AI STUDIO—零門檻實現AI能力
隨著AI技術的發展,人類社會正處于火熱的智能化革命之中,而誰能在技術革命浪潮中快速的武裝自己,誰就能掌握未來的機遇。AI Studio正屬于那一類幫助中小企業,開發者實現AI能力的武器庫之一。
如今,AI能力已經滲透到各行各業,在語音、圖像以及NLP領域,已獲得了突破性的進展和效果,這進一步增強了我們對AI技術的信心,將其推廣到更多的傳統行業來助力各行業的發展。AI技術可以讓我們釋放更多的腦力和體力,在更需要人類創造力的地方發揮作用,其他的一切交給AI,相信我,它們做的比我們更好。
對于大型互聯網企業,形成AI能力只要投錢投人就行了,但是對于中小企業單獨構建AI能力將耗費巨大的精力:招兵買馬,設備采購,模型開發,系統維護,于是大量的云計算及建模平臺如雨后春筍般發展起來,包括AWS(收費),Azure(收費),阿里云(還是收費)等。而百度在確立All in AI后做了很多基礎而扎實的工作,包括最新推出的百度AI Studio一站式開發平臺:一個囊括了AI教程、代碼環境、算法算力、數據集,并提供免費的在線云計算的一體化編程環境,在這里,用戶就不必糾結于復雜的環境配置和繁瑣的擴展包搜尋,只要有電腦、網絡以及一顆走進深度學習的心,打開瀏覽器輸入aistudio.baidu.com,就可以在AI Studio開展深度學習項之旅。下面,本文將從功能簡介,實戰建模及AI能力應用等角度聊聊AI Studio。
俗話說,授人以魚不如授人以漁。百度All in AI的戰略里,魚就是諸如基于語音技術、圖像技術、視頻技術、知識圖譜及NLP技術等形成的人工智能產品服務;而漁就是AI Studio一類的能夠幫助個人開發者和中小企業去開發屬于自己的產品服務,運用AI Studio開發者可以實現自定義的AI建模能力而無需考慮硬件成本、運維成本、人力成本。相比在谷歌云,AWS等云平臺上花錢買計算資源和存儲空間跑模型來說,AI Studio提供全套免費服務(計算資源免費,空間資源免費,項目托管免費,視頻教程也免費)。可以說AI Studio從教學、應用、工程上全面推進了AI民主化的進程,極大的降低了AI技術跨入門檻。
1.功能簡介
第一次進入主頁,首先的感覺這是個類似Kaggle的數據競賽平臺,但是仔細看來,AI Studio強化了工程項目的概念,一大亮點就是AI學習項目這個版塊,里面包括大量真實場景的工程項目(圖像識別,情感分析,個性化推薦等);另一個重要組成就是比賽了,眾所周知構建良性循環的產、學、研社區是行業發展的重要組成部分,不過目前AI Studio組織的比賽還剛起步,希望后續比賽多多,大家在這里都能學到知識,交到朋友,最重要的是,可以在學習的同時給自己賺點零用錢花花(笑~)。
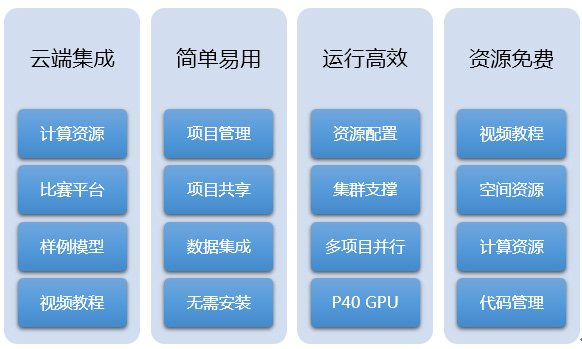
Figure 1 AI Studio特性
AI Studio主要功能有項目類的項目大廳,創建項目,樣例項目,共享項目等四大部分,有數據科學比賽,有各種經典數據集和自定義數據集,有詳盡的機器學習和深度學習的教程及視頻公開課等。下面就簡單的來介紹一下:
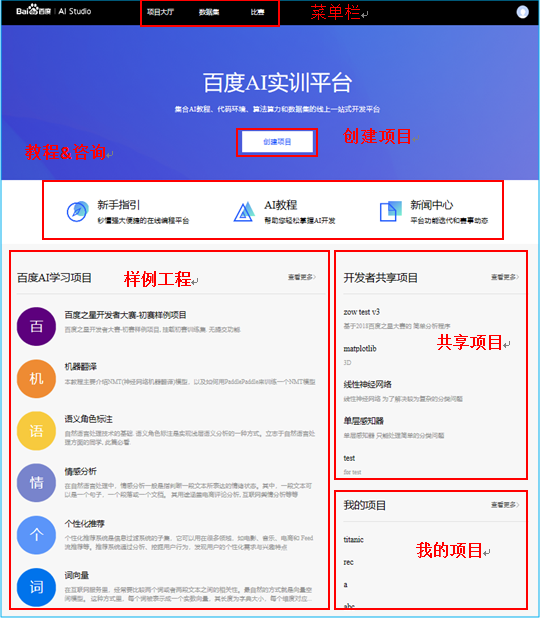
Figure 2 AI Studio主要功能
1.1. 菜單欄
1.1.1. 項目大廳
作為AI Studio的主頁,集成百度積累的經典AI學習項目,自我的項目管理及共享項目列表。整個平臺都是以項目為核心的,也凸顯了AI Studio的定位,就是以技術及資源輸出幫助個人開發者,中小企業快速擁有AI能力以更好的服務自身業務。
1.1.2. 數據集
數據集包括一些經典的公開數據集,像MNIST,IMDB,CIFAR10,Penn Treebank,MovieLens等;也包括一些開放的百度數據(中文短文本語料,信息抽取數據)。不過相比Kaggle近萬份數據集來說,仍然有很大的發展空間,但是個人感覺AI Studio的數據集還是要比Tianchi的數據集規整很多的。當然,用戶也可以上傳自定義數據進行模型開發。
1.1.3. 比賽
這個模塊應該是所有玩數據的人最感興趣的了吧。我之前在Kaggle參加過一些項目,總的來說,Kaggle在比賽這塊做的真的很好,賽制清晰,社區完善,每次參加比賽都能有很大的提高。相較Kaggle,AI Studio的比賽數量還不多,不過以上提到的功能都有,另外就是AI Studio提供云端訓練平臺,這樣大家的武器庫相對平衡,能夠更公平的進行競賽。

Figure 3 AI Studio 比賽頁面
1.2. 創建項目
AI Studio以項目為單元進行開發。創建項目,添加數據集,運行開發環境(notebook kernel),就可以開始構建自己的模型進行開發生產了。目前,環境僅支持Python2.7(期待更多的環境,Python3,R等),算法框架包括paddlepaddle和sklearn等。

Figure 4 AI Studio創建項目頁面
1.3. 教程&資訊
關于教程,paddlepaddle關于機器學習的教程應該是中文里最好的,不僅有機器學習、深度學習的視頻公開課和教程文檔(獲取),而且包含了大量的各個方向的深度學習實例,比如圖像分類,詞向量,個性化推薦,情感分析,語義角色標注以及機器翻譯等,不僅從原理層面進行深入淺出的講解,更提供模型代碼逐行進行實操,可以說為Everyone can AI提供了強大的后盾。
1.3.1. 樣例工程
樣例工程即是提供的機器學習經典應用場景及歷屆比賽的notebook,我們可以把各個項目fork到自己的項目下進行開發學習。對于急于構建AI能力的中小企業,這個模塊是最大福音了,很久之前看過Tensorflow的文檔,只有幾個典型問題的教程及代碼,而這里包括了大量的基于不同場景的AI模型可供拿來即用。

1.3.2. 共享項目
顧名思義,AI Studio也提供項目共享功能供大家互相學習。在開源的時代,能夠培育成熟活躍的社區是平臺發展的必要因素,這也是Tensorflow能夠在深度學習領域中快速推廣的重要原因。
1.3.3. 我的項目
這里是開發者自己的項目列表,不再贅述。
2.實戰建模
AI Studio以項目為核心,創建項目的同時可以自定義上傳數據,也可以選取平臺已有數據集;目前,環境僅支持Python2.7,算法庫包括sklearn和PaddlePaddle。不需要費心在開發環境上,能夠安心構造模型,將建模工程云服務化應該是未來趨勢(能夠方便中小企業快速構建AI能力)。在AI Studio各項目之間是獨立分配資源的,可以同時調試多個項目模型,這點還是非常贊的。
我這里創建了兩個共享項目,查看代碼直接fork項目開箱即用(需百度賬號登錄:Titanic項目,個性化推薦項目),代碼詳見附錄及共享項目。第一個項目是最最基礎的數據科學的入門問題titanic預測是否生還(自主上傳數據,調用sklearn隨機森林模型);第二,利用已有數據(MovieLens)及PaddlePaddle構建個性化推薦模型。一個小問題就是創建項目后進入項目頁面,進入運行狀態還需要點擊運行項目,這里感覺有點冗余;運行的項目就是一個簡潔的notebook開發環境,該有的功能都有,個人感覺速度比Kaggle要好很多(不知是不是我的網速渣)。
Figure 5 AI Studio項目界面
開發環境主體是由notebook形式組成,熟悉jupyter的同學可以無縫銜接,比notebook好的一點就是項目的數據集都會形成列表,簡單一鍵獲取數據路徑。菜單欄更簡潔,基本功能都有,可以保存notebook,有個有意思的地方是在創建項目的時候環境只能選Python2.7,但這里kernel選擇會出現Python3。
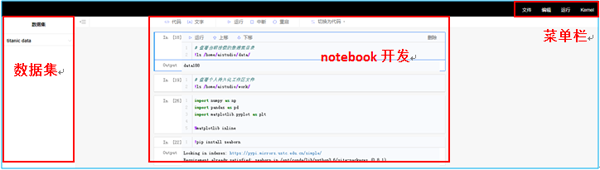
Figure 6 AI Studio開發頁面
3.群雄逐鹿
作為一站式AI建模開發平臺AI Studio,如何在強手如云的AI開發平臺市場殺出一條血路呢?最重要的途徑就是完善比賽社區的理念,通過PaddlePaddle+AI Studio的方式搶占數據科學競賽這個領域,這里就簡要比較一下幾家數據競賽平臺(AI Studio、Kaggle、天池、DataCastle等)。以下將從對開發者的能力提升,平臺比賽的公平性和比賽收獲等三個方面闡述。
3.1. 能力提升
可以說參加數據建模比賽是最好的提升自身能力的方式了,在比賽中,不但能夠了解各行各業的業務形式,數據結構,也能真實的驗證我們對特征和算法的不同理解,而良好的社區環境和代碼共享機制為自身能力的提升提供了溫床。在這方面,Kaggle因為成立最早有很強的人才和代碼沉淀,投靠Google后,更是愈發的體現了其中的優勢。天池和DataCastle在社區建設上也投入了大量的精力,但是與Kaggle還是有較大的差距,不過在中文社區中應該算是佼佼者。AI Studio顯然有后來者的劣勢,不過看過他們的樣例項目,還是很佩服他們在教程和文檔方面的思考,可以說在AI中文教程里AI Studio大踏步的跨入了第一梯隊。
3.2. 比賽的公平性
這里的公平性體現在兩個方面,第一是賽題的數據量要有一定的規模以防止數據量過小導致的模型穩定性問題;第二則是計算資源的公平性,舉個栗子,假如阿里組隊以P100 GPU集群的算力來參賽的話,恐怕其他人的勝算只能寄托于奇跡了,而對于ImageNet那樣量級的數據,我們只有PC機的話恐怕連一次迭代也完成不了,更不要說模型調優了。
在這方面,AI Studio具有極大的優勢,平臺不僅免費對參賽選手給予計算資源上的支持,更是提供最新版本的PaddlePaddle供選手調用。而天池在初賽階段是沒有集群算力支持的,只有進入復賽的選手才會有機會使用數加平臺。Kaggle和DataCastle更是沒有平臺的支持。相比來說在比賽資源的公平性上AI Studio的優勢巨大。
3.3. 比賽收獲
這里的收獲是只除了能力以外的物質方面的獲得,比如現金獎勵和簡歷背書。這兩點對于初入職場的新人還是非常重要的。客觀來講,國際影響力的話Kaggle絕對是No.1,致力于進入Google、facebook的同學最好還是在Kaggle上挑選優質的比賽;針對國內的話,AI Studio、天池和DataCastle在獎金方面相差不大,由于AI Studi推出最晚,所以獎金相對來說高一些。
綜合來看,AI Studio作為數據科學競賽中的新人,背靠百度資源,憑借更加公平的平臺資源輸出,獎勵制度和完善的教程文檔體系將會在未來大規模的搶占數據競賽市場。對開發者來說,免費使用GPU資源,更簡單的開發流程已經是很大的誘惑了。
4.百度AI戰略
身處AI圈,對各家的AI產品戰略比較感興趣,最近有意思的事情就是Baidu Create 2018了,會上,李彥宏的AI夢完成了從All In AI到Everyone Can AI的升華。發布的AI產品從自動駕駛巴士“阿波龍”到百度自主研發的云端AI 芯片“昆侖”,再到兩大AI生態平臺DuerOS3.0、Apollo3.0,可以說百度在AI的布局已經從稚嫩走向成熟,以多兵種合成集團軍的面貌展示在世界人工智能的舞臺。
百度的AI戰略重在開放,強調技術賦能。
根據百度的說法, 目前已經形成了以行業應用為牽引,AI技術產品服務為動力,AI基礎平臺服務為核心的生態閉環(AI開放平臺)。從百度公開的資料上看, ,百度已經將AI服務應用于智慧零售,金融科技,商業地產,企業服務,智能硬件,教育培訓等各行各業。比如說智慧零售, 百度提供基礎能力, 合作伙伴進行集成和落地, 將人臉識別,人體分析,圖像識別,大數據分析研判等服務賦能給線下門店,商場超市,各大品牌商等零售業態,有效提升了商業效率及利潤率。在技術服務上,百度提供全面的AI能力,包括語音技術圖像技術,人臉識別,視頻技術,等等等等, 據說已經超過110項能力 在平臺服務上,百度不僅有Apollo自動駕駛開放平臺和DuerOS對話式開放平臺,也包括像AI Studio囊括AI教程、開發環境、算法算力的一站式AI開發平臺,EasyDL圖像自定義模型構建平臺以及基礎的深度學習框架PaddlePaddle。
可見,百度在這場智能化革命中=不但醞釀已久,而且已經結出了不少果實。
5.總結
AI Studio是一個基于PaddlePaddle的集成了大量數據集、經典樣例項目及比賽項目的云計算建模平臺,也是一個機器學習、深度學習的交流社區。AI Studio最大限度的解放了數據科學家需要環境配置的煩惱,在云端集成計算資源,項目管理,代碼管理,比賽等多種功能,形成一站式兼顧學習和工作的建模平臺。而且AI Studio提供計算資源,空間資源,視頻公開課都是免費的!免費的!免費的!(所謂重要的事情說三遍)。最后,期待一下的更多比賽的推出。
參考文獻
- http://aistudio.baidu.com
- http://ai.baidu.com/
- http://www.paddlepaddle.org/
- http://ai.baidu.com/paddlepaddle
附錄
- # 查看當前掛載的數據集目錄
- !ls /home/aistudio/data/
- # 查看個人持久化工作區文件
- !ls /home/aistudio/work/
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- # titanic problem
- # 數據集是經典的機器學習問題,titanic的原始數據,以下是在AI Studio平臺上Python2.7環境,完整的從數據清洗,數據處理,特征工程,到運用
- # 隨機森林構建模型
- # 最簡單的模型開發流程如下
- # - 數據讀入
- # - 特征工程
- # - 數據分割
- # - 模型訓練
- # - 模型評估
- # - 交叉檢驗
- ## 數據讀入
- # 創建項目的時候讀入數據,通過ls /home/aistudio/data/查看數據集目錄,添加數據。
- data_train = pd.read_csv('/home/aistudio/data/data188/train.csv')
- data_test = pd.read_csv('/home/aistudio/data/data188/test.csv')
- data_train.sample(3)
- ## 特征工程
- ### 數據清洗及特征處理
- # 對特征進行如下處理:
- # - 對特征Age進行分箱離散化處理(simplify_ages)
- # - 提取特征Cabin進行類別化處理(simplify_cabins)
- # - 對特征Fare進行分箱離散化處理(simplify_fares)
- # - 對特征名字進行處理(format_name)
- # - 刪掉意義不大的特征(drop_features)
- def simplify_ages(df):
- df.Age = df.Age.fillna(-0.5)
- bins = (-1, 0, 5, 12, 18, 25, 35, 60, 120)
- group_names = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior']
- categories = pd.cut(df.Age, bins, labels=group_names)
- df.Age = categories
- return df
- def simplify_cabins(df):
- df.Cabin = df.Cabin.fillna('N')
- df.Cabin = df.Cabin.apply(lambda x: x[0])
- return df
- def simplify_fares(df):
- df.Fare = df.Fare.fillna(-0.5)
- bins = (-1, 0, 8, 15, 31, 1000)
- group_names = ['Unknown', '1_quartile', '2_quartile', '3_quartile', '4_quartile']
- categories = pd.cut(df.Fare, bins, labels=group_names)
- df.Fare = categories
- return df
- def format_name(df):
- df['Lname'] = df.Name.apply(lambda x: x.split(' ')[0])
- df['NamePrefix'] = df.Name.apply(lambda x: x.split(' ')[1])
- return df
- def drop_features(df):
- return df.drop(['Ticket', 'Name', 'Embarked'], axis=1)
- def transform_features(df):
- df = simplify_ages(df)
- df = simplify_cabins(df)
- df = simplify_fares(df)
- df = format_name(df)
- df = drop_features(df)
- return df
- data_train = transform_features(data_train)
- data_test = transform_features(data_test)
- data_train.head()
- ### 特征處理
- # - 篩選可用的特征
- # - 對類別特征做數值化處理
- from sklearn import preprocessing
- def encode_features(df_train, df_test):
- features = ['Fare', 'Cabin', 'Age', 'Sex', 'Lname', 'NamePrefix']
- df_combined = pd.concat([df_train[features], df_test[features]])
- for feature in features:
- le = preprocessing.LabelEncoder()
- le = le.fit(df_combined[feature])
- df_train[feature] = le.transform(df_train[feature])
- df_test[feature] = le.transform(df_test[feature])
- return df_train, df_test
- data_train, data_test = encode_features(data_train, data_test)
- data_train.head()
- ## 數據分割
- # 對數據集進行訓練集和測試集的分割
- from sklearn.model_selection import train_test_split
- X_all = data_train.drop(['Survived', 'PassengerId'], axis=1)
- y_all = data_train['Survived']
- num_test = 0.20
- X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=num_test, random_state=23)
- ## 模型訓練
- # 選取隨機森林模型,利用網格搜索進行參數調優。
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.metrics import make_scorer, accuracy_score
- from sklearn.model_selection import GridSearchCV
- # Choose the type of classifier.
- clf = RandomForestClassifier()
- # Choose some parameter combinations to try
- parameters = {'n_estimators': [4, 6, 9],
- 'max_features': ['log2', 'sqrt','auto'],
- 'criterion': ['entropy', 'gini'],
- 'max_depth': [2, 3, 5, 10],
- 'min_samples_split': [2, 3, 5],
- 'min_samples_leaf': [1,5,8]
- }
- # Type of scoring used to compare parameter combinations
- acc_scorer = make_scorer(accuracy_score)
- # Run the grid search
- grid_obj = GridSearchCV(clf, parameters, scoring=acc_scorer)
- grid_obj = grid_obj.fit(X_train, y_train)
- # Set the clf to the best combination of parameters
- clf = grid_obj.best_estimator_
- # Fit the best algorithm to the data.
- clf.fit(X_train, y_train)
- ## 模型評估
- # 用準確率評估模型效果
- predictions = clf.predict(X_test)
- print(accuracy_score(y_test, predictions))
- ## 交叉檢驗
- # KFold
- from sklearn.cross_validation import KFold
- def run_kfold(clf):
- kf = KFold(891, n_folds=10)
- outcomes = []
- fold = 0
- for train_index, test_index in kf:
- fold += 1
- X_train, X_test = X_all.values[train_index], X_all.values[test_index]
- y_train, y_test = y_all.values[train_index], y_all.values[test_index]
- clf.fit(X_train, y_train)
- predictions = clf.predict(X_test)
- accuracy = accuracy_score(y_test, predictions)
- outcomes.append(accuracy)
- print("Fold {0} accuracy: {1}".format(fold, accuracy))
- mean_outcome = np.mean(outcomes)
- print("Mean Accuracy: {0}".format(mean_outcome))
- run_kfold(clf)
- ids = data_test['PassengerId']
- predictions = clf.predict(data_test.drop('PassengerId', axis=1))
- output = pd.DataFrame({ 'PassengerId' : ids, 'Survived': predictions })
- # output.to_csv('titanic-predictions.csv', index = False)
- output