說說對數據庫讀寫分離的理解
作者:lyl
數據庫讀寫分離是一種有效的優化策略,可以提高數據庫的性能、可擴展性和可用性。然而,它也需要仔細的設計和管理,以確保數據的一致性、故障切換的可靠性以及負載均衡的有效性。
數據庫讀寫分離是一個在數據庫管理和優化中非常重要的概念,特別是在面對大量并發讀寫請求的場景時。以下是對數據庫讀寫分離的詳細理解:
一、讀寫分離的定義
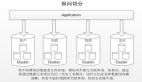
讀寫分離是指將數據庫的讀操作和寫操作分離開來,分別由不同的數據庫實例或服務器來處理。通常,一個主數據庫(Master)負責處理寫操作(如插入、更新、刪除),而一個或多個從數據庫(Slave)負責處理讀操作(如查詢)。
二、讀寫分離的目的
- 提高性能:通過將讀寫操作分離,可以避免寫操作對讀操作的干擾,提高數據庫的查詢性能和響應速度。同時,讀請求可以被分散到多個從數據庫上,實現負載均衡。
- 增強可擴展性:當系統需要擴展時,可以很容易地添加更多的從數據庫來承擔讀請求,而無需對主數據庫進行復雜的修改或升級。
- 提高可用性:在主數據庫發生故障時,可以將從數據庫快速切換為主數據庫,繼續提供服務,從而減少系統的停機時間和數據丟失風險。
三、讀寫分離的實現方式
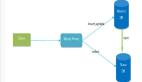
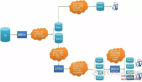
- 基于主從復制:這是最常見的讀寫分離實現方式。主數據庫負責處理寫操作,并將這些操作復制到一個或多個從數據庫上。從數據庫可以實時或異步地接收這些更新,并根據需要處理讀請求。
- 基于中間件:有些系統使用專門的中間件來管理讀寫分離。這些中間件通常位于應用程序和數據庫之間,負責將讀請求和寫請求路由到正確的數據庫實例上。
- 基于智能路由:一些高級數據庫系統支持智能路由功能,可以根據當前的負載情況和數據庫實例的狀態動態地調整讀寫請求的路由策略。
四、讀寫分離的挑戰和注意事項
- 數據一致性:由于主從復制可能存在延遲,從數據庫上的數據可能不是最新的。這可能導致讀請求返回過時的數據,需要應用程序進行處理或校正。
- 故障切換:在主數據庫發生故障時,需要快速且準確地將從數據庫切換為主數據庫,以確保系統的連續性和穩定性。這通常需要額外的監控和故障恢復機制。
- 負載均衡:需要合理地分配讀請求到不同的從數據庫上,以避免某些數據庫過載而其他數據庫空閑的情況。這可能需要動態的負載均衡策略和調整機制。
- 維護成本:管理多個數據庫實例(特別是從數據庫)可能會增加系統的維護成本和復雜性。需要定期備份、監控和調優這些數據庫,以確保它們的性能和可用性。
五、總結
數據庫讀寫分離是一種有效的優化策略,可以提高數據庫的性能、可擴展性和可用性。然而,它也需要仔細的設計和管理,以確保數據的一致性、故障切換的可靠性以及負載均衡的有效性。在實際應用中,需要根據具體的業務需求和系統架構選擇合適的讀寫分離實現方式,并進行持續的監控和優化。
責任編輯:武曉燕
來源:
程序員編程日記