別讓加密難倒你:Python爬蟲攻克加密網站的實戰教程
今天有個朋友向我求助,希望我幫他爬取一個網站上的內容。網站內容如下:
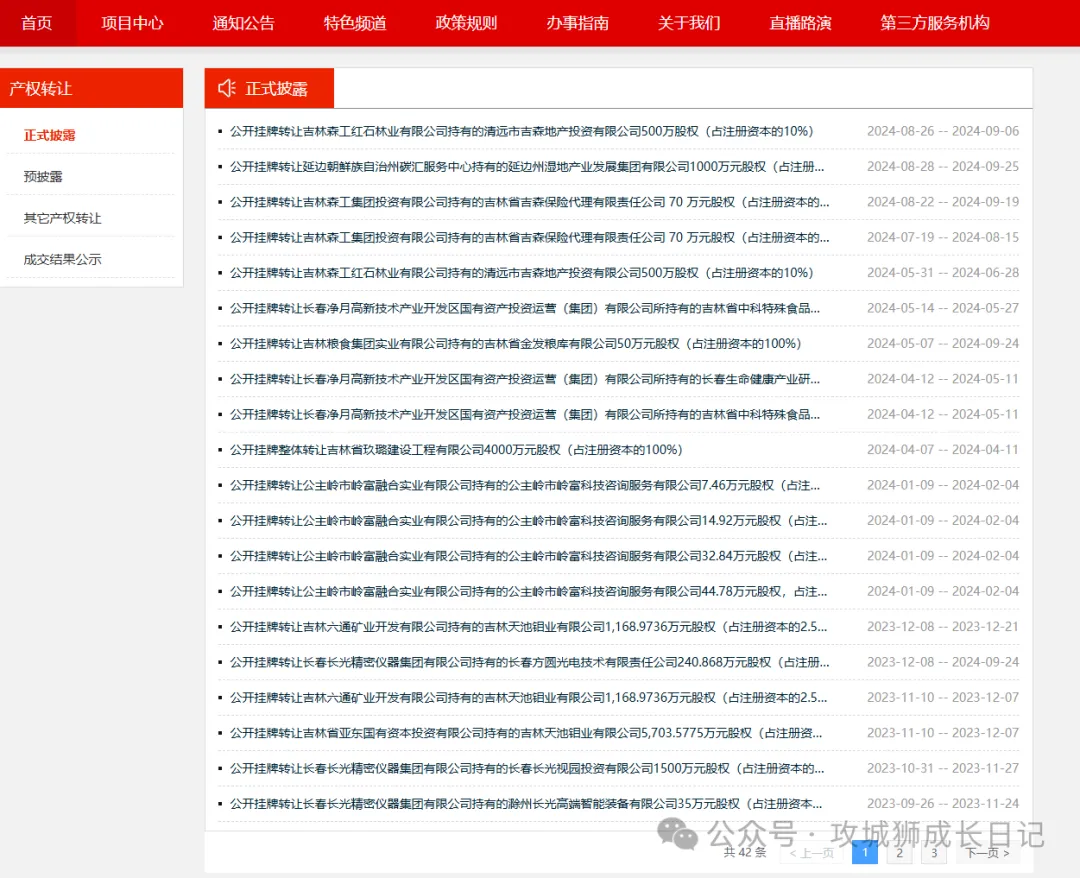
aHR0cHM6Ly93d3cuY2NwcmVjLmNvbS9uYXZDcXpyLyMvCg==打開上述網址,進入開發者模式,這些數據的請求接口,正常邏輯是通過搜索頁面上內容進行鎖定請求接口。但是,進行搜索時,發現什么都搜索不到。
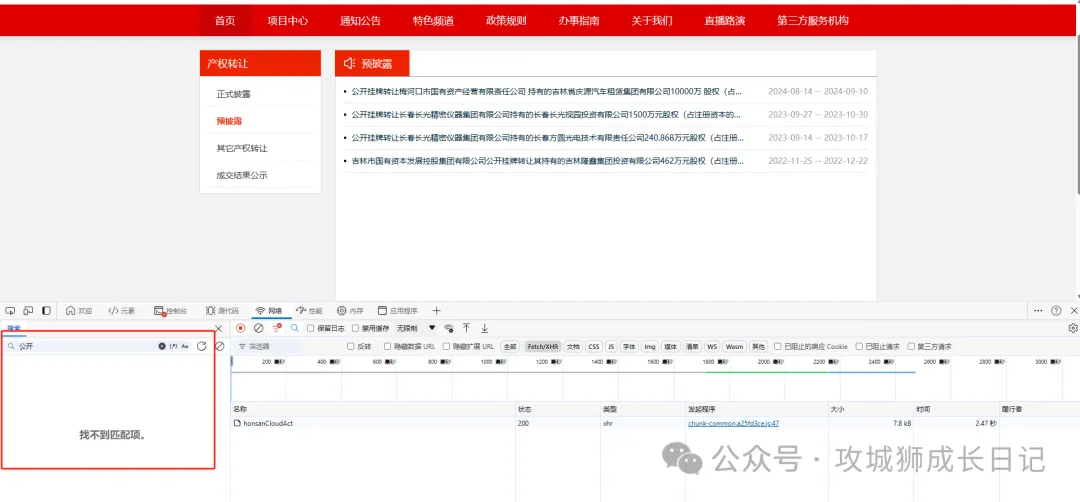
通過上圖發現,這些數據只請求了一個接口,當我點擊負載和響應這兩個標簽,發現數據是被加密了,所以,我們搜索不了頁面的內容。
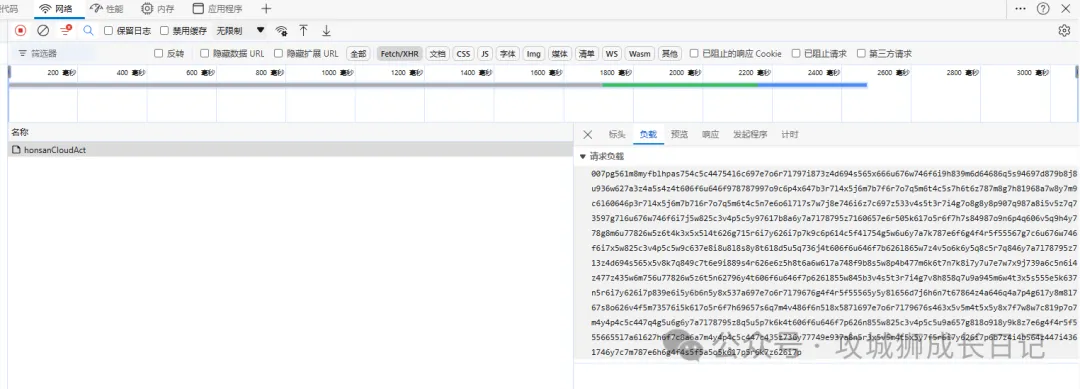
負載加密內容
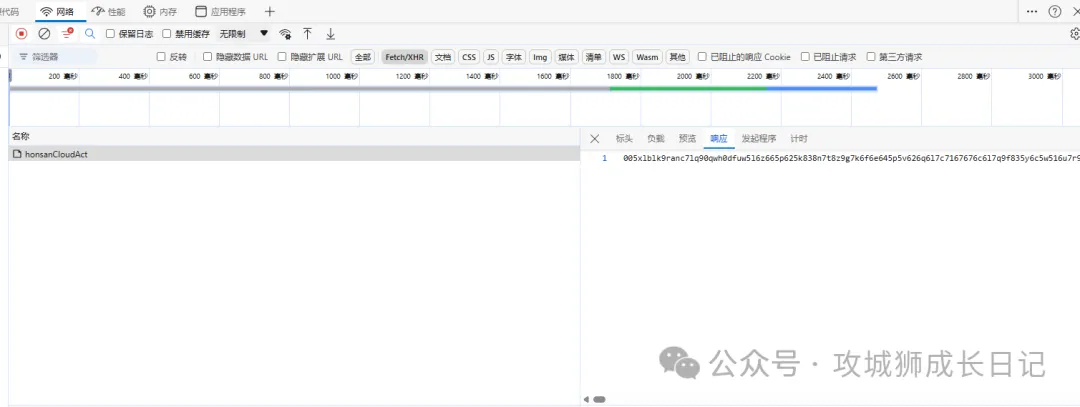
響應加密內容
瀏覽器為啥是明文?
這時相信小伙伴,心中都有一個疑問瀏覽器為啥是明文? 瀏覽器在收到數據后,會自動采用服務器返回的資源文件對加密內容進行解密并顯示明文,這也是我們能夠在頁面上看到正常內容的原因。
如何定位到加密資源文件
通過XHR/提取斷點,該方法是通過匹配URL包括請求路徑關鍵字進行斷點,具體配置如下圖:
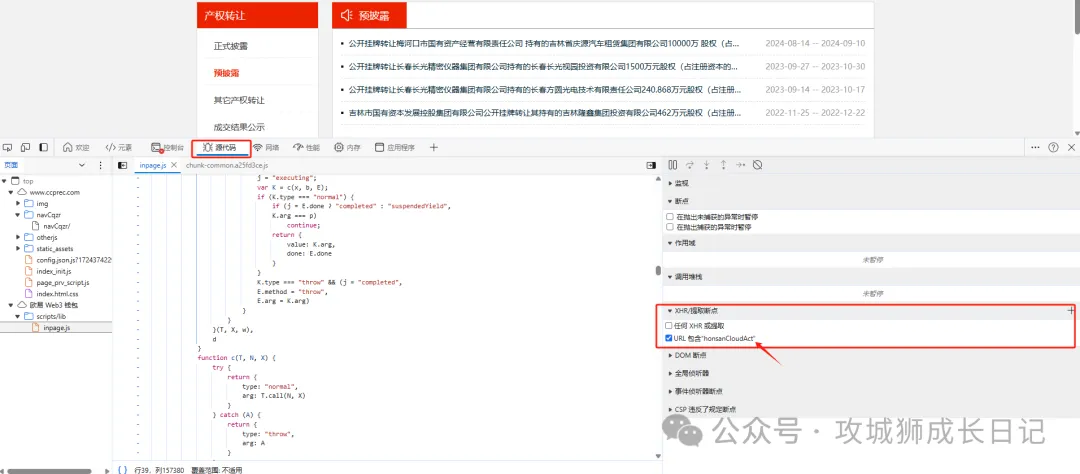
這時我們重新刷新網頁,如下圖所示,網站就成功進入我們上一步設置的斷點中。
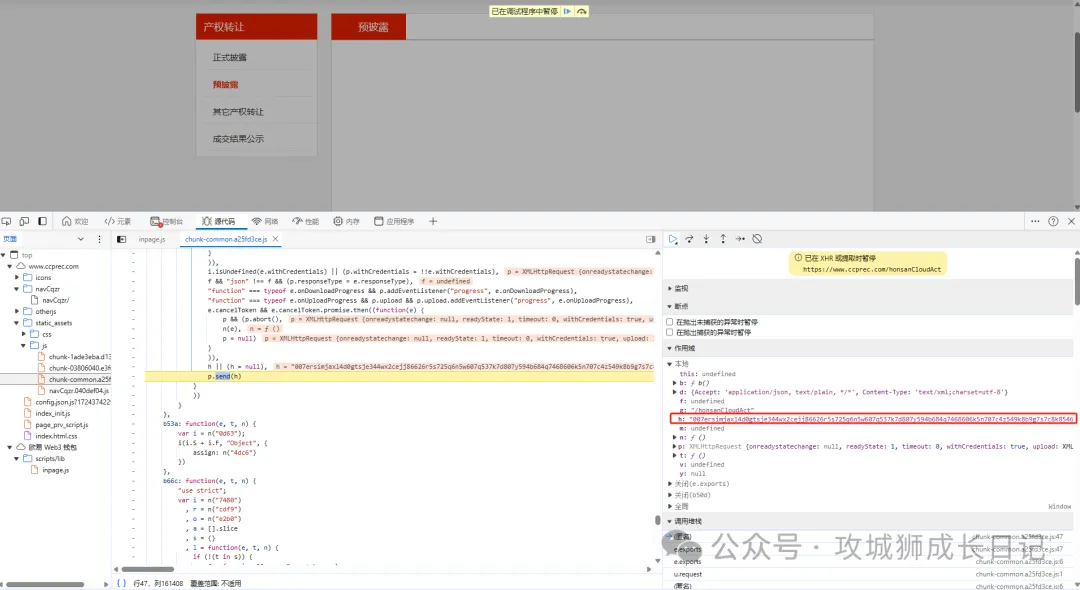
其中,h就是加密后的請求體參數,然后我們從調用堆棧中一步步往前推。至于如何找呢?這里是有一個技巧的,我們需要找到前一步請求體還沒加密,后一步請求體就加密成功了。
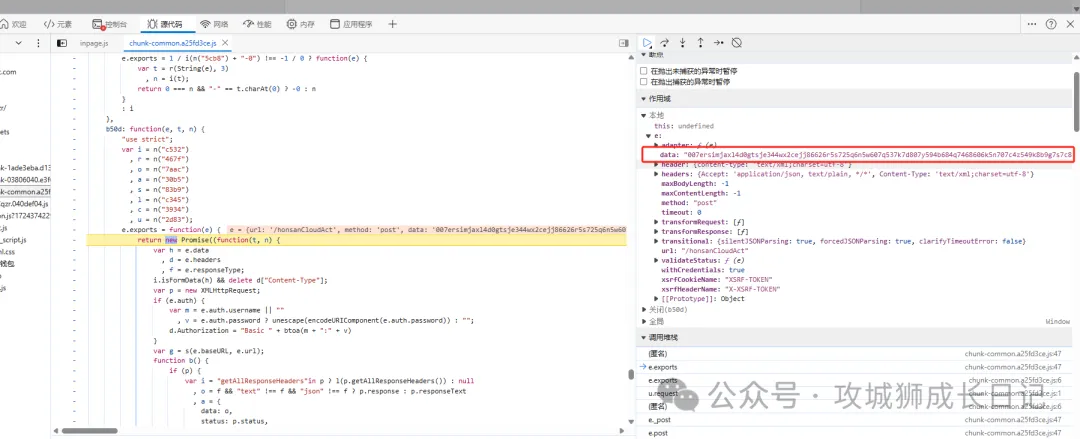
請求體加密后
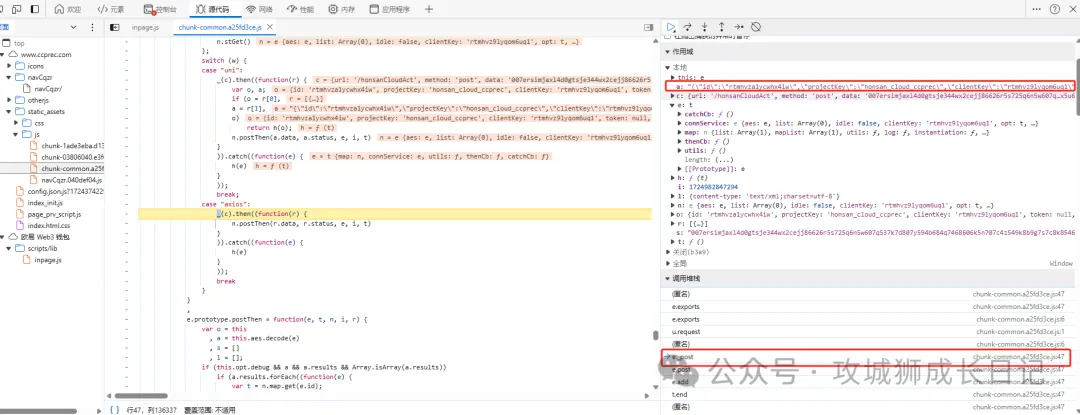
請求體加密前
其中上圖o就是請求體加密之前的參數,s就是加密后的參數。chunk-common.a25fd3ce.js就是進行加密的js。通過點擊堆棧的js名稱就可以定位到對應的地方。
扣取代碼
經過上一步分析,我們知道o就是加密之前的參數,就在js代碼找o定義的位置,如下圖所示:
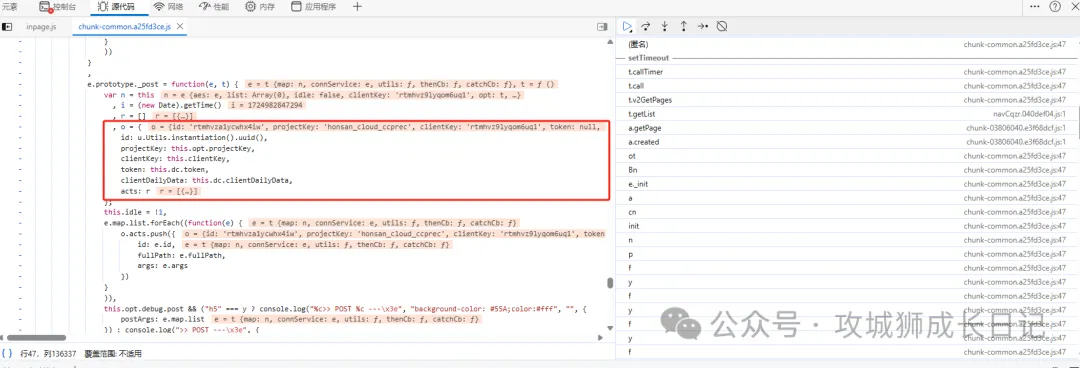
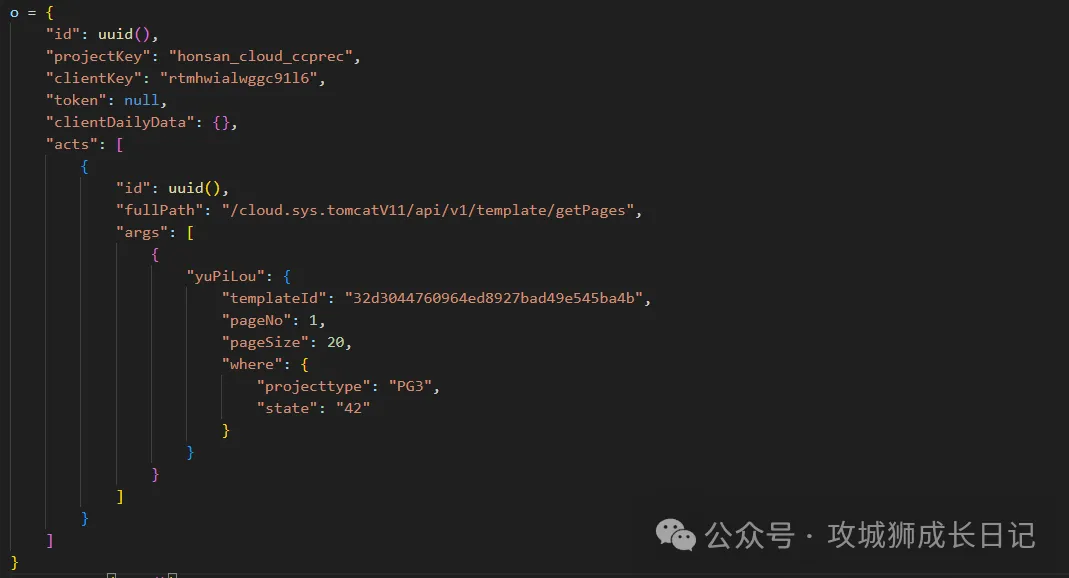
下面代碼就是請求體的參數,通過上述代碼發現id是通過uuid方法生成的。
{
"id": "rtmhwib79r4ytdgn",
"projectKey": "honsan_cloud_ccprec",
"clientKey": "rtmhwialwggc91l6",
"token": null,
"clientDailyData": {},
"acts": [
{
"id": "rtmhwib65mon96h1",
"fullPath": "/cloud.sys.tomcatV11/api/v1/template/getPages",
"args": [
{
"yuPiLou": {
"templateId": "32d3044760964ed8927bad49e545ba4b",
"pageNo": 1,
"pageSize": 20,
"where": {
"projecttype": "PG3",
"state": "42"
}
}
}
]
}
]
}接著我們需求扣取這個uuid方法。通過鼠標懸停在這個方法上面,就會彈出面板,如下圖所示:
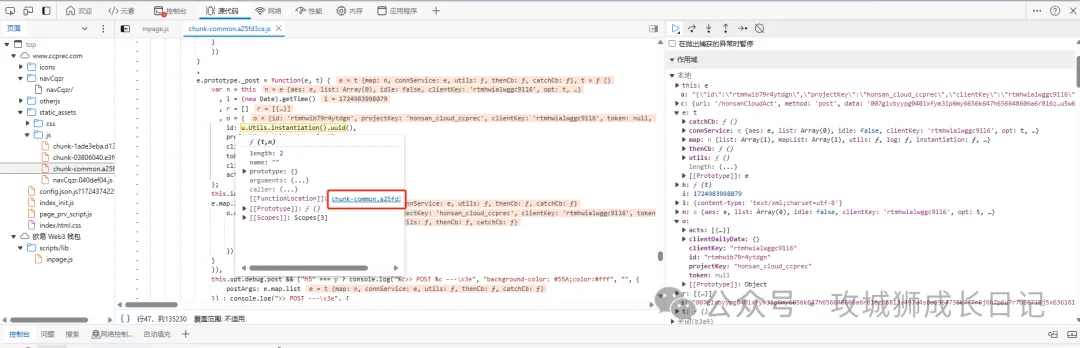
點擊后就會調到uuid方法定義的地方,如下圖所示:
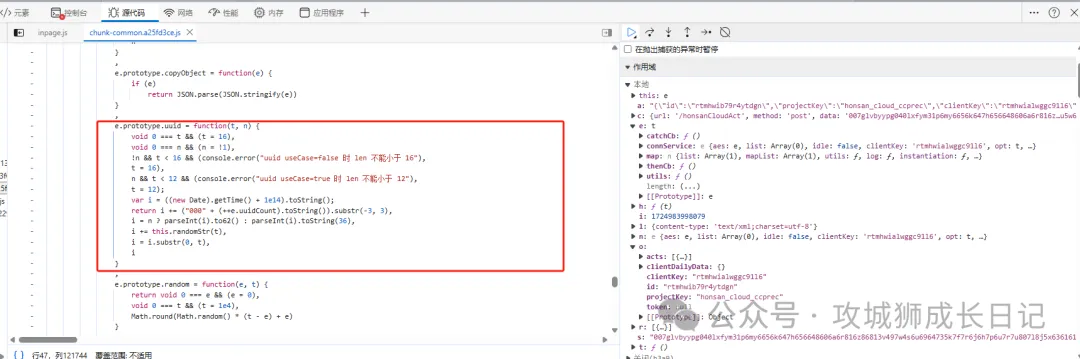
把這段代碼扣取下面,如下所示:
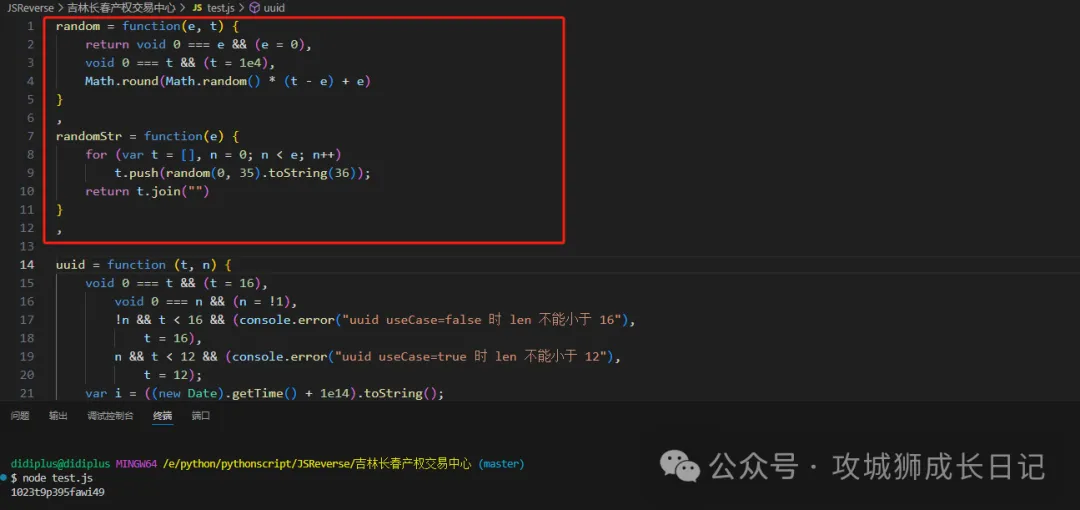
uuid = function (t, n) {
void 0 === t && (t = 16),
void 0 === n && (n = !1),
!n && t < 16 && (console.error("uuid useCase=false 時 len 不能小于 16"),
t = 16),
n && t < 12 && (console.error("uuid useCase=true 時 len 不能小于 12"),
t = 12);
var i = ((new Date).getTime() + 1e14).toString();
return i += ("000" + (++e.uuidCount).toString()).substr(-3, 3),
i = n ? parseInt(i).to62() : parseInt(i).toString(36),
i += randomStr(t),
i = i.substr(0, t),
i
}把this關鍵的全部刪除它。
然后通過node進行運行,如下圖所示報錯了e沒有定義。
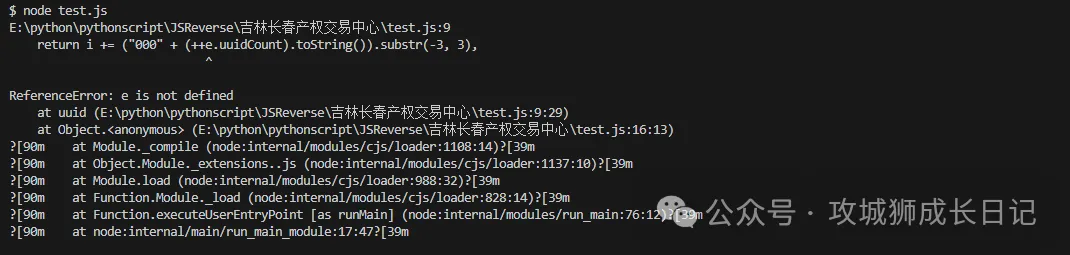
于是,我們再去源碼中找改值是什么?通過選中該值,經過幾次的確認。該值是NaN,如下圖所示:
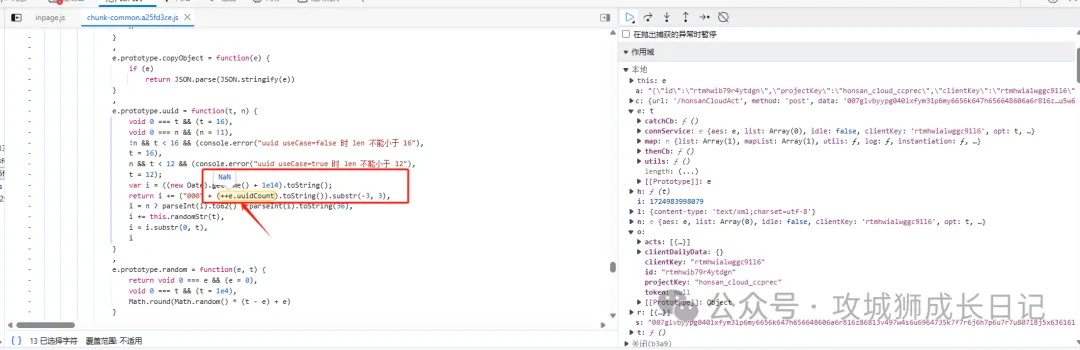
我們再自己扣取的代碼寫死它,再次運行。如下圖所示:
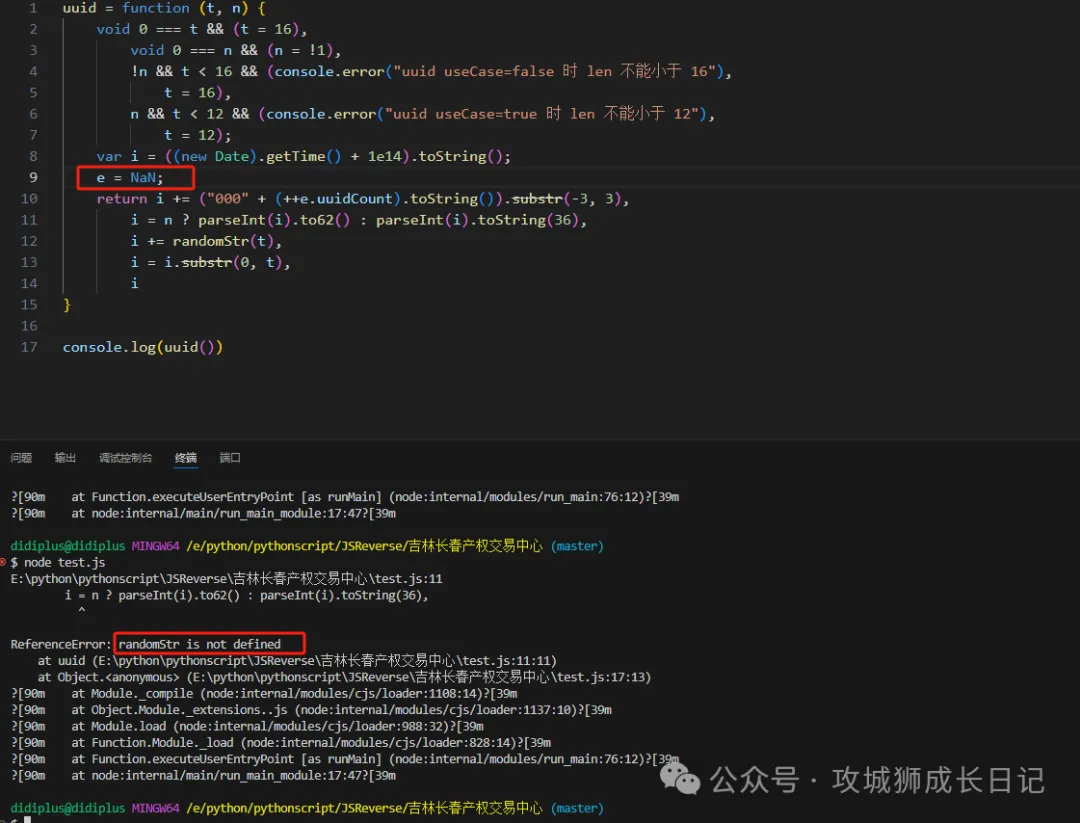
發現這是報randomStr沒有定義,我們再去源碼找這個方法進行補環境。通過搜索發現了randomStr方法,該方法有調用了random。于是我們兩個方法一起扣取下來。
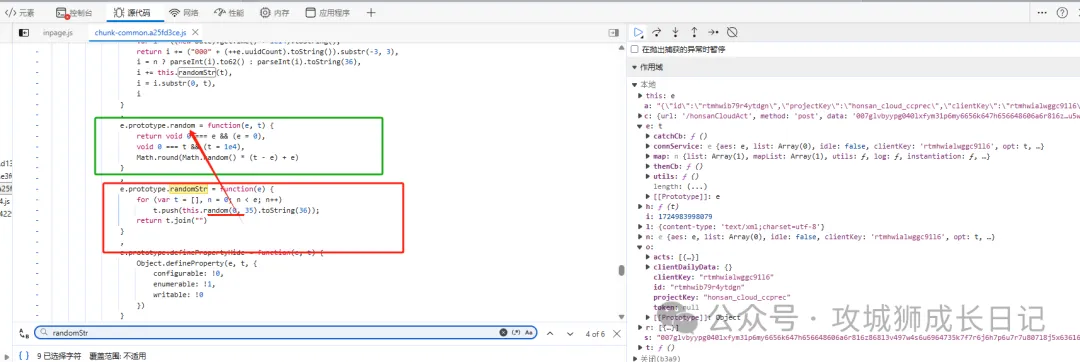
再次運行,沒有報錯了,成功打印了uuid,如下圖所示:
把之前扣取下來的請求體,id字段固定值替換成uuid函數生成的動態值,如下圖所示:
最重要的一步就是扣取加密的JS代碼啦, 在請求體參數附近查看this.aes.encode(a)加密方法,如下圖所示:
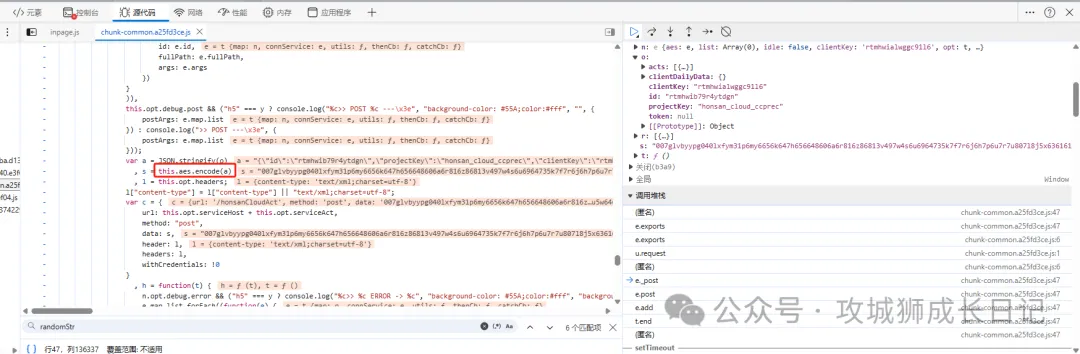
通過上面介紹的方面快速定位到這個加密的方法,如下圖所示:
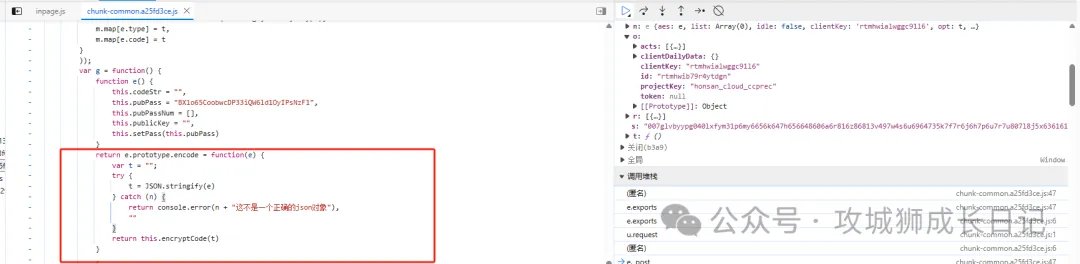
該方法又調用了另外一個方法this.encryptCode,通過關鍵搜索也找到了encryptCode方法,如下圖所示:
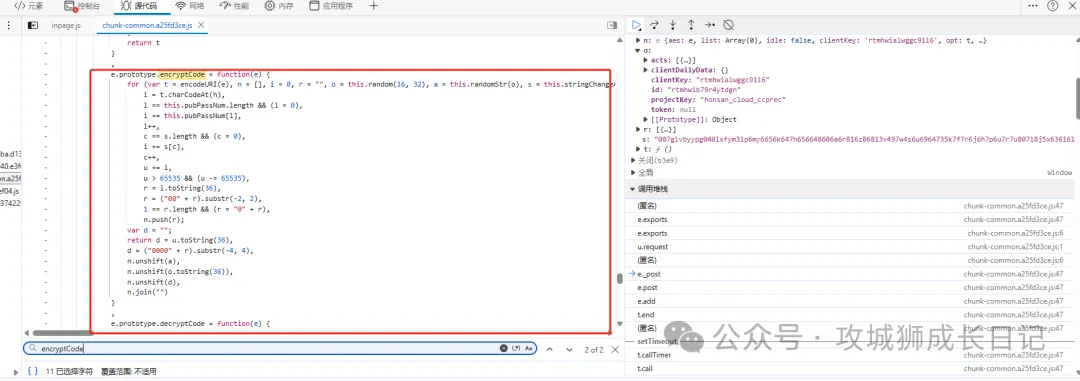
加密方法
按照編程習慣,附近也會有對應的解密方法的,如下圖所示:
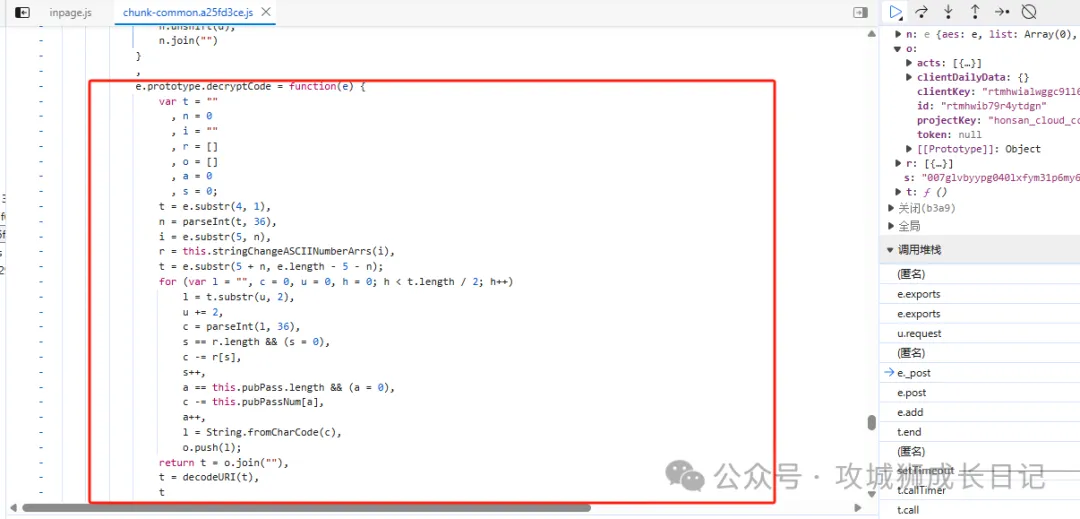
解密方法
現在加密和解密的方法都找到了,我們把它全部扣取下面進行調試,發現缺什么方法再進行補。重新定義一個方法生成加密請求頭,后續讓python調用這個方法并傳入分頁參數。如下圖所示:
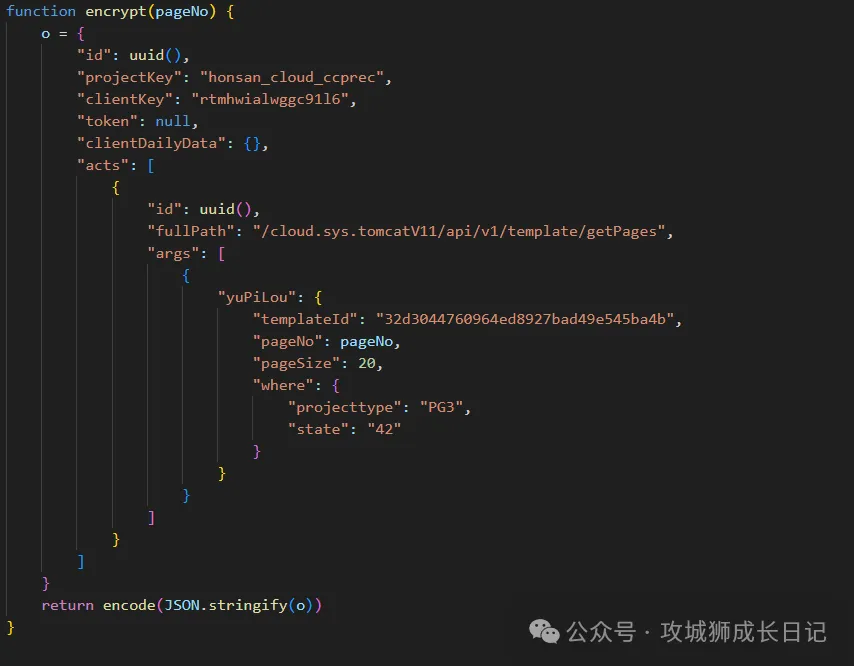
測試該方法是否能正常生成加密請求頭,執行如下命令:
console.log(encrypt())執行上述方法后,輸入如下圖所示:

通過python模擬請求
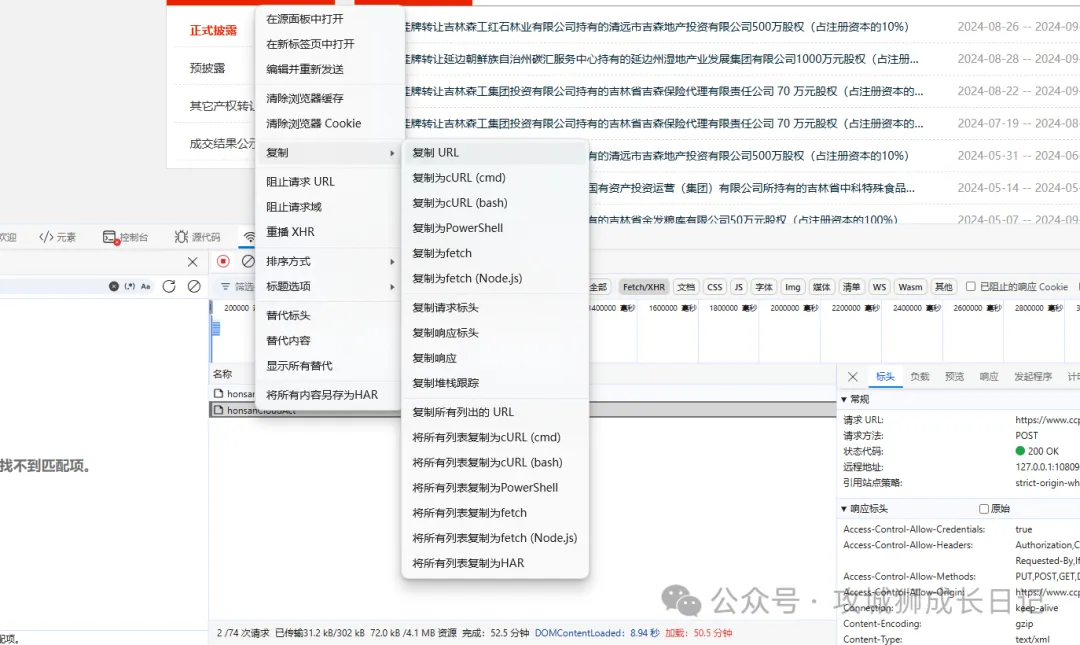
這里介紹一個非常快捷的方式用python模擬一個瀏覽器請求,首先我們先在開發者模式選擇這條請求,然后右擊選擇**將所有列表復制為cURL(Bash)**,如下圖所示:
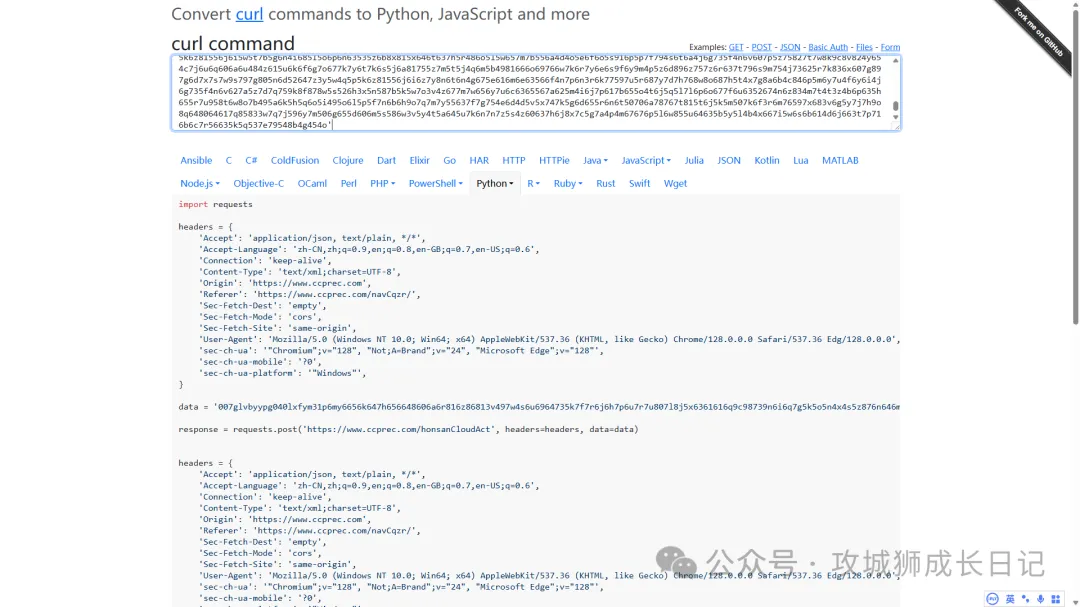
然后,來的這個工具網站[1],粘貼剛才復制的cURL信息,就可以根據自己喜歡的編程語言生成模擬瀏覽器請求的代碼,如下圖所示:
然后,把生成的代碼拷貝下來,進行修改。通過python的第三方庫execjs調用js代碼并執行對應的方法。
jscode=open("./test.js",'r',encoding='utf-8').read()以讀的模式打開test.js并賦值給jscode
data = execjs.compile(jscode).call("encrypt",page)通過execjs調用jscode對象,并通過call方法調用encrypt加密方法,并傳入分頁參數page。
下圖是python中的完整代碼:
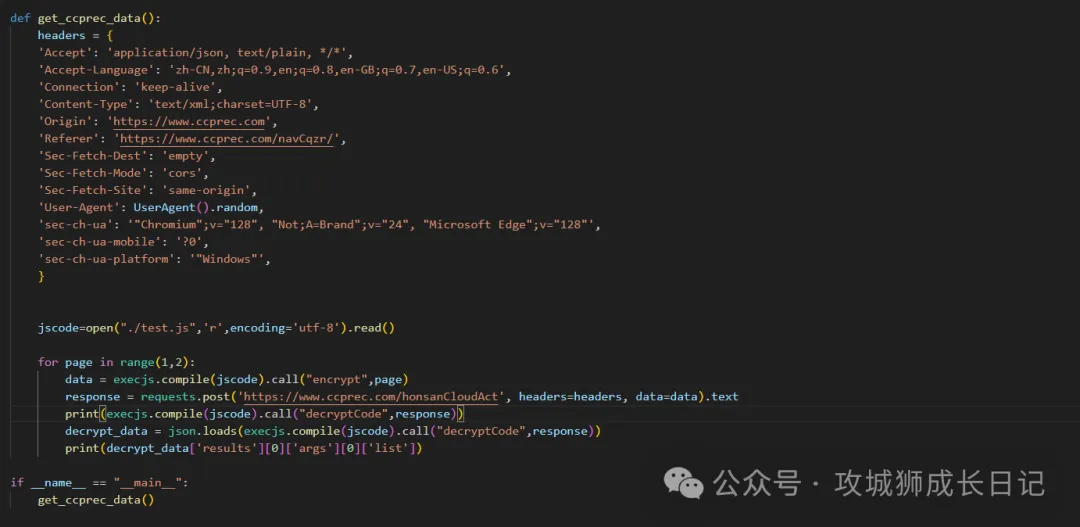
執行上述代碼后,成功獲取網站的數據如下圖所示:

遇到的問題
在python中使用execjs庫,出現UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xac in position 244: illegal multibyte sequence,一般遇見編碼問題先看看代碼里寫沒寫encoding='utf-8',沒寫的話寫加上試試。加了也不行。通過在python代碼中加入如下代碼:
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")腳本獲取方式
上述腳本已經上傳上傳到gitee,有需要的小伙伴可以自行獲取。gitee上的倉庫主要是分享一些工作中常用的腳本。小伙伴可以frok或者watch倉庫,這樣有更新可以及時關注到。
倉庫地址:https://gitee.com/didiplus/script
工具網站: https://curlconverter.com/