Delphi:更適合端到端模型的world model,更長更真更可控!(理想汽車&西湖大學)
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
導讀:
理想汽車智駕團隊聯合西湖大學等提出了一種新的基于擴散模型的可控長視頻生成的方法--Delphi,來釋放端到端模型的泛化性能。該方法可以在公開的nuScenes數據集上生成長達 40 幀的具備時空一致性的長視頻,該時長大約是目前最優方法可生成時長的 5 倍。以Delphi為數據引擎,該文進一步地提出了一個 failure-case driven framework,該框架能有效地提升數據采樣的效率,從而用最小的數據成本提升端到端模型在復雜場景上的泛化性能。在大規模的nuSenes數據集上的實驗表明,以Delphi為數據引擎的的failure-case driven framework, 僅需生成4% 的訓練數據集大小,就能夠將端到端自動駕駛模型的規劃性能提高 25%。
論文信息
- 論文題目:Unleashing Generalization of End-to-End Autonomous Driving with Controllable Long Video Generation
- 論文發表單位:西湖大學,理想汽車,天津大學中山大學,東南大學,哈爾濱工程大學,哈爾濱工業大學
- 論文地址:https://arxiv.org/abs/2406.01349
- 項目主頁:https://westlake-autolab.github.io/delphi.github.io/

寫在前面|為什么提出?

使用生成模型來合成新數據已經成為自動駕駛領域解決數據稀缺問題的事實標準。雖然現有方法能夠提升感知模型的性能,但我們發現這些方法未能改善端到端自動駕駛模型的規劃性能,因為生成的視頻通常少于8幀,且空間和時間的一致性問題不可忽視。為此,我們提出了Delphi,一種基于擴散模型的長視頻生成方法,通過跨多視角的共享噪聲建模機制來增加空間一致性,并通過特征對齊模塊實現精確的可控性和時間一致性。我們的方法能夠生成多達40幀的視頻而不失去一致性,約為現有最先進方法的5倍。不同于隨機生成新數據的策略,我們進一步設計了一個采樣策略,使Delphi生成與失敗案例相似的新數據,以提高采樣效率。這是通過借助預訓練視覺語言模型建立一個failure-case driven framework實現的。我們的廣泛實驗表明,Delphi生成的長視頻質量更高,超越了現有最先進的方法。因此,盡管只生成了訓練數據集大小的4%,我們的框架首次超越了感知和預測任務,將端到端自動駕駛模型的規劃性能提升了25%。請參考項目主頁:https://westlake-autolab.github.io/delphi.github.io/
Demo示例
在nuScenes數據集上的長視頻生成(40幀)
精準的控制能力
該文從兩方面來展示了Delphi的精準控制能力。
首先,對于instance-level即物體級別的時序一致性,與現有最優方法相比,Delphi可以在前后幀上保持同一車輛實例的外觀一致性:

除此之外,Delphi展示了優秀的multi-level編輯能力。如下圖所示,通過編輯instance caption / scene caption, Delphi可以精準地改變場景中實例的顏色屬性/整體的天氣屬性:

Scaleing up
除此之外,為了驗證訓練數據規模的影響,該文又做了一個額外的實驗(注意:只有該處用了extra training data)。即通過在私有的多視角駕駛數據集 ? 上進行額外訓練(訓練數據大約比 nuScenes 大 50 倍),Delphi 展示了生成多達 120 幀具有時空一致性的長視頻的有趣功能。這充分體現了Delphi的可擴展性。
? 理想汽車股份有限公司 版權所有。
應用:可用于閉環評估的視覺渲染器
Delphi 可以用作具有逼真圖像生成能力的數據引擎,并進一步支持端到端模型(如 UniAD)的閉環評估。下面我們展示了在 nuNcenes 上進行閉環評估的視頻demo:
上面一排展示的是 nuNcenes 數據集采集到的一段開環評估場景:“自車以恒定速度行駛”,其中自車不能與真實環境交互。下排展示了我們使用 Delphi 在 nuNcenes 上的一段閉環評估場景:“自車加速,與前車的距離不斷減小,最終撞上前車”。以Delphi作為數據引擎,端到端算法可以自由地與真實環境交互,從而在仿真環境中就可實現上路實測的效果。
方法框架介紹
我們首先介紹Delphi,一種用于生成自動駕駛長多視角視頻的創新方法。然后介紹了一個failure-case driven framework,展示了如何利用長視頻生成能力,僅通過訓練數據集中的數據,來自動增強端到端模型的泛化能力。
Delphi: A Controllable Long Video Generation Method
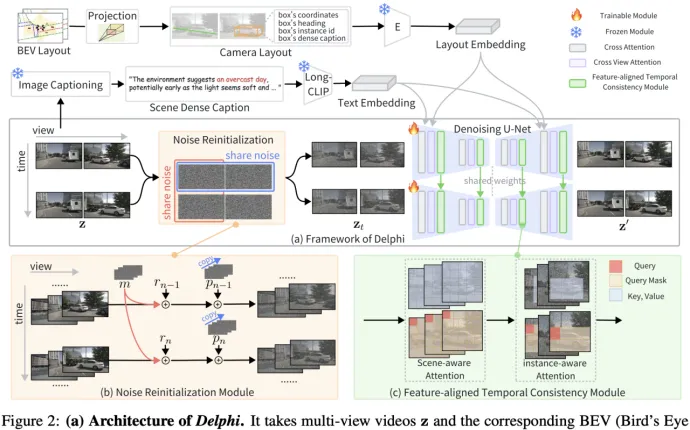
Delphi的整體框架如上圖所示。現有方法往往忽略了時間和空間維度上的噪聲處理,導致長視頻生成質量較差。相比之下,我們提出了兩個關鍵組件來解決這些問題:Noise Reinitialization Module(NRM)和 Feature-aligned Temporal Consistency(FTCM)。
- Noise Reinitialization Module
多視角視頻自然在時間和視角維度上表現出相似性。然而,現有方法分為兩類:一類是并行單視角視頻生成方法,無法直接應用于戶外多視角場景;另一類是多視角生成模型,它們添加的獨立噪聲未考慮視角間的一致性。我們通過引入跨這兩個維度的共享噪聲來解決這個問題。具體而言,如上圖(b)所示,我們在時間維度上引入共享運動噪聲 m,在視角維度上引入共享全景噪聲 p。最終輸出的多視角視頻的噪聲版本在時間和視角維度上都具有相關性。其中引入共享噪聲的過程可以表示如下:

- Feature-aligned Temporal Consistency
現有方法在生成當前幀時,利用簡單的交叉注意力機制將前一幀的信息融合到當前視角中。然而,它們往往忽略了不同網絡深度處的特征具有不同的感受野。結果是,這種粗略的特征交互方法未能捕捉到前一幀中不同層次的所有信息,導致視頻生成性能不理想。
為了解決這個問題,我們提出了一種更有效的結構,旨在完全建立相鄰幀中相同網絡深度下的對齊特征之間的特征交互,如上圖(c)所示。我們的做法是確保全局一致性并優化局部一致性,其中包含兩個主要設計:Scene-aware Attention 和 Instance-aware Attention。
- Scene-aware Attention
為了充分利用前一幀中不同網絡深度的豐富信息,我們提出了一種場景級跨幀注意力機制。具體來說,該模塊在相鄰幀中相同網絡深度的特征上執行注意力計算。其計算過程可以表示如下:

- Instance-aware Attention
為了增強場景中移動物體的一致性,我們提出了一種實例感知跨幀注意力機制。與場景級注意力相比,該模塊使用前景邊界框作為注意力掩碼,在相鄰幀的局部區域中計算特征交互。其計算過程可以表示如下:

Failure-case Driven Framework

為了利用生成的數據,常見的方法是隨機抽取訓練數據集的一個子集,然后應用視頻生成模型來增強這些數據,從而提升下游任務的性能。我們假設這種隨機抽樣并未考慮現有的長尾案例分布,還有進一步優化的空間。因此,我們提出了一個簡單但有效的 failure-case driven framework,通過四個步驟來降低計算成本。如上圖所示,我們首先評估現有的失敗案例,然后采用一種 visual language-based 的方法來分析這些數據中的模式,并檢索相似的場景以更深入地理解上下文。接著,我們多樣化場景和實例的描述,以生成具有不同外觀的新數據。最后,我們用這些額外的數據對下游任務進行訓練,以提高泛化能力。
請注意,所有這些操作都是在訓練集上進行的,以避免任何驗證信息的潛在泄漏。每個組件的詳細實現請參見補充材料。
實驗結果
本文在大規模真實場景的nuScenes進行實驗,以評估生成模型的性能,實驗結果如下。我們的評估指標包括FID、FVD 和下游模型在新生成數據上的性能來評估 image、video和sim-to-real gap。
主要實驗
- 將 Delphi 與最先進的視頻生成方法進行比較

如表1所示,Delphi 在短視頻生成任務上以明顯優勢超越了現有的最先進方法,并且可以生成長達40幀的視頻。
- 本文的 failure-case driven framework 增強了端到端規劃模型的泛化性能

為了證明我們框架的有效性,我們在表2中比較了三個因素:生成案例數量、數據引擎(視頻生成方法)和數據源選擇。總的來說,我們發現,通過僅生成訓練集大小的4%數據,我們的方法可以將碰撞率從0.33降低到0.27,降低了25%。然而,在相同的設置下,如果我們使用其他數據引擎(如 Panacea)對 UniAD 進行微調,碰撞率會增加。盡管如此,我們還是利用隨機抽樣對兩種數據引擎進行了比較,我們的方法始終優于基線。
我們在下圖中展示了我們的框架如何修復失敗案例:

如果我們從驗證集中對layout進行采樣,會發生什么?
由于 Delphi 只看到 nuScenes 的訓練集,一個自然的問題是,我們是否可以包含驗證集,看看是否可以進一步提升下游任務的性能?在這里,我們收集了來自訓練集和驗證集的失敗案例。請注意,由于我們的框架只使用layout和caption,因此驗證集中的原始視頻片段在任何訓練過程中都不會被暴露。我們注意到,僅生成429個cases,僅占訓練集大小的1.5%,碰撞率就從0.33降低到0.26。這個結果可能對工業從業者很有趣,即僅看到訓練集視頻的diffusion-based方法可以通過layout和caption,來有效地提升驗證集的性能。
消融實驗
sim-to-real gap 的消融實驗
為了進一步評估 sim-to-real gap,我們使用不同比例的合成數據訓練 UniAD。在表3 的第二行,我們用純生成的視頻片段訓練 UniAD,碰撞率從0.34增加到0.50。這表明合成數據尚不能完全替代真實數據。相比之下,如果我們考慮增量學習的設置,即使用額外數據訓練 UniAD 時,使用合成數據能夠顯著提升性能,而使用額外的真實數據則會使性能從0.34惡化到0.38。

場景和實例編輯的消融實驗
表4 展示了數據多樣性對端到端模型的有效性。具體來說,我們通過兩種方法編輯現有場景:scene-level editing 和 instance-level editing。這一高級功能使我們能夠從有限的現有數據中生成大量的新數據。如表4所示,同時編輯場景和實例能取得最佳性能。利用強大的精確可控性,Delphi 通過生成更豐富和多樣的數據,最大化端到端模型的性能。

NRM 和 FTCM的消融實驗
在表5 中,我們驗證了兩個模塊NRM和FTCM。我們看到所有指標均顯著提高,從而驗證了我們提出方法的有效性。特別是,FTCM 結構將 FID 從 22.85 提高到 19.81,而 NRM 則進一步提升了這一指標。

總結
本文提出了一種用于自動駕駛場景的新型視頻生成方法,可以在 nuScenes 數據集上合成多達40幀的視頻。令人驚訝的是,本文展示了以僅使用訓練數據集訓練的擴散模型為數據引擎,并通過一個樣本高效的 failure-case driven framework,就能夠提升端到端規劃模型的planning性能。我們希望能為該領域的研究人員和實踐者在解決數據稀缺問題上提供一些啟示,并向確保自動駕駛車輛道路安全邁出堅實的一步。