更快更小!ProtoBuf 入門詳解
作者 | dorabwzhang
什么是 Proto Buffer
Proto Buffer 是一種語言中立的、平臺中立的、可擴展的序列化結構數據的方法。
Protocol Buffers are a language-neutral, platform-neutral extensible mechanism for serializing structured data.
這是來自官網 Overview 頁面對于 Protobuf 的簡介,拋開繁雜的修飾詞,Protobuf 的核心是序列化結構數據,為了更好地理解 Protobuf,我們首先需要知道序列化是什么?

序列化指的是將一個數據結構或者對象轉換為某種能被跨平臺識別的字節格式,以便進行跨平臺存儲或者網絡傳輸。
例如前端和后端可能使用不同的編程語言,它們內部的數據表示方式可能不兼容。序列化提供了一種語言無關的格式來表示數據,這樣不同的系統就可以理解和處理這些數據。在我們日常進行前后端開發時,后端通常會返回 JSON 格式的數據,前端拿到后再進行相關的渲染,JSON 其實就是序列化的一種表現形式。而我們這里提到的 Proto Buffer 就是序列化的其他表現形式。事實上除了 JSON 與 Protobuf 還有很多種形式,例如 XML、YAML。
回到正題,我們來看看 Protobuf 所具備的特性:
- 語言中立與平臺中立: Protobuf 不依賴于某一種特殊的編程語言或者操作系統的機制,意味著我們可以在多種編程環境中直接使用。(大部分序列化機制其實都具有這個特性,但是某些編程語言提供了內置的序列化機制,這些機制可能只在該語言的生態系統內有效,例如 Python 的 pickle 模塊)
- 可拓展:Protobuf 可以在不破壞現有代碼的情況下,更新消息類型。具體表現為向后兼容與向前兼容,這一點將在后文做出更詳細的解釋。
- 更小更快:序列化的目的之一是進行網絡傳輸,在傳輸過程中數據流越小傳輸速度自然越快,可以整體提升系統性能。Protobuf 利用字段編號與特殊的編碼方法巧妙地減少了要傳遞的信息量,并且使用二進制格式,相比于 JSON 的文本格式,更節省空間。
工作流程
假設我想要將 Person 的信息在前后端之間進行傳遞,如果說采用傳統 JSON 的形式,那我們可能會寫出下面這樣的代碼:
// 要發送的數據對象
const data = {
username: 'exampleUser',
password: 'examplePassword'
};
// 將數據轉換為 JSON 格式的字符串
const jsonData = JSON.stringify(data);
// 發送 POST 請求
fetch('https://your-api-endpoint.com/login', {
method: 'POST', // 請求方法
headers: {
'Content-Type': 'application/json' // 指定內容類型為 JSON
},
body: jsonData // 請求體
})
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json(); // 解析 JSON 響應
})
.then(data => {
console.log(data); // 處理響應數據
})
.catch(error => {
console.error('There has been a problem with your fetch operation:', error);
});上述代碼做了下面這幾件事:
- 利用工具函數 JSON.stringify 將要發送的數據對象序列化。(對于復雜的數據結構,如果不進行序列化,直接發送 text/plain 的數據,后端顯然是無法準確理解目標數據的,所以序列化在傳輸結構化的數據時起到極其重要的作用)。
- 將序列化后的數據使用 fetch 進行網絡傳輸。
- 利用工具函數 response.json 將返回的序列化數據反序列化得到目標數據,此時反序列化后的 data 就是一個正兒八經的 JavaScript 對象,我們可以直接拿來使用。
上述過程其實就是網絡傳輸結構化數據的通用方法,而 JSON 只是實現這一目的的常用格式。想必此時你對序列化的概念已經有了足夠的理解,序列化其實就像一個翻譯官,將一種編程語言中的數據結構轉換成一種通用的格式,以便其他編程語言或者其他系統能夠理解和處理。下面我們來看看,如果說我們使用 Proto Buffer 來作為這個翻譯官,我們的工作流程是怎樣的?
(1) 定義數據結構:首先,開發者使用.proto文件來定義數據結構。這個文件是一種領域特定語言(DSL),用來描述數據消息的結構,包括字段名稱、類型(如整數、字符串、布爾值等)、字段標識號等等。
syntax = "proto3";
// 有點類似 TypeScript 的 interface
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}為什么需要額外定義 proto 文件呢?Proto Buffer 能夠利用該文件中的定義,去做很多方面的事情,例如生成多種編程語言的代碼方便跨語言服務通信,例如借助字段編碼與類型來壓縮數據獲得更小的字節流,再例如提供一個更加準確類型系統,為數據提供強類型保證。 聽上去或許比較抽象,這里先用一個簡單的例子來說明 proto 文件的好處之一:如果我們采用 JSON 進行序列化,由于 JSON 的類型比較寬松,比如數字類型不區分整數和浮點數,這可能會導致在不同的語言間交換數據時出現歧義,而 proto 中我們可以定義 float int32 等等更加具體的類型。至于其他好處,希望我能在后文中讓大家逐步理解。
(2) 生成工具函數代碼:接下來,我們需要使用 protobuf 編譯器(protoc)處理.proto文件,生成對應目標語言(如C++、Java、Python等)的源代碼。這些代碼包含了數據結構的類定義(稱為消息類)以及用于序列化和反序列化的函數。
(3) 使用生成的代碼進行網絡傳輸:當需要發送數據或者接收到消息對象時,我們就可以利用生成代碼中所提供的序列化與反序列化函數對數據進行處理了,就像我們使用 JSON.stringify 那樣。
值得注意的是,在利用 Protobuf 進行網絡數據傳輸時,確保通信雙方擁有一致的 .proto 文件至關重要。缺少了相應的 .proto 文件,通信任何一方都無法生成必要的工具函數代碼,進而無法解析接收到的消息數據。與 JSON 這種文本格式不同,后者即便在沒有 JSON.parse 反序列化函數的情況下,人們仍能大致推斷出消息內容。相比之下,Protobuf 序列化后的數據是二進制字節流,它并不適合人類閱讀,且必須通過特定的反序列化函數才能正確解讀數據。Protobuf 的這種設計在提高數據安全性方面具有優勢,因為缺少 .proto 文件就無法解讀數據內容。然而,這也意味著在通信雙方之間需要維護一致的 .proto 文件,隨著項目的擴展,這可能會帶來額外的維護成本。
實際應用
由于筆者從事的是前端工作,所以此處將使用 Node.js 及其相關生態進行舉例。由于 protobuf 官方提供的 protoc 并不直接支持由 proto 文件生成 js 代碼,所以我們需要借助一些額外的工具。
倉庫地址:protobuf.js | Github
(1) 安裝所需依賴:npm install protobufjs protobufjs-cli。
(2) 在 src 下新建一個 protos 目錄用于存放 .proto 文件,新建一個 User.proto 文件,添加以下內容:
syntax = "proto3";
// 有點類似 TypeScript 的 interface
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}(3) 在 package.json 中添加一條腳本命令,該命令將會把所有的 proto 文件編譯到一個 js 模塊中并且生成相應的類型聲明。該命令行指令的其他用法請參考上文倉庫中的 README 文件。
syntax = "proto3";
message User {
uint32 id = 1;
string name = 2;
string email = 3;
string password = 4;
}嘗試運行:
npm run proto會得到:
protoRoot.js簡單觀察,我們可以發現該文件中定義了 User 類以及一些其他的工具函數。這些工具函數的具體用法可以參考API 文檔,基本的工作流程如下:
- 對原始的 JavaScript 對象使用 verify 進行類型校驗,隨后使用 create 創建為消息實例,再利用 encode 將其編碼為二進制串。
- 對于二進制串,使用 decode 解碼為消息實例,隨后通過 toObject 轉換為原始的 JavaScript 對象。
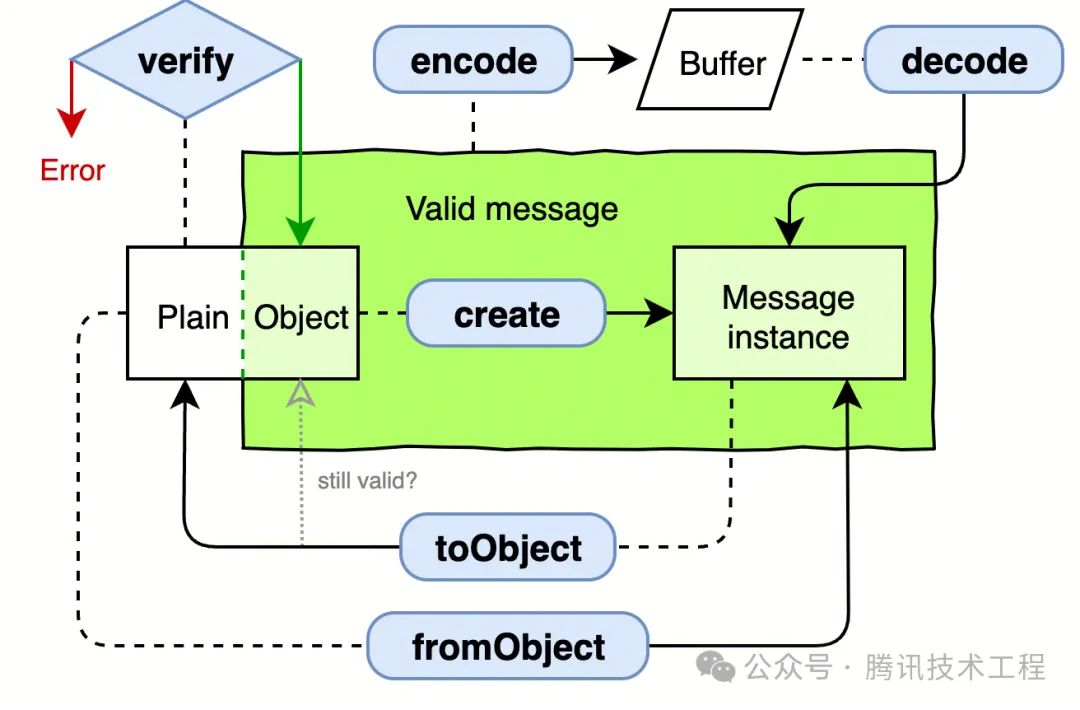
編寫 index.ts 代碼如下:該代碼展示了將 JavaScript 對象序列化并進行網絡傳輸的過程,也模擬了收到 protobuf 數據后將其反序列化的過程。
import axios from "axios";
import * as root from "./protoRoot";
const encodeMessage = ()=> {
const payload = {
id: 2333,
name: 'dora',
email: 'dora@mmm.com',
password: '123456',
deprecated: true,
}
// verify 只會校驗數據的類型是否合法,并不會校驗是否缺少或增加了數據項。
// 雖然上面的對象中多出了一個 deprecated 屬性, 但是 verify 函數并不會報錯。事實上多余的屬性在 encode 時會被忽略
const invalid = root.User.verify(payload);
if( invalid) {
console.log(invalid);
throw Error(invalid);
}
const message = root.User.create(payload);
const buffer = root.User.encode(message).finish();
return buffer;
}
const buffer = encodeMessage();
axios.post('http://localhost:3000/',buffer,{
headers: {
'Content-Type': 'application/octet-stream',
responseType: 'arraybuffer',
},
}).then((res)=>{
const buffer = Buffer.from(res.data);
const message = root.User.decode(buffer);
const user = root.User.toObject(message);
console.log(user);
})
// 可以簡單起一個 express 項目來模擬傳輸過程
const express = require("express");
const bodyParser = require("body-parser");
const app = express();
app.use(bodyParser.raw({ type: 'application/octet-stream', limit: '2mb' }));
const port = 3000;
app.post("/", (req, res) => {
const data = req.body;
console.log(data);
res.type('application/octet-stream')
res.send(data);
});
app.listen(port, () => {
console.log(`Server listening at http://localhost:${port}`);
});以上就是使用 protobuf 進行網絡通信的簡單 demo,事實上實際工作中可能還涉及更加復雜的過程,但由于筆者能力有限暫時無法給出比較合適的例子。在后文中我將嘗試對 proto 的原理進行淺顯的解釋。
語法指南 v3
1.基本語法
讓我們以上面定義的 proto 代碼為例:
syntax = "proto3"; // 指定使用的語法版本, 默認情況下是 proto2
// 定義包含四個字段的消息 User
message User {
uint32 id = 1; // 字段 id 的類型為 uint32,編號 1
string name = 2; // 字段 name 的類型為 string,編號 2
string email = 3; // ...
string password = 4;
}需要注意的是 syntax = "proto3"; 必須是文件的第一個非空的非注釋行。
在聲明 protobuf 文件的語法版本之后,我們就可以開始定義消息結構。這個過程在語法上有點類似于 TypeScript 中的 interface 。在定義字段時,必須指明字段的類型,名稱以及一個唯一的字段編號。
(1) 類型:proto 提供了豐富的類型系統,包括無符號整數 uint32 、有符號整數 sint32、浮點數 float 、字符串、布爾等等,你可以在這個鏈接中查看完整的類型描述。當然,除了為字段指定基本的類型意外,你還可以為其指定 enum 或是自定義的消息類型。
(2) 字段編號:每個字段都需要一個唯一的數字標識符,也就是字段編號。這些編號在序列化和反序列化過程中至關重要,因為他們將替代字段名稱出現在序列化后二進制數據流中。在使用 JSON 序列化數據時,其結果中往往包含人類刻度的字段名稱,例如 { "id": "123456" } ,但是在 protobuf 中,序列化后的結果中只會包含字段編號而非字段名稱,例如在本例中, id 的編號為 1,那我序列化后的結果只會包含 1 而非 id 。這種方法有點類似于 HTTP 的頭部壓縮,可以顯著減少傳輸過程中的數據流大小。 事實上字段編號的使用是 proto 中非常重要的一環,在使用中務必遵循以下原則:
- 字段編號一旦被分配后就不應更改,這是為了保持向后兼容性(咱們會在后文詳細說明)。
- 編號在 [1,15] 范圍內的字段編號在序列化時只占用一個字節。因此,為了優化性能,對于頻繁使用的字段,盡可能使用該范圍內的數字。同時也要為未來可能添加的常用字段預留一些編號(不要一股腦把 15 之內的編號都用了!)
- 字段編號從 1 開始,最大值是 29 位,字段號 19000,19999 是為 Protocol Buffers 實現保留的。如果在消息定義中使用這些保留字段號之一,協議緩沖區編譯器將報錯提示。
(3) (可選)字段標簽:除了上述三個必須設置的元素外,你還可以選擇性設置字段標簽:
- optional : 之后字段被顯式指定時,才會參與序列化的過程,否則該字段將保持默認值,并且不會參與序列化。在 proto3 中所有字段默認都是可選的,并不需要使用這個關鍵字來聲明字段,除非在某些情況下我們需要區分字段是否被設置過。在 proto3 中,如果字段未被設置,它將不會包含在序列化的消息之中。在 JavaScript 中,如果一個字段被指定為 optional 并且沒有設置值,在解析后的對象將不會包含該字段(如果沒有指定 optional 將會包含該字段的默認值)。
- repeated:以重復任意次數(包括零次)的字段。它們本質上是對應數據類型列表的動態數組。
- map:成對的鍵/值字段類型,語法類似 Typescript 中的 Record 。
(4) 保留字段:如果你通過完全刪除字段或將其注釋來更新消息類型,則未來其他開發者對類型進行自己的更新時就有可能重用字段編號。當舊版本的代碼遇到新版本生成的消息時,由于字段編號的重新分配,可能會引發解析錯誤或不預期的行為。為了避免這種潛在的兼容性問題,protobuf 提供 reserved 關鍵字來明確標記不再使用的字段編號或標識符,如果將來的開發者嘗試使用這些標識符,proto 編譯器將會報錯提醒。
message Foo {
reserved 2, 15, 9 to 11, 40 to max;
// 9 to 11 表示區間 [9,11], 40 to max 表示區間 [40, 編號的最大值]
reserved "foo", "bar";
}2.默認值
在解析消息時,如果編碼的消息中并不包含某個不具有字段標簽的字段,那么解析后對象中的響應字段將設置為該字段的默認值。默認值的規則如下:
- 對于 string ,默認值為空字符串
- 對于 byte , 默認值為空字節
- 對于 bool , 默認值為 false
- 對于數字類型,默認值為 0
- 對于 enum 類型,默認值為第一個定義的枚舉值(編號為 0)
假設某個字段具有 optional 字段標簽(或是其他什么的標簽),那么在解析后的對象中將不會存在這些字段。
3.兼容性
如果現有的消息類型不再滿足您的需求,你可以對其進行一定程度的變更。
- 如果添加新字段,請勿更改任何現有字段的字段編號。舊的消息依然能被新生成的工具函數解析,新增的字段將會使用默認值;同樣,新的消息也能被舊的工具函數所解析(新增的字段將會被忽略)。
- 如果刪除字段,請記得保留字段編號,以免在未來重復使用導致預期之外的錯誤。
- 如果你想要進行字段類型的變更,一種方式是刪除原有字段隨后新建一個,另外一個方式就是直接修改某些可以無縫兼容的類型(例如 int32 轉變為 int64 ,顯然不會丟失信息),具體有哪些屬性是兼容的,可以查閱字段更新說明
除了上述提到的語法之外,其實還有很多進階的操作,例如:
- 聲明 Package 關鍵字區分命名空間。
- 使用 oneof 類型表示特殊的消息(包含多個字段,但這些字段在任何給定時間只能有一個字段被設置)
- 使用 service 定義定義服務端接口的請求與響應格式。
- 使用 import 導入其他文件中的消息定義。
請自行參考官方文檔吧!一個包含了大部分語法特性的代碼如下:
syntax = "proto3"; // 指定 protobuf 的版本
package example; // 定義包名
// 導入其他 protobuf 文件
import "google/protobuf/timestamp.proto";
import "other_package/other_file.proto";
// 定義一個枚舉類型
enum State {
UNKNOWN = 0; // 枚舉值必須從 0 開始
STARTED = 1;
RUNNING = 2;
STOPPED = 3;
}
// 定義一個消息類型
message Person {
// 定義一個字符串字段
string name = 1; // 字段編號必須是唯一的正整數
// 定義一個整型字段
int32 id = 2; // 這里的 2 是字段編號
// 定義一個布爾字段
bool has_pony = 3;
// 定義一個浮點字段
float salary = 4;
// 定義一個枚舉字段
State state = 5;
// 定義一個重復字段(類似于列表)
repeated string emails = 6;
// 定義一個嵌套消息
message Address {
string line1 = 1;
string line2 = 2;
string city = 3;
string country = 4;
string postal_code = 5;
}
// 定義一個嵌套消息字段
Address address = 7;
// 定義一個 map 字段(類似于字典)
map<string, string> phone_numbers = 8;
// 定義一個任意類型字段
google.protobuf.Any any_field = 9;
// 定義一個時間戳字段
google.protobuf.Timestamp last_updated = 10;
// 定義一個從其他文件導入的消息類型字段
other_package.OtherMessage other_field = 11;
// 定義一個 oneof 字段,可以設置其中一個字段
oneof test_oneof {
string name = 12;
int32 id = 13;
bool is_test = 14;
}
}
// 定義一個服務
service ExampleService {
// 定義一個 RPC 方法,請求類型為 GetPersonRequest 響應類型為 Person
rpc GetPerson(GetPersonRequest) returns (Person);
}
// 定義 GetPerson RPC 方法的請求消息類型
message GetPersonRequest {
int32 person_id = 1;
}4.數據編碼
該部分內容細節主要參考官方文檔: protobuf.dev/program...
Protobuf 采用了一種稱為 Tag-Length-Value(TLV)的編碼方案,在開始之前,我們可以利用以下函數幫助我們打印出編碼后的二進制序列方便觀察:
function toBinaryString(uint8Array) {
return Array.from(uint8Array).map(byte => byte.toString(2).padStart(8, '0'));
}
/*
const payload = {
name: 'dora',
}
const message = root.User.create(payload);
const buffer = root.User.encode(message).finish();
console.log(toBinaryString(buffer));
*/現在讓我們對一個 string 類型的數據 t 進行編碼,可以得到序列: 00001010 00000001 01110100 。

這三個字節分別對應了 protobuf 編碼的三個內容:(在 protobuf 中每個字節的首位都是控制位,用于表示隨后的字節是否需要和自己屬于同一個字段)
5.Tag
標簽由字段編號與字段類型組成,其編碼格式為:(field_number << 3) | wire_type
例如 0 | 0001 | 010 表示當前字段的類型是 3(010),字段編號是 1 (0001)。對于更大的字段編號例如 18,其 Tag 部分編碼序列可能為: 10010010 00000001 ,第一個字節去除控制位與字段類型剩下 0010 與后續字節逆序(考慮到大端小端字節序)拼接形成 00000001 0010(2+16=18) 。這就是為什么對于頻繁使用的字段最好將其字段編號設置在 [1,15] 之間,因為這樣編碼后的 tag 部分只會占據一個字節,能有效利用空間。另外從編碼后的結果來看,我們只保留了字段對應的編號,并沒有把字段的名稱也添加進來,這能夠非常有效地減少字節流大小。
那么字段類型是什么呢?
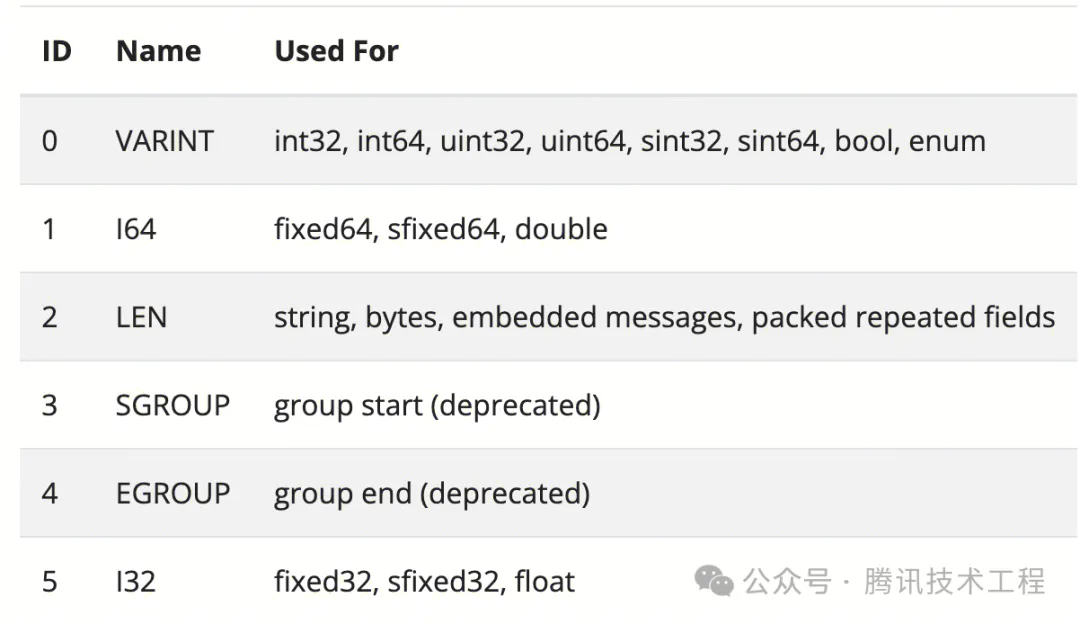
字段類型用于告訴解析器它后面的有效載荷有多大,從而允許舊的解析起跳過他們不理解的新字段。前面這句話其實是官方文檔做出的解釋,當個人認為理解起來較為困難。最好結合實際來看,例如對于 I32 類型 ,其有效載荷是固定 4 個字節的,也就是說 Tag 之后的 4 個字節是屬于當前字段的;對于 LEN 類型,其有效載荷則需要通過后續 length 部分的編碼才能確定;而對于 VARINT 類型,其有效載荷長度由編碼后的數字長度決定(并不需要由 length 部分決定)。那么舊的解析器遇到未知的字段時,只需要根據不同字段類型的規則跳過特定長度的有效載荷就能夠跳過那些無法理解的字段了。所有字段類型如下:
6.Length
對于具有長度的字段,例如字符串、列表等等,編碼后的序列需要顯式指定字段的長度。對于上面的例子,長度為 1 的字符串 t 編碼后的第二個字節就是用來指定字符串長度的00000001,后續的字節則用來表示每個字符的 ASCII 值。
7.Varint 編碼
Varint 編碼是一種用于壓縮數據的變長編碼方法,特別適用于編碼較小的正整數,但對于大整數和負數來說,反而會表現糟糕。 在傳統的 int32 類型中,一個數字比如 150(128 + 16 + 4 + 2) 會占用四個字節: 00000000 00000000 00000000``10010110。可以發現前 3 個字節都是 0 并沒有攜帶有效信息,導致存儲空間的浪費。Varint 編碼通過變長編碼優化了這一點,將同樣的數字 150 編碼為僅需要兩個字節的序列: 10010110 00000001 。
Varint 編碼的工作原理如下:每個字節的最高位(最左邊的一位)用作控制位,指示隨后的字節是否也屬于這個數的編碼。如果該位為 1,則表示后續還有字節;如果是 0,則表示這是最后一個字節。每個字節剩余的七位則用于表示實際的數字。(對于變長編碼,顯然我們需要一個信息位來表示是否到達了編碼末尾。)
10010110 00000001 // 原始字節流
// 10010110 開頭的 1 說明后面字節 00000001 也是編碼的一部分
0010110 0000001 // 丟棄信息位
0000001 0010110 // 由于 varint 編碼時采用小段順序,我們需要將其調換順序轉換為大段順序
00000010010110 // 鏈接有效載荷
128 + 16 + 4 + 2 = 150 // 解釋為無符號 64 位整數 這就是 Varint 編碼的工作原理,上述例子也說明了在處理小整數時的確非常高效。但它在編碼較大的整數時會需要更多的字節,這是因為每個字節只能貢獻七位有效數據。對于負數,由于它們在計算機中通常以補碼形式表示,這使得它們在 varint 編碼中看起來像是非常大的整數,因此編碼效率也不理想。例如 -5: 11111111 11111111 11111111 11111011,對于 sintN 類型的數據, protobuf 中采用的是后文將要提到 ZigZag 編碼。
ZigZag 編碼
工作原理:將所有整數映射成無符號整數,然后再采用 Varint 編碼方式編碼。 其基本思想是負數和正數進行交錯,使得負數映射為奇數,例如 0 -> 0, -1 -> 1, 1 -> 2, -2 -> 3 。這樣的好處是,無論正負,數值的絕對大小都能較為緊湊地表示。具體的映射方式如下:
(n << 1) ^ (n >> 31) // 32 bit
(n << 1) ^ (n >> 63) // 64 bit具體而言,當我們使用 ZigZag 對 -5 進行編碼時,結果為 00001001 。
最佳實踐
建議閱讀官方文檔:protobuf.dev/program...
- 不要重復使用字段編號,如果你想要刪除某個字段,請使用 reserved 關鍵字保留該字段對應的字段編號。
- 不要輕易改變已有字段的類型,盡管在某些情況下是安全的。
- 在單獨的文件中定義廣泛使用的消息類型。
- 避免使用語言的關鍵字作為字段名稱。
- 不要依賴于 protobuf 序列化的穩定性
- map 序列化時的順序是不確定的。
- 不要使用序列化后的內容作為 key。
- 不要通過比較序列化后的內容來確定兩條消息是否相同。
個人建議:
- 常用字段盡量使用 [1,15] 內的字段編碼,也注意為日后可能的拓展保留該區間的字段;
- 盡量使用小整數。
- 如果負數占據數據的大多數,請使用 sintN 類型。
總結
序列化目的是跨平臺存儲或者網絡傳輸,而 protobuf 作為一款序列化的協議,其最主要的特點就是序列化后的數據更小,傳輸更快并且具有良好的兼容性;主要的缺點就是通信雙方必須維護好 proto 定義文件。