













詳解Kafka端到端的延遲
【編者的話】在大規(guī)模的使用Kafka過程中,我們通常會遇到各種各樣的問題,比如說,通常會有一些大數(shù)據(jù)集群中的Job發(fā)現(xiàn)總有幾個Task會比較慢,導(dǎo)致整體的任務(wù)遲遲不能完成運行,這種情況通常問題會比較復(fù)雜,想要知道具體延遲在哪里,我們需要知道在Kafka集群中哪些點可能會增加端到端的延遲。
接下來的內(nèi)容翻譯自Confluent官網(wǎng)博客中的一篇文章,希望能夠幫助大家理解Kafka使用過程中端到端的延遲。
欺詐檢測、支付系統(tǒng)和股票交易平臺只是許多Apache Kafka用例中的一小部分,這些用例需要快速且可預(yù)測的數(shù)據(jù)交付。例如,在線銀行交易的欺詐檢測必須實時發(fā)生,以交付業(yè)務(wù)價值,而不需要為每個交易增加超過50-100毫秒的開銷,以保持良好的客戶體驗。
在Kafka術(shù)語中,數(shù)據(jù)交付時間(data delivery time)是由端到端延遲(end-to-end latency)定義的,即消費者獲取一條向Kafka生成的記錄所需的時間。延遲目標(biāo)表示為目標(biāo)延遲和滿足此目標(biāo)的重要性。例如,您的延遲目標(biāo)可以表示為:我希望99%的情況下從Kafka獲得端到端延遲為50 ms。
這將增加可用性、持久性和吞吐量目標(biāo)。實現(xiàn)高持久性和高吞吐量兩個目標(biāo),我們需要進(jìn)行一定的權(quán)衡,挑戰(zhàn)在于在保持延遲界限的同時擴展應(yīng)用程序的吞吐量,并調(diào)整Kafka集群的大小以使用可接受的Broker延遲來處理客戶端和復(fù)制的請求。延遲也取決于您對硬件或云提供商的選擇,所以您需要能夠監(jiān)視和調(diào)優(yōu)您的客戶端,以在您獨特的環(huán)境中實現(xiàn)您的特定延遲目標(biāo)。
注意:通常情況下,Broker所在的網(wǎng)絡(luò)區(qū)域其實也會對延遲造成很大影響,當(dāng)然這仍然取決于您對可用性和延遲的權(quán)衡。
之前,我們有寫過白皮書《Optimizing Your Apache Kafka Deployment》,其中列出了配置Kafka部署以優(yōu)化各種目標(biāo)的指導(dǎo)原則。
這篇文章將幫助你進(jìn)一步獲得更好的直覺和對端到端延遲的理解,并配置和擴展您的應(yīng)用程序的吞吐量,同時保持延遲的界限。
理解端到端的延遲(end-to-end latency)
端到端延時是指應(yīng)用邏輯調(diào)用KafkaProducer.send()生產(chǎn)消息到該消息被應(yīng)用邏輯通過KafkaConsumer.poll()消費到之間的時間。
下圖顯示了一條記錄在系統(tǒng)中的路徑,從Kafka生產(chǎn)者到Kafka的Broker節(jié)點,副本的復(fù)制,以及消費者最終在其主體分區(qū)日志中獲取到具體的消息。
因此,端到端的延遲主要會由以下幾個部分組成:
- Produce time:內(nèi)部Kafka Producer處理消息并將消息打包的時間
- Publish time:Producer發(fā)送到Broker并寫入到Leader副本log的時間
- Commit time:Follower副本備份消息的時間
- Catch-up time:消費者追趕消費進(jìn)度,消費到該消息位移值前所花費的時間
- Fetch time:從Broker讀取該消息的時間
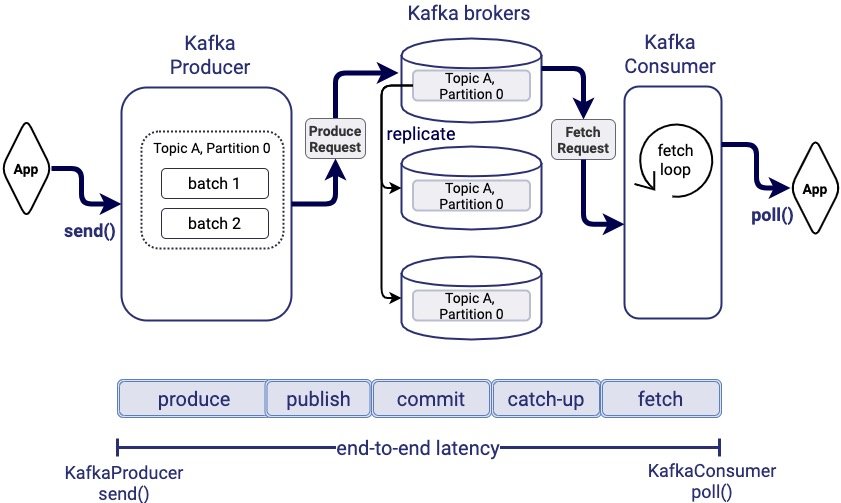
在接下來的內(nèi)容中,我們將分別解釋這五個延遲階段的具體含義,特定的客戶端配置或應(yīng)用邏輯設(shè)計通常會極大地影響端到端延時,因此我們有必要精準(zhǔn)定位哪個因素對延時的影響最大。
- Produce time
Produce time指的是從應(yīng)用程序通過KafkaProducer.send()生產(chǎn)一條記錄到包含該消息的生產(chǎn)者請求被發(fā)往leader副本所在的broker之間的時間。(因此,生產(chǎn)者所處的網(wǎng)絡(luò)環(huán)境以及對應(yīng)topic分區(qū)leader副本所在的broker的網(wǎng)絡(luò)可能會影響到produce time的延遲)
Kafka producer會將相同topic分區(qū)下的一組消息打包在一起形成一個批次(batch)以提升網(wǎng)絡(luò)I/O性能。(在必要情況下,我們可以對生產(chǎn)者的batch size進(jìn)行一定的調(diào)整)
默認(rèn)情況下,producer會立即發(fā)送batch,這樣一個batch中通常不會包含太多的消息。為了提高batch的效率,生產(chǎn)者通常會對linger.ms來人為設(shè)置一個較小的延遲來保證有足夠多的消息記錄能封裝在一個batch中。一旦過了linger.ms設(shè)置的事件,或者batch size已經(jīng)達(dá)到最大值(batch.size的參數(shù)值),這個batch將被認(rèn)為已經(jīng)完成。
如果生產(chǎn)者也開啟了壓縮(compression.type),Kafka的生產(chǎn)者會將已完成的batch進(jìn)行壓縮。在batch完成之前,它的大小時根據(jù)生產(chǎn)者指定的壓縮類型和之前觀測到的壓縮比率估算出來的。
如果發(fā)送給leader副本的未確認(rèn)的生產(chǎn)者請求數(shù)量已經(jīng)達(dá)到最大(max.inflight.requests.per.connection=5),則在生產(chǎn)者的批處理可能需要等待更長的時間。因此,broker響應(yīng)生產(chǎn)者請求越快,生產(chǎn)者的等待時間也將會變得更小。
- Publish time
Publish time是指內(nèi)部Kafka生產(chǎn)者發(fā)送生產(chǎn)者請求到一個broker節(jié)點,并且對應(yīng)的消息到達(dá)leader副本日志之間的時間。當(dāng)請求到達(dá)Broker節(jié)點時,負(fù)責(zé)連接的網(wǎng)絡(luò)線程將獲取該請求并將其放入請求隊列中。其中一個請求處理程序線程從隊列中獲取請求并處理它們。(對應(yīng)broker節(jié)點的num.thread 和num.io.thread兩個相關(guān)參數(shù))
因此,Publish time包含生產(chǎn)者請求的網(wǎng)絡(luò)時間,broker上的排隊時間,以及將消息追加到日志所消耗的時間(通常也是page cache 的訪問時間)。當(dāng)Broker端負(fù)載比較低,網(wǎng)絡(luò)和日志的追加寫入時間會影響publish time,隨著broker負(fù)載變高,隊列延遲的增加 將會更多的影響publish time。
- Commit time
Commit time是指從leader副本中復(fù)制消息到全部的同步副本(all in-sync replicas)中所消耗的時間。Kafka只會將已提交(committed)的消息暴露給consumer,也就是該消息必須在全部的ISR中包含。follower副本中的消息會從leader副本中并行的拉取,在一個正常的集群中,我們通常不希望副本處于不同步狀態(tài)(當(dāng)然有的業(yè)務(wù)場景可能會導(dǎo)致短暫的不同步現(xiàn)象)。這意味著消息被提交的時間等于ISR中最慢的follower副本所在broker去從ledaer broker節(jié)點獲取記錄并寫入到follower副本日志的時間。
為了復(fù)制數(shù)據(jù),follower所在的broker會想leader節(jié)點發(fā)送fetch請求,準(zhǔn)確的來講消費者也是使用fetch請求來獲取消息。但是,官方在副本復(fù)制的fetch請求中,broker端優(yōu)化了默認(rèn)配置: leader副本會盡早的發(fā)送請求,只要有一個字節(jié)可用,就會發(fā)起fetch請求(由replica.fetch.min.bytes參數(shù)控制)或者當(dāng)replica.fetch.wait.max.ms滿足條件。Commit time主要受副本因此配置參數(shù)的影響以及集群的當(dāng)前負(fù)載情況。
- Catch-up time
Kafka中消息是按照其生產(chǎn)的順序被消費的,除非顯示的聲明了一個新的offset或者有一個新的消費者從最新的offset進(jìn)行消費。同一個分區(qū)下,consumer必須要消費完之前發(fā)布的消息后才能讀取后面的消息。假設(shè)在提交消息時,消費者的偏移量是提交消息后面的N條消息,那么,Catch-up time就是消費者消費者N條消息的總時間。

當(dāng)我們在構(gòu)建實時處理應(yīng)用的時候,最好讓catch-up時間為0,即一旦消息被提交,消費者可以立馬讀取到消息。如果消費者總是落后,端到端延遲可能會變得無限大。因此,catch-up 時間通常依賴于消費者的能力是否能夠追趕上生產(chǎn)者的吞吐量。
- Fetch time
訂閱主題分區(qū)的消費者會不斷輪詢?nèi)膌eader副本中獲取更多的數(shù)據(jù),F(xiàn)etch time是從leader副本所在broker節(jié)點獲取消息記錄的s時間,可能需要等待足夠的數(shù)據(jù)來形成對fetch請求的響應(yīng),并從KafkaConsumer.poll()的響應(yīng)中返回記錄。在默認(rèn)的配置下,已經(jīng)對于消費者的fetch延遲做了優(yōu)化(fetch.min.bytes=1),即及時只有一個字節(jié)可用的時候,fetch請求也會響應(yīng)數(shù)據(jù),或者在一個短暫超時之后fetch.max.wait.ms。
- End-to-end latency VS producer and consumer latencies
下圖顯示了Kafka客戶端觀察到的延遲(通常稱為生產(chǎn)者延遲和消費者延遲)與端到端延遲之間的關(guān)系。
生產(chǎn)者延遲是指KafkaProducer.send()發(fā)送和生產(chǎn)的消息被確認(rèn)間的事件。消息的確認(rèn)依賴于acks的配置,該參數(shù)可以控制消息的持久性(durability):
- 當(dāng)acks=0,立即確認(rèn),不等待broker的返回
- 當(dāng)acks=1,消息被追加到leader副本所在分區(qū)后再確認(rèn)
- 當(dāng)acks=all,在所有的ISR(同步副本)都接收到消息時才確認(rèn)
所以,生產(chǎn)者延遲包含produce time,publich time(如果acks >= 1),commit time(如果acks=all)以及生產(chǎn)者響應(yīng)從broker返回到生產(chǎn)者的時間。
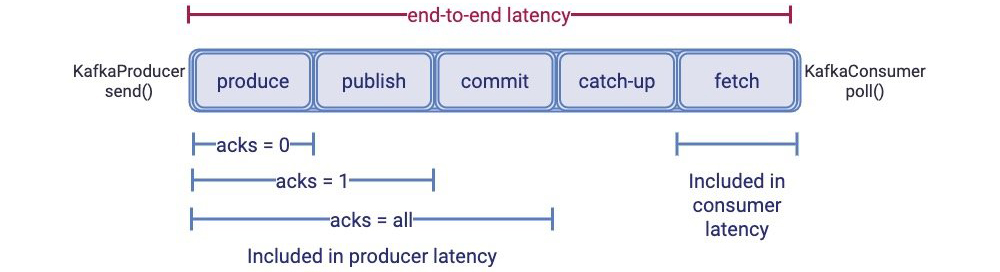
上圖清晰的向我們展示了為何改變acks參數(shù)能夠減少生產(chǎn)者延遲(其實是通過從生產(chǎn)者延遲中移除幾個延遲概念來減少的publish和commit)。不過,無論我們?nèi)绾闻渲蒙a(chǎn)者的acks參數(shù),publish和commit時間總是端到端延遲的一部分。
消費者延遲(Consumer latency)是指消費者發(fā)起一個fetch請求到broker節(jié)點,以及broker節(jié)點向consumer返回響應(yīng)的時間。計算方法是KafkaConsumer.poll()返回的時間。Consumer的延遲主要包含了上圖中的fetch time。
控制end-to-end latency
如果我們思考一條消息的生命周期,控制端到端延時其實就是控制消息在系統(tǒng)中流轉(zhuǎn)的時間總和。很多Kafka clients端和broker端參數(shù)的默認(rèn)值已然對延時做了優(yōu)化:比如減少人為等待時間來提高批處理的能力(通過linger.ms,fetch.min.bytes,replica.fetch.min.bytes參數(shù)來適當(dāng)調(diào)優(yōu))。其他的延時可能來自于broker端上的隊列等候時間,控制這種延時就要涉及控制broker的負(fù)載(CPU或吞吐量),通常情況下我們要時刻關(guān)注broker節(jié)點的各項基礎(chǔ)監(jiān)控指標(biāo)。
如果我們將系統(tǒng)視為一個整體,那么整個端到端的延遲還要求系統(tǒng)中的每一個部分(生產(chǎn)者,broker,消費者)都能夠可靠的維持應(yīng)用程序邏輯所需的吞吐量。
例如,如果你的應(yīng)用程序邏輯以100 MB/s發(fā)送數(shù)據(jù),但是由于某種原因,你的Kafka消費者吞吐量在幾秒鐘內(nèi)下降到10 MB/s,那么在此之前產(chǎn)生的大多數(shù)消息都需要在系統(tǒng)中等待更長的時間,直到消費者趕上了。此時,你需要一種高效的方式來擴展你的Kafka clients程序以提升吞吐量——高效地利用broker端資源來減少隊列等候時間和偶發(fā)的網(wǎng)絡(luò)擁塞。
理想情況下,限制延遲意味著確保所有延遲都低于目標(biāo)。但實際生產(chǎn)環(huán)境中,由于意外故障和峰值負(fù)載,這種嚴(yán)格的保證是不可能的。不過,可以設(shè)計應(yīng)用程序并對系統(tǒng)進(jìn)行調(diào)優(yōu),以實現(xiàn)95%的延遲目標(biāo),控制所有的消息延遲在95~99%低于目標(biāo)延遲時間。高百分位延遲也稱為尾部延遲,因為它們是延遲頻譜的尾部。
目標(biāo)延時所用的百分位越大,你需要降低或容忍應(yīng)用最差表現(xiàn)所做的努力就越多。比如,偶爾的大請求可能會阻塞全部的請求,從而增加整體的延遲,這也就是所謂的head-of-line隊首阻塞。同時,大量低速率客戶端可能偶爾會同時向Kafka發(fā)送生產(chǎn)或消費請求,或全部刷新集群元數(shù)據(jù),也會導(dǎo)致請求隊列比平常更長,從而引發(fā)比平時更嚴(yán)重的尾延遲。這種行為就是所謂的micro-bursting(微型沖擊,可能就是水滴石穿的意思吧)。
不同客戶端配置的延遲測試
在這接下來的內(nèi)容中,我們使用實驗結(jié)果來說明Kafka客戶端配置和吞吐量擴展技術(shù)對性能的影響。我們使用Kafka內(nèi)置的Trogdor測試框架以及生產(chǎn)者和消費者的基準(zhǔn)測試,ProduceBench和ConsumeBench來進(jìn)行我們的生產(chǎn)者和消費者實驗測試。
我們所有的測試都在一個包含9個代理的Kafka集群上運行,該集群的復(fù)制因子為3,這保證了在出現(xiàn)最多兩個同時發(fā)生的節(jié)點故障時不會丟失消息。
Kafka集群運行在AWS的r5.xlarge實例上,使用有2T的EBS(彈性塊存儲)。Kafka的broker節(jié)點分布在同一區(qū)域內(nèi)的三個可用性區(qū)域(AZ),以獲得更強的容錯性,其中每個主題分區(qū)副本被放置在一個不同的AZ上,并且Kafka客戶端配置使用SASL認(rèn)證和SSL加密,Broker之間使用PLAINTEXT進(jìn)行通信。
主題:需要注意的是,分布式集群中節(jié)點如果在不同可用區(qū)也可能導(dǎo)致延遲的增加,當(dāng)然這要在延遲和容錯性角度進(jìn)行權(quán)衡,也需要考慮到云廠商的可用區(qū)之間本身的延遲。
我們的實驗使用了以下非默認(rèn)客戶端配置和其他規(guī)范:
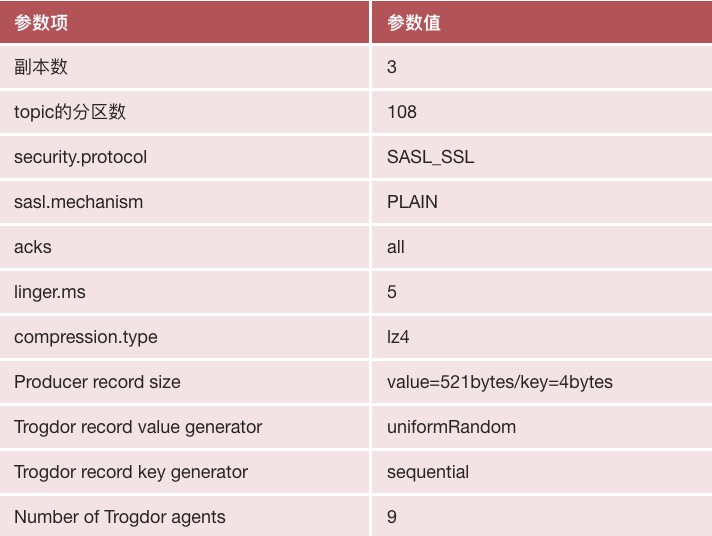
這個測試場景會產(chǎn)生額外的延遲:多可用區(qū)可能增加commit時間,由于是跨可用區(qū)的副本。無論是clients端還是broker端,SSL加密也是有開銷的。同時由于SSL無法利用Zero Copy特性進(jìn)行數(shù)據(jù)傳輸,因為consumer獲取消息時也會增加額外的開銷。
雖然這些因素都會影響延遲,但是通常情況下企業(yè)內(nèi)部可能還是需要這種架構(gòu)上的考慮,因此采用該部署結(jié)構(gòu)進(jìn)行測試。
持久性設(shè)置對延遲的影響
當(dāng)將延遲目標(biāo)與其他需求疊加在一起時,首先考慮持久性需求是很有用的。由于數(shù)據(jù)的重要性,通常需要一定程度的持久性。
優(yōu)化持久性會增加端到端延遲,因為這會增加延遲的復(fù)制開銷(提交時間),并向Broker添加復(fù)制負(fù)載,從而增加排隊延遲。
- Replication factor
Replication factor是Kafka持久化保證的核心,它定義了Kafka集群上保存的topic副本數(shù)。Replication factor = N表示我們最多能夠容忍N-1臺broker宕機而不必數(shù)據(jù)丟失。N=1能夠令端到端延時最小化,但卻是最低的持久化保證。
增加副本數(shù)會增加備份開銷并給broker額外增加負(fù)載。如果clients端帶寬在broker端均勻分布,那么每個broker都會使用N * w寫帶寬和r + (N - 1) * w讀帶寬,其中w是clients端在broker上的寫入帶寬占用,r是讀帶寬占用。
由此,降低N 對端到端延時影響的最佳方法就是確保每個broker上的負(fù)載是均勻的。這會降低commit time,因為commit time是由最慢的那個follower副本決定的。
如果你的Kafka broker使用了過多的磁盤帶寬或CPU,follower就會開始出現(xiàn)追不上leader的情況從而推高了commit time。(其實還需要注意的是,當(dāng)最小的ISR默認(rèn)為副本的數(shù)量個數(shù)時,在出現(xiàn)follower和leader不同步時恰巧leader節(jié)點宕機,會導(dǎo)致topic本身不可用)
我們建議為副本同步消息流量設(shè)置成使用不同的listener來減少與正常clients流量的干擾。你也可以在follower broker上增加I/O并行度,并增加副本拉取線程數(shù)量number.replica.fetchers來改善備份性能。
- Acks
縱然我們配置了多個副本,producer還是必須通過Acks參數(shù)來配置可靠性水平。設(shè)置acks=all能夠提供最強的可靠性保證,但同時也會增加broker應(yīng)答PRODUCE請求的時間,就像我們之前討論的那樣。
Broker端應(yīng)答的速度變慢通常會降低單個producer的吞吐量,進(jìn)而增加producer的等待時間。這是因為producer端會限制未應(yīng)答請求的數(shù)量(max.inflight.requests.per.connection)。
舉個例子,在我們的環(huán)境中acks=1,我們啟動了9個producer(同時也跑了9個consumer),吞吐量達(dá)到了195MB/秒。當(dāng)Acks切換成all時,吞吐量下降到161MB/秒。設(shè)置更高級別的acks通常要求我們擴展producer程序才能維持之前的吞吐量水平以及最小化producer內(nèi)部的等待時間。
- Min.insync.replicas
min.insync.replicas是一個重要的持久化參數(shù),因為它定義了broker端ISR副本中最少要有多少個副本寫入消息才算PRODUCE請求成功。這個參數(shù)會影響可用性,但是不會影響端到端的延時。因此,選擇一個小一點的值并不能減少commit time并減少延遲。
在滿足延遲目標(biāo)的前提下擴展吞吐
- 延遲和吞吐的權(quán)衡
優(yōu)化Kafka clients端吞吐量意味著優(yōu)化batching的效果。Kafka producer內(nèi)部會執(zhí)行一類batching,即收集多條消息到一個batch中。
每個batch被統(tǒng)一壓縮然后作為一個整體被寫入日志或從日志中讀取。這說明消息備份也是以batch為單位進(jìn)行的。
Batching會減少每條消息的成本,因為它將這些成本攤還到clients端和broker端。通常來說,batch越大這種開銷降低的效果就越高,減少的網(wǎng)絡(luò)和磁盤I/O就越多。
另一類batching就是在單個網(wǎng)絡(luò)請求/響應(yīng)中收集多個batch以減少網(wǎng)絡(luò)數(shù)據(jù)傳輸量。這能降低clients端和broker端的請求處理開銷。這類batching能夠提升吞吐量和降低延時,因為batch越大,網(wǎng)絡(luò)傳輸I/O量越小,CPU和磁盤使用率越低,故最終能夠優(yōu)化吞吐量。另外batch越大還能減低端到端延時,因為每條消息的成本降低了,使得系統(tǒng)處理相同數(shù)量消息的總時間變少了。
這里的延時-吞吐量權(quán)衡是指通過人為增加等待時間來提升打包消息的能力。但過了某個程度,人為等待時間的增加可能會抵消或覆蓋你從打包機制獲得的延時收益。因此你的延時目標(biāo)有可能會限制你能實施打包化的水平,進(jìn)而減少所能達(dá)到的吞吐量并增加延時。如果拉低了本能達(dá)到的吞吐量或端到端延時水平,你可以通過擴展集群來換取或“購買”更多的吞吐量或處理能力。
- 配置kafka的生產(chǎn)者和消費者以實現(xiàn)batching
對于producer而言,batching由兩個參數(shù)進(jìn)行控制: batch.size(16KB)和linger.ms(0),前者控制batch的大小,后者限制延遲量。如果使用場景中,應(yīng)用會頻繁的像kafka集群發(fā)送數(shù)據(jù),及時設(shè)置了linger.ms=0,整個batch也會被盡快填滿。如果應(yīng)用生產(chǎn)數(shù)據(jù)的頻率較低,可以通過增加linger.ms來增加batch。
對于consumer而言,可以調(diào)整fetch.min.bytes(1)來限制每個消費者在每個fetch響應(yīng)中接收的數(shù)據(jù)量,該參數(shù)指定了broker應(yīng)該在一個fetch響應(yīng)中返回的最小數(shù)據(jù),以及fetch.max.wait.ms(500)來設(shè)置等待數(shù)據(jù)的超時時間。在fetch響應(yīng)中的數(shù)據(jù)越多,就會有更少的fetch請求。
在生產(chǎn)者端的batching也會間接影響produce和fetch的請求數(shù)量,因為batch定義了數(shù)據(jù)能夠被獲取的最小數(shù)據(jù)量。
值得注意的是,默認(rèn)情況下,Kafka producer和consumer設(shè)置的是無人為等待時間,這么做的目的是為了降低延時。但是,即使你的目標(biāo)就是了使延時最小化,我們依然推薦你設(shè)置一個不為0的linger.ms值,比如5~10ms。當(dāng)然,這么做是有前提的:
- 如果你擴展了你的producer程序,平均下來使得每個producer實例的發(fā)送速率變得很低,那么你的batch只會包含很少的幾條消息。如果你整體的吞吐量已然很高了,那么你可能會直接把你的Kafka集群壓掛,導(dǎo)致超高的隊列等候時間從而推高延時。此時,設(shè)置一個較小的linger.ms值確實能夠改善延時。
- 如果你在意尾延時,那么增加linger.ms可能會降低請求速率以及同時到達(dá)broker端的瞬時沖擊流量。這種沖擊越大,請求在尾部的延時就越高。這些瞬時沖擊流量決定了你的尾延時水平。
下面這個實驗說明了以上兩種場景。我們啟動了90個producer,向一個有108個分區(qū)的topic發(fā)送消息。生產(chǎn)端整體的吞吐量峰值在90MB/秒。我們跑了3次測試,每一次對應(yīng)一種不同的producer配置。
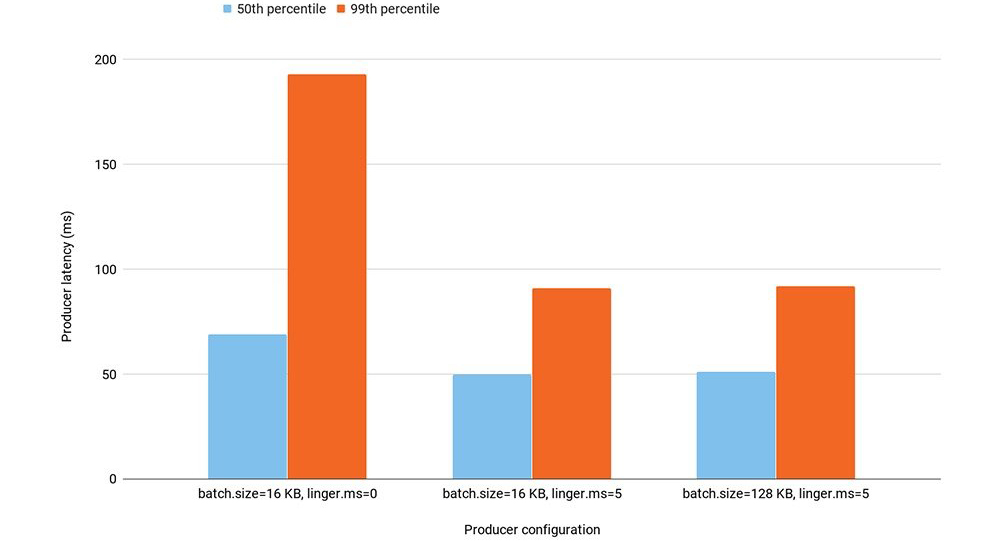
因為在給定的總吞吐下,我們有相對大量的生產(chǎn)者,因此linger.ms = 0導(dǎo)致在生產(chǎn)者端機會沒有batch操作。將linger.ms從0調(diào)整到5可以增加batching能力: 向kafka發(fā)起的生產(chǎn)者請求從2800降低到了1100。這減少了50%和99%的生產(chǎn)者延遲。
增加batch.size不會直接影響生產(chǎn)者的等待時間,因為生產(chǎn)者在填滿batch的時間不會超過linger.ms的限制。在我們的實驗中,增加batch.size從16KB到128KB沒有增加bacth的效果,因為每個生產(chǎn)者的吞吐量非常低。正如預(yù)期的那樣,生產(chǎn)者延遲在兩種配置之間沒有變化。
總之,如果您的目標(biāo)是最小化延遲,我們建議保留默認(rèn)的客戶端批處理配置,并盡可能增加linger.ms。如果你在意尾延時,最好調(diào)優(yōu)下打包水平來減少請求發(fā)送率以及大請求沖擊的概率。
不增加人為延遲以提高batching效率
batching效果不好的另一個原因是producer發(fā)送消息給大量分區(qū)。如果消息不是發(fā)往同一個分區(qū)的,它們就無法聚集在一個batch下。因此,通常最好設(shè)計成讓每個producer都只向有限的幾個分區(qū)發(fā)送消息。
另外,可以考慮升級到Kafka 2.4 producer。這個版本引入了一個全新的Sticky分區(qū)器。該分區(qū)器能夠改善non-keyed topic的打包效果,同時還無需引入人為等待。
- clients的數(shù)量對尾延遲(tail-latency)的影響
即使整體的生產(chǎn)和消費的吞吐量保持不變,通常也是Clients數(shù)越多,broker上負(fù)載越大。這是因為clients數(shù)量多會導(dǎo)致更多的METADATA請求發(fā)到Kafka,繼而要維護更多的連接,故給broker帶來更大的開銷。
相對于50%或平均延時的影響,Clients數(shù)量增加對尾延時的影響更大。
每個producer最多發(fā)送max.inflight.requests.per.connection個PRODUCE請求給單個broker,而每個consumer一次最多只會給一個broker發(fā)送FETCH請求。Clients越多,同一時刻發(fā)送到broker的PRODUCE和FETCH請求也就越多,這就增加了形成請求瞬時沖擊的概率,進(jìn)而推高了尾延時。
Consumer數(shù)量通常由topic分區(qū)數(shù)量以及期望consumer沒有較大lag的目標(biāo)共同決定。但是,我們卻很容易為了擴展吞吐量而引入大量的producer。
基于吞吐量的考量增加producer實例數(shù)可能有相反的效果,因為producer會導(dǎo)致更少的消息被打包,畢竟每個producer處理了更少的消息,因而發(fā)送速率會變慢。同時producer還必須等待更長的時間來積累相同數(shù)量的消息進(jìn)到batch里面。
在我們的實驗中,我們將producer的數(shù)量從90增加到900,發(fā)現(xiàn)吞吐量沒有他打變化:90MB/秒。
我們使用batch.size=16KB,linger.ms=5,acks=all的生產(chǎn)者配置,實驗結(jié)果如下:
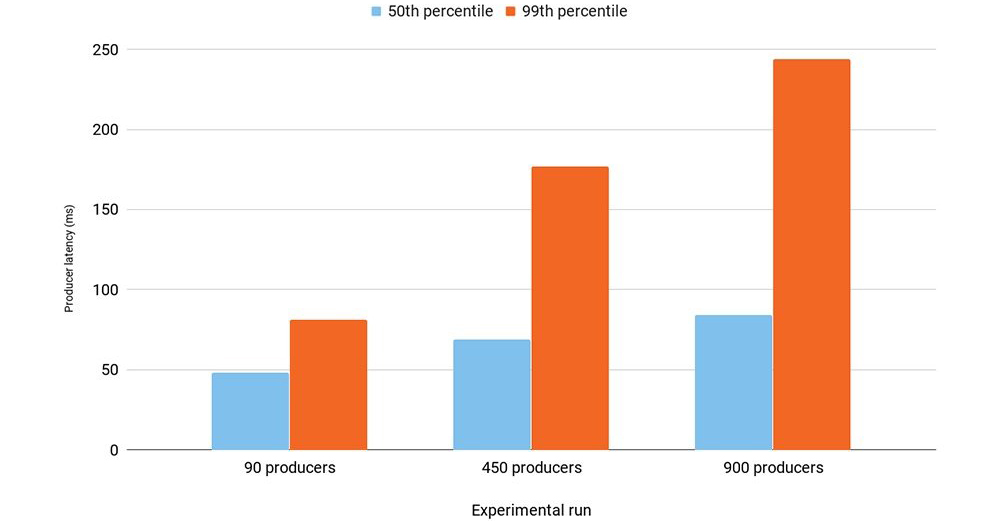
結(jié)果顯示增加producer數(shù)量(90->900)增加了60%的中位數(shù)延時值,而99%延時值幾乎增加了3倍。
延時的增加是因為producer端打包效果變差導(dǎo)致的。
尾延時的增加是因為更大的請求瞬時沖擊,這會拉升broker端延時,同時producer端會等待更長的時間來接收應(yīng)答。
在900個producer的測試中,broker完全被PRODUCE請求壓垮了。用于處理請求的時間幾乎占到了broker端CPU使用率的100%。另外由于我們使用了SSL,它也會進(jìn)一步引入請求級的開銷。
如果你通過添加producer來提升吞吐量,那么可以考慮增加單個proudcer的吞吐量,即改善batching的效果。不管怎樣,你最終可能會有很多producer實例。比如,大公司收集設(shè)備上的統(tǒng)計指標(biāo),而設(shè)備數(shù)可能有成千上萬。此時,你可以考慮使用一個Broker收集來自多個clieints的請求,然后把它們轉(zhuǎn)換成更高效的PRODUCE請求再發(fā)給Kafka。你也可以增加broker數(shù)來降低單個broker上的請求負(fù)載。
關(guān)于增加消費者數(shù)量的說明
當(dāng)擴展消費者時需要注意,在同一個消費者組的消費者會提交offset信息和心跳到broker節(jié)點上(controller節(jié)點)。如果按時間間隔執(zhí)行偏移提交(auto.commit.interval.ms),則消費者組中的更多消費者者會增加偏移提交率。偏移量提交本質(zhì)上是向內(nèi)部__consumer_offsets產(chǎn)生請求,因此增加consumer數(shù)量會導(dǎo)致broker上的請求負(fù)載增加,特別是auto.commit.interval.ms值很小的時候。
壓縮配置的影響
默認(rèn)情況下,Kafka producer不做壓縮。compression.type參數(shù)可以決定要不要做壓縮。
壓縮會在producer端引入額外的開銷來壓縮消息,在broker端做校驗時解壓縮從而引入額外的開銷,另外在consumer端解壓縮也是開銷。
注意:通常情況下broker端的壓縮參數(shù)需要設(shè)置成producer,以避免壓縮方式?jīng)_突導(dǎo)致數(shù)據(jù)無法正常消費,這樣broker只需要直接將壓縮后的日志寫入。
雖然壓縮會增加CPU開銷,但它還是可能減少端到端延時的,因為它能顯著地降低處理數(shù)據(jù)所需的帶寬占用,進(jìn)而減少broker端的負(fù)載。壓縮是在batch級別上完成的,故打包效果越好,壓縮效果也就越好。
更多的分區(qū)可能增加延遲
一個主題的分區(qū)是kafka中的并行單元。發(fā)送到不同分區(qū)的消息可以由生產(chǎn)者并行發(fā)送,由不同的Broker并行寫入,并可以由不同的消費者并行讀取。因此,更多的分區(qū)通常會導(dǎo)致更高的吞吐量,不過單從吞吐量的角度來看,我們能夠從每個Broker有10個分區(qū)的kafka集群,就已經(jīng)能夠達(dá)到最大的吞吐量了。您可能需要更多的主題分區(qū)來支持您的應(yīng)用程序邏輯。
但是,太多的分區(qū)可能導(dǎo)致更多的端到端的延遲。每個主題的分區(qū)越多,對生產(chǎn)者的批處理就越少。每個Broker的主題分區(qū)越多,每個follow副本獲取請求的開銷就越大。每個fetch請求必須去枚舉自己感興趣的分區(qū),并且每個leader副本必須去檢查狀態(tài),同時從請求的每個分區(qū)中去fetch數(shù)據(jù),這通常會導(dǎo)致較小的磁盤I/O。因此,越多的分區(qū),可能會導(dǎo)致更長的commit time和更高的cpu使用,最終導(dǎo)致較長的排隊延遲。
提交時間的增加和更高的CPU負(fù)載會導(dǎo)致所有共享同一個Kafka集群的客戶端端到端延遲的增加,即使是那些只生產(chǎn)和使用少量主題分區(qū)的客戶端來說,也是如此。
我們使用兩個topic來做此次測試。一個Topic有9個生產(chǎn)者生產(chǎn)5MB/s的數(shù)據(jù),然后有一個對應(yīng)9個消費者的消費者組。這個實驗持續(xù)了幾天,我們將這個主題中的分區(qū)數(shù)量從108個逐步增加到7200個(每個Broker8000個),每個步驟運行一個小時。第二個主題在整個實驗運行期間有9個分區(qū)和9個生產(chǎn)者,每個生產(chǎn)者向一個分區(qū)和一個對應(yīng)的消費者組(每個分區(qū)一個)生產(chǎn)消息,該主題每秒生產(chǎn)一個512bytes的數(shù)據(jù)。
下圖顯示了分區(qū)數(shù)量對客戶端訪問9分區(qū)主題的99%的端到端延遲的影響,隨著每個broker上分區(qū)數(shù)的增加,clients的端到端延時大致呈線性增加趨勢。分區(qū)數(shù)的增加會推高broker上的CPU負(fù)載同時拖慢所有clients的備份,即使是對那些只與固定分區(qū)數(shù)量交互的clients而言,也會抬高端到端延遲。

為了減少延時,最好還是限制每個broker上的分區(qū)數(shù),方法是減少總的分區(qū)數(shù)或擴展集群。你還可以通過增加fetcher線程數(shù)量的方式來改善commit time。
broker節(jié)點負(fù)載對延遲的影響
我們已經(jīng)討論了Broker上的負(fù)載導(dǎo)致增加排隊延遲,從而增加了端到端的延遲,很容易看出為什么請求速率的增加會加劇排隊延遲,因為更多的請求會導(dǎo)致更大的隊列。
broker節(jié)點上高資源利用率(磁盤或cpu)可能導(dǎo)致更高的隊列的延遲,并且延遲的增長會隨著資源利用率的增長呈指數(shù)級增長。這是一個可以有排隊理論解釋的已知屬性: Kingman公式證明等待某種資源的時間正比于資源繁忙程度/資源空閑程度(% of time resource is busy)/(% of time resource is idle)。

由于延遲隨資源利用率呈指數(shù)增長,如果broker中的任何資源的利用率接近100%,您可能會看到很高的延遲。通過減少每個Broker的資源使用(比如減少每個broker的鏈接數(shù),請求以及分區(qū)數(shù))或擴展集群來整體降低每個broker節(jié)點的資源使用率,在這種情況可以顯著降低延遲。保持負(fù)載在broker之間平均通常情況下是非常有用的,同時也可以均勻地或基于負(fù)載分布分區(qū)副本也能降低尾部延遲。
因此,通常情況下,負(fù)責(zé)kafka集群的SRE團隊需要自動檢測Broker節(jié)點上的高資源利用率(磁盤和CPU),然后重新平衡集群上的分區(qū),以便更均勻地在Broker之間重新分配負(fù)載,或者在需要時擴展集群。而如果使用云廠商提供的kafka服務(wù),則可以適當(dāng)避免這類事情的發(fā)生,因為云服務(wù)會去做相關(guān)的事情。
總結(jié)
我們已經(jīng)演示了,在為吞吐量擴展客戶機和分區(qū)時的邊界延遲要求時可以通過限制每個broker的連接數(shù)、分區(qū)數(shù)和請求速率來限制每個broker的使用。
邊界尾延遲需要額外注意減少來自客戶機的任何突發(fā)(連接和請求)或應(yīng)用程序行為中的差異。
均勻加載的broker節(jié)點對于最小化尾部延遲也很重要,因為它受到最慢broker的影響。
























