告別CUDA無需Triton!Mirage零門檻生成PyTorch算子,人均GPU編程大師?
近日,來自 CMU 的 Catalyst Group 團隊發(fā)布了一款 PyTorch 算子編譯器 Mirage,用戶無需編寫任何 CUDA 和 Triton 代碼就可以自動生成 GPU 內(nèi)核,并取得更佳的性能。
隨著 GPU 加速器的不斷發(fā)展以及以大語言模型為代表的生成式 AI 應(yīng)用的不斷推廣,通過開發(fā)高性能 GPU 內(nèi)核來優(yōu)化 PyTorch 程序的計算效率變得越來越重要。目前,這項任務(wù)主要由專門的 GPU 專家來完成。在 NVIDIA CUDA 或 AMD ROCm 中編寫高性能 GPU 內(nèi)核需要高水平的 GPU 專業(yè)知識和大量的工程開發(fā)經(jīng)驗。目前的機器學(xué)習(xí)編譯器(如 TVM、Triton 和 Mojo)提供了一些高級編程接口,以簡化 GPU 編程,使用戶可以使用 Python 而非 CUDA 或 ROCm 來實現(xiàn) GPU 內(nèi)核。
然而,這些語言仍然依賴用戶自行設(shè)計 GPU 優(yōu)化技術(shù)以達(dá)到更高的性能。例如,在 Triton 中實現(xiàn)一個 FlashAttention 內(nèi)核大約需要 700 行 Python 代碼(在 CUDA 中需要大約 7,000 行 C++ 代碼)。在這些程序中,用戶需要手動劃分線程塊之間的工作負(fù)載,組織每個線程塊內(nèi)的計算,并管理它們之間的同步與通信。

用 Triton 實現(xiàn)的 FlashAttention 算子
能否在不使用 CUDA/Triton 編程的情況下就獲得高效的 GPU 內(nèi)核呢?基于這一動機,來自卡內(nèi)基梅隆大學(xué)的 Catalyst Group 團隊發(fā)布了 Mirage 項目,基于 SuperOptimization 技術(shù)(https://arxiv.org/abs/2405.05751),為 PyTorch 自動生成高效 GPU 內(nèi)核算子。例如,對于一個 FlashAttention 算子,用戶只需編寫幾行 Python 代碼來描述注意力(Attention)的計算過程而無需了解 GPU 編程細(xì)節(jié),如下所示:
# Use Mirage to generate GPU kernels for attention
import mirage as mi
graph = mi.new_kernel_graph ()
Q = graph.new_input (dims=(64, 1, 128), dtype=mi.float16)
K = graph.new_input (dims=(64, 128, 4096), dtype=mi.float16)
V = graph.new_input (dims=(64, 4096, 128), dtype=mi.float16)
A = graph.matmul (Q, K)
S = graph.softmax (A)
O = graph.matmul (S, V)
optimized_graph = graph.superoptimize ()Mirage 會自動搜索可能的 Attention GPU 內(nèi)核實現(xiàn),搜索空間不僅包括現(xiàn)有的手動設(shè)計的注意力內(nèi)核(如 FlashAttention 和 FlashDecoding),還包括在某些場景中比目前的手寫版本快多達(dá) 3.5 倍的其他實現(xiàn)。Mirage 生成的 GPU 內(nèi)核可以直接在 PyTorch 張量上操作,并可以在 PyTorch 程序中直接調(diào)用。
import torch
input_tensors = [
torch.randn (64, 1, 128, dtype=torch.float16, device='cuda:0'),
torch.randn (64, 128, 4096, dtype=torch.float16, device='cuda:0'),
torch.randn (64, 4096, 128, dtype=torch.float16, device='cuda:0')
]
# Launch the Mirage-generated kernel to perform attention
output = optimized_graph (input_tensors)Why Mirage?
與使用 CUDA/Triton 編程相比,Mirage 提供了一種新的編程范式,包含三個主要優(yōu)勢:
更高的生產(chǎn)力:隨著 GPU 架構(gòu)日新月異,現(xiàn)代 GPU 編程需要持續(xù)學(xué)習(xí)大量的專業(yè)知識。Mirage 的目標(biāo)是提高機器學(xué)習(xí)系統(tǒng)工程師的生產(chǎn)力 —— 他們只需在 PyTorch 層面描述所需的計算,Mirage 便會自動生成適用于各種 GPU 架構(gòu)的高性能實現(xiàn)。因此,程序員不再需要手動編寫 CUDA/Triton 或特定架構(gòu)的低級代碼。
更好的性能:目前手動設(shè)計的 GPU 內(nèi)核由于無法充分探索和利用各種 GPU 優(yōu)化技術(shù),往往只能達(dá)到次優(yōu)性能。Mirage 可以自動搜索與輸入的 PyTorch 程序功能等價的潛在 GPU 實現(xiàn),探索并最終發(fā)現(xiàn)性能最優(yōu)的內(nèi)核。在多個 LLM/GenAI 基準(zhǔn)測試中的測試結(jié)果顯示,Mirage 生成的內(nèi)核通常比 SOTA 的專家人工編寫或編譯器生成的替代方案快 1.2 至 2.5 倍。
更強的正確性:手動實現(xiàn)的 CUDA/Triton GPU 內(nèi)核容易出錯,而且 GPU 內(nèi)核中的錯誤難以調(diào)試和定位,而 Mirage 則利用形式化驗證(Formal Verification)技術(shù)自動驗證生成的 GPU 內(nèi)核的正確性。

LLaMA-3-8B 和 Chameleon-7B 端到端推理延遲對比(NVIDIA A100,batch size=1,context length=4K),相比于 CUDA/Triton 的實現(xiàn),Mirage 可以實現(xiàn) 15-20% 的加速
GPU 架構(gòu)與 Mirage 中的
GPU 計算的內(nèi)核函數(shù)以單程序多數(shù)據(jù)(SPMD)方式在多個流處理器(SM)上同時運行。GPU 內(nèi)核(Kernel)借助由線程塊(Thread Block)組成的網(wǎng)格結(jié)構(gòu)來組織其計算,每個線程塊在單個 SM 上運行。每個塊進一步包含多個線程(Thread),以對單獨的數(shù)據(jù)元素進行計算。GPU 還擁有復(fù)雜的內(nèi)存層次結(jié)構(gòu),以支持這種復(fù)雜的處理結(jié)構(gòu)。每個線程都有自己的寄存器文件(Register File),以便快速訪問數(shù)據(jù)。線程塊內(nèi)的所有線程可以訪問一個公共的共享內(nèi)存(Shared Memory),這有助于它們之間高效的數(shù)據(jù)交換和集體操作。最后,內(nèi)核內(nèi)的所有線程可以訪問分配給整個 GPU 的大型設(shè)備內(nèi)存(Device Memory)。

GPU 計算架構(gòu)和編程抽象示意圖
Mirage 使用 來描述 GPU 內(nèi)核,
來描述 GPU 內(nèi)核, 包含多個層次,代表內(nèi)核、線程塊和線程級別的計算。大體上,Kernel Graph、Thread Block Graph 和 Thread Graph 分別代表整個 GPU、一個流處理器(SM)和一個 CUDA/tensor 核心上的計算。
包含多個層次,代表內(nèi)核、線程塊和線程級別的計算。大體上,Kernel Graph、Thread Block Graph 和 Thread Graph 分別代表整個 GPU、一個流處理器(SM)和一個 CUDA/tensor 核心上的計算。
對 細(xì)節(jié)感興趣的讀者可以參考:
細(xì)節(jié)感興趣的讀者可以參考:
- https://mirage-project.readthedocs.io/en/latest/mugraph.html

Mirage 工作流示意圖
上圖展示了 Mirage 的工作流程:對于輸入的 PyTorch 程序,Mirage 的 生成器自動搜索與輸入程序功能等價的其他
生成器自動搜索與輸入程序功能等價的其他 ,搜索空間涵蓋了內(nèi)核、線程塊和線程級別的各種 GPU 優(yōu)化。所有生成的
,搜索空間涵蓋了內(nèi)核、線程塊和線程級別的各種 GPU 優(yōu)化。所有生成的 都被發(fā)送到等價性驗證器,該驗證器自動檢查每個
都被發(fā)送到等價性驗證器,該驗證器自動檢查每個 是否與所需程序等價。最后,
是否與所需程序等價。最后, 轉(zhuǎn)譯器將所有經(jīng)過驗證的
轉(zhuǎn)譯器將所有經(jīng)過驗證的 轉(zhuǎn)譯為 CUDA 內(nèi)核。最后,Mirage 會從中返回性能最佳的 CUDA 內(nèi)核。
轉(zhuǎn)譯為 CUDA 內(nèi)核。最后,Mirage 會從中返回性能最佳的 CUDA 內(nèi)核。
- 項目成員:Mengdi Wu (CMU), Xinhao Cheng (CMU), Shengyu Liu (PKU), Chuan Shi (PKU), Jianan Ji (CMU), Oded Padon (VMWare), Xupeng Miao (Purdue), Zhihao Jia (CMU)
- 項目地址:https://github.com/mirage-project/mirage
為什么 Mirage 生成的內(nèi)核更高效?
在多個 LLM/GenAI 基準(zhǔn)測試中的測試結(jié)果顯示,Mirage 生成的內(nèi)核通常比現(xiàn)有的手寫或編譯器生成的內(nèi)核快 1.2 至 2.5 倍。接下來,本文以 LLM 中的 Transformer 架構(gòu)為例,展示現(xiàn)有系統(tǒng)中缺失的幾項 GPU 程序優(yōu)化技術(shù):
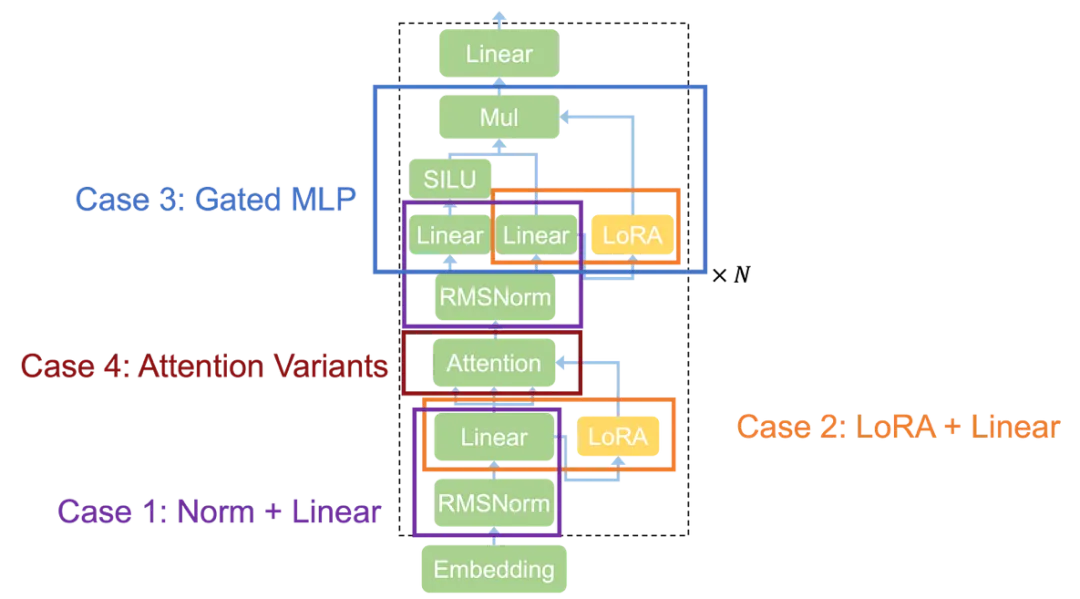
Transformer 架構(gòu)示意圖
Case 1: Normalization + Linear
歸一化(Normalization)操作,如 LayerNorm、RMSNorm、GroupNorm 和 BatchNorm,廣泛應(yīng)用于當(dāng)今的機器學(xué)習(xí)模型。當(dāng)前的機器學(xué)習(xí)編譯器通常在獨立的內(nèi)核中啟動歸一化層,因為歸一化涉及到歸約和廣播,難以與其他計算融合。然而,Mirage 發(fā)現(xiàn),大多數(shù)歸一化層可以通過進行適當(dāng)?shù)拇鷶?shù)變換,與后續(xù)的線性層(如 MatMul)融合。
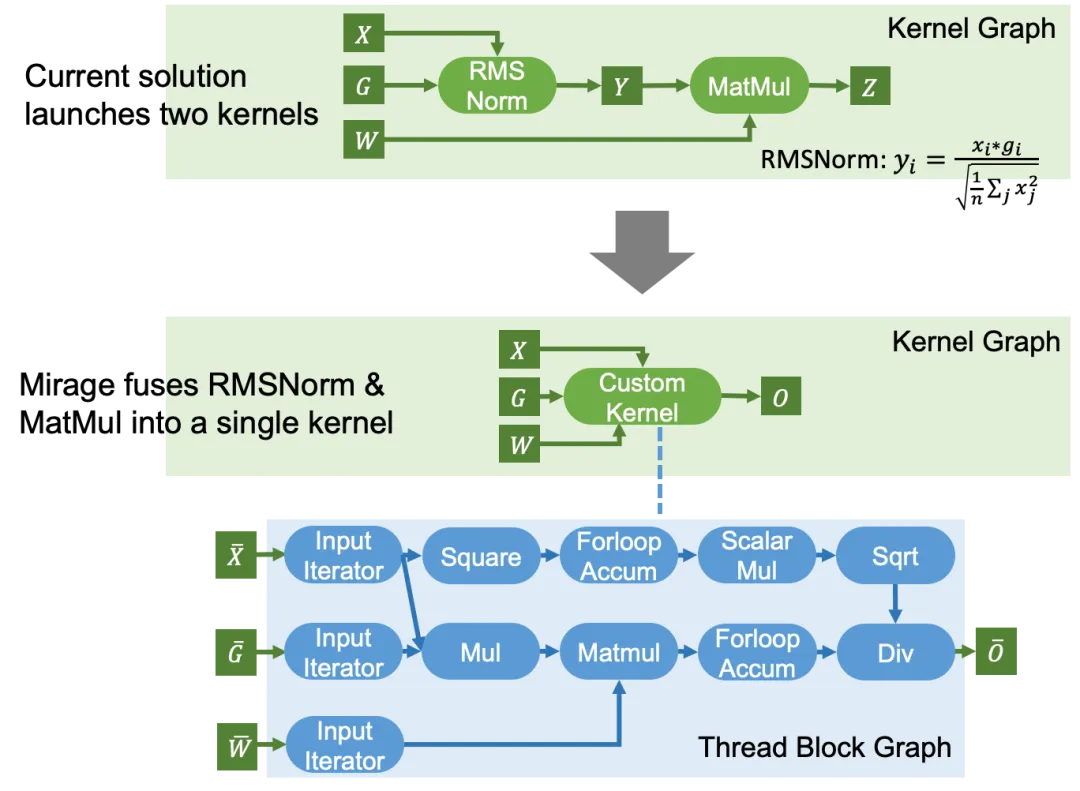
Normalization + Linear 現(xiàn)有內(nèi)核 v.s. Mirage 發(fā)現(xiàn)的內(nèi)核
Mirage 發(fā)現(xiàn)的自定義內(nèi)核利用了 RMSNorm 中的除法和 MatMul 中的乘法的可交換性,將除法移到 MatMul 之后。這一變換保持了功能等價性,同時避免了中間張量 Y 的實例化。該內(nèi)核的性能比單獨運行這兩個操作快 1.5 到 1.7 倍。

Normalization + Linear 內(nèi)核性能對比
Case 2: LoRA + Linear
LoRA 廣泛用于預(yù)訓(xùn)練模型的微調(diào)場景,以適配到特定領(lǐng)域和任務(wù)。這些 LoRA 適配器通常會被插入到模型的線性層中,引入額外的矩陣乘法。現(xiàn)有系統(tǒng)通常為原始矩陣乘法和 LoRA 中的兩個矩陣乘法啟動獨立的內(nèi)核,從而導(dǎo)致較高的內(nèi)核啟動開銷。

LoRA+Linear 現(xiàn)有內(nèi)核 v.s. Mirage 發(fā)現(xiàn)的內(nèi)核
如上圖所示,Mirage 發(fā)現(xiàn)了一個將三個矩陣乘法和隨后的加法融合為單個內(nèi)核的內(nèi)核。這是通過將計算重組為兩個線程塊級別的矩陣乘法實現(xiàn)的,利用了以下代數(shù)變換:W×X+B×A×X=(W|B)×(X|(A×X)),其中的兩個拼接操作不涉及任何計算,而是通過在 GPU 共享內(nèi)存中更新張量偏移量來完成。Mirage 發(fā)現(xiàn)的內(nèi)核比現(xiàn)有系統(tǒng)中使用的內(nèi)核快 1.6 倍。

LoRA+Linear 內(nèi)核性能對比
Case 3: Gated MLP
Gated MLP 層目前在許多 LLM 中使用(如 LLAMA-2、LLAMA-3 及其變體),它的輸入張量 X 與兩個權(quán)重矩陣相乘,輸出結(jié)果被組合以產(chǎn)生最終結(jié)果。Mirage 發(fā)現(xiàn)了一個內(nèi)核,該內(nèi)核執(zhí)行兩個矩陣乘法、SiLU 激活以及隨后的逐元素乘法,從而減少了內(nèi)核啟動開銷和對設(shè)備內(nèi)存的訪問。

Gated MLP 現(xiàn)有內(nèi)核 v.s. Mirage 發(fā)現(xiàn)的內(nèi)核

Gated MLP 內(nèi)核性能對比
Case 4: Attention Variants
如今的大多數(shù) LLM 基于注意力及其變體,雖然現(xiàn)有系統(tǒng)通常提供高度優(yōu)化的注意力實現(xiàn),如 FlashAttention、FlashInfer 和 FlexAttention,但支持注意力變體通常需要新的自定義內(nèi)核。下面用兩個例子來展示 Mirage 如何為非常規(guī)注意力計算發(fā)現(xiàn)自定義 GPU 內(nèi)核。
Case 4.1: Attention with Query-Key Normalization
許多最近的 LLM 架構(gòu)(包括 Chameleon、ViT-22B 等)在 LLaMA 架構(gòu)中引入了 QK-Norm 來緩解訓(xùn)練過程中的數(shù)值發(fā)散問題。QK-Norm 在注意力之前對 Query 和 Key 向量應(yīng)用 LayerNorm 層。現(xiàn)有注意力實現(xiàn)中并不支持這些額外的歸一化層,并且它們還需要作為獨立內(nèi)核啟動。

QK-Norm 注意力現(xiàn)有內(nèi)核 v.s. Mirage 發(fā)現(xiàn)的內(nèi)核
對于在注意力之前和 / 或之后引入計算的注意力變體,這些計算可以與注意力融合以提高 GPU 性能,而這需要自定義內(nèi)核。對于帶有 QK-Norm 的注意力,Mirage 發(fā)現(xiàn)了上述內(nèi)核來融合計算,從而避免在 GPU 設(shè)備內(nèi)存中實例化中間結(jié)果。這個自定義內(nèi)核還對注意力進行了現(xiàn)有的 GPU 優(yōu)化,實現(xiàn)了 1.7 至 2.5 倍的性能提升。

QK-Norm 注意力內(nèi)核性能對比
Case 4.2: Multi-Head Latent Attention

MLA 的現(xiàn)有內(nèi)核 v.s. Mirage 發(fā)現(xiàn)的內(nèi)核
另一個常用的注意力變體是 MLA(Multi-Head Latent Attention),它將注意力的 KV Cache 壓縮為一個向量,以減少存儲 KV Cache 的內(nèi)存開銷。這一變化還在注意力之前引入了兩個線性層,如下圖所示。與 QK-Norm 類似,現(xiàn)有注意力實現(xiàn)中并不支持這些額外的歸一化層,同樣需要作為獨立內(nèi)核啟動,而 Mirage 可以將線性層和注意力融合為一個單獨的自定義內(nèi)核。
長期愿景
Mirage 項目的長期目標(biāo)是希望能夠讓未來的 AI 開發(fā)者無需學(xué)習(xí) CUDA 或者 Triton 等復(fù)雜的 GPU 編程語言,只需指定所需的數(shù)學(xué)操作,就能在 GPU 上輕松實現(xiàn) AI 模型。通過利用 Mirage 的 SuperOptimization 技術(shù),各種計算任務(wù)可以自動轉(zhuǎn)換為高度優(yōu)化的 GPU 實現(xiàn)。隨著 LLM 和其他生成式 AI 應(yīng)用的飛速發(fā)展,在各種實際部署場景都需要高效的 GPU 支持,降低 GPU 編程門檻并提高程序效率也愈發(fā)重要。