原作者帶隊,LSTM卷土重來之Vision-LSTM出世
AI 領域的研究者應該還記得,在 Transformer 誕生后的三年,谷歌將這一自然語言處理屆的重要研究擴展到了視覺領域,也就是 Vision Transformer。后來,ViT 被廣泛用作計算機視覺中的通用骨干。
這種跨界,對于前不久發(fā)布的 xLSTM 來說同樣可以實現(xiàn)。最近,享譽數(shù)十年的 LSTM 被擴展到一個可擴展且性能良好的架構 ——xLSTM,通過指數(shù)門控和可并行化的矩陣內(nèi)存結構克服了長期存在的 LSTM 限制。現(xiàn)在,這一成果已經(jīng)擴展到視覺領域。

xLSTM和 Vision-LSTM 兩項研究均由 LSTM 原作者帶隊,也就是 LSTM 的提出者和奠基者 Sepp Hochreiter。
在最近的這篇論文中,Sepp Hochreiter 等人推出了 Vision-LSTM(ViL)。ViL 包含一堆 xLSTM 塊,其中奇數(shù)塊從上到下、偶數(shù)塊則從下到上處理補丁 token 序列。

- 論文題目:Vision-LSTM: xLSTM as Generic Vision Backbone
- 論文鏈接:https://arxiv.org/abs/2406.04303
- 項目鏈接: https://nx-ai.github.io/vision-lstm/
正如 xLSTM 誕生之時,作者希望新架構能夠撼動 Transformer 在語言模型領域的江山。這一次,闖入視覺領域的 Vision-LSTM 也被寄予厚望。
研究者在論文中表示:「我們的新架構優(yōu)于基于 SSM 的視覺架構,也優(yōu)于 ImageNet-1K 分類中的優(yōu)化 ViT 模型。值得注意的是,在公平的比較中,ViL 的表現(xiàn)優(yōu)于經(jīng)過多年超參數(shù)調整和 Transformer 改進的 ViT 訓練 pipeline。」
對于需要高分辨率圖像以獲得最佳性能的任務,如語義分割或醫(yī)學成像, ViL 極具應用潛力。在這些情況下,Transformer 因自注意力的二次復雜性而導致計算成本較高,而 ViL 的線性復雜性不存在這種問題。研究者還表示,改進預訓練方案(如通過自監(jiān)督學習)、探索更好的超參數(shù)設置或從 Transformer 中遷移技術(如 LayerScale )都是 ViL 的可探索方向。
ViT 與 ViL
語言建模架構 —— 如 Transformer 或最近的狀態(tài)空間模型 Mamba,通常被應用到計算機視覺領域,以利用它們強大的建模能力。
然而,在自然語言處理中,通過離散詞匯表(Discrete vocabulary),輸入的句子通常被編碼成代表詞或常見子詞的 token。
為了將圖像編碼成一組 token,Vision Transformer(ViT)提出將輸入圖像分組成非重疊的補丁(例如 16x16 像素),將它們線性投影成所謂的補丁 token 序列,并向這些 token 添加位置信息。
然后,這個序列就可以被語言建模架構處理了。
擴展長短期記憶(xLSTM)最近被引入作為一種新的語言建模架構,可以說是 LSTM 在 LLM 時代的復興,與 Transformer 和狀態(tài)空間模型(SSMs)等相媲美。
現(xiàn)有的 Transformer 或狀態(tài)空間模型的視覺版本,例如 ViT 或 Vision Mamba,已經(jīng)在各種計算機視覺任務中取得了巨大成果。
使用 xLSTM 作為核心組建的 ViL 使用簡單的交替設計,從而可以有效地處理非序列輸入(如圖像),而無需引入額外的計算。
類似于 SSMs 的視覺適應,ViL 展示了關于序列長度的線性計算和內(nèi)存復雜度,這使得它在高分辨率圖像的任務中展現(xiàn)極佳的作用,如醫(yī)學成像、分割或物理模擬。
相比之下,ViT 的計算復雜度由于自注意力機制而呈二次方增長,使得它們在應用于高分辨率任務時成本高昂。
交替 mLSTM 塊并行
Vision-LSTM(ViL)是一個用于計算機視覺任務的通用骨干,它從 xLSTM 塊殘差構建,如圖 1 所示。
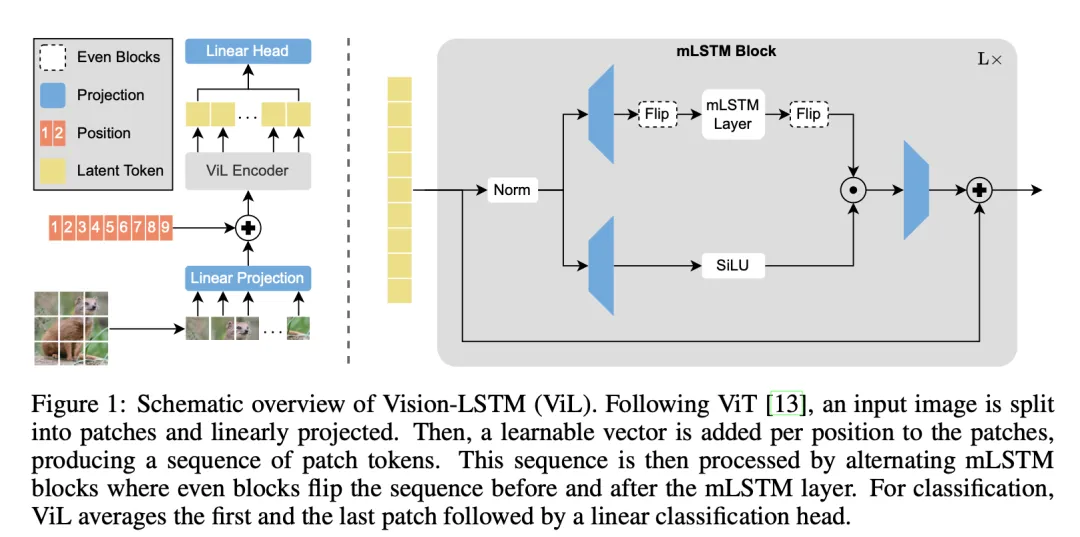
與 ViT 類似,ViL 首先通過共享線性投影將圖像分割成非重疊的補丁,然后向每個補丁 token 添加可學習的定位嵌入。ViL 的核心是交替的 mLSTM 塊,它們是可完全并行化的,并配備了矩陣內(nèi)存和協(xié)方差更新規(guī)則。
奇數(shù) mLSTM 塊從左上到右下處理補丁 token,而偶數(shù)塊則從右下到左上。
ImageNet-1K 實驗
研究團隊在 ImageNet-1K 上進行了實驗:它包含 130 萬張訓練圖像和 5 萬張驗證圖像,每張圖像屬于 1000 個類別之一。
對比實驗集中在使用序列建模骨干的模型上,而該模型在大致相當?shù)膮?shù)數(shù)量上是可比較的。
他們在 224x224 分辨率上訓練 ViL 模型,使用余弦衰減調度,1e-3 的學習率訓練了 800 個周期(tiny, tiny+)或 400 個周期(small, small+, base),具體見下方表 5.

為了對 Vision Mamba(Vim)進行公平比較,研究人員向模型內(nèi)添加了額外的塊以匹配 tiny 和小型變體(分別表示為 ViL-T + 和 ViL-S+)的參數(shù)數(shù)量。
需要注意的是,由于 ViL 以交替的方式遍歷序列,而 Vim 則在每個塊中遍歷序列兩次,因此 ViL 所需的計算量遠少于 Vim。
盡管 Vim 使用了優(yōu)化的 CUDA 內(nèi)核(而 mLSTM 目前還沒有這樣的內(nèi)核),但這仍然成立,并且會進一步加速 ViL 的速度。
如表 4 所示的運行時間對比,在其中兩項的比較重,ViL 比 Vim 快了 69%。

新秀 ViL 相比于 ViTs 如何?
雖然 ViL 首次出場,但仍是展現(xiàn)了極佳的潛力。
由于 ViTs 在視覺社區(qū)中已經(jīng)得到了廣泛的認可,它們在過去幾年經(jīng)歷了多次優(yōu)化周期。
因為這項工作是首次將 xLSTM 應用于計算機視覺,研究人員并不期望在所有情況下都超過 ViTs 多年的超參數(shù)調整。
即便如此,表 1 中的結果顯示,ViL 在小規(guī)模上相比于經(jīng)過大量優(yōu)化的 ViT 協(xié)議(DeiT, DeiT-II, DeiT-III)仍是顯示出較良好的結果,其中只有訓練時間是 ViL-S 兩倍的 DeiT-III-S 表現(xiàn)略好一點。
在「base」規(guī)模上,ViL 超越了最初的 ViT 模型,并取得了與 DeiT 相當?shù)慕Y果。
需要注意的是:由于在這個規(guī)模上訓練模型的成本很高,ViL-B 的超參數(shù)遠非最佳。作為參考,訓練 ViL-B 大約需要 600 個 A100 GPU 小時或在 32 個 A100 GPU 上的 19 個小時。
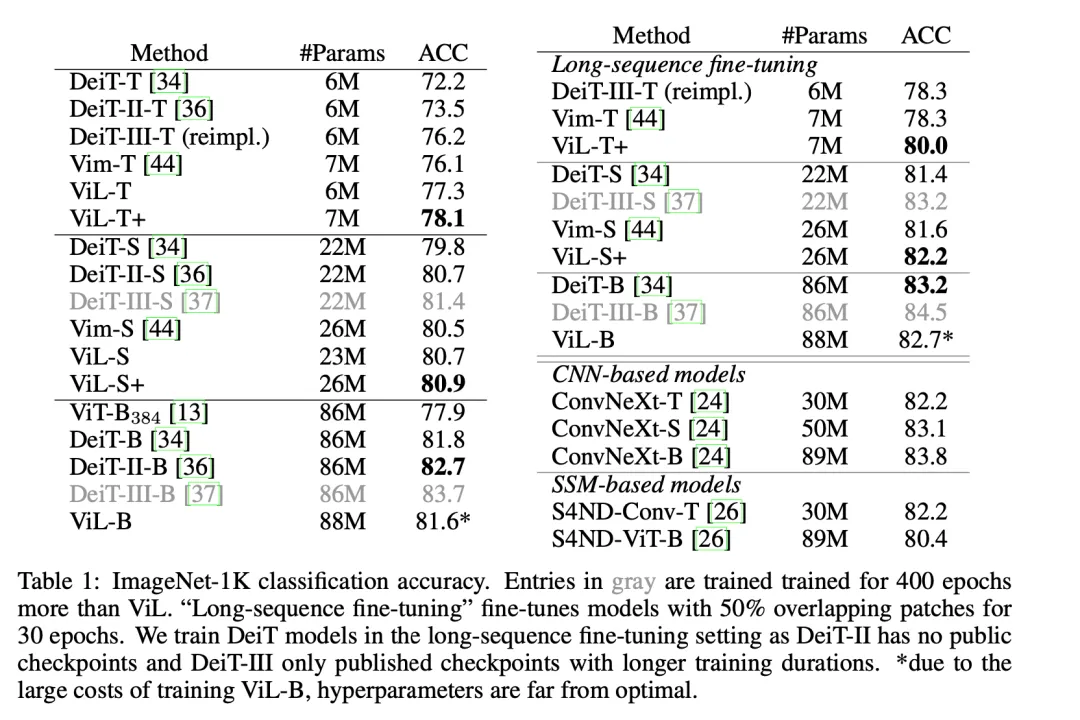
通過在「長序列微調」設置中微調模型,性能可以進一步提高,該設置通過使用連續(xù)補丁 token 之間 50% 的重疊,將序列長度增加到 729,對模型進行 30 個周期的微調。
盡管沒有利用卷積固有的歸納偏置,ViL 還是展現(xiàn)出了與基于 CNN 的模型(如 ConvNeXt)相當?shù)男阅堋?/span>
塊設計
該團隊研究了設計 ViL 塊的不同方式,如圖 2 所示。
- 普通且單向的 xLSTM 塊未能達到期待的性能,因為 xLSTM 的自回歸性質并不適合圖像分類。
- 以雙向方式遍歷塊 —— 即在每個塊中引入第二個 mLSTM 層,該層向后遍歷序列(類似于 Vim),提高了性能,但也需要更多的參數(shù)和 FLOPS。
- 共享前向和后向 mLSTM 的參數(shù)使模型在參數(shù)上更高效,但仍然需要更多的計算并超載這些參數(shù),而這最終也會導致性能下降。
- 使用交替塊在保持計算和參數(shù)效率的同時提高了性能。
該團隊還探索了四向設計,這指的是按行(兩個方向)和按列(兩個方向)遍歷序列。雙向僅按行遍歷序列(兩個方向)。
圖 2 可視化了不同的遍歷路徑。
 圖片
圖片
由于雙向和四向塊的成本增加,這項研究是在設置大幅減少的條件中進行的。
研究人員在 128x128 分辨率下,對包含僅來自 100 個類別的樣本的 ImageNet-1K 的一個子集進行 400 個周期的訓練。這是特別必要的,因為四向實現(xiàn)方法與 torch.compile(來自 PyTorch 的一個通用速度優(yōu)化方法)不兼容,這會導致更長的運行時間,如表 2 最后一列所示。
由于此技術限制,該團隊最終了選擇交替雙向塊作為核心設計。

分類設計
為了使用 ViT 進行分類,需要將 token 序列匯集成一個 token,然后將其作為分類頭的輸入。
最常見的匯集方法是:(i) 在序列的開頭添加一個可學習的 [CLS] token,或 (ii) 平均所有補丁 token,生成一個 [AVG] token。使用 [CLS] 還是 [AVG] token 通常是一個超參數(shù),兩種變體的性能相當。相反,自回歸模型通常需要專門的分類設計。例如,Vim 要求 [CLS] token 位于序列的中間,如果采用其他分類設計,如 [AVG] token 或在序列的開始和結束處使用兩個 [CLS] token,則會造成嚴重的性能損失。
基于 ViL 的自回歸特性,研究者在表 3 中探討了不同的分類設計。

[AVG] 是所有補丁 token 的平均值,「Middle Patch 」使用中間的補丁 token,「Middle [CLS]」使用序列中間的一個 [CLS] token,「Bilateral [AVG]」使用第一個和最后一個補丁 token 的平均值。
可以發(fā)現(xiàn)的是, ViL 分類設計相對穩(wěn)健,所有性能都在 0.6% 以內(nèi)。之所以選擇 「Bilateral [AVG]」而不是 「Middle [CLS]」,因為 ImageNet-1K 有中心偏差,即物體通常位于圖片的中間。通過使用 「Bilateral [AVG]」,研究者盡量避免了利用這種偏差,從而使模型更具通用性。
為了與之前使用單個 token 作為分類頭輸入的架構保持可比性,研究者對第一個和最后一個 token 進行了平均處理。為了達到最佳性能,建議將兩個標記合并(「Bilateral Concat」),而不是取平均值。
這類似于 DINOv2 等自監(jiān)督 ViT 的常見做法,這些是通過分別附加在 [CLS] 和 [AVG] token 的兩個目標來進行訓練的,因此可以從連接 [CLS] 和 [AVG] token 的表征中獲益。視覺 SSM 模型也探索了這一方向,即在序列中分散多個 [CLS] token,然后將其作為分類器的輸入。此外,類似的方向也可以提高 ViL 的性能。
更多研究細節(jié),請參考原論文。