算法、系統(tǒng)和應用,三個視角全面讀懂混合專家(MoE)
最近,各家科技公司提出的新一代大模型不約而同地正在使用混合專家(Mixture of Experts:MoE)方法。
混合專家這一概念最早誕生于 1991 年的論文《Adaptive mixtures of local experts》,三十多年來已經(jīng)得到了廣泛的探索和發(fā)展。近年來,隨著稀疏門控 MoE 的出現(xiàn)和發(fā)展,尤其是與基于 Transformer 的大型語言模型相結合,這種已有三十多年歷史的技術煥發(fā)出了新的生機。
MoE 框架基于一個簡單卻又強大思想:模型的不同部分(稱為專家)專注于不同的任務或數(shù)據(jù)的不同方面。
使用這一范式時,對于一個輸入,僅有與之相關的專家(Expert)才會參與處理,這樣一來便能控制計算成本,同時仍能受益于大量專業(yè)知識。因此,MoE 可在不大幅提升計算需求的前提下提升大語言模型的能力。
如圖 1 所示,MoE 相關研究增長強勁,尤其是在 2024 年 Mixtral-8x7B 以及 Grok-1、DBRX、Arctic、DeepSeek-V2 等各種產(chǎn)業(yè)級 LLM 出現(xiàn)之后。

這張圖來自香港科技大學(廣州)的一個研究團隊近日發(fā)布的一篇 MoE 綜述報告,其中清晰且全面地總結了 MoE 相關研究,并提出了一種全新的分類法,將這些研究歸類到了算法、系統(tǒng)和應用三大類。

- 論文標題:A Survey on Mixture of Experts
- 論文地址:https://arxiv.org/pdf/2407.06204
機器之心整理了這篇綜述報告的內(nèi)容主干,以幫助讀者了解當前 MoE 的發(fā)展概況,更多詳情請閱讀原論文。此外,我們也在文末整理了一些與 MoE 相關的報道。
混合專家的背景知識
在基于 Transformer 的大型語言模型(LLM)中,每個混合專家(MoE)層的組成形式通常是 ?? 個「專家網(wǎng)絡」{??_1, ... , ??_??} 搭配一個「門控網(wǎng)絡」G。
這個門控網(wǎng)絡的形式通常是一個使用 softmax 激活函數(shù)的線性網(wǎng)絡,其作用是將輸入引導至合適的專家網(wǎng)絡。MoE 層的放置位置是在 Transformer 模塊內(nèi),作用是選取前向網(wǎng)絡(FFN),通常位于自注意力(SA)子層之后。這種放置方式很關鍵,因為隨著模型增大,F(xiàn)FN 的計算需求也會增加。舉個例子,在參數(shù)量達到 5400 億的 PaLM 模型中,90% 的參數(shù)都位于其 FFN 層中。
用數(shù)學形式描述的話:每個專家網(wǎng)絡 ??_?? (通常是一個線性 - ReLU - 線性網(wǎng)絡)都由 W_?? 進行參數(shù)化,其接收同一輸入 x 并生成輸出 ??_?? (x; W_??)。同時,參數(shù)為 Θ 的門控網(wǎng)絡 G(通常由一個線性 - ReLU - 線性 - softmax 網(wǎng)絡構成)得到輸出 G (x; Θ)。再根據(jù)門控函數(shù)的設計方式,可以將 MoE 層大致分為以下兩類。

密集 MoE
密集混合專家層是在每次迭代過程中激活所有專家網(wǎng)絡 {??_1, ... , ??_??}。早期的 MoE 研究普遍采用了這一策略。近段時間也有一些研究采用了密集 MoE,比如 EvoMoE、MoLE 、LoRAMoE 和 DS-MoE。圖 2a 給出了密集 MoE 層的結構。因此,密集 MoE 層的輸出可以表示成:
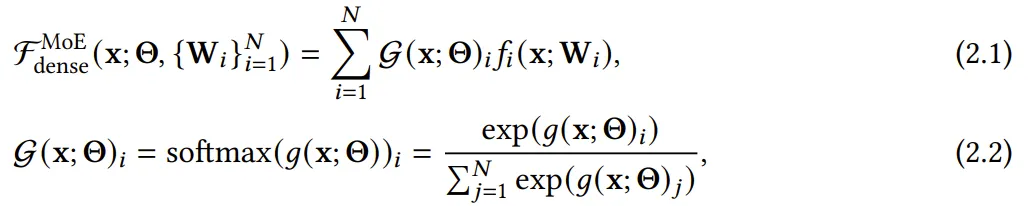
其中,??(x; Θ) 是 softmax 運算之前的門控值。
稀疏 MoE
盡管密集混合專家的預測準確度通常更高,但其計算負載也非常高。
為了解決這個問題,Shazeer et al. 的論文《Outrageously large neural networks: The sparsely-gated mixture-of-experts layer》引入了稀疏門控 MoE 層,其能在每次前向通過時僅激活選定的專家子集。該策略實現(xiàn)稀疏性的方式是計算 top-k 個專家的輸出的加權和,而非將所有專家的輸出聚合到一起。圖 2b 展示了這種稀疏 MoE 層的結構。
根據(jù)上述論文提出的框架,可對 2.2 式進行修改以反映稀疏門控機制:

這里解釋一下:TopK (?, ??) 函數(shù)是僅保留向量原始值的前 k 項,同時將其它項設置為 ?∞。之后是 softmax 運算,所有 ?∞ 項都會變成近似于零。超參數(shù) k 要根據(jù)具體應用選取,常見選項是 ?? = 1 或 ?? = 2。加入噪聲項 R_noise 是訓練稀疏門控 MoE 層的一種常用策略,可促進專家之間的探索并提升 MoE 訓練的穩(wěn)定性。
盡管稀疏門控 G (x; Θ) 可在不增加相應計算成本的前提下顯著擴展模型的參數(shù)空間,但也會導致負載平衡問題。負載平衡問題是指各專家的負載分布不均 —— 某些專家被頻繁使用,而另一些專家則很少被使用甚至完全不上場。
為了解決這個問題,每個 MoE 層都要集成一個輔助損失函數(shù),其作用是敦促每批次的 token 被均勻分配給各個專家。從數(shù)學形式描述來看,首先定義一個包含 T 個 token 的查詢批次 B = {x_1 , x_2, ... , x_?? } 以及 N 個專家。則對于其的輔助負載平衡損失定義為:

其中 D_i 是分配給專家 i 的 token 比例,P_i 是分配給專家 i 的門控概率比例。為了確保該批次在 N 個專家之間均勻分布,應當最小化負載平衡損失函數(shù) L_{load-balancing}。當每個專家都被分配了同等數(shù)量的 token D_?? = 1/?? 和同等的門控概率 P_?? = 1/?? 時,即達到最優(yōu)條件:

此時各專家的負載達到平衡。
在后文中,除非另有明確說明,則「MoE」這一術語單指「稀疏 MoE」。
混合專家的分類
為了幫助研究者在大量采用 MoE 的 LLM 研究中找到目標,該團隊開發(fā)了一套分類方法,根據(jù)三個方面對這些模型進行了分類:算法設計、系統(tǒng)設計和應用。
圖 3 展示了這種分類法以及一些代表性研究成果。
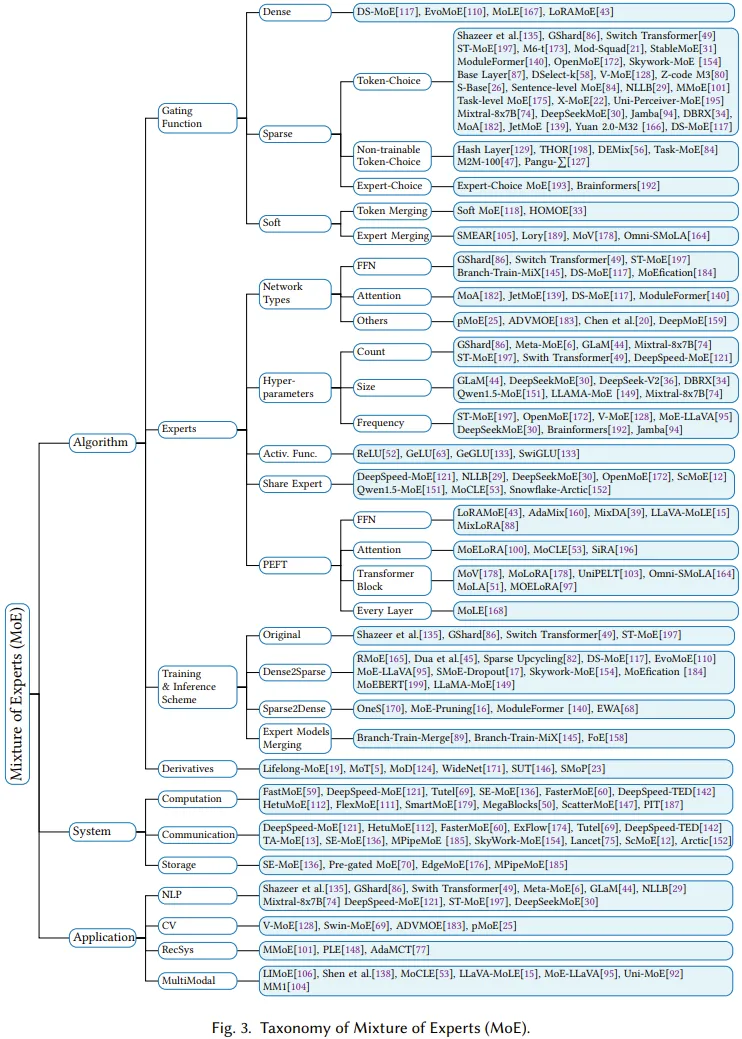
下面將全面深入地介紹各類別的情況。
混合專家的算法設計
門控函數(shù)
門控函數(shù)(也被稱為路由函數(shù)或路由器)是所有 MoE 架構的基礎組件,其作用是協(xié)調(diào)使用專家計算以及組合各專家的輸出。
根據(jù)對每個輸入的處理方法,該門控可分為三種類型:稀疏式、密集式和 soft 式。其中稀疏式門控機制是激活部分專家,而密集式是激活所有專家,soft 式則包括完全可微方法,包括輸入 token 融合和專家融合。圖 4 展示了 MoE 模型中使用的各種門控函數(shù)。
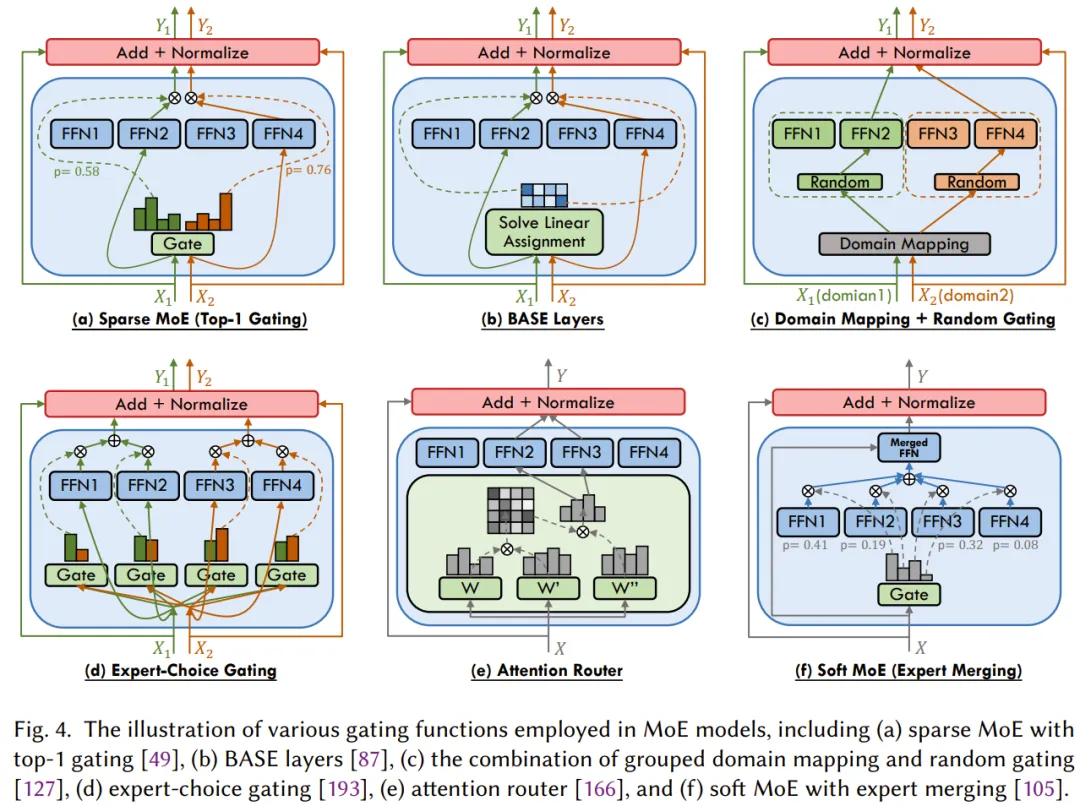
- 稀疏式
稀疏門控函數(shù)在處理各個輸入 token 時會激活被選中的部分專家,這可被視為一種形式的條件計算。
門控函數(shù)可以實現(xiàn)多種形式的門控決策,比如二元決策、稀疏或連續(xù)決策、隨機或確定性決策;其已經(jīng)得到了深入的研究,可使用各種形式的強化學習和反向傳播來訓練。
Shazeer et al. 的研究《Outrageously large neural networks: The sparsely-gated mixture-of-experts layer》開創(chuàng)性地提出了一種使用輔助負載平衡損失的可微分啟發(fā)式方法,其中可根據(jù)選取概率對專家計算的輸出進行加權。這為門控過程引入了可微性,由此可通過梯度來引導門控函數(shù)的優(yōu)化。
后來,這一范式便成了 MoE 研究領域的主導范式。由于這種方法會針對每個輸入 token 選擇專家,因此可將其看作是 token 選擇式門控函數(shù)。
以下為這一小節(jié)的要點,詳見原論文:
- token 選擇式門控
- 用于 token 選擇式門控的輔助損失
- token 選擇式門控的專家容量
- token 選擇式門控的其它進展
- 不可訓練的 token 選擇式門控
- 專家選擇式門控

- 密集式
密集 MoE 是指處理每個輸入時都激活所有專家。
雖然稀疏 MoE 有效率方面的優(yōu)勢,但密集 MoE 方向依然在不斷迎來創(chuàng)新。尤其值得一提的是,密集激活在 LoRA-MoE 微調(diào)方面表現(xiàn)很好,并且 LoRA 專家的計算開銷相對較低。這種方法能夠有效靈活地集成多個 LoRA 以完成各種下游任務。這能保留原始預訓練模型的生成能力,同時保留各個 LoRA 針對各個任務的獨有特性。
- soft 式
對稀疏 MoE 來說,一大基本離散優(yōu)化難題是如何決定為每個 token 分配哪些合適的專家。為了確保專家能平衡地參與并盡可能減少無分配 token,這通常必須啟發(fā)式的輔助損失。在涉及分布外數(shù)據(jù)的場景(比如推理批次小、有全新輸入或遷移學習)中,這個問題尤其顯著。
類似于密集 MoE,soft MoE 方法在處理每個輸入時也會使用所有專家,從而維持完全可微性,進而避免離散專家選擇方法的固有問題。soft MoE 與密集 MoE 的不同在于前者會通過對輸入 token 或?qū)<疫M行門控加權的融合來緩解計算需求。
專家
這一節(jié)會介紹 MoE 框架內(nèi)專家網(wǎng)絡的架構,并會討論協(xié)調(diào)這些專家的激活的門控函數(shù)。
- 網(wǎng)絡類型
自從 MoE 被整合到 Transformer 架構中以來,其通常會替代這些模型中的前向網(wǎng)絡(FFN)模塊。通常來說,MoE 層中的每個專家都會復制其替換的 FFN 的架構。
這種將 FFN 用作專家的范式到現(xiàn)在依然是主流,但人們也對此做了不少改進。
- 超參數(shù)
稀疏 MoE 模型的規(guī)模由幾個關鍵超參數(shù)控制,包括:
- 每個 MoE 層的專家數(shù)量
- 每個專家的大小
- MoE 層在整個模型中的放置頻率
這些超參數(shù)的選擇至關重要,因為它會深刻影響模型在各種任務中的性能和計算效率。因此,要根據(jù)特定的應用要求和計算基礎設施來選擇最佳超參數(shù)。表 2 給出了一些使用 MoE 的模型的配置情況。

另外,表 3 列舉了一些近期的開源模型的參數(shù)數(shù)量和基準性能。

- 激活函數(shù)
基于密集 Transformer 架構構建的稀疏 MoE 模型采用了與 BERT、T5、GPT 和 LLAMA 等領先的密集 LLM 類似的激活函數(shù)。激活函數(shù)已經(jīng)從 ReLU 發(fā)展出了 GeLU、GeGLU、SwiGLU 等更先進的選擇。
這一趨勢也擴展到了 MoE 模型的其它組件,它們經(jīng)常整合均方根層歸一化(RMSNorm)、分組查詢注意力(GQA)和旋轉(zhuǎn)位置嵌入(RoPE)等技術。
- 共享專家
DeepSpeed-MoE 創(chuàng)新性地引入了殘差 MoE(Residual-MoE)架構,其中每個 token 都由一個固定專家外加一個門控選擇的專家進行處理,實現(xiàn)了每一層都有兩個專家參與處理,同時也不會讓通信成本超過 top-1 門控方法。這種方法是把門控選擇的 MoE 專家當作是固定密集 FFN 的糾錯輔助。
NLLB 中使用的條件式 MoE 路由(CMR/Conditional MoE Routing)也采用了類似的方法,將密集 FFN 和 MoE 層的輸出組合起來使用。
將固定 FFN 和稀疏 MoE 整合起來的范式通常被稱為共享專家,如圖 5b 所示。

近期有 DeepSeekMoE、OpenMoE、Qwen1.5-MoE 和 MoCLE 等模型采用這一范式,表明其正在成為一種主流配置。不過 DeepSeekMoE 和 Qwen1.5-MoE 采用了多個共享專家,而不是單個。
混合參數(shù)高效型專家
參數(shù)高效型微調(diào)(PEFT)是一種提升微調(diào)效率的方法。簡單來說,PEFT 就是在微調(diào)時僅更新基礎模型的一小部分參數(shù)。
PEFT 很成功,但由于其可訓練的參數(shù)有限以及可能存在的災難性遺忘問題,該方法難以用于需要泛化到多個任務的情況。
為了緩解這些局限,混合參數(shù)高效型專家(MoPE)誕生了,其將 MoE 框架與 PEFT 整合到了一起。MoPE 集成了 MoE 的門控機制與多專家架構,同時每個專家都使用了 PEFT 技術進行構建。這種巧妙的組合能極大提升 PEFT 在多任務場景中的性能。此外,由于使用了 PEFT 來構建專家,因此 MoPE 使用的參數(shù)也更少,資源效率比傳統(tǒng) MoE 模型高得多。
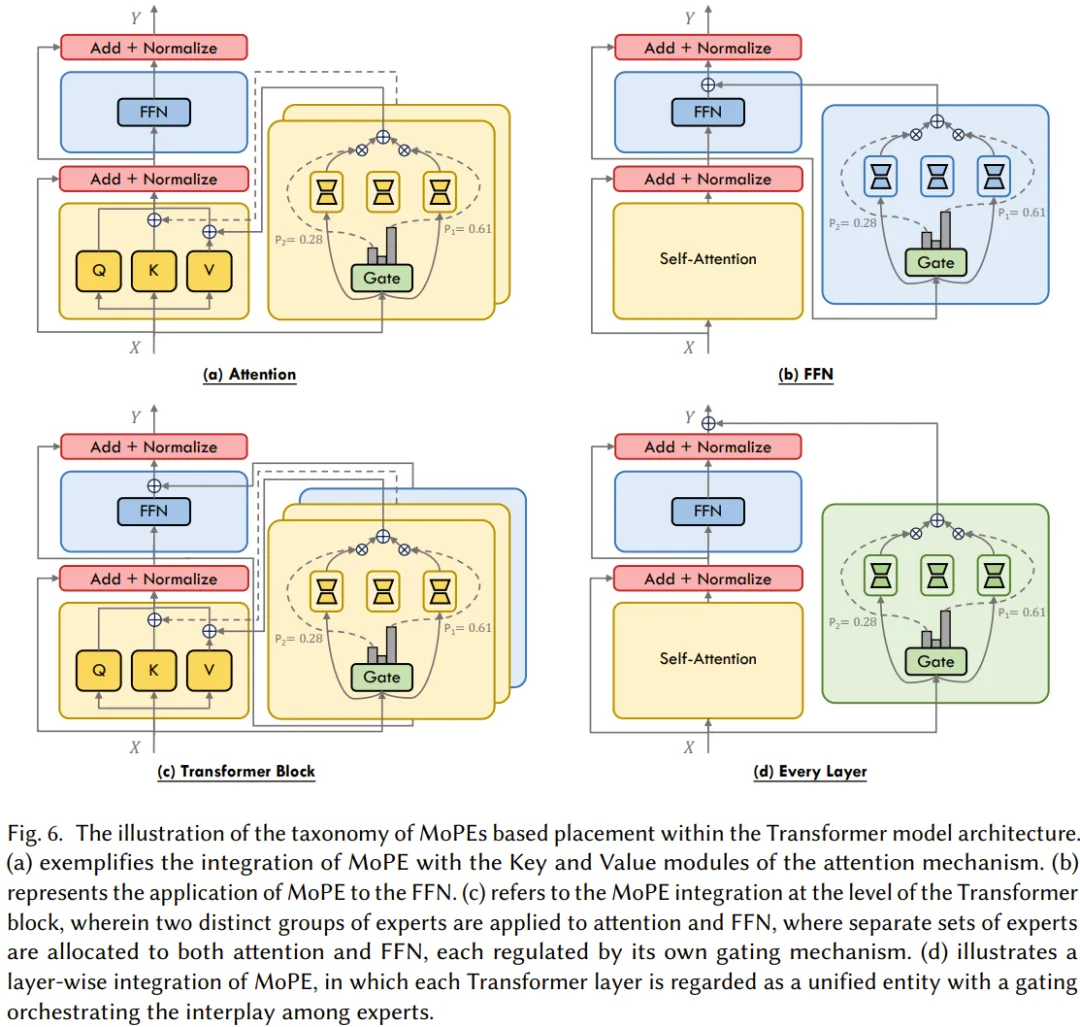
MoPE 融合了 MoE 的多任務特性與 PEFT 的資源效率,是一個極具前景的研究方向。圖 6 根據(jù)在 Transformer 模型架構中的位置對 MoPE 進行了分類。至于 MoPE 方面更詳細的研究成果介紹,請參看原論文。
訓練和推理方案
混合專家在進步發(fā)展,相關的訓練和推理方案也在進步發(fā)展。
初始的訓練和推理方案需要從頭開始訓練 MoE 模型,直接采用訓練的模型配置來執(zhí)行推理。
但現(xiàn)在,MoE 模型的訓練和推理方面已經(jīng)出現(xiàn)了許多新范式,包括組合密集模型和稀疏模型的優(yōu)勢實現(xiàn)取長補短。
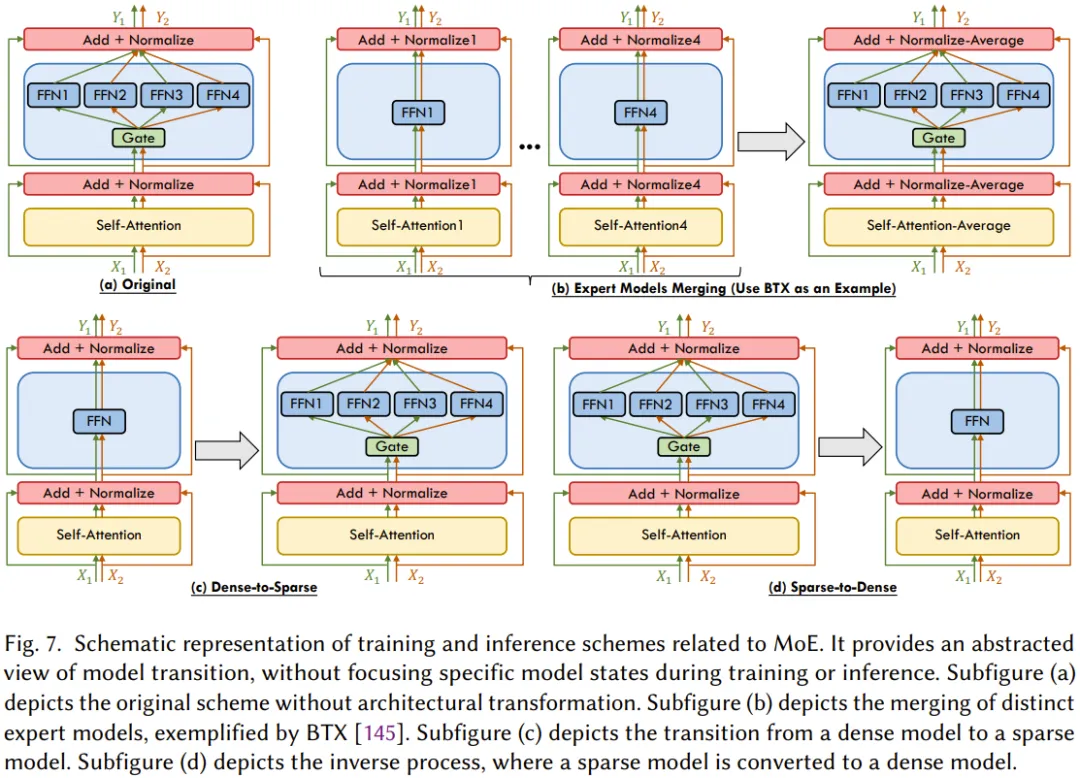
圖 7 展示了與 MoE 相關的訓練和推理方案,可以看到新出現(xiàn)的方案可分為三類:
- 密集到稀疏:從密集模型訓練開始,逐步過渡到稀疏 MoE 配置;
- 稀疏到密集:涉及到將稀疏 MoE 模型降格為密集形式,這有利于將推理實現(xiàn)為硬件形式;
- 專家模型融合:將多個預訓練密集專家模型整合成一個統(tǒng)一的 MoE 模型。
MoE 的衍生技術
混合專家(MoE)啟發(fā)了許多不同的變體技術。舉個例子,Xue et al. 的論文《Go wider instead of deeper》提出了模型寬度增大的 WideNet,其做法是將前向網(wǎng)絡(FFN)替換成 MoE 層,同時維持 Transformer 層上的共享可訓練參數(shù),但歸一化層除外。
另外還有 Tan et al. 提出的 SYT(稀疏通用 Transformer)、Antoniak et al. 提出的 MoT(混合 token)、Choi et al. 提出的 SMoP(稀疏混合提詞)、Chen et al. 提出的 Lifelong-MoE、Raposo et al. 提出的 MoD(混合深度)等。
總結一下,MoE 衍生技術的發(fā)展揭示了一個趨勢:MoE 的功能越來越多,越來越能適應不同的領域。
混合專家的系統(tǒng)設計
混合專家(MoE)雖然能增強大型語言模型的能力,但也帶來了新的技術挑戰(zhàn),因為其具有稀疏且動態(tài)的計算負載。
GShard 引入了專家并行化(expert parallelism),可根據(jù)專家能力的負載平衡限制來調(diào)度切分后的局部 token,從而實現(xiàn)并行的門控和專家計算。該范式已經(jīng)成為促進 MoE 模型高效擴展的基礎策略。我們可以將該方法看作是增強版的數(shù)據(jù)并行化 ——MoE 層中的每個專家都被分配到一臺不同設備,同時所有設備上都重復配備所有非專家層。
如圖 8a 所示,專家并行化的工作流程是按順序執(zhí)行以下操作:門路由、輸入編碼、All-to-All 調(diào)度、專家計算、All-to-All 組合、輸出解碼。

一般來說,GEMM 的輸入大小需要足夠大,以便充分利用計算設備。因此,要使用輸入編碼將同一個專家的輸入 token 聚合到連續(xù)的內(nèi)存空間中,這由門路由中的「token - 專家映射」決定。之后,All-to-All 調(diào)度的作用是將輸入 token 分發(fā)給各設備上對應的專家。之后是專家的本地化計算。計算完成后再通過 All-to-All 組合匯總,然后解碼輸出,根據(jù)門控索引恢復原始數(shù)據(jù)的布局。
此外,也有研究者探索專家并行化與其它已有并行策略(比如張量、管道化、序列并行化)的協(xié)同,以提升 MoE 模型在大規(guī)模分布式環(huán)境中的可擴展性和效率。
圖 8 中給出了一些混合并行化示例,包括 (b) 數(shù)據(jù) + 專家 + 張量并行化、(c) 數(shù)據(jù) + 專家 + 管道并行化、(d) 專家 + 張量并行。
需要認識到,計算效率、通信負載、內(nèi)存占用之間存在復雜的相互作用,分布式并行化策略的選擇會對其產(chǎn)生影響,并且也會被不同的硬件配置影響。因此,在部署用于實際應用的策略時,必須細致地權衡考慮并針對具體場景進行調(diào)整。
之后,該團隊分計算、通信和存儲三大板塊介紹了 MoE 模型開發(fā)所面臨的系統(tǒng)設計難題以及解決這些難題的研究成果,詳見原論文。表 4 給出了開源 MoE 框架的概況。

混合專家的應用
在當前 Transformer 主導的大型語言模型(LLM)領域,混合專家(MoE)范式頗具吸引力,因為其能在不給訓練和推理階段引入過大計算需求的前提下大幅提升模型能力。這類技術能顯著 LLM 在多種下游任務上的性能,甚至造就了一些超越人類水平的 AI 應用。
有傳言說強大如斯的 GPT-4 可能也采用了某種 MoE 架構 —— 由 8 個 2200 億參數(shù)的專家構成,在多樣化的數(shù)據(jù)集和任務上完成了訓練,并使用了一種 16 次迭代的推理過程。有關該傳言的更多詳情可參閱機器之心報道《終極「揭秘」:GPT-4 模型架構、訓練成本、數(shù)據(jù)集信息都被扒出來了》。
所以,毫不奇怪 MoE 在自然語言處理、計算機視覺、推薦系統(tǒng)和多模態(tài)應用中遍地開花了。
這些應用本質(zhì)上就需要使用條件計算來大幅提升模型的參數(shù)量,以此增強模型在固定計算成本下的性能,或通過門控機制實現(xiàn)動態(tài)專家選擇來實現(xiàn)高效多任務學習。
該團隊也介紹了這些不同領域的代表性 MoE 應用,可幫助讀者理解如何將 MoE 用于具體任務。詳見原論文。
挑戰(zhàn)與機遇
混合專家,功能強大,降低成本,提升性能。前景雖好,仍有挑戰(zhàn)。
這一節(jié)中,該團隊梳理了 MoE 相關的關鍵性挑戰(zhàn),并指出了有希望獲得重要成果的未來研究方向。下面簡要列出了這些挑戰(zhàn)和研究方向,更多詳情請查看原論文。
- 訓練穩(wěn)定性和負載平衡
- 可擴展性和通信開銷
- 專家的專業(yè)化和協(xié)作
- 稀疏激活和計算效率
- 泛化和穩(wěn)健性
- 可解釋性和透明性
- 最優(yōu)的專家架構
- 與現(xiàn)有框架整合