沒有等來OpenAI開源GPT-4o,等來了開源版VITA
大語言模型 (LLM) 經歷了重大的演變,最近,我們也目睹了多模態大語言模型 (MLLM) 的蓬勃發展,它們表現出令人驚訝的多模態能力。
特別是,GPT-4o 的出現顯著推動了 MLLM 領域的發展。然而,與這些模型相對應的開源模型卻明顯不足。開源社區迫切需要進一步促進該領域的發展,這一點怎么強調也不為過。
本文 ,來自騰訊優圖實驗室等機構的研究者提出了 VITA,這是第一個開源的多模態大語言模型 (MLLM),它能夠同時處理和分析視頻、圖像、文本和音頻模態,同時具有先進的多模態交互體驗。
研究者以 Mixtral 8×7B 為語言基礎,然后擴大其漢語詞匯量,并進行雙語指令微調。除此以外,研究者進一步通過多模態對齊和指令微調的兩階段多任務學習賦予語言模型視覺和音頻能力。
VITA 展示了強大的多語言、視覺和音頻理解能力,其在單模態和多模態基準測試中的出色表現證明了這一點。
除了基礎能力,該研究在提升自然多模態人機交互體驗方面也取得了長足進步。據了解,這是第一個在 MLLM 中利用非喚醒交互和音頻中斷的研究。研究者還設計了額外的狀態 token 以及相應的訓練數據和策略來感知各種交互場景。
VITA 的部署采用復式方案,其中一個模型負責生成對用戶查詢的響應,另一個模型持續跟蹤環境輸入。這使得 VITA 具有令人印象深刻的人機交互功能。
VITA 是開源社區探索多模態理解和交互無縫集成的第一步。雖然在 VITA 上還有很多工作要做才能接近閉源同行,但該研究希望 VITA 作為先驅者的角色可以成為后續研究的基石。

- 論文地址:https://arxiv.org/pdf/2408.05211
- 論文主頁:https://vita-home.github.io/
- 論文標題:VITA: Towards Open-Source Interactive Omni Multimodal LLM

在上述視頻中,用戶可以和 VITA 進行無障礙的溝通,看到用戶穿的白色 T 恤后,會給出搭配什么顏色的褲子;在被問到數學題時,能夠實時查看題目類型,進行推理,然后給出準確的答案;當你和別人講話時,VITA 也不會插嘴,因為知道用戶不是和它交流;出去旅游,VITA 也會給出一些建議;在 VITA 輸出的過程中,你也可以實時打斷對話,并展開另一個話題。

在這個視頻中,用戶拿著一個餅干,詢問 VITA 自己在吃什么,VITA 給出在吃餅干,并給出餅干搭配牛奶或者茶口感會更好的建議。
健身時,充當你的聊天搭子:

注:上述視頻都是實時 1 倍速播放,沒有經過加速處理。
根據用戶提供的流程圖,VITA 就能編寫代碼:

提供一張圖片,VITA 也能根據圖片內容回答問題:

還能觀看視頻回答問題,當用戶拋出問題「詳細描述狗的動作」,VITA 也能準確給出答案:

方法介紹
如圖 3 所示,VITA 的整體訓練流程包括三個階段:LLM 指令微調、多模態對齊和多模態指令微調。

LLM 指令微調
Mixtral 8x7B 的性能屬于頂級開源 LLM 中一員,因此該研究將其作為基礎。然而研究者觀察到官方的 Mixtral 模型在理解中文方面的能力有限。為了注入雙語(中文和英文)理解能力,該研究將中文詞匯量擴展到基礎模型,將詞匯量從 32,000 個增加到 51,747 個。在擴展詞匯量后,研究者使用 500 萬個合成的雙語語料庫進行純文本指令微調。
多模態對齊
為了彌合文本和其他模態之間的表征差距,從而為多模態理解奠定基礎。僅在視覺對齊階段訓練視覺連接器。表 1 總結了所使用的訓練數據,除了純文本部分。

視覺模態
首先是視覺編碼器。研究者使用 InternViT-300M-448px 作為視覺編碼器,它以分辨率 448×448 的圖像作為輸入,并在使用一個作為簡單兩層 MLP 的視覺連接器后生成了 256 個 token。對于高分辨率圖像輸入,研究者利用動態 patching 策略來捕捉局部細節。
視頻被視作圖像的特殊用例。如果視頻長度短于 4 秒,則統一每秒采樣 4 幀。如果視頻長度在 4 秒到 16 秒之間,則每秒采樣一幀。對于時長超過 16 秒的視頻,統一采樣 16 幀。
其次是視覺對齊。研究者僅在視覺對齊階段訓練視覺連接器,并且在該階段沒有使用音頻問題。
最后是數據級聯。對于純文本數據和圖像數據,該研究旨在將上下文長度級聯到 6K token,如圖 4 所示。值得注意的是,視頻數據不進行級聯。

級聯不同的數據有兩個好處:
- 它支持更長的上下文長度,允許從單個圖像問題交互擴展到多個圖像問題交互,從而產生更靈活的輸入形式,并擴展上下文長度。
- 它提高了計算效率,因為視頻幀通常包含大量視覺 token。通過級聯圖像 - 問題對,該研究可以在訓練批中保持平衡的 token 數量,從而提高計算效率。
此外,該研究發現使用級聯數據訓練的模型與使用原始數據訓練的模型性能相當。
音頻模態
一方面是音頻編碼器。輸入音頻在最開始通過一個 Mel 濾波器組塊進行處理,該塊將音頻信號分解為 mel 頻率范圍內的各個頻帶,模仿人類對聲音的非線性感知。隨后,研究者先后利用了一個 4×CNN 的下采樣層和一個 24 層的 transformer,總共 3.41 億參數,用來處理輸入特征。同時他們使用一個簡單的兩層 MLP 作為音頻 - 文本模態連接器。最后,每 2 秒的音頻輸入被編碼為 25 個 tokens。
另一方面是音頻對齊。對于對齊任務,研究者利用了自動語言識別(ASR)。數據集包括 Wenetspeech(擁有超過 1 萬小時的多領域語音識別數據,主要側重于中文任務)和 Gigaspeech(擁有 1 萬小時的高質量音頻數據,大部分數據面向英文語音識別任務)。對于音頻字幕任務,研究者使用了 Wavcaps 的 AudioSet SL 子集,包含了 400k 個具有相應音頻字幕的音頻片段。在對齊過程中,音頻編碼器和連接器都經過了訓練。
多模態指令微調
該研究對模型進行了指令調整,以增強其指令遵循能力,無論是文本還是音頻。
數據構建。指令調優階段的數據源與表 1 中對齊階段的數據源相同,但該研究做了以下改進:
問題被隨機(大約一半)替換為其音頻版本(使用 TTS 技術,例如 GPT-SoVITS6),旨在增強模型對音頻查詢的理解及其指令遵循能力。
設置不同的系統 prompt,避免不同類型數據之間的沖突,如表 2 所示。例如,有些問題可以根據視覺信息來回答或者基于模型自己的知識,導致沖突。此外,圖像數據已被 patch,類似于多幀視頻數據,這可能會混淆模型。系統 prompt 顯式區分不同數據類型,有助于更直觀地理解。

為了實現兩種交互功能,即非喚醒交互和音頻中斷交互,該研究提出了復式部署框架,即同時部署了兩個 VITA 模型,如圖 1 所示。

在典型情況下,生成模型(Generation model)會回答用戶查詢。同時,監控模型(Monitoring model)在生成過程中檢測環境聲音。它忽略非查詢用戶聲音,但在識別到查詢音頻時停止生成模型的進度。監控模型隨后會整合歷史上下文并響應最新的用戶查詢,生成模型和監控模型的身份發生了轉換。

實驗評估
語言性能。為了驗證語言模型訓練過程的有效性,研究者使用了四個數據集,分別是 C-EVAL、AGIEVAL、MMLU 和 GSM8K。這些數據集涵蓋了各種場景,包括一般選擇題、多學科問答題以及數學和邏輯推理任務,同時覆蓋了中英文上下文。
下表 3 的結果表明,本文的訓練顯著增強了語言模型在中文評估集(C-EVAL 和 AGIEVAL)上的能力,同時保持了在英文相關基準(MMLU)上的原始性能水平,并在數學推理任務(GSM8K)上實現顯著提升。

音頻性能。為了驗證模型學得的語音表示的穩健性,研究者在 Wenetspeech 和 Librispeech 兩個數據集上進行了測試。
其中 Wenetspeech 有兩個評估指標,分別是 test_net 和 test_meeting,前者數據源與訓練數據更加一致,因而更容易;后者提出了更大的挑戰。作為模型的 held-out 數據集,Librispeech 評估了模型在未見過數據集上的泛化能力,它有四個評估集,以「dev」開頭的是驗證集,以「test」開頭的是測試集,「Clean」代表挑戰性較低的集,「other」代表挑戰性更高的集。
從下表 4 的結果可以看到,VITA 在 ASR 基準測試上取得了非常不錯的結果。

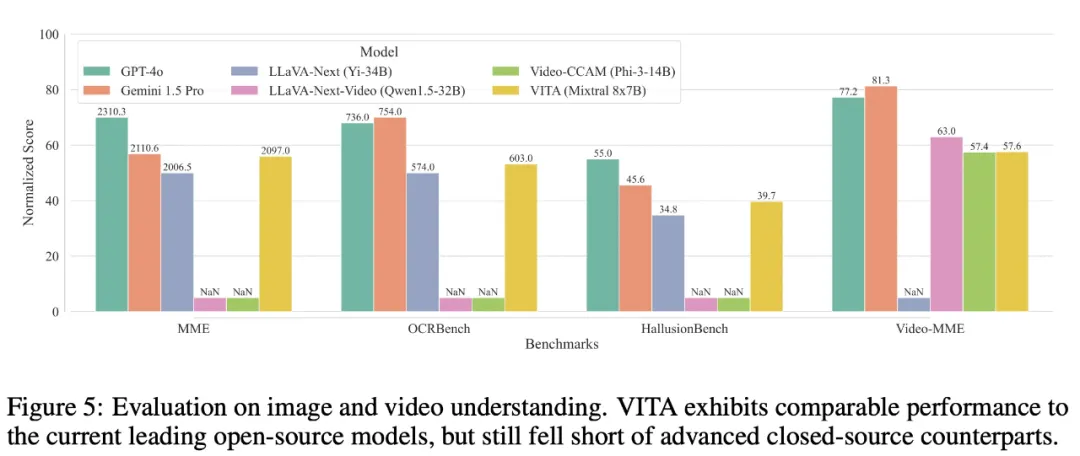
多模態性能。為了評估多模態能力,該研究在四個基準上評估了 VITA,包括 MME 、OCRBench、HallusionBench 和 Video-MME。結果如圖 5 所示。
在圖像理解方面,VITA 優于圖像專用開源模型 LLaVA-Next,并且接近閉源模型 Gemini 1.5 Pro。
在視頻理解方面,VITA 超過了視頻開源模型 Video-CCAM。盡管 VITA 和視頻專用的 LLaVA-Next-Video 之間存在差距,但考慮到 VITA 支持更廣泛的模態并優先考慮可交互性,因而這是可以接受的。
最后,值得注意的是,目前開源模型與專有模型在視頻理解能力方面仍存在較大差距。