













什么是最好的面部檢測(cè)器? | Dlib、OpenCV DNN、Yunet、Pytorch-MTCNN和RetinaFace
我正在處理的面部識(shí)別問題,需要選擇一個(gè)面部檢測(cè)模型。面部檢測(cè)是面部識(shí)別流水線的第一步,準(zhǔn)確識(shí)別圖像中的面部至關(guān)重要。Garbage in, garbage out。
然而,眾多的選項(xiàng)讓我感到不知所措,而且關(guān)于這一主題的零散寫作還不夠詳細(xì),無法幫助我決定選擇哪種模型。比較各種模型花費(fèi)了我很多精力,因此我認(rèn)為傳達(dá)我的研究可能會(huì)幫助處于類似情況的人們。

面部檢測(cè)器的選擇要點(diǎn)是什么?
選擇面部檢測(cè)模型時(shí)的主要權(quán)衡是準(zhǔn)確性和性能之間的平衡。但還有其他因素需要考慮。關(guān)于面部檢測(cè)模型的大多數(shù)文章要么是模型創(chuàng)建者寫的,通常發(fā)表在期刊上,要么是那些在代碼中實(shí)現(xiàn)模型的人寫的。在這兩種情況下,作者自然會(huì)對(duì)他們所寫的模型持有偏見。在一些極端情況下,這些文章實(shí)際上是該模型的宣傳廣告。
很少有文章比較不同模型的性能表現(xiàn)。進(jìn)一步增加混亂的是,每當(dāng)有人寫關(guān)于像RetinaFace這樣的模型時(shí),他們討論的是該模型的特定實(shí)現(xiàn)。模型本身實(shí)際上是神經(jīng)網(wǎng)絡(luò)架構(gòu),不同的實(shí)現(xiàn)可能會(huì)導(dǎo)致不同的結(jié)果。更復(fù)雜的是,這些模型的性能還取決于后處理參數(shù),如置信度閾值、非極大值抑制等。
每個(gè)作者都將自己的模型描述為“最好”,但我很快意識(shí)到“最好”取決于上下文。沒有客觀上最好的模型。決定哪個(gè)面部檢測(cè)模型最合適的兩個(gè)主要標(biāo)準(zhǔn)是準(zhǔn)確性和速度。
沒有一個(gè)模型能同時(shí)具備高準(zhǔn)確性和高速度,這是一個(gè)權(quán)衡。我們還必須查看原始準(zhǔn)確性之外的指標(biāo),大多數(shù)基準(zhǔn)測(cè)試基于原始準(zhǔn)確性(正確猜測(cè)/總樣本量),但原始準(zhǔn)確性不是唯一需要關(guān)注的指標(biāo)。假陽性與真陽性的比率以及假陰性與真陰性的比率也是重要的考慮因素。用技術(shù)術(shù)語來說,這種權(quán)衡是精度(最小化假陽性)和召回率(最小化假陰性)之間的權(quán)衡。這篇文章深入討論了這個(gè)問題。
測(cè)試模型
有一些現(xiàn)有的用于基準(zhǔn)測(cè)試的面部檢測(cè)數(shù)據(jù)集,如WIDER FACE,但我總是喜歡看看這些模型在我的數(shù)據(jù)上表現(xiàn)如何。所以我隨機(jī)選取了1064幀電視節(jié)目樣本來測(cè)試這些模型(±3%的誤差范圍)。在手動(dòng)標(biāo)注每張圖像時(shí),我盡量選擇盡可能多的面部,包括部分或幾乎完全遮擋的面部,以給模型帶來真正的挑戰(zhàn)。因?yàn)槲易罱K要對(duì)檢測(cè)到的面部進(jìn)行面部識(shí)別,所以我想測(cè)試每個(gè)模型的極限。
數(shù)據(jù)和標(biāo)注可以從下面鏈接進(jìn)行下載:
- https://drive.google.com/uc?export=download&id=1OPAT47OXjgmjKlAY2irQLf4GNoHyMlhX(數(shù)據(jù))
- https://drive.google.com/uc?export=download&id=1UbrndfOvvzFIdU-w3Kw8qrFM6D_ZljJZ(標(biāo)注)
將各種模型分為兩類是有幫助的;那些運(yùn)行在GPU上的模型和那些運(yùn)行在CPU上的模型。一般來說,如果你有兼容CUDA的GPU,應(yīng)該使用基于GPU的模型。我有一個(gè)NVIDIA 1080 TI顯卡,具有11GB內(nèi)存,這使我能夠使用一些大規(guī)模的模型。然而,我的項(xiàng)目規(guī)模巨大(我指的是成千上萬的視頻文件),所以對(duì)速度極快的基于CPU的模型很感興趣。基于CPU的面部檢測(cè)模型不多,所以我決定只測(cè)試最受歡迎的一個(gè):YuNet。由于其速度,YuNet構(gòu)成了我的基線比較。一個(gè)GPU模型必須比其CPU對(duì)應(yīng)的模型準(zhǔn)確得多,以證明其較慢的處理速度是合理的。
CPU模型
YuNet
YuNet是為性能而開發(fā)的,其模型大小僅為較大模型的一小部分。例如,YuNet只有75,856個(gè)參數(shù),而RetinaFace則有27,293,600個(gè)參數(shù),這使得YuNet可以在“邊緣”計(jì)算設(shè)備上運(yùn)行,而這些設(shè)備不足以運(yùn)行較大的模型。
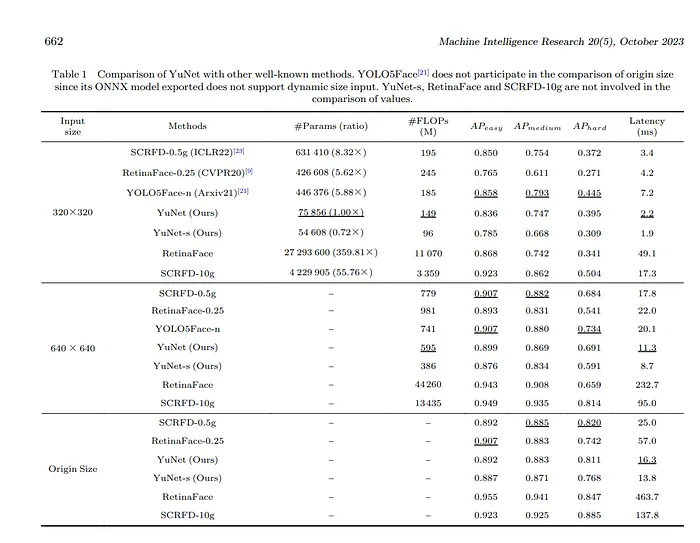
- 論文地址:https://doi.org/10.1007/s11633-023-1423-y
- 代碼地址:https://github.com/ShiqiYu/libfacedetection
- 預(yù)訓(xùn)練模型:https://github.com/opencv/opencv_zoo
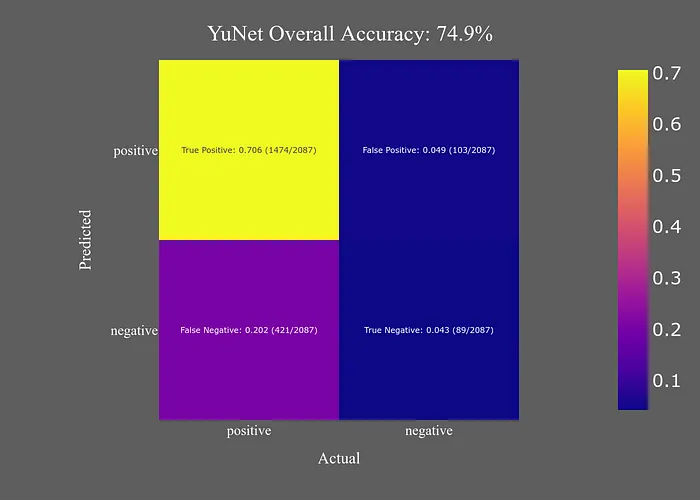
作為一個(gè)CPU模型,YuNet的表現(xiàn)比我預(yù)期的要好得多。它能夠毫無問題地檢測(cè)到大面部,但在檢測(cè)較小面部時(shí)有些困難。
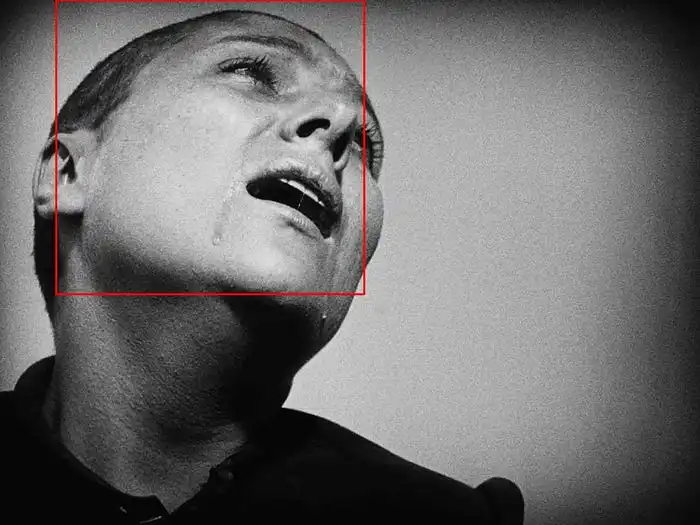
能夠檢測(cè)到即使在斜角度的大面部。邊界框有些偏差,可能是因?yàn)閳D像需要調(diào)整為300x300才能輸入到模型中。

YuNet幾乎找到了所有面部,但也包括了一些假陽性。
當(dāng)限制為圖像中的最大面部時(shí),準(zhǔn)確性大大提高。
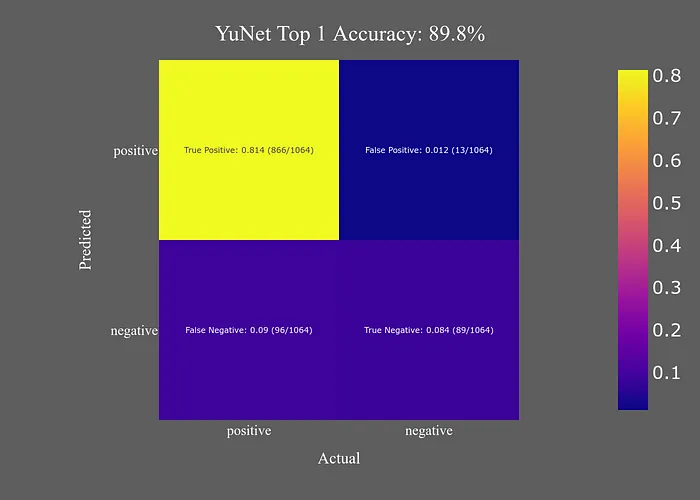
如果性能是主要考慮因素,YuNet是一個(gè)很好的選擇。它甚至足夠快,可以用于實(shí)時(shí)應(yīng)用,而GPU選項(xiàng)則不能(至少在沒有一些嚴(yán)重硬件的情況下)。
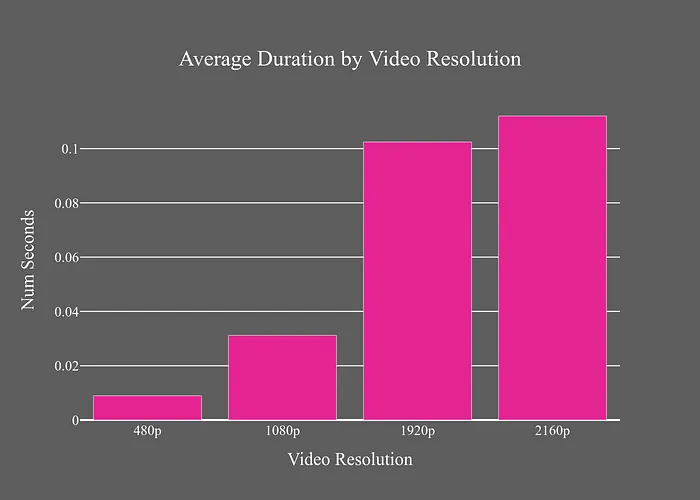
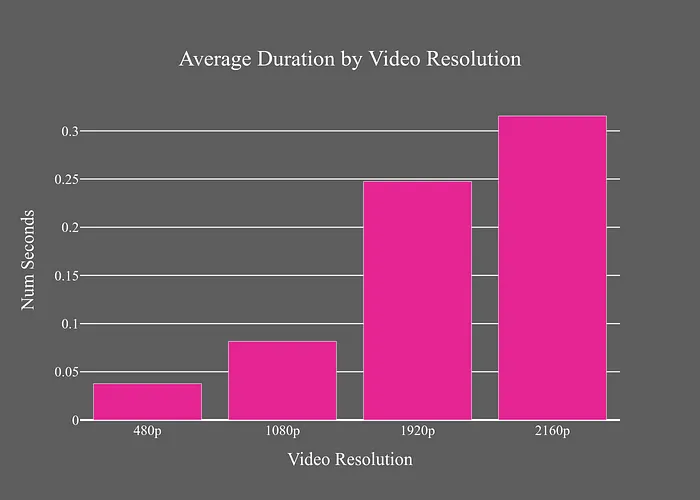
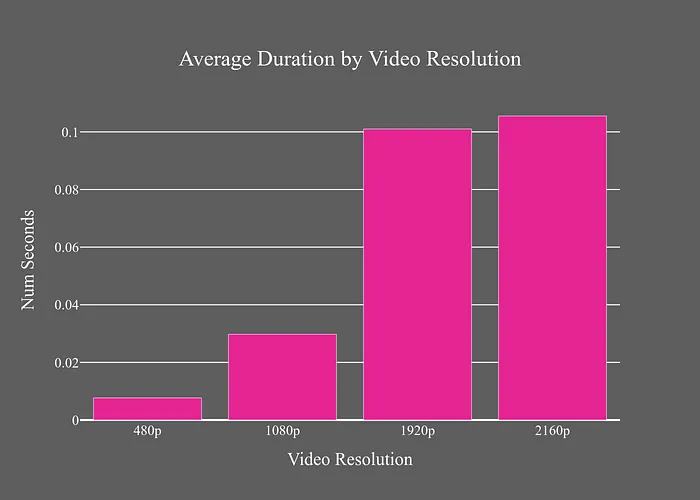
YuNet使用固定的300x300輸入尺寸,因此時(shí)間差異是由于將圖像調(diào)整為這些尺寸導(dǎo)致的。GPU模型
Dlib
Dlib是一個(gè)C++實(shí)現(xiàn),帶有Python包裝器,保持了準(zhǔn)確性、性能和便利性之間的平衡。Dlib可以直接通過Python安裝,也可以通過Face Recognition Python庫訪問。然而,Dlib的準(zhǔn)確性和性能在upsampling參數(shù)上有很強(qiáng)的權(quán)衡。當(dāng)上采樣次數(shù)設(shè)置為0時(shí),模型速度更快但準(zhǔn)確性較低。
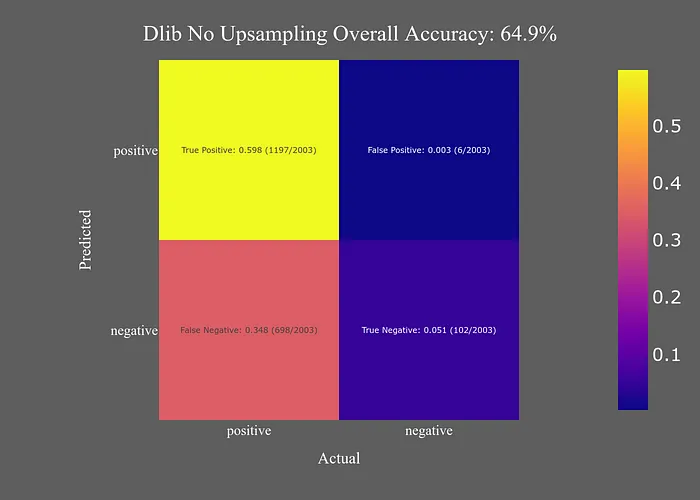
無上采樣
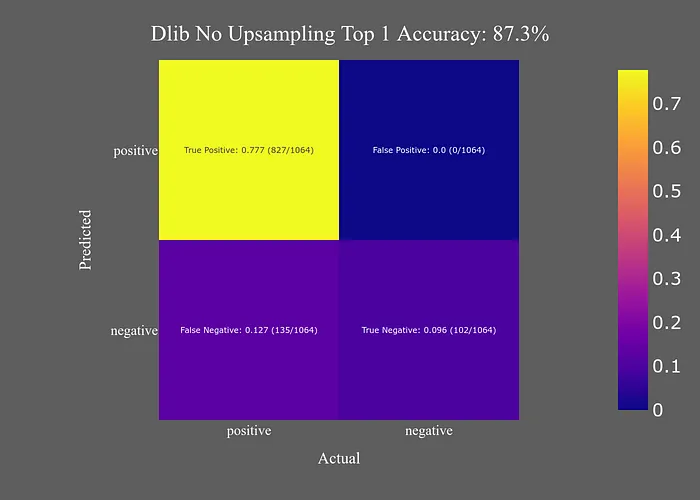
上采樣=1
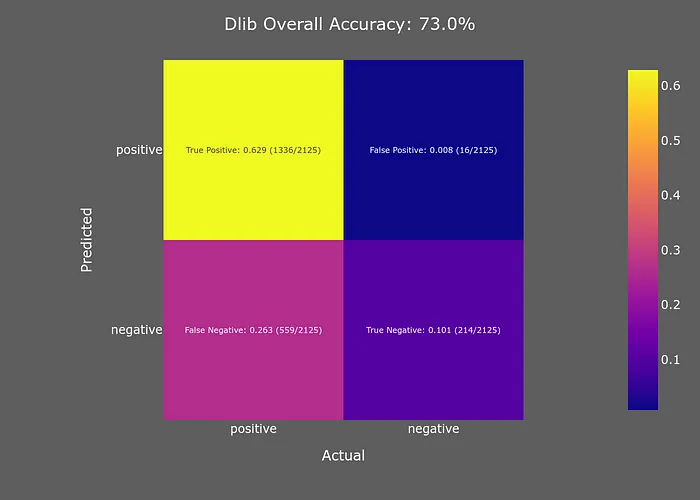
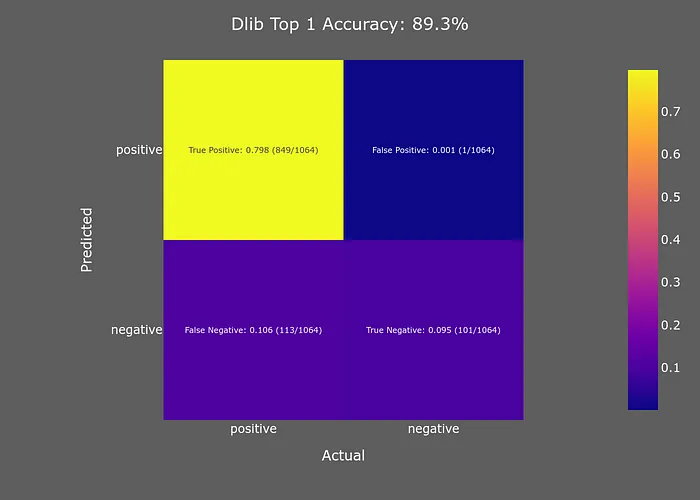

Dlib模型的準(zhǔn)確性隨著進(jìn)一步的上采樣而增加,但任何高于上采樣=1的值都會(huì)導(dǎo)致我的腳本崩潰,因?yàn)樗隽宋业腉PU內(nèi)存(順便說一下,我的內(nèi)存是11GB)。
Dlib的準(zhǔn)確性相對(duì)于其(缺乏)速度來說有些令人失望。然而,它在最小化假陽性方面表現(xiàn)非常好,這是我的優(yōu)先事項(xiàng)。面部檢測(cè)是我面部識(shí)別流水線的第一部分,因此最小化假陽性數(shù)量將有助于減少下游的錯(cuò)誤。為了進(jìn)一步減少假陽性數(shù)量,我們可以使用Dlib的置信度輸出來過濾低置信度的樣本。
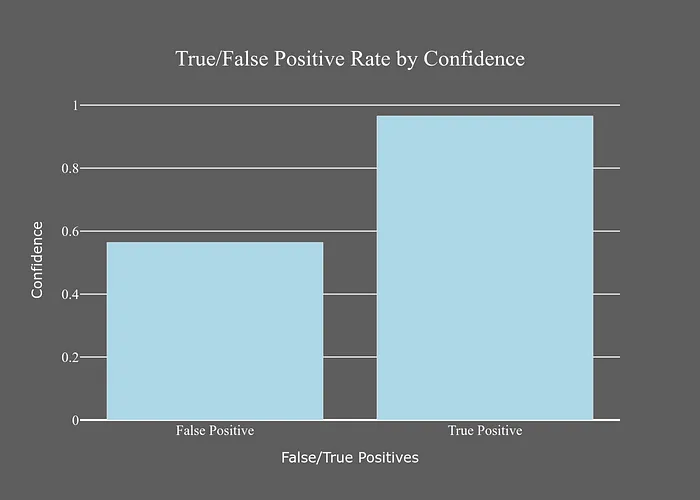
假陽性和真陽性之間的置信度差異很大,我們可以利用這一點(diǎn)來過濾前者。我們可以查看置信度分布來選擇一個(gè)更精確的閾值,而不是選擇一個(gè)任意的閾值。
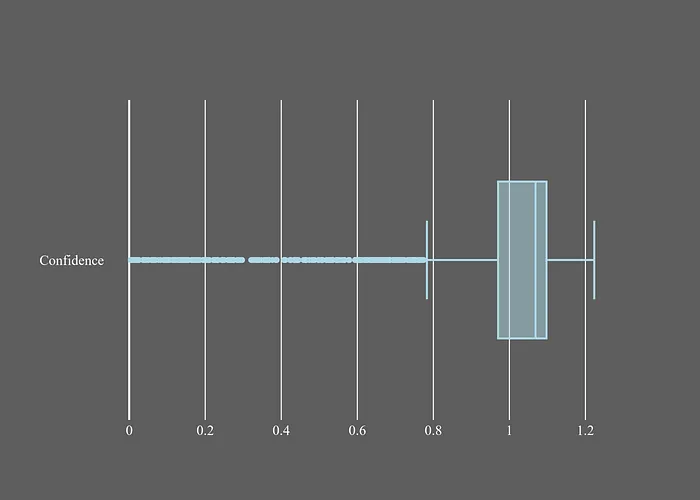
95%的置信度值在0.78以上,因此排除低于該值的所有內(nèi)容可以將假陽性數(shù)量減少一半。

雖然通過置信度過濾減少了假陽性數(shù)量,但并沒有提高整體準(zhǔn)確性。我會(huì)考慮在最小化假陽性數(shù)量是主要關(guān)注點(diǎn)時(shí)使用Dlib。但除此之外,Dlib在準(zhǔn)確性上并沒有比YuNet大幅增加,無法證明其更高的處理時(shí)間是合理的;至少對(duì)我的用途來說是這樣。
OpenCV DNN
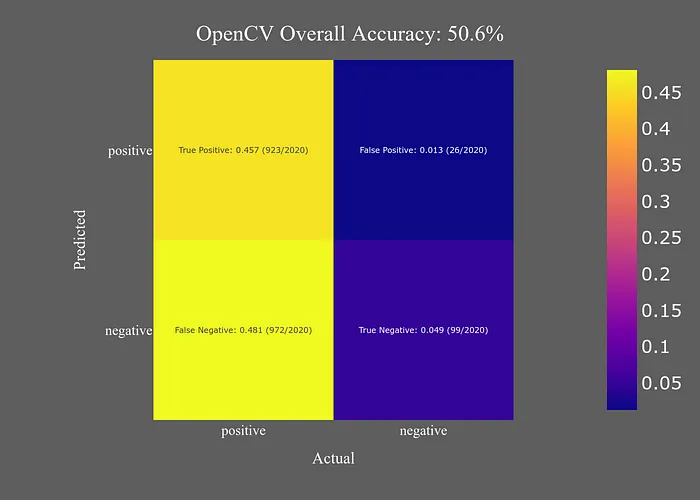
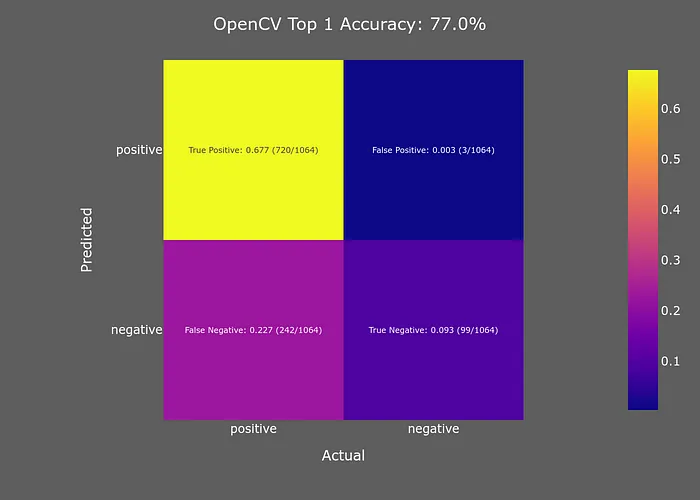
OpenCV面部檢測(cè)模型的主要吸引力在于其速度。然而,其準(zhǔn)確性令人失望。雖然與其他GPU模型相比,它速度非常快,但即使是Top 1準(zhǔn)確性也僅略好于YuNet的整體準(zhǔn)確性。我不清楚在什么情況下我會(huì)選擇OpenCV模型進(jìn)行面部檢測(cè),尤其是因?yàn)樗茈y正常工作。
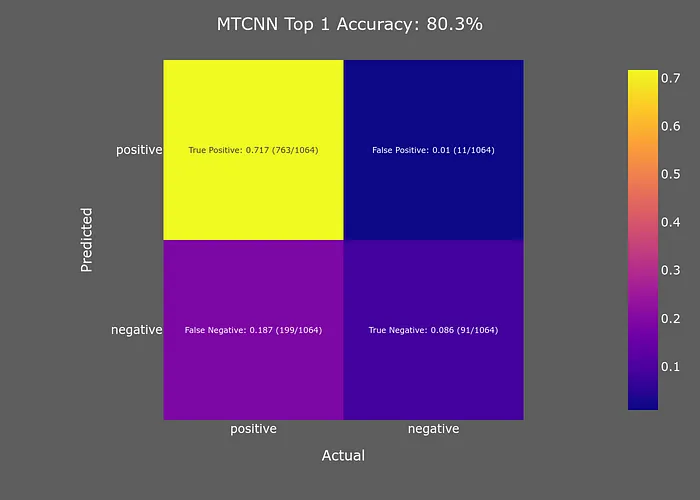
Pytorch-MCNN
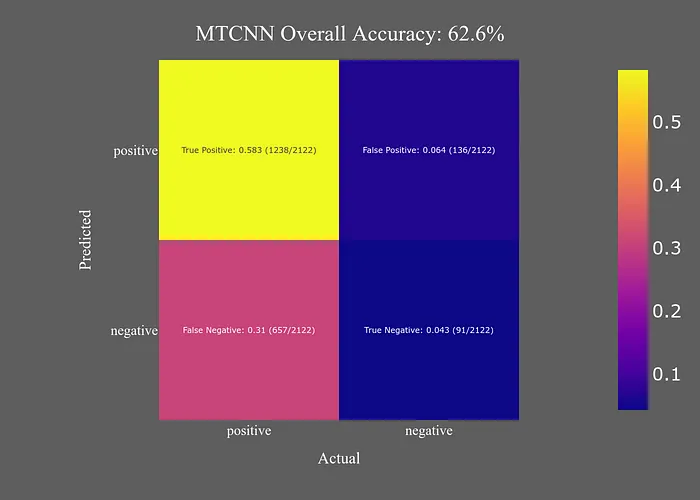
MTCNN模型的表現(xiàn)也很差。盡管它的準(zhǔn)確性略高于OpenCV模型,但速度要慢得多。由于其準(zhǔn)確性低于YuNet,沒有 compelling reason to select MTCNN。

RetinaFace
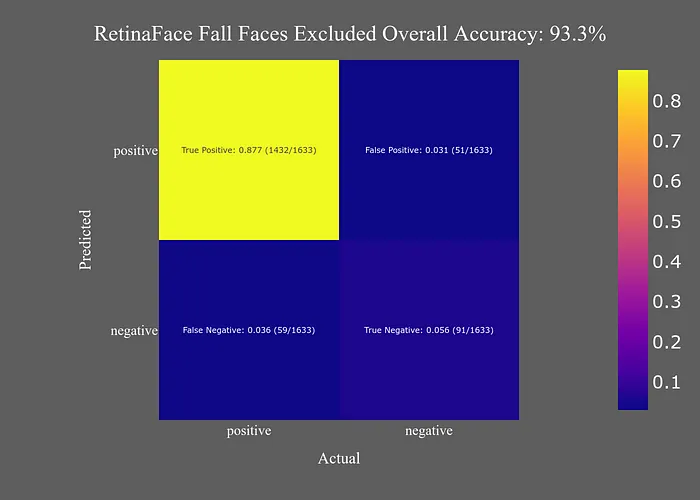
RetinaFace以其作為開源面部檢測(cè)模型中最準(zhǔn)確的聲譽(yù)而聞名。測(cè)試結(jié)果支持了這一聲譽(yù)。
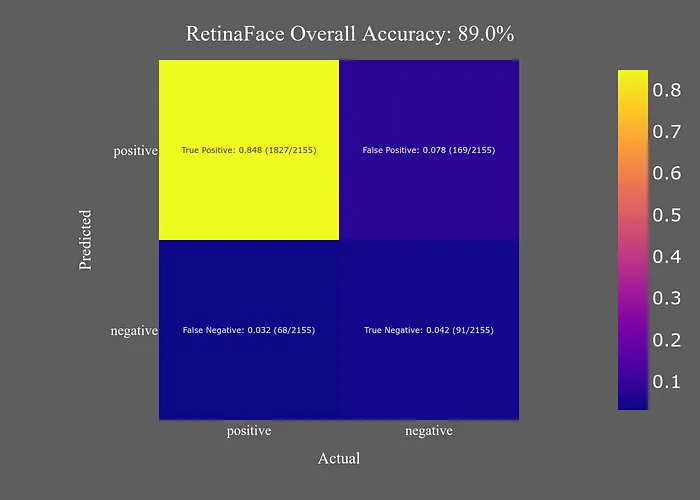
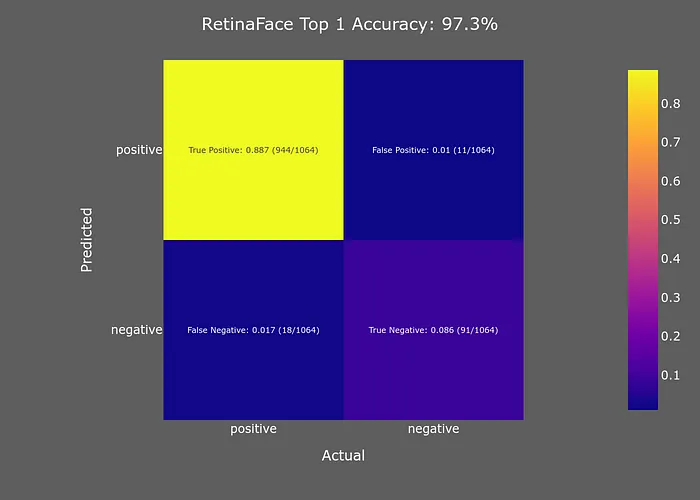
它不僅是最準(zhǔn)確的模型,而且許多“錯(cuò)誤”實(shí)際上并不是實(shí)際錯(cuò)誤。RetinaFace真的測(cè)試了“假陽性”這個(gè)類別,因?yàn)樗鼨z測(cè)到了一些我沒有看到的面部,沒有標(biāo)注的因?yàn)槲艺J(rèn)為它們太難了,或者沒有考慮是“面部”。
它在這張《Seinfeld》片段中的鏡子中檢測(cè)到了部分面部。

它在《Modern Family》的背景圖像中找到了面部。
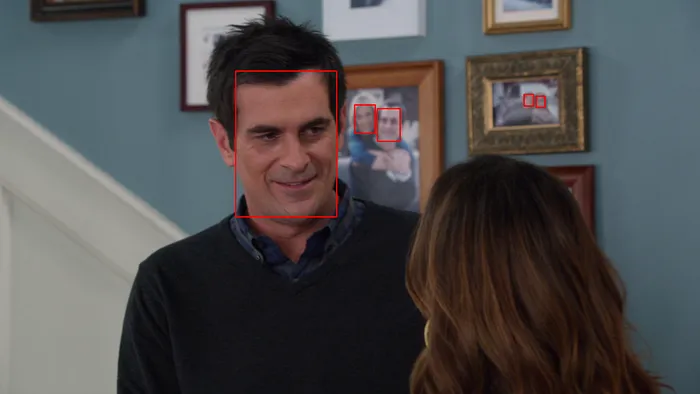
它在識(shí)別人臉方面如此出色,以至于找到了非人臉。

學(xué)習(xí)到RetinaFace并不算太慢是一個(gè)驚喜。雖然它不如YuNet或OpenCV快,但與MTCNN相當(dāng)。雖然它在低分辨率下比MTCNN慢,但它擴(kuò)展得相對(duì)較好,可以同樣快速地處理更高分辨率。RetinaFace擊敗了Dlib(至少在需要上采樣時(shí))。它比YuNet慢得多,但準(zhǔn)確性顯著提高。
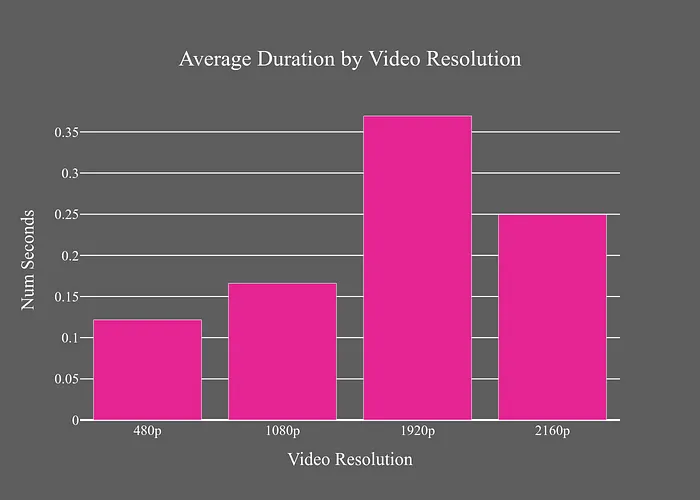
通過過濾掉較小的面部,可以排除RetinaFace識(shí)別的許多“假陽性”。如果我們刪除最低四分位的面部,假陽性率會(huì)大幅下降。
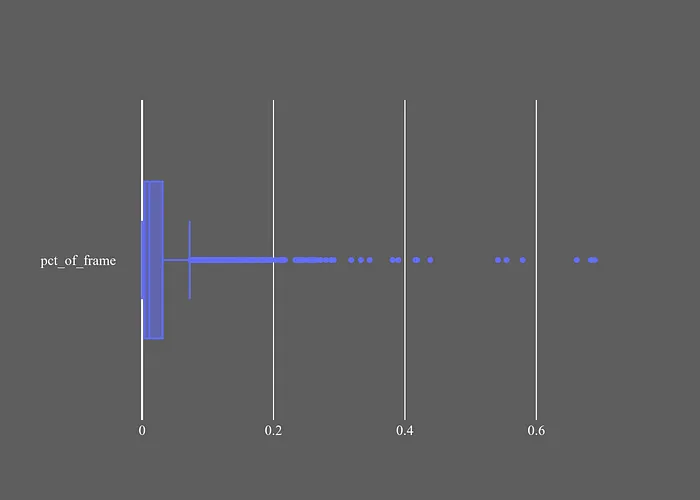
最低四分位的邊界是0.0035
雖然RetinaFace非常準(zhǔn)確,但其錯(cuò)誤確實(shí)有特定的偏差。雖然RetinaFace容易識(shí)別小面部,但它在檢測(cè)較大、部分遮擋的面部時(shí)存在困難,這在查看面部尺寸相對(duì)于準(zhǔn)確性時(shí)尤為明顯。
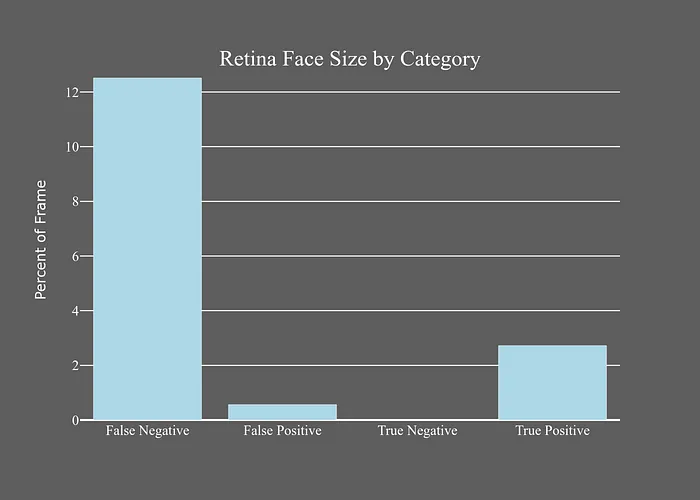
這對(duì)我的用途來說可能是個(gè)問題,因?yàn)閳D像中面部的大小與其重要性密切相關(guān)。因此,RetinaFace可能會(huì)錯(cuò)過最重要的情況,例如以下示例。

RetinaFace未能檢測(cè)到這張圖像中的面部,但YuNet做到了。
結(jié)論
根據(jù)我的測(cè)試(我想強(qiáng)調(diào)這些測(cè)試并不是世界上最嚴(yán)格的測(cè)試;所以要保留一點(diǎn)懷疑態(tài)度),我只會(huì)考慮使用YuNet或RetinaFace,具體取決于我的主要關(guān)注點(diǎn)是速度還是準(zhǔn)確性。可能在我絕對(duì)想要最小化假陽性數(shù)量時(shí)會(huì)考慮使用Dlib,但對(duì)于我的項(xiàng)目來說,只能選擇YuNet或RetinaFace。
完整的項(xiàng)目代碼在這里:https://github.com/astaileyyoung/CineFace























