Nginx日志分析:編寫Shell腳本進行全面日志統計
Nginx是一個高性能的HTTP和反向代理服務器,也是一個IMAP/POP3/SMTP代理服務器。無論是在大流量的網站還是小型的個人博客中,Nginx都得到了廣泛應用。在實際生產環境中,對Nginx日志的分析有助于我們了解網站的訪問情況,發現潛在問題并進行優化。本文將通過編寫Shell腳本,實現對Nginx日志的全面統計分析。

Nginx日志格式
首先,我們需要確保Nginx日志格式與以下格式類似:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';假設我們的日志文件名為access.log。
Shell腳本實現
接下來,我們編寫一個Shell腳本,對Nginx日志進行統計分析。這個腳本包括以下功能:
- 統計各種狀態碼的數量
- 統計訪問最多的Referer
- 統計訪問最高的URI
- 統計訪問最多的IP和User-Agent
- 統計每分鐘的請求數、流量、請求時間、狀態碼等
腳本代碼實現:
1.統計各種狀態碼的數量:
awk '
{
Arry[$12] += 1;
total++;
}
END {
for (s in Arry) {
printf "%d\t%.4f\t%s\n", Arry[s], Arry[s] / total, s
}
}
'$LOG_FILE | sort -nr -k 1,1① Arry[$12] += 1;:
- $12 是日志文件的第十二個字段,通常表示 HTTP 狀態碼。
- Arry 是一個關聯數組,以 HTTP 狀態碼為鍵,將每個狀態碼出現的次數累加到數組 Arry 中。
- Arry[$12] += 1; 表示狀態碼 $12 出現的次數加 1。
② total++;:
- 記錄總的日志行數。
③ for (s in Arry):
- 遍歷數組 Arry 中的每個狀態碼 s。
④ printf "%d\t%.4f\t%s\n", Arry[s], Arry[s] / total, s:
- 打印每個狀態碼的出現次數、占比和狀態碼本身。
- Arry[s] 是狀態碼 s 出現的次數。
- Arry[s] / total 是該狀態碼出現的比例(占總請求數的百分比)。
- s 是狀態碼。
- 輸出格式為:出現次數\t 比例\t 狀態碼。
運行上述的命令,輸出如下結果:

統計各種狀態碼的數量
2.統計訪問最多的Referer
awk -F\" '
{
Arry[$4] += 1; # 將每個引用的字段($4)出現的次數累加到數組Arry中
total++; # 記錄總的日志行數
}
END {
for (s in Arry) { # 遍歷數組Arry中的每個引用字段
printf "%d\t%.4f\t%s\n", Arry[s], Arry[s] / total, s # 打印每個引用字段的出現次數、占比和引用字段本身
}
}
' $LOG_FILE | sort -nr -k 1,1 # 按出現次數降序排序執行上述命令后,輸出如下圖的結果:

統計訪問最多的Referer
3.統計訪問最高的URI
awk '
{
Arry[$9] += 1; # 將每個引用的字段($18)出現的次數累加到數組Arry中
total++; # 記錄總的日志行數
}
END {
for (s in Arry) { # 遍歷數組Arry中的每個引用字段
printf "%d\t%.4f\t%s\n", Arry[s], Arry[s] / total, s # 打印每個引用字段的出現次數、占比和引用字段本身
}
}
'$LOG_FILE | sort -nr -k 1 # 按出現次數降序排序執行上述命令后,輸出如下圖的結果:

統計訪問最高的URI
4.統計訪問最多的IP和User-Agent
(1) 統計最多IP訪問次數
awk '
{
Arry[$1] += 1; # 將每個IP地址出現的次數累加到數組Arry中
total++; # 記錄總的日志行數
}
END {
for (s in Arry) { # 遍歷數組Arry中的每個IP地址
printf "%d\t%.4f\t%s\n", Arry[s], Arry[s] / total, s # 打印每個IP地址的出現次數、占比和IP地址本身
}
}
'$LOG_FILE | sort -nr -k 1,1執行上述命令后,輸出如下圖的結果:

統計最多IP訪問次數
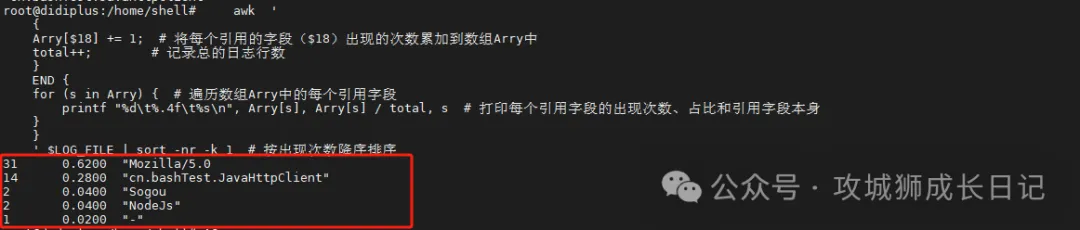
(2) 統計最多訪問的User-Agent
awk '
{
Arry[$18] += 1; # 將每個引用的字段($18)出現的次數累加到數組Arry中
total++; # 記錄總的日志行數
}
END {
for (s in Arry) { # 遍歷數組Arry中的每個引用字段
printf "%d\t%.4f\t%s\n", Arry[s], Arry[s] / total, s # 打印每個引用字段的出現次數、占比和引用字段本身
}
}
'$LOG_FILE | sort -nr -k 1 # 按出現次數降序排序執行上述命令后,輸出如下圖的結果:
統計訪問統計訪問
5.統計每分鐘的請求數、流量、請求時間、狀態碼等
awk -F '|''
BEGIN {
printf "時間\t數量\t流量[MB]\t請求時間\t20x\t30x\t40x\t50x\t60x\n"
}
{
# 提取時間的分鐘部分
minute = substr($2, 12, 5)
# 累計流量、請求數和請求時間
tms[minute] += $13
cnt[minute] += 1
reqt[minute] += $15
# 統計狀態碼
status_code = $9
if (status_code ~ /^2/) { sc20x[minute]++ }
else if (status_code ~ /^3/) { sc30x[minute]++ }
else if (status_code ~ /^4/) { sc40x[minute]++ }
else if (status_code ~ /^5/) { sc50x[minute]++ }
else { sc60x[minute]++ }
}
END {
for (t in tms) {
printf "%s\t%d\t%.4f\t%.4f\t%d\t%d\t%d\t%d\t%d\n",
t,
cnt[t],
tms[t] / 1024 / 1024,
(cnt[t] > 0 ? reqt[t] / cnt[t] : 0),
sc20x[t],
sc30x[t],
sc40x[t],
sc50x[t],
sc60x[t]
}
}
'"$LOG_FILE"執行上述命令后,輸出如下結果:

總結
通過上述Shell腳本,我們可以快速、全面地分析Nginx日志,了解網站的訪問情況和性能表現。這不僅有助于我們發現潛在問題,還能為后續的優化工作提供有力的數據支持。在實際應用中,你可以根據自己的需求,進一步擴展和定制這個腳本。
腳本獲取方式
上述腳本已經上傳上傳到gitee,有需要的小伙伴可以自行獲取。gitee上的倉庫主要是分享一些工作中常用的腳本。小伙伴可以frok或者watch倉庫,這樣有更新可以及時關注到。

腳本倉庫
倉庫地址:https://gitee.com/didiplus/script