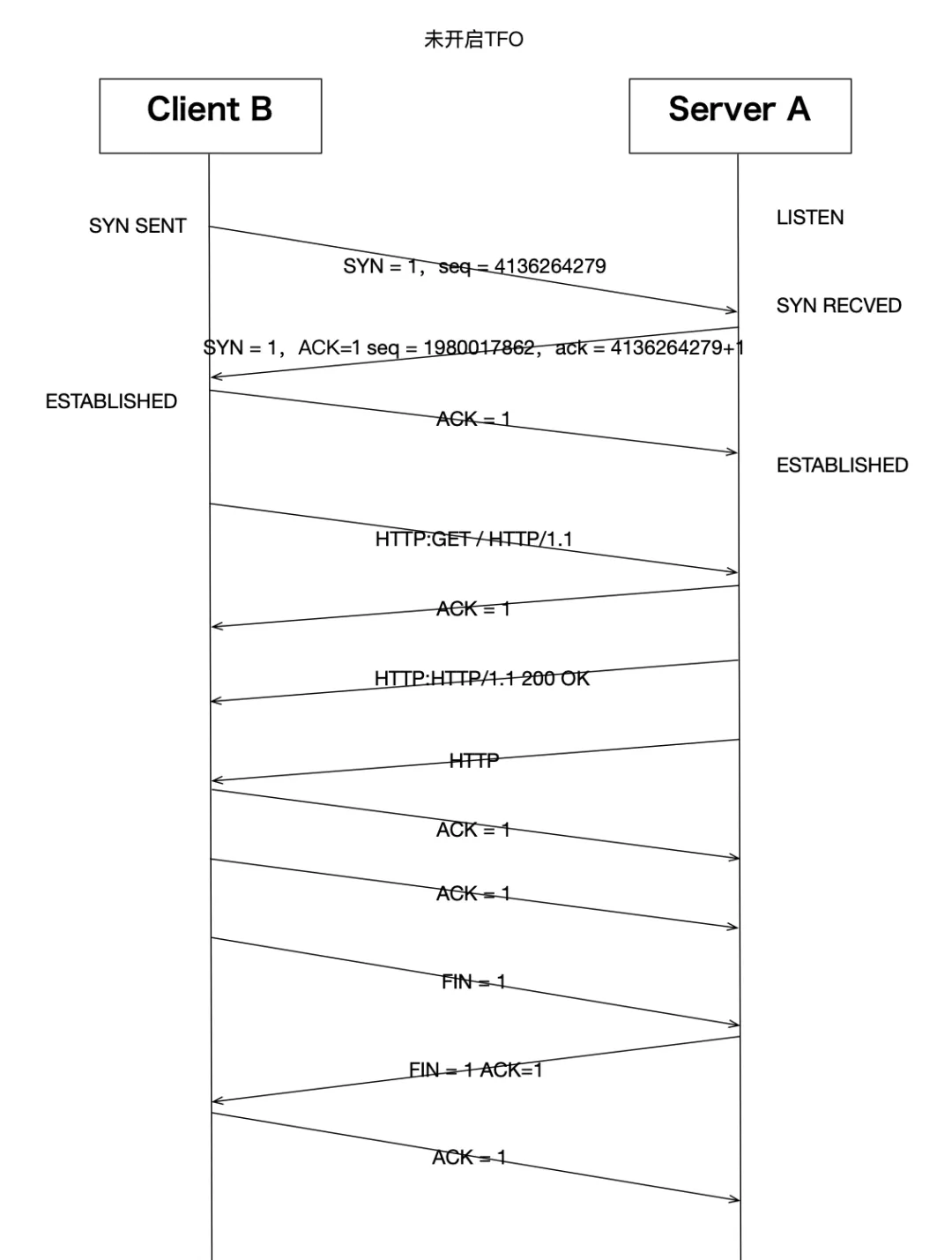
我們幸運的在這個連接過程中觀察到了一次三次揮手關閉連接,但那不是我們今天的主題。其他連接過程基本就是標準的tcp行為。之后我們打開TFO看看是不是有什么變化。
我們的web服務器使用nginx,客戶端使用curl,這兩個軟件默認情況下都是支持TFO的。首先內核開啟TFO支持:
[root@localhost zorro]# echo 3 > /proc/sys/net/ipv4/tcp_fastopen
[root@localhost zorro]# cat /proc/sys/net/ipv4/tcp_fastopen
3這個文件是TFO的開關,0:關閉,1:打開客戶端支持,也是默認值,2:打開服務端支持,3:打開客戶端和服務端。一般在需要的情況下,我們在client的服務器上設置為1,在server端的服務器上設置為2。方便起見,都設置為3也行。然后服務器nginx上配置打開TFO:
server {
listen 80 default_server fastopen=128;
listen [::]:80 default_server fastopen=128;
server_name _;找到nginx的配置文件中listen的設置,加個fastopen參數,后面跟一個值,如上所示。然后重啟服務器。
客戶端比較簡單,使用curl的--tcp-fastopen參數即可,我們在客戶端執行這個命令:
[root@localhost zorro]# curl --tcp-fastopen http://192.168.247.129/同時在服務端抓包看一下:
第一次請求抓包:
[root@localhost zorro]# tcpdump -i ens33 -nn port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
11:44:03.774234 IP 192.168.247.130.58074 > 192.168.247.129.80: Flags [S], seq 3253027385, win 64240, options [mss 1460,sackOK,TS val 668453730 ecr 0,nop,wscale 7,tfo cookiereq,nop,nop], length 0
11:44:03.774361 IP 192.168.247.129.80 > 192.168.247.130.58074: Flags [S.], seq 3812865995, ack 3253027386, win 28960, options [mss 1460,sackOK,TS val 4228761923 ecr 668453730,nop,wscale 7,tfo cookie 336fe8751f5cca4b,nop,nop], length 0
11:44:03.774540 IP 192.168.247.130.58074 > 192.168.247.129.80: Flags [.], ack 1, win 502, options [nop,nop,TS val 668453730 ecr 4228761923], length 0
11:44:03.774575 IP 192.168.247.130.58074 > 192.168.247.129.80: Flags [P.], seq 1:80, ack 1, win 502, options [nop,nop,TS val 668453730 ecr 4228761923], length 79: HTTP: GET / HTTP/1.1
11:44:03.774597 IP 192.168.247.129.80 > 192.168.247.130.58074: Flags [.], ack 80, win 227, options [nop,nop,TS val 4228761923 ecr 668453730], length 0
11:44:03.774786 IP 192.168.247.129.80 > 192.168.247.130.58074: Flags [.], seq 1:2897, ack 80, win 227, options [nop,nop,TS val 4228761923 ecr 668453730], length 2896: HTTP: HTTP/1.1 200 OK
11:44:03.774889 IP 192.168.247.129.80 > 192.168.247.130.58074: Flags [P.], seq 2897:4297, ack 80, win 227, options [nop,nop,TS val 4228761923 ecr 668453730], length 1400: HTTP
11:44:03.774997 IP 192.168.247.130.58074 > 192.168.247.129.80: Flags [.], ack 2897, win 496, options [nop,nop,TS val 668453731 ecr 4228761923], length 0
11:44:03.775022 IP 192.168.247.130.58074 > 192.168.247.129.80: Flags [.], ack 4297, win 489, options [nop,nop,TS val 668453731 ecr 4228761923], length 0
11:44:03.775352 IP 192.168.247.130.58074 > 192.168.247.129.80: Flags [F.], seq 80, ack 4297, win 501, options [nop,nop,TS val 668453731 ecr 4228761923], length 0
11:44:03.775455 IP 192.168.247.129.80 > 192.168.247.130.58074: Flags [F.], seq 4297, ack 81, win 227, options [nop,nop,TS val 4228761924 ecr 668453731], length 0
11:44:03.775679 IP 192.168.247.130.58074 > 192.168.247.129.80: Flags [.], ack 4298, win 501, options [nop,nop,TS val 668453731 ecr 4228761924], length 0第二次請求抓包:
11:44:11.476255 IP 192.168.247.130.58076 > 192.168.247.129.80: Flags [S], seq 3310765845:3310765924, win 64240, options [mss 1460,sackOK,TS val 668461432 ecr 0,nop,wscale 7,tfo cookie 336fe8751f5cca4b,nop,nop], length 79: HTTP: GET / HTTP/1.1
11:44:11.476334 IP 192.168.247.129.80 > 192.168.247.130.58076: Flags [S.], seq 2616505126, ack 3310765925, win 28960, options [mss 1460,sackOK,TS val 4228769625 ecr 668461432,nop,wscale 7], length 0
11:44:11.476601 IP 192.168.247.129.80 > 192.168.247.130.58076: Flags [.], seq 1:2897, ack 1, win 227, options [nop,nop,TS val 4228769625 ecr 668461432], length 2896: HTTP: HTTP/1.1 200 OK
11:44:11.476619 IP 192.168.247.129.80 > 192.168.247.130.58076: Flags [P.], seq 2897:4297, ack 1, win 227, options [nop,nop,TS val 4228769625 ecr 668461432], length 1400: HTTP
11:44:11.476657 IP 192.168.247.130.58076 > 192.168.247.129.80: Flags [.], ack 1, win 502, options [nop,nop,TS val 668461432 ecr 4228769625], length 0
11:44:11.476906 IP 192.168.247.130.58076 > 192.168.247.129.80: Flags [.], ack 4297, win 489, options [nop,nop,TS val 668461433 ecr 4228769625], length 0
11:44:11.477100 IP 192.168.247.130.58076 > 192.168.247.129.80: Flags [F.], seq 1, ack 4297, win 501, options [nop,nop,TS val 668461433 ecr 4228769625], length 0
11:44:11.477198 IP 192.168.247.129.80 > 192.168.247.130.58076: Flags [F.], seq 4297, ack 2, win 227, options [nop,nop,TS val 4228769625 ecr 668461433], length 0
11:44:11.477301 IP 192.168.247.130.58076 > 192.168.247.129.80: Flags [.], ack 4298, win 501, options [nop,nop,TS val 668461433 ecr 4228769625], length 0我們發現開啟TFO之后,第一次http請求,tcp整體交互方式跟沒開啟之前基本一樣。第一次握手的syn多了cookiereq字段。第二次握手服務器端回復了cookie 336fe8751f5cca4b字段。這就是開啟了TFO之后,同一個客戶端請求的第一個tcp連接的主要交互差別:
客戶端的syn包中會帶一個空的cookie字段,服務器如果也支持TFO,那么看到這個空cookie字段后,會計算一個TFO cookie,然后回復給客戶端。這個cookie是用在下一次這個客戶端再跟服務端建立TCP連接的時候用的,帶cookie的syn包表示包內還有承載應用層數據,這樣后續的TCP三次握手過程就可以不 僅僅是握手作用,還可以承載http協議數據了。圖示兩次交互如下:
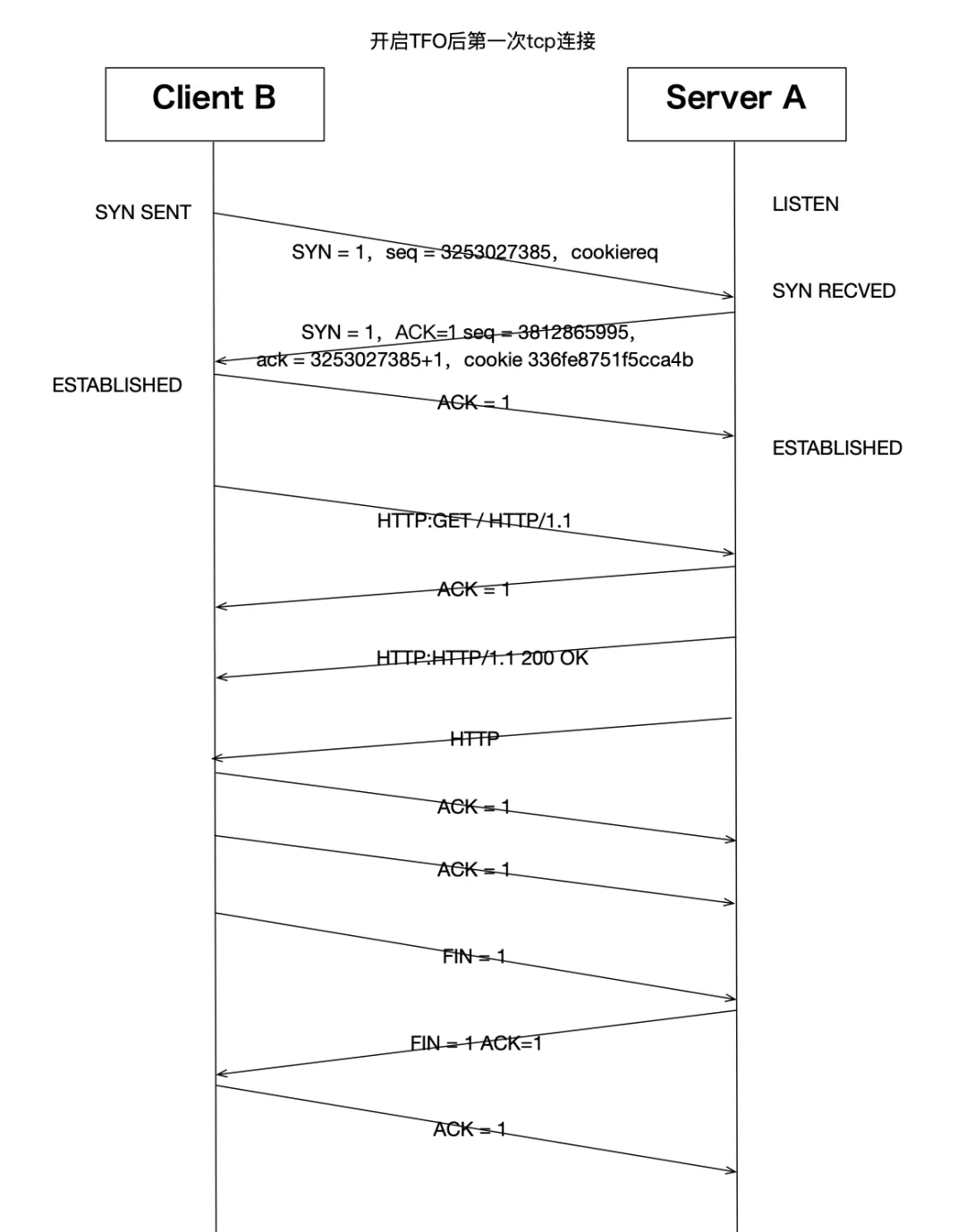
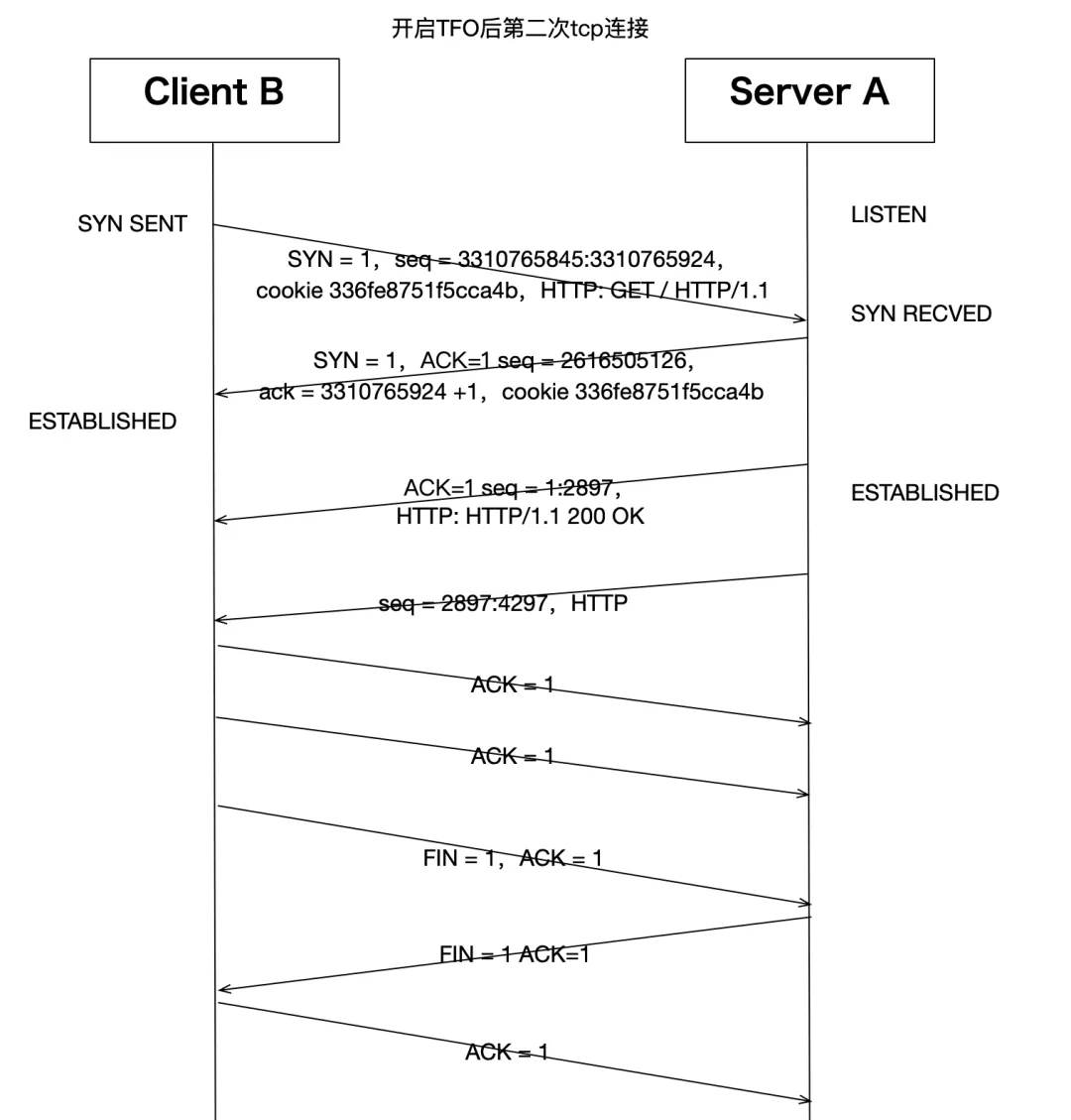
我們再來看一下跟TFO有關的其他內核參數:
/proc/sys/net/ipv4/tcp_fastopen
通過上述內容我們已經知道,這個文件值為1,2,3的含義。除了這些值以外,我們還可以設置為:
- 0x4 :對客戶端有效。不論Cookie是否可用且沒有cookie選項,都將在SYN中發送數據。
- 0x200 :對服務器端有效。接受沒有任何Cookie選項的SYN數據。
- 0x400 :對服務器端有效。默認情況下,使所有listen端口都支持TFO,而無需設置TCP_FASTOPEN套接字選項。
這里還需要補充的是,在一般情況下,除了內核打開相關開關以外,應用程序要支持TFO還要做相關調整。對于客戶端來說,需要使用sendmsg()或sendto()來法送數據,并且要在flag參數中添加MSG_FASTOPEN標記。對于服務端來說,需要在socket打開后,使用setsockopt設置TCP_FASTOPEN選項來打開TFO支 持。
/proc/sys/net/ipv4/tcp_fastopen_key
打開TFO后,內核產生的cookie需要一個密鑰。默認情況下,在打開了TFO的系統上,每個TCP連接所產生的密鑰都是內核隨機產生的。除此之外,還可以使用setsockopt的TCP_FASTOPEN_KEY參數來設置密鑰,當沒有設置的時候,系統會用這個文件中的值來作為密鑰。這個文件中密鑰指定為4個8位十六進制整 數,并用'-'分隔:xxxxxxxx-xxxxxxxx-xxxxxxxx-xxxxxxxx。前導零可以省略。可以通過用逗號分隔主密鑰和備份密鑰指定它們。主密鑰用于創建和驗證cookie,而可選的備用密鑰僅用于驗證cookie。如果僅指定一個密鑰,它將成為主密鑰,并且任何先前配置的備份密鑰都將被刪除。默認值為:00000000-00000000-00000000-00000000,表示內核隨機產生密鑰。
/proc/sys/net/ipv4/tcp_fastopen_blackhole_timeout_sec
因為TFO修改了正常tcp三次握手的過程,在第一個syn包經過網絡到達服務器期間,有可能部分路由器或防火墻規則會把這種特殊的syn當成異常流量而禁止掉。在這個語境下,我們把這種現象叫做TFO firewall blackhole。默認的機制是,如果檢測到防火墻黑洞,則觸發暫時關閉TFO功能,這個文件就是用 來設置關閉時間周期的,默認值為:3600,表示如果檢測到黑洞,則在3600秒內關閉TFO。并且在第每個關閉周期結束后,如果再次檢測還發現有黑洞,則下次關閉周期時間是將會成倍增長。值為0表示關閉黑洞檢測。
另外就是nginx配置中的fastopen=128的128是啥意思:其實就是限制打開fastopen后,針對這個端口未完成三次握手連接的最大長度限制。這個限制可以開的大些。具體可以參見nginx的配置說明:nginx.org/en/docs/ht... 。
TFO的內核代碼實現,這里不再詳述了。大家可以在上面描述過的各個代碼中找到TFO相關的處理過程,有基礎的可以自行研究。關于服務器是否打開TFO仍然是一件爭論不休的事情,在復雜的網絡環境中,TFO的表現似乎距離大家的理想還差得有點遠,當然并不是TFO不好,而是網絡經常會把相關包給拒絕掉 ,導致TFO實際沒有生效。
有關TFO的更詳細說明,大家還可以參考RFC7413:tools.ietf.org/html/...
其他內核參數
三次握手的過程中,還有幾個重試設置:
/proc/sys/net/ipv4/tcp_synack_retries
設置第二次握手synack發出之后,在沒有收到最后一個ack的情況下,最大重試次數,默認值為5。
這里只有重試次數設置,并沒有重試間隔時間。間隔時間是按照2的指數增長的,就是說第一次重試是1秒,第二次為2秒,然后是4秒,8秒以此類推。所以默認情況下tcp_syn_retries最多等待63秒,tcp_synack_retries最多等待31秒。




















