













驚掉下巴:GPT-4o現(xiàn)場(chǎng)爆改代碼看圖導(dǎo)航!OpenAI曝光LLM路線圖,GPT Next年底發(fā)
這幾天,在巴黎舉辦的最大科技活動(dòng)VivaTech上,OpenAI再次帶來(lái)了許多驚喜。
從展示的模型智能進(jìn)化路線圖中,可以確定的是,今年OpenAI一定會(huì)發(fā)布新一代旗艦?zāi)P汀?/span>
而且,大概率不會(huì)以GPT-5命名,演示中將其稱之為「GPT Next」。

那么,OpenAI究竟會(huì)在2024年哪個(gè)月發(fā)布,爆料人Flowers掐指一算——可能在11月。

以GPT-3和GPT-4的發(fā)布時(shí)間等軸劃分
這是OpenAI開發(fā)者體驗(yàn)負(fù)責(zé)人Romain Huet在長(zhǎng)達(dá)38分鐘的演講中,向外界傳達(dá)的一個(gè)重要的信息。

演講現(xiàn)場(chǎng),Huet主要講了三件事:
- OpenAI是如何走到今天的
- 旗艦?zāi)P虶PT-4o
- OpenAI的下一步和前景

若說(shuō)整場(chǎng)演講中,最令人印象深刻的,依舊還是GPT-4o。
Huet現(xiàn)場(chǎng)用ChatGPT Mac版程序,讓GPT-4o向在場(chǎng)的400多位觀眾打招呼。
甚至還要求讓它用法語(yǔ),更熱情地問好,通過呈現(xiàn)不同的語(yǔ)音語(yǔ)調(diào),展現(xiàn)出GPT-4o強(qiáng)大的語(yǔ)音能力。
即便在打招呼過程中,Huet也可以隨時(shí)打斷對(duì)話,與人類真正交流互動(dòng)的方式幾乎無(wú)異。
另外,Huet還讓GPT-4o實(shí)時(shí)將英語(yǔ)翻譯成法語(yǔ),引得臺(tái)下公眾一陣鼓掌歡呼。

更讓人驚掉下巴的是,Huet打開攝像頭,向GPT-4o展示了一張凱旋門和巴黎鐵塔的草圖,它準(zhǔn)確識(shí)別出巴黎的標(biāo)志性地標(biāo)。

接下來(lái),他又向其展示了一張地圖,并詢問如何從凡爾賽門導(dǎo)航到草圖中的地方。

沒想到,ChatGPT不假思索地提供了詳細(xì)的火車路線,而且包括換乘和停靠站的具體信息。
,時(shí)長(zhǎng)01:23
有網(wǎng)友表示,「他們30分鐘的演示直接扼殺了數(shù)十家初創(chuàng)公司」。

除此以外,Romain Huet的精彩演講,還有哪些亮點(diǎn)?
「全能」GPT-4o驚艷全場(chǎng)
先來(lái)看看最新的第二趴,Huet主要強(qiáng)調(diào)了旗艦?zāi)P虶PT-4o的三個(gè)重點(diǎn)。
首先它是「多模態(tài)」的,幾乎沒有延遲,堪稱為一個(gè)真正的「全能模型」(omni model)。

其次,在大模型競(jìng)技場(chǎng)中,經(jīng)過盲測(cè)后的GPT-4o,取得了最新的SOTA。

最后,GPT-4o的API價(jià)格還是GPT-4 Turbo的一半,而速率大大提升的2倍。

接下來(lái),Huet顯示做了一個(gè)文章開篇介紹的GPT-4o演示。
作為ChatGPT的基操,讀代碼、debug這個(gè)環(huán)節(jié)也是必不可少的。Huet本人也做了現(xiàn)場(chǎng)直播演示,讓GPT-4o加持的ChatGPT Mac版去修復(fù)bug。
他將一段復(fù)制給ChatGPT,然后先讓其首先簡(jiǎn)單地描述下代碼的內(nèi)容:
代碼是一個(gè)名為Discover的React組件,它渲染一個(gè)Discover卡片組件網(wǎng)格,每個(gè)卡片的數(shù)據(jù)從trips.json文件中獲取。

然后,Huet將自己的屏幕分享給ChatGPT,并詢問能否讓這個(gè)頁(yè)面更具響應(yīng)性。

接下來(lái),就是ChatGPT放大招的時(shí)候了。
你可以使用Tailwind CSS的響應(yīng)式設(shè)計(jì)功能,根據(jù)屏幕大小調(diào)整網(wǎng)格中的列數(shù)。這是修改網(wǎng)格布局的快速方法。Div的顏色和布局方案,設(shè)置網(wǎng)格列數(shù)為1,從0到4列。
不過,Huet表示,其實(shí)我就是在使用Tailwind去處理,繼續(xù)問道,「那么你能告訴我屬性是什么嗎」?
ChatGPT答道,「對(duì)于Tailwind,你可以調(diào)整網(wǎng)格響應(yīng)列,以使網(wǎng)格響應(yīng)」。
以下是設(shè)置方法:網(wǎng)格列數(shù)將根據(jù)當(dāng)前屏幕大小進(jìn)行控制。所以你不需要太多列來(lái)填充網(wǎng)格,這是大多數(shù)響應(yīng)設(shè)計(jì)的經(jīng)驗(yàn)法則。默認(rèn)情況下設(shè)置1列,小屏幕設(shè)置2列.
Huet表示,「我明白了。所以我應(yīng)該在小屏幕上設(shè)置一列,對(duì)嗎?然后隨著屏幕變大,增加列數(shù)」?

ChatGPT確認(rèn)道,「沒錯(cuò)。你可以根據(jù)不同的屏幕尺寸調(diào)整列數(shù)。例如,默認(rèn)情況下設(shè)置一列,sm:-grid-cols-2設(shè)置小屏幕及更大屏幕為兩列,md:-grid-cols-3設(shè)置中等屏幕及更大屏幕為三列,等等」。
最后,Huet按著ChatGPT要求修改過后,再讓其看看是否正確。
ChatGPT給出了回答,「完美」!
這些演示,向所有人展示了GPT-4o相較于以往模型,展現(xiàn)出的強(qiáng)大能力,能夠在編碼問題上實(shí)時(shí)查看屏幕,幫你解決問題。
而且,GPT-4o生成文本的速度,完全碾壓了GPT-4 Turbo。

ChatGPT為Sora視頻配音,夢(mèng)幻聯(lián)動(dòng)
見識(shí)過GPT-4o的厲害之后,Huet還現(xiàn)場(chǎng)演示了一段ChatGPT和Sora夢(mèng)幻聯(lián)動(dòng)的例子。
首先是準(zhǔn)備工作——輸入Prompt,坐等Sora把視頻生成出來(lái),再配上背景音,一段「巴黎之旅」的視頻就做好了。
接下來(lái),再讓ChatGPT根據(jù)視頻中的關(guān)鍵幀,生成一段介紹。
其中,給到模型的系統(tǒng)提示是這樣的:
你是位歷史教授。你將看到一系列連續(xù)的圖片,它們是一部歷史紀(jì)錄片的一部分。你的任務(wù)是用一種引人入勝且富有信息性的方式描述畫面中的場(chǎng)景。
請(qǐng)為一位語(yǔ)速適中的解說(shuō)員編寫一份腳本,講述時(shí)間不應(yīng)超過45秒。
請(qǐng)將腳本分為2-4個(gè)小段落。不要添加任何前綴或描述,僅包括要講述的文字。

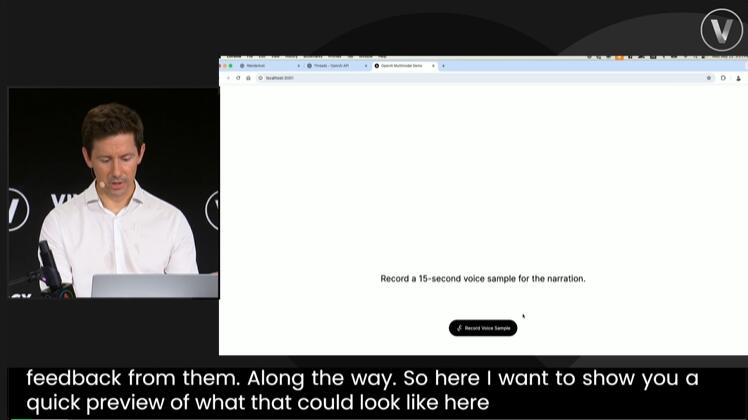
如果想讓視頻更加生動(dòng),則可以進(jìn)一步利用OpenAI的「Voice Engine」模型(語(yǔ)音引擎)把之前的文字介紹變成真人配音。
接下來(lái),首先需要向ChatGPT發(fā)送了一段錄制好的語(yǔ)音片段。
我非常高興自己站在VivaTech的舞臺(tái)上,并見到了一些非常棒的創(chuàng)始人和開發(fā)者。我很期待向他們展示一些現(xiàn)場(chǎng)demo,以及如何真正地將OpenAI的技術(shù)和模型應(yīng)用到他們自己的產(chǎn)品和業(yè)務(wù)中。
然后ChatGPT基于Huet的語(yǔ)音內(nèi)容,然后為Sora預(yù)先生成的一段巴黎歷史介紹視頻,進(jìn)行了「原聲」配音。
這時(shí),不僅可以用音頻源語(yǔ)言,還可以選擇法語(yǔ)、西班牙語(yǔ)、日語(yǔ)等多種語(yǔ)言,而且音色保持不變。
配好音的視頻,可以針對(duì)目標(biāo)語(yǔ)群體進(jìn)行分享,而且,還能為其配上字幕。
網(wǎng)友稱,「OpenAI這個(gè)案例向我們展示了,將Sora視頻發(fā)送給ChatGPT獲取腳本,并利用「語(yǔ)音引擎」為其配音,最后將所有模態(tài)內(nèi)容整合到一起」。

押注GPT大模型,多模態(tài)智能體是重點(diǎn)
接下來(lái),OpenAI下一步大動(dòng)作會(huì)是什么?
Huet稱我們未來(lái)將大力投資這四個(gè)領(lǐng)域。

首先是文本智能。
目前,GPT-4、GPT-4o雖是全球最優(yōu)秀的模型,但它們更像是一到二年級(jí)的學(xué)生,時(shí)不時(shí)會(huì)犯錯(cuò)誤。
「我認(rèn)為,也許一兩年后,這些模型將無(wú)法與今天的樣子辨認(rèn)」。
Huet繼續(xù)稱,今年OpenAI將計(jì)劃在下一代模型上更好地推動(dòng)這一界限,并提供像逐步函數(shù)一樣的推理改進(jìn)。
也就是,如下這張傳遍全網(wǎng)的路線圖。

第二,OpenAI要確保模型始終更便宜、更快。
因?yàn)椋贠penAI看來(lái),并非每個(gè)用例都需要最高水平的智能。

與此同時(shí),OpenAI還希望確保當(dāng)開發(fā)者想要擴(kuò)展時(shí),能夠提供不同的模型來(lái)滿足所有的需求。
在一些真實(shí)的工作流中,部分子流程,可能需要更小參數(shù)規(guī)模的模型,或者對(duì)延遲更敏感的模型。

第二個(gè)投資領(lǐng)域的最后一部分,OpenAI也是希望能夠幫助開發(fā)者,運(yùn)行異步工作負(fù)載。
比如,幾周前,推出的批處理API。這是一種非常便捷的方式,可以將你的所有請(qǐng)求批量發(fā)送到OpenAI。
這意味著,對(duì)于不需要立即響應(yīng)的任務(wù),還將能夠再享受50%的折扣。

第三,OpenAI還將投資自定義模型。
在未來(lái),不同的組織可能有不同的工作方式,更需要一個(gè)可以深入了解自身業(yè)務(wù)的模型。因此,OpenAI未來(lái)將會(huì)提供一系列微調(diào)的產(chǎn)品,包括簡(jiǎn)單微調(diào)API、提供團(tuán)隊(duì)幫助,以及讓OpenAI為其訓(xùn)練模型。

這里,Huet舉了兩個(gè)和OpenAI合作的公司,Harvey和SK telecom。

而對(duì)于第四個(gè)OpenAI投資的領(lǐng)域,那便是「多模態(tài)智能體」。
「我非常確信,在未來(lái),智能體可能是軟件,以及我們與計(jì)算機(jī)交互方式發(fā)生的最大變化」。

現(xiàn)場(chǎng),Huet還引用了美國(guó)著名程序員Paul Graham曾說(shuō)過的話。
通常,28歲的程序員比22歲的程序員更具生產(chǎn)力,因?yàn)樗麄儞碛懈嗟慕?jīng)驗(yàn)。但顯然,22歲的程序員現(xiàn)在和28歲的程序員一樣優(yōu)秀,因?yàn)樗麄兪褂肁l時(shí)更得心應(yīng)手。

Huet通過舉例Devin在實(shí)際中幫助開發(fā)者解決代碼問題,以及其他案例,去說(shuō)明智能體真的是當(dāng)今重要的應(yīng)用之一。

用例翻倍,GPT-4開創(chuàng)無(wú)限可能
演講開篇,Huet主要回顧了OpenAI至今已取得的成就。
一開始,他再次重申了,「我們是一家研究型公司,OpenAI的使命是打造有益于全人類的AGI」。

而目前,全球已經(jīng)有超300萬(wàn)開發(fā)者使用OpenAI API正創(chuàng)造一些有趣的事情。

92%的財(cái)富500強(qiáng)讓ChatGPT加入工作流,而還有1億的活躍用戶,開發(fā)者們已經(jīng)打造了300萬(wàn)GPTs。
總之,OpenAI在AI采用率上,是全球領(lǐng)先的。

ChatGPT發(fā)布之初是靜默的,卻沒想到,給世界帶來(lái)了翻天覆地的變化
其實(shí),ChatGPT之前,OpenAI早在2020年打造了GPT-3模型,并為開發(fā)者提供了嘗試?yán)肔LM去構(gòu)建應(yīng)用的體驗(yàn)。
可以看到,GPT-3的用例已經(jīng)非常廣泛,包括編程助手、代碼審查、搜索和信息檢索、內(nèi)容創(chuàng)造等等。
下圖中右邊展示的是,Huet的個(gè)人用例——角色扮演游戲。

直到2023年GPT-4誕生,開創(chuàng)了一個(gè)全新的紀(jì)元。
新模型可以開創(chuàng)盡可能多的無(wú)限想象,從GPT-3的8個(gè)用例到GPT-4的13個(gè)用例,幾乎實(shí)現(xiàn)了翻倍增長(zhǎng)。
它不僅推理能力得到了大幅提升,還可以像人類一樣,利用「工具」完成多項(xiàng)任務(wù)。
如今,這些能力已經(jīng)得到許多公司的采用,比如下圖中右側(cè)Spotify為用戶創(chuàng)建的獨(dú)特的清晨播放列表。

OpenAI在上周推出的GPT-4o,就像一個(gè)魔法層,給GPT-4用例加滿buff。
得益于實(shí)時(shí)跨音頻、文本、視覺的能力,GPT-4o能夠讓我們以前所未有的方式進(jìn)行交互。

站在OpenAI巨人的肩膀上,眾多初創(chuàng)公司已經(jīng)在客戶服務(wù)、知識(shí)助手、語(yǔ)音服務(wù)、內(nèi)容生成、智能體領(lǐng)域挖掘出的應(yīng)用,遍地開花。

演講最后,Huet表示,我們的目標(biāo)不是讓你在OpenAI身上花更多的錢,而是用OpenAI建造更多。






























